曾几何时,当多纹理单元或硬件转换和照明(T&L)出现在GPU上时,这是一个巨大的事件。 设置固定功能管道是神奇的萨满教。 那些知道如何通过D3D9 API黑客启用和使用特定芯片的高级功能的人,都认为自己已经学过Zen。 但是时间过去了,着色器出现了。 首先,在功能和长度上都受到严格限制。 此外,越来越多的功能,更多的指令,更快的速度。 计算(CUDA,OpenCL,DirectCompute)出现了,视频卡的容量范围开始迅速扩大。
在这一系列(希望如此)的文章中,我将尝试解释并展示在开发游戏时,除了图形效果外,您如何“异常”地应用现代GPU的功能。 第一部分将专门介绍动画系统。 所描述的所有内容均基于实际经验,在实际游戏项目中已实现并可以正常工作。
噢,再来一次动画。 大约已经写和描述了一百次。 有什么复杂的? 我们将骨骼矩阵打包到缓冲区/纹理中,并在顶点着色器中将其用于蒙皮。 这已在
GPU Gems 3(第2章)中进行了描述 。 并在最近的
Unite Tech Presentation中实施 。 还有可能吗?
来自Unity的Technodemka
大量宣传,但真的很酷吗? 该中心上有
一篇文章 ,详细介绍了如何制作骨骼动画以及如何在此技术演示中起作用。 并行工作都很好,我们不考虑它们。 但是我们需要在渲染方面找出内容和方式。
在大规模战斗中,两军作战,每支军队由一种单位组成。 骷髅在左边,骑士在右边。 品种一般。 每个单元包含3个LOD(每个〜300,〜1000,〜4000个顶点),并且只有2条骨骼会影响顶点。 对于每种类型的单元,动画系统仅包含7个动画(我记得其中已经有2个)。 动画不会混入,而是从job'ax中执行的简单代码中离散切换,这在演示中得到了强调。 没有状态机。 当我们有两种类型的网格时,您可以在两个实例化的绘制调用中绘制整个人群。 正如我已经写过的,骨骼动画是基于2009年描述的技术。
创新吗? 嗯...突破? 嗯...适合现代游戏吗? 好吧,也许FPS与单位数量的比率是吹牛的。
这种方法的主要缺点(纹理前矩阵):
- 取决于帧速率。 想要两倍的动画帧-提供两倍的内存。
- 缺乏混合动画。 您当然可以制作它们,但是在皮肤着色器中,混合逻辑将形成一个复杂的混乱局面。
- 缺乏与Unity Animator状态机的绑定。 一个方便的自定义角色行为的工具,可以连接到任何蒙皮系统,但是在我们的案例中,由于第2点,一切变得非常困难(想象如何混合嵌套的BlendTree)。
通用会计准则
GPU驱动的动画系统。 这个名字刚出现。
新的动画系统有几个要求:
- 快速工作(很好,可以理解)。 您需要为成千上万个不同单位制作动画。
- 是Unity动画系统的完整(或几乎)类似物。 如果那里的动画看起来像这样,那么在新系统中它应该看起来完全一样。 能够在内置CPU和GPU系统之间切换。 这通常是调试所必需的。 当动画“笨拙”时,通过切换到经典动画器,您可以了解:这些是新系统或状态机/动画本身的故障。
- 所有动画均可在Unity Animator中自定义。 一种方便,经过测试且最重要的即用型工具。 我们将在其他地方制造自行车。
让我们重新考虑动画的准备和烘焙。 我们将不使用矩阵。 现代视频卡可以很好地与循环配合使用,除了float之外,它本身还支持int,因此我们将像在CPU上使用关键帧。
让我们看一下“动画查看器”中的动画示例:

可以看出,关键帧是分别针对位置,比例和旋转设置的。 对于某些骨骼,您需要大量骨骼,而对于少数骨骼,则需要这些骨骼,对于那些没有单独设置动画的骨骼,只需设置初始和最终关键帧即可。
位置-Vector3,四元数-Vector4,比例-Vector3。 关键帧结构将有一个共同点(为简化起见),因此我们需要4个float来适应上述任何类型。 我们还需要InTangent和OutTangent,以便根据曲率在关键帧之间进行正确的插值。 哦,是的,标准化时间不会忘记:
struct KeyFrame { float4 v; float4 inTan, outTan; float time; };
要获取所有关键帧,请使用AnimationUtility.GetEditorCurve()。
另外,我们必须记住骨骼的名称,因为在准备GPU数据的阶段必须将动画的骨骼重新映射到骨骼的骨骼中(并且它们可能不一致)。
用关键帧数组填充线性缓冲区时,我们会记住它们中的偏移量,以便找到与所需动画有关的偏移量。
现在很有趣。 GPU骨架动画。
我们准备一个大缓冲区(“动画骨架的数量” X“骨架中的骨骼数量” X“最大动画混合数量的经验系数”)缓冲区。 在其中,我们将存储动画时骨骼的位置,旋转和比例。 对于此框架中所有计划的动画骨骼,运行计算着色器。 每个线程都为其骨骼动画。
每个关键帧,无论它属于什么大小(平移,旋转,缩放),都以完全相同的方式插值(通过线性搜索进行搜索,请原谅我Knuth):
void InterpolateKeyFrame(inout float4 rv, int startIdx, int endIdx, float t) { for (int i = startIdx; i < endIdx; ++i) { KeyFrame k0 = keyFrames[i + 0]; KeyFrame k1 = keyFrames[i + 1]; float lerpFactor = (t - k0.time) / (k1.time - k0.time); if (lerpFactor < 0 || lerpFactor > 1) continue; rv = CurveInterpoate(k0, k1, lerpFactor); break; } }
该曲线是三次贝塞尔曲线,因此插值函数如下:
float4 CurveInterpoate(KeyFrame v0, KeyFrame v1, float t) { float dt = v1.time - v0.time; float4 m0 = v0.outTan * dt; float4 m1 = v1.inTan * dt; float t2 = t * t; float t3 = t2 * t; float a = 2 * t3 - 3 * t2 + 1; float b = t3 - 2 * t2 + t; float c = t3 - t2; float d = -2 * t3 + 3 * t2; float4 rv = a * v0.v + b * m0 + c * m1 + d * v1.v; return rv; }
计算骨骼的局部姿势(TRS)。 接下来,使用单独的计算着色器,混合此骨骼的所有必要动画。 为此,我们有一个缓冲区,其中包含动画索引以及最终混合中每个动画的权重。 我们从状态机获得此信息。 BlendTree内部的BlendTree的情况解决如下。 例如,有一棵树:
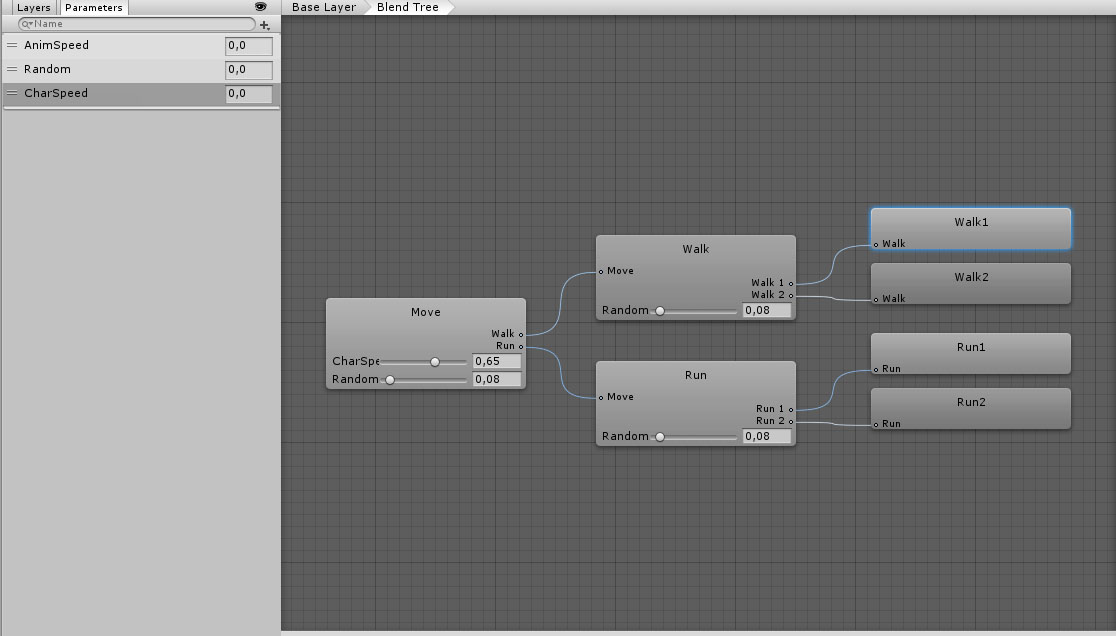
BlendTree Walk的权重为0.35,运行-0.65。 因此,骨骼的最终位置应由4个动画确定:Walk1,Walk2,Run1和Run2。 它们的权重分别为(0.35 * 0.92、0.35 * 0.08、0.65 * 0.92、0.65 * 0.08)=(0.322、0.028、0.598、0.052)。 应当注意,权重的总和应始终等于1,否则将提供魔术错误。
融合功能的“心脏”:
float bw = animDef.blendWeight; BoneXForm boneToBlend = animatedBones[srcBoneIndex]; float4 q = boneToBlend.quat; float3 t = boneToBlend.translate; float3 s = boneToBlend.scale; if (dot(resultBone.quat, q) < 0) q = -q; resultBone.translate += t * bw; resultBone.quat += q * bw; resultBone.scale += s * bw;
现在您可以转换为转换矩阵。 停下 关于骨头的等级制度完全被遗忘了。
基于骨骼的数据,我们构造了一个索引数组,其中具有骨骼索引的单元格包含其父级的索引。 在根目录下,写入-1。
一个例子:
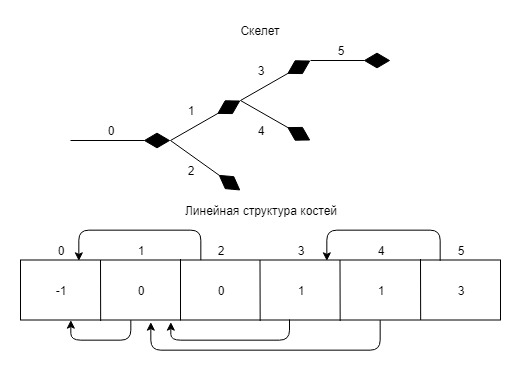
float4x4 animMat = IdentityMatrix(); float4x4 mat = initialPoses[boneId]; while (boneId >= 0) { BoneXForm b = blendedBones[boneId]; float4x4 xform = MakeTransformMatrix(b.translate, b.quat, b.scale); animMat = mul(animMat, xform); boneId = bonesHierarchyIndices[boneId]; } mat = mul(mat, animMat); resultSkeletons[id] = mat;
原则上,这里是渲染和混合动画的所有要点。
GPSM
GPU供电的状态机(您猜对了)。 上面描述的动画系统可以与Unity动画状态机完美配合,但是所有的努力都是没有用的。 可以计算每帧成千上万个动画(如果不是成百上千个),UnityAnimator将不会提取成千上万个同时工作的状态机。 嗯...
Unity中的状态机是什么? 这是状态和转换的封闭系统,由简单的数值属性控制。 每个状态机彼此独立运行,并针对同一组输入数据运行。 等一下 对于GPU和计算着色器而言,这是一项理想的任务!
烘烤阶段首先,我们需要收集所有状态机数据并将其放置在GPU友好的结构中。 这是:状态(状态),过渡(过渡)和参数(参数)。
所有这些数据都放在线性缓冲区中,并通过索引进行寻址。
每个计算线程都考虑其状态机。
AnimatorController提供了到所有必需的内部状态机结构的接口。
状态机的主要结构:
struct State { float speed; int firstTransition; int numTransitions; int animDefId; }; struct Transition { float exitTime; float duration; int sourceStateId; int targetStateId; int firstCondition; int endCondition; uint properties; }; struct StateData { int id; float timeInState; float animationLoop; }; struct TransitionData { int id; float timeInTransition; }; struct CurrentState { StateData srcState, dstState; TransitionData transition; }; struct AnimationDef { uint animId; int nextAnimInTree; int parameterIdx; float lengthInSec; uint numBones; uint loop; }; struct ParameterDef { float2 line0ab, line1ab; int runtimeParamId; int nextParameterId; }; struct Condition { int checkMode; int runtimeParamIndex; float referenceValue; };
- 状态包含状态播放的速度,以及根据状态机转换到其他状态的条件的索引。
- 转换包含状态索引“从”和“到”。 过渡时间,退出时间以及进入该状态的一系列条件的链接。
- CurrentState是一个运行时数据块,其中包含有关状态机当前状态的数据。
- AnimationDef包含对动画的描述,并带有BlendTree与其他与动画相关的链接。
- ParameterDef是控制状态机行为的参数的描述。 Line0ab和Line1ab是线方程的系数,可通过参数值确定动画的权重。 从这里:
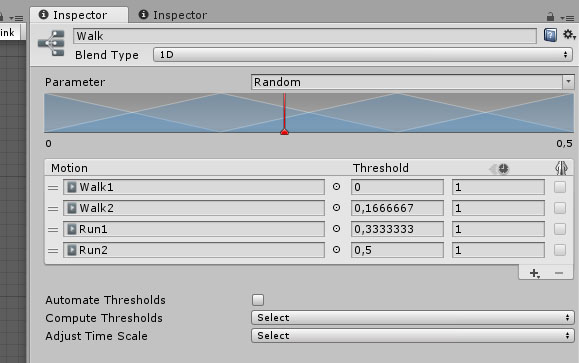
- 条件-用于比较参数的运行时值和参考值的条件的规范。
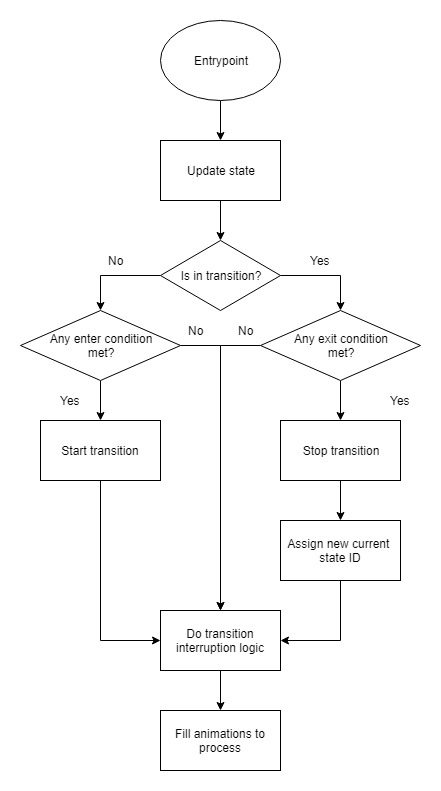
运行阶段可以使用以下算法显示每个状态机的主周期:
Unity动画器中有4种类型的参数:float,int,bool和触发器(bool)。 我们将它们全部以浮点形式呈现。 设置条件时,可以选择
六种比较类型之一。 如果==等于。 IfNot ==不等于。 因此,我们将仅使用4。运算符索引将传递到Condition结构的checkMode字段。
for (int i = t.firstCondition; i < t.endCondition; ++i) { Condition c = allConditions[i]; float paramValue = runtimeParameters[c.runtimeParamIndex]; switch (c.checkMode) { case 3: if (paramValue < c.referenceValue) return false; case 4: if (paramValue > c.referenceValue) return false; case 6: if (abs(paramValue - c.referenceValue) > 0.001f) return false; case 7: if (abs(paramValue - c.referenceValue) < 0.001f) return false; } } return true;
要开始过渡,所有条件都必须为真。 奇怪的大小写标签只是(int)AnimatorConditionMode。 中断逻辑是中断和回滚转换的棘手逻辑。
在更新状态机的状态并滚动delta t帧上的时间戳后,该准备有关在此帧中应读取哪些动画以及相应权重的数据了。 如果单元模型不在框架中(视锥剔除),则跳过此步骤。 我们为什么要考虑看不见的动画? 我们遍历混合树的源状态,混合树的目标状态,添加它们中的所有动画,然后根据从源到目标的过渡时间(过渡时间)计算权重。 借助准备好的数据,GPAS可以发挥作用,并为游戏中的每个动画实体计数动画。
单元控制参数来自单元控制逻辑。 例如,您需要启用运行,设置CharSpeed参数,并且正确配置的状态机可以平滑地混合从“行走”到“运行”的过渡动画。
自然,与Unity Animator的完全类比是行不通的。 如果未在文档中描述内部工作原理,则必须颠倒并进行类似的处理。 某些功能尚未完成(可能尚未完成)。 例如,BlendTree中的BlendType仅支持1D。 从原则上讲,制作其他类型并不困难,只是现在没有必要。 没有动画事件,因为必须使用GPU进行回读,并且“正确”回读将落后几帧,这并不总是可以接受的。 但这也是可能的。
渲染
单元渲染通过实例化完成。 根据SV_InstanceID,在顶点着色器中,我们获取影响顶点的所有骨骼的矩阵,并对其进行变换。 绝对没有异常:
float4 ApplySkin(float3 v, uint vertexID, uint instanceID) { BoneInfoPacked bip = boneInfos[vertexID]; BoneInfo bi = UnpackBoneInfo(bip); SkeletonInstance skelInst = skeletonInstances[instanceID]; int bonesOffset = skelInst.boneOffset; float4x4 animMat = 0; for (int i = 0; i < 4; ++i) { float bw = bi.boneWeights[i]; if (bw > 0) { uint boneId = bi.boneIDs[i]; float4x4 boneMat = boneMatrices[boneId + bonesOffset]; animMat += boneMat * bw; } } float4 rv = float4(v, 1); rv = mul(rv, animMat); return rv; }
总结
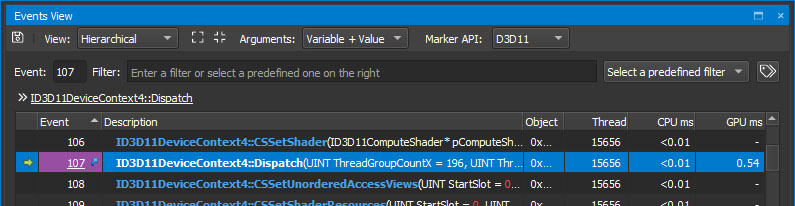
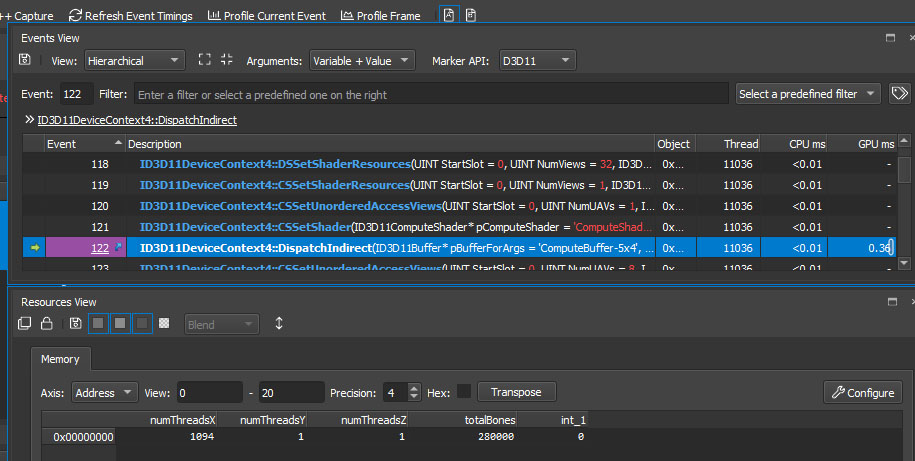
这个农场工作快吗? 显然比使用矩阵采样纹理要慢,但是我仍然可以显示一些数字(GTX 970)。
这是50,000个状态机:
这是280,000个动画骨骼:
设计和调试所有这些都是一个真正的难题。 一堆缓冲区和偏移量。 一堆组件及其相互作用。 有时候,当您为某问题打了头几天时,双手就掉下来了,但是您找不到问题所在。 当一切都可以在测试数据上正常运行时,这尤其“不错”,但是在真正的“战斗”情况下,没有任何动画故障。 Unity状态机的操作与其自身状态之间的差异也不是立即可见的。 通常,如果您决定自己制作一个模拟,那么我不会羡慕您。 实际上,GPU下的整个开发都是值得抱怨的。
PS:我想在Unite TechDemo开发人员的花园里扔一块石头。 他们在舞台上有大量相同的废墟和桥梁模型,并且没有以任何方式优化其渲染。 相反,他们通过勾选“静态”来尝试。 但是现在,在16位索引中,您无法填充很多几何图形(3次,2017年,哈哈),因为模型是高度多边形的,所以没有任何东西融合在一起。 我为所有着色器都设置了“启用实例化”,而未选中“静态”。 没有明显的提升,但是,该死,您正在做一个技术演示,为每一个FPS奋斗。 你不能那样胡扯。
是 *** Summary *** Draw calls: 2553 Dispatch calls: 0 API calls: 8378 Index/vertex bind calls: 2992 Constant bind calls: 648 Sampler bind calls: 395 Resource bind calls: 805 Shader set calls: 682 Blend set calls: 230 Depth/stencil set calls: 92 Rasterization set calls: 238 Resource update calls: 1017 Output set calls: 74 API:Draw/Dispatch call ratio: 3.28163 298 Textures - 1041.01 MB (1039.95 MB over 32x32), 42 RTs - 306.94 MB. Avg. tex dimension: 1811.77x1810.21 (2016.63x2038.98 over 32x32) 216 Buffers - 180.11 MB total 17.54 MB IBs 159.81 MB VBs. 1528.06 MB - Grand total GPU buffer + texture load. *** Draw Statistics *** Total calls: 2553, instanced: 2, indirect: 2 Instance counts: 1: 2: 3: 4: 5: 6: 7: 8: 9: 10: 11: 12: 13: 14: >=15: ******************************************************************************************************************************** (2)
已成为 *** Summary *** Draw calls: 1474 Dispatch calls: 0 API calls: 11106 Index/vertex bind calls: 3647 Constant bind calls: 1039 Sampler bind calls: 348 Resource bind calls: 718 Shader set calls: 686 Blend set calls: 230 Depth/stencil set calls: 110 Rasterization set calls: 258 Resource update calls: 1904 Output set calls: 74 API:Draw/Dispatch call ratio: 7.5346 298 Textures - 1041.01 MB (1039.95 MB over 32x32), 42 RTs - 306.94 MB. Avg. tex dimension: 1811.77x1810.21 (2016.63x2038.98 over 32x32) 427 Buffers - 93.30 MB total 9.81 MB IBs 80.51 MB VBs. 1441.25 MB - Grand total GPU buffer + texture load. *** Draw Statistics *** Total calls: 1474, instanced: 391, indirect: 2 Instance counts: 1: 2: ******************************************************************************************************************************** (104) 3: ************************************************* (40) 4: ********************** (18) 5: ****************************** (25) 6: ********************************************************************************************* (76) 7: *********************************** (29) 8: ************************************************** (41) 9: ********* (8) 10: ************** (12) 11: 12: ****** (5) 13: ******* (6) 14: ** (2) >=15: ****************************** (25)
PPS在任何时候,游戏都主要受CPU限制,即 CPU跟不上GPU。 逻辑和物理太多。 将游戏逻辑的一部分从CPU转移到GPU,我们卸载第一个并加载第二个,即 使绑定GPU的情况更有可能发生。 因此,文章标题。