近年来,发展发生了很大变化。 微服务和功能取代了单片应用程序。 通用工业怪兽的数据库已退化为目标狭窄的对象。 Docker改变了他对部署的想法。 但是,我们对原木的想法改变了吗?
Yandex.Verticals中最大的问题之一是日志-每天18 TB,每秒250,000日志,所有内容均写入文件。 日志是异构的,因为有许多语言:Scala,Java,Python,Go。 然后由Fluent Bit收集它们,用Kafka编写,处理程序在一台铁机上工作,从Kafka组装,然后将所有内容写入磁盘。 此外,这是日志的第二个版本。

结果,出现了长搜索问题。 这些日志是使用grep搜索的。 在某些服务上,grep可以达到几个小时。 如果您在生产中遇到问题,则将不需要几个小时的日志。 为了解决该问题,Yandex决定编写自己的日志传送自行车进行搜索。 这将告诉
Yandex.Verticals基础结构团队的开发人员
Alexei Danilov (
danevge )。 开发,编写和支持auto.ru和Yandex.Real Estate项目。
免责声明 本文讨论了现代开发,适用于微服务体系结构。 这里介绍了各种产品-这些是Yandex.Verticals中使用的工具。 在其他条件下,类似物可能更成功,但它们执行几乎相同的功能。 注意事项 本文是Alexey Danilov在RIT ++ 2019 DevOps Conf上的报告“不需要日志”的扩展版本,该报告经过了样式修改并补充了新材料。 您可以在我们的YouTube频道的链接上找到Alexey的讲话录像。
Yandex.Vertical团队有300人,其中大约100人是开发人员。 在开发中,我们与大多数创建自己的产品解决方案的公司没有什么不同。 微服务,每个人都生活在Docker中,PHP的巨石在一个黑暗的角落收集灰尘,通过Hashicorp Nomad进行部署,我们拥有众多的语言动物园:Scala,Java,Go,Node.js,Python。
Yandex.Verticals中的主要基础结构问题之一是应用程序日志。 当我们认真解决这个问题时,我们使用了它们收集和处理的第三版。 简化后,它的工作方式如下:
- 应用程序写入文件;
- 流利的比特读取文件,并将它们逐行发送到Kafka filebeat;
- 在专用的铁机上,有一个应用程序读取Kafka主题并写入磁盘上的文件。
在炎热的季节,我们每天有18 TB的日志,或每秒250,000行。 这是一个非常大的数目,这使使用此数据的工作变得复杂。 分析这一切的唯一方法是grep,因为所有内容都存储在文件中。 对于大型应用程序,分析可能需要几个小时。 对于生产中的问题,您没有这个时间。
现成的解决方案不适合价格,资源或速度。 他们无法接受我们的流程。 甚至很难算出烹饪Elasticsearch的尝试次数。 我想我们不知道怎么做。 但这不是我们所需要的,如果要将其用作日志存储库,则需要特殊能力(技能)。
在这种情况下,我们决定实施自己的系统来收集和分析日志。
单车
 注意:如果下一辆自行车没意思,请立即进入“典型”部分。
注意:如果下一辆自行车没意思,请立即进入“典型”部分。格式
我们使用了几个PL,并且喜欢微服务。 为了处理日志,我们统一形成了自己的JSON格式。 它涵盖了进一步处理日志的大多数需求。
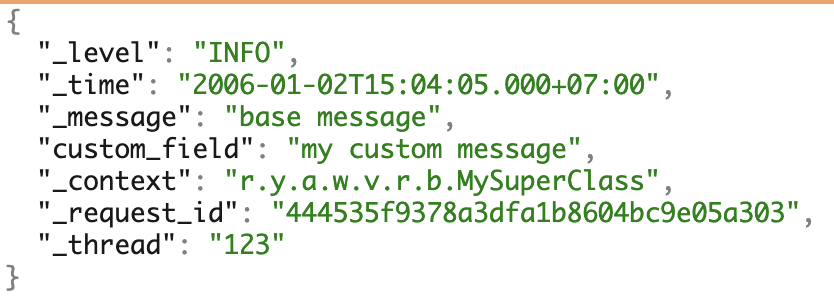 具有所有可能字段的日志示例。
具有所有可能字段的日志示例。Docker日志驱动程序
为了收集日志,我们编写了自己的
docker日志驱动程序-Go上的应用程序。 它以特殊方式组装,由docker插件命令交付,存储在注册表中,并在运行Docker的单个实例中运行。
由于日志驱动程序的任何问题都会对所有工作产生负面影响,因此我们尝试编写一个最小的实现。 我们的驱动程序侦听容器的标准输出,并立即将日志传递到附近的应用程序。 它已经处理了交付中更复杂的部分。
问题所在
我将分别提及更新docker log driver版本的问题。
 内部Grafana的屏幕截图。
内部Grafana的屏幕截图。左侧是已安装版本与计算机的比率。 现在,所有硬件上都安装了三个版本-不会在任何地方丢车,也没有不必要的安装。 右侧是使用此版本或该版本的容器的数量。
泊坞窗驱动程序无法立即更新。 为此,您必须重新启动所有容器和所有服务,这可能会导致问题。 因此,要安装新版本,我们只需要等待所有容器更新即可。
一般方案
考虑用于收集和传送日志的新系统的一般方案。 其他细节并不那么有趣。
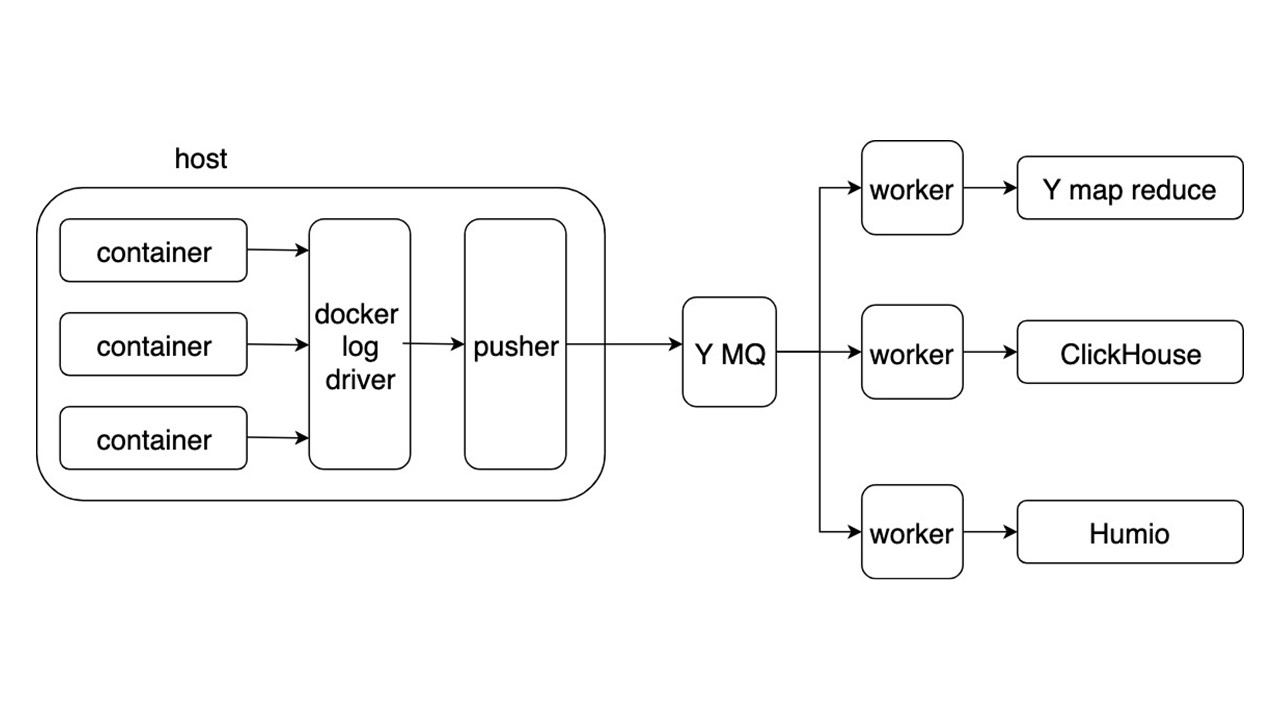
应用程序在stdout中以JSON格式写入日志。 Docker侦听来自容器的管道,并将其重定向到Docker驱动程序。 Docker驱动程序读取并异步重新推送Pusher中的所有内容。
推杆站在每辆铁车上。 他准备,饱和,翻转日志并将其推入Yandex Message Queue。 来自MQ的日志流由三种类型的工作程序进行解析,并将其写入存储库。
有三个用于记录日志的存储库。
- Yandex mapReduce用于长时间存储和分析日志。 这是Hadoop的类似物。
- ClickHouse,用于存储最后一天的日志。
- Humio (作为实验)存储最后一天的日志。
获利
通用格式允许您以相同的方式编写和处理日志。 日志收集是自动的,无需使用磁盘,并且交付时间大约为几秒钟。 键搜索从2秒到5秒。 长时间存储和检索。
对于较小的体积,请考虑以下替代方案:Humio,Splunk和Elastic。 后两个具有官方的Docker驱动程序。 如果您住在AWS中,那就是Amazon CloudWatch。
亚马逊CloudWatch
Amazon CloudWatch处理指标,事件和日志。 他不会寻找后者,不会提供超级搜索项目,也不会以常规形式对其进行处理。 Amazon CloudWatch处理日志,分析,过滤并在图形上显示。
 Amazon CloudWatch将日志转换为指标和图形。
Amazon CloudWatch将日志转换为指标和图形。如何处理日志?
回到我们的自行车-它能满足所有情况吗? 不,我们的解决方案允许您查找日志,但是它们需要信息及其类型的异构性更高。 日志用于更多情况。
一旦您收集了日志,下面的句子将是:“让我们解析某些内容,以某种方式对其进行处理,将其写下来,然后开始在图表或仪表板上显示。” 这是通往地狱的方式。 特别是在我们谈论通用工具时。
如果您将日志想象为任何数据的特定混乱或事件日志,则它们将无法工作。
这将是一大堆无法处理的信息。 游戏将从日志的形式化开始:“让我们以特殊格式编写这些行,以便以后解析它们时会很方便!” 那也不行。 相信我们,我们尝试了。
打字
如果将日志分为类型并分别进行处理,则可以找到使它们更易于使用的工具。 不再像日志那样工作,而是像有用的数据一样工作-这样的工作更加透明和方便。 某些类型的日志可以完全丢弃。
以防万一
我最喜欢这种类型的“成为”日志。 如果不可能明确回答为什么需要此行,那么就可以了。 此类型也可以称为“日志以防万一”。
// validate customer func Validate(customer Customer) { // ??? log.debug(“Validate customer %v”, customer) … log.Error(“Customer not valid %v. Reason: %s”, ...) …. }
日志不是可以删除的注释。 这是代码的一部分,很难修改,维护,甚至更难删除。
在最佳情况下,此类日志可能会变成调试或跟踪。 这种类型
会使代码混乱 。 由于粗鲁的日志记录,我可以将个人数据,用户的密码和Cookie放入其中。
正确的方法是
将它们扔掉并忘记它们 。 但是随后我们面临一个新问题。 如何解析错误情况?
致命/严重错误
首先,我们仅考虑严重错误。 这些都是用户和开发人员所遭受的错误。 第一个-当他们无法完成操作时。 第二个-当您需要手动进行更正时。
为什么日志不适合?
没有快速反应 。 如果开发团队通过支持或Twitter从用户那里了解错误,那么该是时候做些改变了。
没有上下文 。 错误日志的单独一行是无用的。 我们必须一点一点地收集上下文。 即使如此,这可能还不够,因为这是过程的上下文,而不是错误。
没有大图景 。 对这些问题没有答案:
- 这种错误多久发生一次;
- 它发生在服务的其余副本上;
- 是以前吗
要解决这些问题,请使用合适的工具,例如
sentry.io 。 它允许您使用可自定义的
alerting rule来处理具有代表性的完整(上下文)错误信息。
sentry网站描述了使用sentry.io日志的差异。
非严重错误
我们抛出了致命错误和严重错误,现在将它们写成哨兵。 但是存在内部错误-各种库或第三方服务的答案。
一个很好的例子是重试成功。 假设服务A转向服务B,但是由于网络问题,无法获得答案。 错误发生后,服务A再次转向服务B并收到了有效的响应。 首次通话的错误严重吗? 不行 在这种情况下,该过程成功完成,并且用户可以使用该服务。
如果此类错误对于服务正常运行而言并非至关重要,并且不会以极少的重复影响用户,那么这些根本就不是错误。 这是服务的降级,尽管对用户的响应是在50毫秒后发出的。 此类日志指警告-警告。
警告
警报是有关服务降级的信息。
在这里,我们将看到严重错误中固有的相同问题,但有所保留。 对单个事件的反应并不重要-随着时间的推移它们的数量很重要。
考虑一个服务无法检索缓存条目并访问冷存储器的示例。 如果这种情况每分钟发生一次,则可以将其用于服务的正常运行。
稀有气体的排放并不重要 。
但同时,您需要具有查看全局的工具,需要
实时分析 。 要跟踪长期的变化,最好还进行
回顾性分析 。 降解超过一定水平(阈值)会对用户产生不利影响-您需要
做出严重降解的
反应 。
我们不需要标记为警告的日志,而是降级指标。
最受欢迎的度量标准收集工具是Prometheus,您可以使用Grafana进行可视化。 如果您需要较大的上下文(与错误相同),则可以使用相同的Sentry,但是会关闭警报。 但是,在大多数情况下,将有足够的上下文。 它将用于图形-Prometheus标签。
例子
条件
user_service发生了三个事件。 它们会影响服务的操作:对数据库的长时间请求,对
service_b服务API的重复访问以及在缓存中找不到用户权限。 由于上下文的关系,图表和警报将被配置为对该服务的开发者非常重要。
追踪
首先,如果我们选择了需要解析日志的路径,那么这是第一件事。 日志中的这些信息本身是无用的,因为您需要构建呼叫链,查看请求中的数据,呼叫链中的错误,响应时间以及RPS的数量。
有很好的跟踪工具-Jaeger或Zipkin。 我建议使用它们都支持的OpenTracing。
您可以从三个来源收集跟踪。
- 如果您使用共享平衡器 ,请从中分析日志并将其发送到Jaeger。
- 服务本身 (如果它们通过服务发现接收地址并直接进入)。 在这种情况下,来自服务的跟踪将直接发送到Jaeger。
- 智能服务网格 。 他知道如何收集和发送跟踪,例如Istio。
初始信息
此信息与API服务调用,Cron启动,数据库查询或对其他服务的调用有关。
{ "_message": "Request: ...; request_id: ...,... ", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcHandler", "_tread": "785534" }
该信息属于“ Just in case”(防万一)情况,但由于更为常见而被单独使用。 需要此信息来分析错误,
您可以将其丢弃 。
如果有关内部方法调用的信息至关重要,即使在发生错误的情况下使用收集的上下文,也不能不使用它,那么值得将方法调用作为跟踪进行检测。
执行时间
此信息与方法,API,数据库查询或其他服务的执行时间有关。
{ "_message": "Get customer 12ms", "_level": "INFO", "_time": "2019-03-08T12:04:05.000+07:00", "_context": "ryawvcCustomerRepository", "_tread": "785534" }
日志中没有任何值,因为您需要分析此信息,在图表上显示它,并配置阈值。 例如,在Prometheus中,此类日志需要替换为
指标 。
商家资讯
此信息对于业务分析,客户行为分析,财务计算是必需的。 在这个地方,我们历来使用相反的方法-解析日志。 但是,这是一个很好的示例,说明了如果您以这种方式使用应用程序日志,则该应用程序日志可能会退化。
对于包含业务数据的日志,已与TSKV格式的固定字段形成了协议,这对于分析是必需的。 应用程序将业务日志写入专用文件。 然后,读取日志并将它们逐行发送到MQ,然后一个单独的应用程序对其进行处理并将其写入数据库。 这是任何解析结果的一个示例。
解析整个日志流以希望数据会收敛是行不通的。
惯例,格式,规则和可靠性要求正在出现。 这看起来已经有点像应用程序日志。 在这种情况下,日志将成为具有所有随后的MQ需求的数据传递队列。 值得注意的是,日志形式的中间件在这里是多余的。
一个好的解决方案是将这些数据直接发送到MQ。 它们已经被处理,存储在适当的存储中并由分析团队使用。 例如,对于显示,我们使用Tableau。
性能表现
这种类型的日志很少在应用程序日志中找到,并且更经常作为度量收集。 另外,我补充说,要收集特定于该语言的基本指标,使用Prometheus库就足够了。 默认情况下,她将收集她到达的所有物品。 添加这些指标的成本很小。

打字结果
按类型对日志进行排序后,我们可以选择使用功能更强大的工具。 没有像亚马逊这样的复杂系统或太空技术,明天就没有其他东西可以提出。 您可能已经拥有其中一些系统或类似系统:Sentry在某个地方收集灰尘,Prometheus在某个地方工作。

问题不在于技术,而在于我们信任日志作为可靠表示系统状态的一种手段时的认知陷阱。 事实并非如此,日志是一系列混乱的事件。
有一个例外-调试日志,可在极少数情况下使用。
调试日志
调试日志应为详细信息。 他们不应复制已经发送到上述系统的内容。 存在用于解析特殊情况的类型。 例如,一个难以理解的错误发生在生产中,而目前尚无法通过度量标准确定发生了什么。
在不重新启动服务的情况下,热启动调试日志 。 由于我们在谈论几种服务,因此不会有很多。 不需要复杂的基础架构。 足够的ELK堆栈,无需复杂的“准备工作”。 在所有必要的上下文中向Sentry添加警报也很有意义。
调试日志可用于开发 。 但是它们已被调试完美替代。
总结一下
我们写了我们的自行车日志以供搜索 。 我们不满意该服务的客户-他们全都来我们这里解析,收集和汇总它们。 可以避免-不需要复杂的日志处理系统。
原始日志没有用,但可以将其转换为有用的指标。
足以创建一个基础架构,以围绕服务交付有用的指标和数据。 结果,将出现有用的度量标准,这些度量标准谈论服务并透明地显示发生在服务上的一切。
错误必须包含错误本身的上下文。
这将有助于应对并立即修复。
错误和降级应该导致采取行动 ,以便开发人员即使在用户生气之前也可以立即了解问题并加以解决。
正确的工具将使您的服务工作更加愉快和透明 。 调试有一个地方,但是您必须严格遵守它。
在11月的HighLoad ++ 2019上,将有一个DevOps部分-有关AWS中负载的13个报告,Lamoda中的监视系统,用于模型交付的输送机,没有Kubernetes的寿命等等。 请在单独的页面“ 报告 ”中查看主题和摘要的完整列表。 我们将于春季在DevOpsConf见面-订阅新闻通讯 ,让我们知道何时确定日期和位置。