2018年11月,在立陶宛成立了一个信息支持部门,并邀请
Andrei Yumashev领导。 去年,该部门帮助公司进行工作和开发,并使整个基础架构处于受控状态。 但这并非总是如此。 在开始工作之前,Andrei面临着一片废墟:半死的Nagios,有条件居住的仙人掌和昏昏欲睡的Puppet,120页的死Wiki,不连贯的任务表和铁清单,过时的架构,340个不活动的内核,2 TB的内存和17 TB的内存由于某种原因未在清单表中记录的磁盘空间。 无法执行的计划,无法按时完成的期限,无法使用的工作环境和工具-所有这些都在新项目中等待着安德烈(Andrei)。

在
2019年DevOpsConf上,安德烈(Andrei)作了一份报告,在现场示例中展示了当您进入一个您没有看到或不了解的项目时,什么是有价值的以及不应做什么。 切入部分是故事的更新版本-如何正确分析问题范围并制定活动计划,如何正确计算KPI以及何时及时停止。
Andrey Yumashev是自己在各个领域(在线和线下)的开发公司的所有者,流程构建的顾问以及LiteRes的信息支持部门主管。
关于LiteRes的一些知识。 这是俄罗斯最大的电子和有声读物供应商,一家出版社和一系列合作项目。 这些是成百上千的Perl行,几个数据库集群和存储库。 这是每秒2 GB的传出流量,每天数十万个唯一请求,不同数据中心中的几个机架以及100多个服务器。 总而言之,这不仅仅是一家电子书店。
第一步
我以前是在LiteRes中按件工作。 该公司通过在州内远程员工的注册来进行人员发展。
以升为单位的任务执行系统以“拍卖”为原则。 在内部任务跟踪器中,管理人员和架构师描述内部项目的任务并以本地货币对其进行评估。 货币是“蘑菇,草和树”。
然后开始“轻松拍卖”-任何开发人员都可以承担任务或讨价还价。 做得好-您会获得报酬。 我根本不工作-你不明白。 人们以一种有趣的方式对完成任务感兴趣。 要了解有关此系统的更多信息,请参阅Dmitry Gribov的
演示文稿 。
 为蘑菇工作。
为蘑菇工作。该系统适合我-我支持Perl编程经验,在方便且不花太多时间的情况下工作。 在这种模式下,我花了几年时间直到去年11月,以为我了解生态系统的结构。
我错了
我受邀加入该公司,并告知不需要作为Perl开发人员的服务,因此我被任命为新部门的负责人。 2018年11月,我成为信息部门主管。
在我眼前是空地:莫斯科多个数据中心中的几个铁架子,过时的架构,国外资源以及几乎完全没有相关文件。 序言听起来像是这样:“现在这是您的遗产,不断完善,不要中断和支持。” 来年有一些现成的任务清单和粗略计划。 有必要理解所有这些并将其变成人类形式。
感觉到我正在看着深渊,而深渊正在看着我。
当我与陌生人或难以理解的人一起工作时,当我建立起明确的职位时,过去几年的经验对我有很大帮助。 首先,这是一个彻底的研究和最小的行动计划。 这是我开始的地方。
清洁是健康的关键
顺序是第一位的。
在第一个月设法找到:
- 散布有当前任务和大量有用信息的Google表格;
- 散乱的文档:单词,文本,旧Wiki的120页页面的碎片;
- 半死的老纳吉奥斯;
- 有条件地实时监测仙人掌;
- 很老的木偶,生命迹象很少。
所有这些废墟也收集了400个指标。
 我在第一个月发现的废墟。
我在第一个月发现的废墟。我当时很有趣,阅读所有内容并坚持使用Trello流程。 他将同事的当前任务转移给他,并开始梦想-为该季度和年度制定计划。
第一个错误
在您探索该地区之前,没有计划。
该计划充满热量和健康,但没有考虑现实。 它既简单又美观:实施监视,分析日志并将部署转移到CI / CD。 最终某个地方出现了一个乏味的“对项目弱点的分析”。 经典的第一步。
我忘了主要的事情。 我的首要任务不是实现用于实现工具的工具,而是确保整个服务的可行性和稳定性。
在我编写计划并受到同事问题的折磨时,第一个问题来了。 一个群集集群中的一个节点用完了空间,整个SSD终止于同一群集的另一个节点上。 我紧急购买了更大的新磁盘,并且通过将系统从一个磁盘复制到另一个磁盘,我们部门迅速获得了更换这些磁盘的经验。 更换磁盘后,我们通过SST从头开始构建集群。 该集群建立在Percona和Galera上,而这种娱乐活动对他而言毫无益处。
当我在数据中心之间旅行时,有关该计划的
第一批怀疑产生了。
 啊!
啊!同时,黑人工作的强度是如此之高,以至于我什至都不认为要收集完整的病史,而只是拍了些照片以供进一步研究。
同时,另一个介绍出现了。 以升为单位有书籍的音频版本。 为了使收听者不必再次倒带录音,我们有一种机制可以跟踪停止的时刻。 下次您收听时,将从所需部分播放音频版本。 对于此任务,需要更快地找到大约500个内核,1 TB的RAM和Java的分析能力。
我开始向Azure,Google,DigitalOcean以及Droplet解决方案提供的其他所有功能进行简介。 容器化乞求,为什么不乐意实施呢? 此外,在“大计划”中对此有一个单独的观点。
一个月的通信和投标已经过去了,所有事情都添加到了Trello的任务中,我创造了很大一部分,但是结果没有进展。 我想知道我是否要去那里。 在我之前,不管我展示了多少空的活动,一切都以某种方式起作用并且不会停止。 我仔细地坐下来研究了一点点设法收集的库存。 然后他起身去了第二轮数据中心。
对数据中心的第二次平静访问将所有内容都放在了适当的位置。 当我不在控制台,不是在Excel中而是在现场看到所有这些时,我对现实的认识发生了根本性的变化。 我意识到自己根本不忙于应该做的事情。 因为首先您需要了解我的工作。
在不了解自己的工作方式之前,所有计划都是在浪费时间。
我研究了机架,将现实与列表进行了比较,进行了编辑,然后偶然发现了一个带有20个刀片的半单元。 在20个中,只有4个可以工作,我摇动刀片,意识到我们不需要任何液滴来溶解溶液。 因为我发现了340个休眠内核,2 TB的RAM和17 TB的磁盘空间! 这些是旧的后端,只是停止使用的群集的旧节点,而时间已经抹去了它们存在的记忆。 我将Kubernetes放在这些刀片上,摆脱了一项主要任务。
第一次错误输出
分析和研究。 没有对此情况的初步分析,火车就不会行驶。
经过周密的实地考察,我已经掌握了设备和系统总体架构的相关计划。 在院子里是一月。 我花了两个月的时间,其中一半只是左右并进。 我不知道首先要扑灭什么样的火,首先要解决什么问题-在支持下的例行公事并没有解决。
同时,我推导了三个规则。 这些是第一个错误的后果。
 三个推论。
三个推论。第二计划
我从前台排除了次要任务-日志分析和CI / CD实施。 就大灾难而言,这些小事情并不重要。 升已经工作了多年,并已开发出自己的用于处理原木的逻辑,并获得了一个自制的滚动恶魔。 我将第五个计划付诸实践,并且不需要干预。
第二个计划看起来像这样。
处理监控 。 以目前的形式,它虽然有效,但并未反映至少三分之一的问题。
描述整个公升的一般逻辑 。 服务器名称很棒,但是关键捆绑包是关键知识:什么,在哪里,在哪里,为什么以及为什么。 先前的错误清楚地表明,无论如何都没有这样做。
缩放比例 。 几乎最后的免费资源占用了Kubernetes。 根据最小的估计,他应该在六个月内完成全部工作。
设备的库存和条件 。 作为旅行的一部分,我从许多担心其标签的服务器上清理了一个网络,这些服务器带有“备份”,“订阅”,“ bgp”标签。 再次,光盘,删除磁盘。
适应现实的指南 。 大多数说明已过时或不完整。
前六个月的营业额,设备购买和麻烦未引起注意,我终于陷入了第二个错误。
第二个错误
不要小看。
想到的任何术语都被低估了 。 当然,您可以从该项目中迅速受益。 但是要获得最大的回报,请将计划时间
至少乘以两倍 。 特别是在一个复杂且高负荷的项目上,该项目的流量每年稳定增长100%以上。
为什么至少要两次? 如果该项目不稳定且未经研究,请做好准备,以防任何活动都会在邻近地方引发其他活动。 似乎更换磁盘-哪个更容易? 在您进行购买之前,该过程很简单,然后安排停机时间特定节点的时间,然后在更换磁盘后进行维修。 我估计这个简单的操作一周。 最终,即使有一个简单的采购计划,也花了两个半星期。
另一个例子是购买和安装新设备。 坚持购买,有什么困难? 我花了不到一个月的时间才考虑到交货时间。 实际上,三个机箱之一仍然站在我的办公桌前。 这是因为设备根本没有足够的空间-我们计算了当前安装之间的孔中的位置。 当我们到达一个数据中心以晃动机架的意图时,我们突然意识到这两个服务器“不可触摸”。 首先是主机,触摸它根本不安全。 第二个是一篮子16块磁盘,它们关闭了,上面堆满了数据堆。 没有放置秸秆,也没有进行分析,最好能将三分之二粘在上面。
如果一切似乎都很简单-很快您就会遇到问题 。 这次安装提出了一个新的问题-如果这个地方一切都不好,那么我们将如何扩展? 一个小任务现在产生了巨大的汗水。 根据计划,到2020年,将一个数据中心转移到另一个数据中心,并通过机架扩展其余数据中心。 这意味着在模块之间的数据中心内迁移。 网络的重组和向10G的转移是对迁移的补充。
不要低估时间,进入门槛和后果。
基本概念
当然,错误的本质已经在Wiki中描述为基本概念。
任何官僚主义过程至少持续一个月 。 这适用于采购,与数据中心或其他承包商缔结新条件的一切。 把它当作事实。
签订合同并付款后 ,从磁盘到处理器的
任何交付至少持续一个半星期 。 学习与供应商协商交货前的日期。 例如,现在将磁盘小批量交付给我们,直到付款甚至在应用程序批准之前。
尽管对实施没有清晰的了解,但是任何实施某项计划的计划仍然是计划。 步骤越短越好。
例如,要从MySQL切换到ClickHouse,需要执行以下较大步骤:“让我们填充一些服务器,然后为重新集成开票!” 实际上,对该问题的详细研究导致了新的步骤:额外购买设备(例如,处理器和磁盘),用于更改用户行为跟踪器的逻辑的详细票证,维护反向集成,队列服务器等。
计划越详细,效果越好。 笔触较宽可以保证在截止日期内100%的错误。
使任何计划受到最大的批评,并期望最大的风险 。 一定要从业务角度看计划-每一步都会带来什么利润。
我们必须执行强制性实施:监视,Ansible,但我们并没有忘记业务组件。
- 通过更改网络体系结构,我们将能够接受其他流量并解决许多当前的问题。
- 通过更改内容存储的类型,我们将减少归还书籍的错误数量,并提高处理数据的速度。
- 将后端移动到云中-在营销活动期间立即扩展负载。
- 将跟踪转化为ClickHouse,为分析师提供了一个机会,可以更好地了解我们心爱的读者和听众的需求。
处理您对本主题不熟悉的情况的最佳方法是寻求专家的帮助,而不是Stack Overflow的帮助 。 语音联系解决该问题的速度比长信件或阅读文档快很多倍。
六个月后
尽管我一开始就专注于根本任务,但由于研究和纠正,我的手上还是出现了一些美好的事情。
自行编写的网络和地址清单工具。 他定期窃听我们所有的子网,并另外使用BIND配置检查数据。 这样可以轻松快捷地调试新服务并了解网络池的实际负载。 我确实不想花时间在此上,但是我找不到现成的替代方案,并且找到一个分配给新资源的地址花费了很多时间。 在编写工具时,该计划的初稿出现在网络上。
木偶不再是那么的死亡和困惑 。 我从第一错误中得出了结论,甚至没有尝试转到Ansible,这对我来说比较舒服。
或多或少操纵Nagios 。 我将其从办公室移至数据中心,并在三个点分发。 它比实施Zabbix更快,更便宜。 我们用时间和事件不正确的警报,规则的简单重新配置以及其他控制节点的引入填补了漏洞。
了解所用数据库集群的维护。
Wiki严重膨胀 。 她从有关使用环境的评论和说明中“摆脱了脂肪”。
我们购买了
三个HP机箱 ,以供将来安装。
更清晰地
了解到2019年剩余时间的路径 。
用于部门工作的
再生生态系统 。
这六个月,我几乎一个人工作。 继承的员工更多是系统管理员。 他们并不真正渴望深入研究DevOps的本质。
我非常困难地在团队中找到了两名专家-初级和中级。 我从当前的管理员那里收集了最多的知识,外观和密码,并全心全意地与他们分开。
工作系统,环境和工具
我将告诉您引入有效的生态系统和环境的重要性。 我已经提到了Trello,但是没有说为什么以及为什么要实现它。 如果没有设定目标和结构化数据,就不会建立任何工作。 第一个错误部分证明了这一点-收集所有东西。
拿走一切,什么都不给。
这个过程是进步的引擎 。 因此,尽管研究和工作流程受阻,但我一直都在系统上工作。 有了这个系统,六个月后,我将部门的蒸汽机车置于稳定的轨道上。
引入支持工具以及有关其使用的简短课程,可为您和您的同事节省大量时间。 尤其是即使您最上层的人也了解管理知识,并且在桌面和生活中都能保持一定的秩序。
我们不使工具复杂化,我们从简单的角度介绍必要的工具 。 在年初,我以为哪种任务跟踪器适合我们。 立即解散吉拉(Jira)和Redmine-过多的控制权。 我们会花时间填写表格,而不是任务。 Google表格-我认为不值得解释为什么。
特雷洛很完美 。 一些简单的列:“待办事项”-将所有将来发现的错误或任务累加起来,“待完成”-要完成的主要任务和“完成”。 稍后,有五列:“待办事项”,“暂停”,“冲刺”,“完成”和“研究”。
在“暂停”中携带的东西在冲刺过程中失去了相关性。 在“学习”中-需要研究的任务,直到理解并将知识转移到Wiki时才应该丢失。 冲刺已成为我们已切换到冲刺系统的证据。 — 2 . , .
.
— , Trello. . , , . 2-3 , . , .
. — Puppet, Nagios, DNS — SVN GitLab. Jenkins. DNS , Puppet - . , 1Password. .
, .
: , , . , .
— . . , , . , — «.».
( ) - DDoS- . , , DDoS. DNS , 10 DNS . , — , , — . , 20 .
Cloudflare . Anti-DDoS . , Cloudflare . . , DDoS' , .
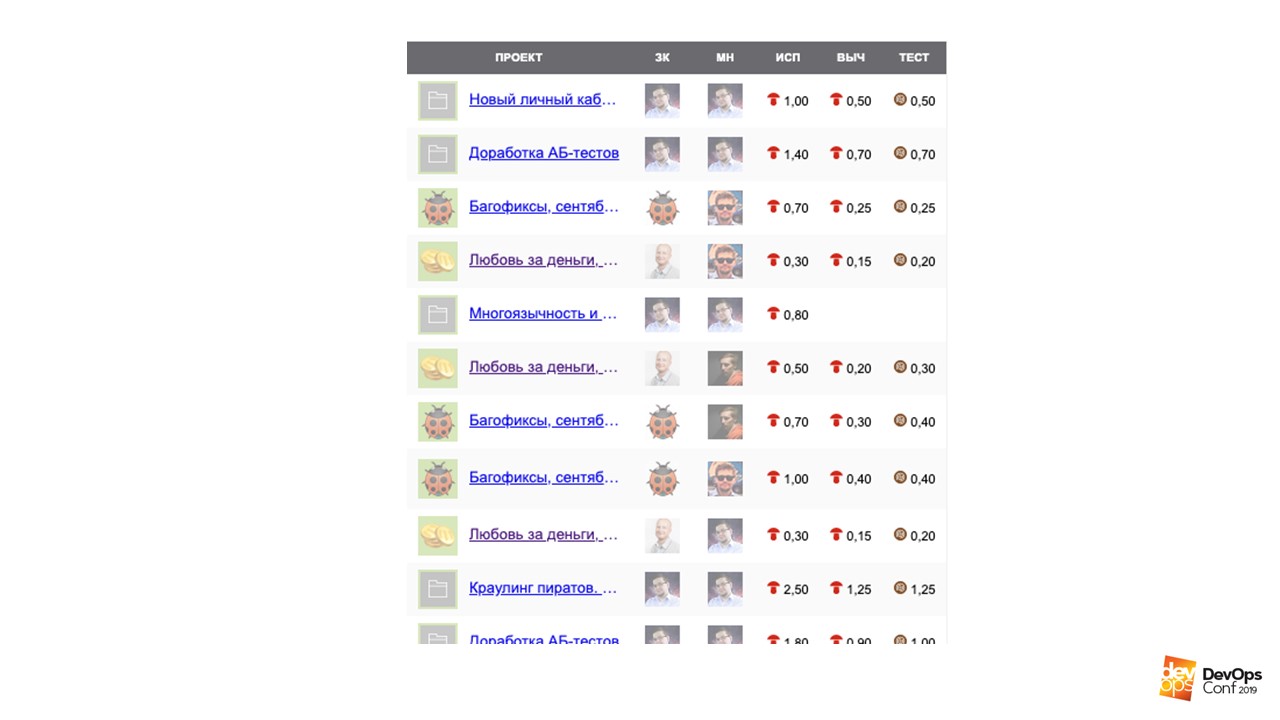
. KPI.
KPI
. . , , .
KPI. — .
- . — .
- Downtime. — .
- . , --, , . , .
KPI, — . , , KPI, .
. 90%. , . — , . . , .
-Nagios -Puppet Zabbix Grafana Ansible. « ».
Prometheus , Zabbix. Zabbix, Prometheus — . — . .
, , .
. ,
, . — . , .
. - -, - . , . . . . .
, .
2 . 3 « », — . .
. : , , , Ansible, .
. , . . .
.
— , , . .
. — , .
. , . . 2019. , , , — . .
. .
.
, - , . .
- , , .
- , .
- , , — .
- , , , — , .
. , - . , , , .
.
— , , . , , .

, — - . , .
« , ». , — , , , .
, , .
—
Ansible? , , Puppet ? — .

CI/CD? , . CI/CD , — .
., , . - ? , KPI? , -.
- — , , .
.
:DevOpsConf . — , , . DevOps- HighLoad++ 2019 . DevOps 13 AWS, Lamoda, , Kubernetes, Kubernetes, Kubernetes . « » . HighLoad++ — , -. . — .