有时会发生以下情况:
-来吧,我们跌倒了。 如果您现在不抬高它,它将显示在电视上。
而我们要去。 在晚上。 到该国的另一边。
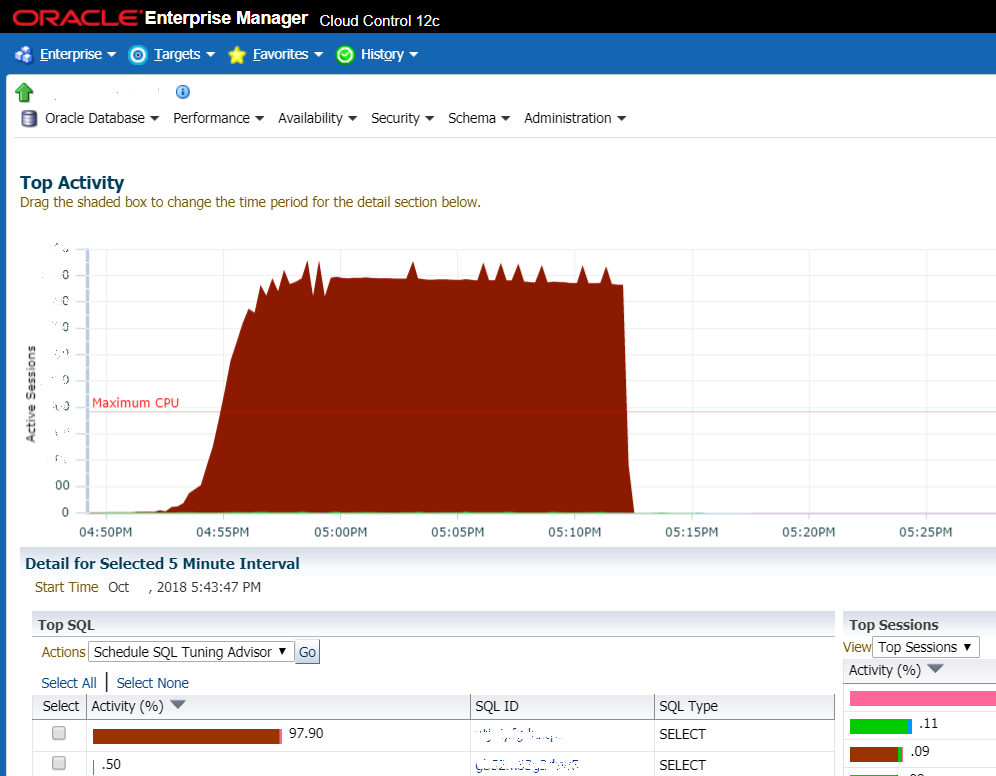 没有运气的情况:该图显示DBMS的负载急剧增加。 通常,这是系统管理员要看的第一件事,并且这是驴来的第一个迹象
没有运气的情况:该图显示DBMS的负载急剧增加。 通常,这是系统管理员要看的第一件事,并且这是驴来的第一个迹象但是更多时候我们在谈论一些典型的事情。 例如,客户面临着糟糕的工作流程系统。 在星期一和星期二,系统崩溃了,他们重新启动了服务器,然后一切正常。 数据库令人窒息。 他们想购买设备(既长又昂贵),他们打电话给我们来计算估算值。 我们计算了他们的估算值,同时提供了确切的估算速度。 在三到四个小时内,问题的根源就定位了。 我们发现这些是缓慢的数据库查询和次优的索引方案。 我们创建了缺失的索引,并在Oracle中使用查询优化器进行了查找,一些问题需要更改代码-我们更改了搜索条件(不更改功能),并使用了预先计算的视图替换了某些请求。 如果他们在数据库中有一个普通人-他们可以自己做。 但是数据库不是正常人,而是每六个月由出色的甲骨文专家审核一次-他们发布了有关设置和硬件的一般建议。
怎么发生的
根据安全性要求,细节有所更改。 在数百个工业设施中都有一个文档管理系统。 她有时会跌倒,工作会增加。 也就是说,对象可以工作,但是没有一个文档通过且没有签名。 尤其是原材料,薪水和订单的运输,每班生产什么以及多少。 每年秋天对于CIO来说都是痛苦,泪水和干邑白兰地,因为这对他来说很难:很多损失。
顺便说一句,导演过去仅六个月大。 去年持续了。 他们俩都在导演三代前推出的系统上工作。 从头开始的第二个人试图介绍自己的个人,但没有时间被解雇。 情况很现实。
乍一看,性能不足。 负载配置文件是锁(等待类“应用程序”)。 也就是说,争夺战线。 我们开始调查事件。 为每个用户事务打开一个会话。 由于用户必须至少放下“熟悉的”签证,因此它迅速进入阻止订单的状态,根据该状态写出了要执行的任务和指令。
最后一种情况-他们针对员工应接受检查的频率制定了新标准。 最高层人事官员写了一条命令,并将其发送给所有组织。 也就是说,每个产品的每个员工。 成千上万的用户收到了签证交易。 他们开始几乎同时打开订单,在数据库中放置了一长串锁。 由于不是最理想的代码,结果发生了“小”溢出,一切都被阻塞了。 大约有4万名用户无法使用。 从备份方案-仅电话和邮件。 生产不会停止,但是效率会大大下降,这会造成特定的财务损失。 然后,从每个企业亲自通过语音向IT主管打电话。 实际上,他们具有SLA,但尚未达成协议。 这种情况具有纯俄国历史的最后特征。
通过深入剖析,分析阻塞对象的逻辑(排除了设置了锁的不必要对象),解决了“被鞭打”的问题,尽管这是不必要的,因为对象不会更改(例如,目录,访问权限等)。 然后,在几个月后,代码的主要部分被重构。
如何搜索这些代码段?
除了标准工具(线程转储,日志,指标,AWR,来自系统表示的数据等)之外,我们还使用更多民用工具,包括商业工具。
示例1:缓慢的事务日志已经收到用户对期刊运行缓慢的投诉(这是一个已知且常见的问题)。
我们找到问题视图,然后在deal_journal_view视图的操作中查找请求。 我们搜索其中有此类请求的所有交易。

对于每个操作,您都可以查看其详细信息,并使用执行参数查找请求本身,从而可以分析请求的操作,验证和调整计划。 找到了特定的慢请求。

他们自己分析并提出了优化方案。 然后,才可以跟踪这组业务操作(查看事务日志),创建事务类型并配置警报。
 示例2:查找导致用户工作缓慢的原因1
示例2:查找导致用户工作缓慢的原因1用户1收到有关该应用程序运行缓慢的投诉。 我们看:

搜索所有用户操作,并按持续时间排序。 接下来,分析最慢的操作,并检测到对外部系统(SAP)的慢查询。

将其指向相邻的团队,并将其修复。
示例3:另一个用户抱怨应用程序运行缓慢我们以相同的方式看。 这次,我们看到了对外部签名服务的大量呼叫。 事实证明,在某些条件下,他们两次签署了一些文件。 已更正。
 例子4:没有足够的细节时
例子4:没有足够的细节时有时,为了分析代码的更复杂部分,我们求助于使用自定义探查器,这使我们能够更深入地研究应用程序的行为。 例如,就像这里:在系统中的逻辑操作期间有很多难以理解的逻辑。 我们弄清楚了逻辑,添加了两个缓存,优化了请求。
 示例5:更多刹车
示例5:更多刹车用户抱怨合同卡工作缓慢。

分析了一周的缓慢用户操作(参数='userlogin =“ ...”')。 大多数问题与合同下的搜索查询有关,但也发现了使用证件卡的操作。 大部分时间都花在创建大量任务上。 找到已存储任务的标识符(屏幕快照中的“参数值”列)及其保存时间。
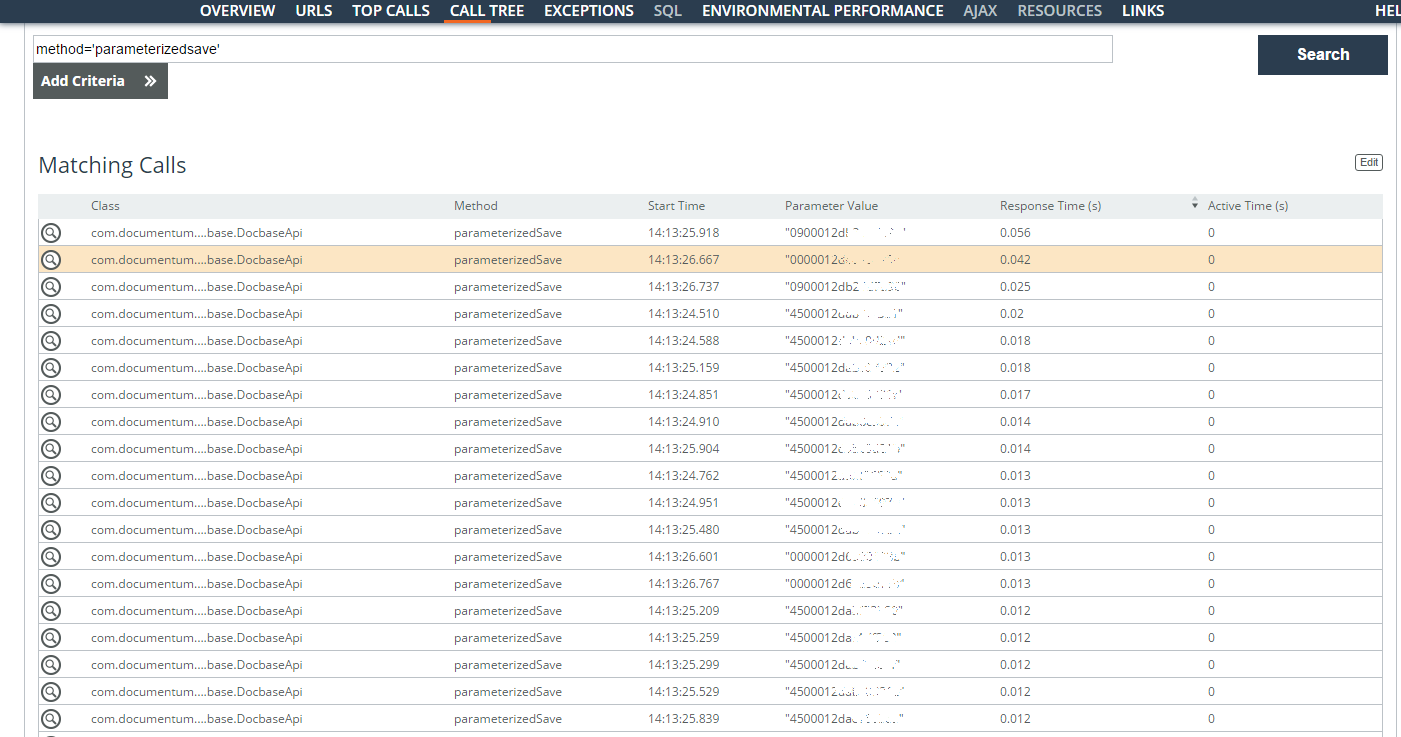
从逻辑上讲,可以异步创建它们,但现在将它们排队,并且需要特殊的锁。 在这里,您已经需要深入研究体系结构。
就是这么简单:您需要找到一个瓶颈-就是这样吗?
不行
再说一次。
这都是对症状的治疗。
迅速挽救局势,这是正确的做法,现在这种情况正在大火中。 然后放入流程。 使用系统的人很少不了解他们在做什么。 只是他们要么需要证明减少技术债务的手段(没有人相信),要么将流程更改为更现代的流程(也没有资源),或者做类似的事情。
总的来说,我们来自最高层,看到客户的痛苦。 然后我们抓住了瓶颈。 有时,它以引入监视系统结束。 而且,如果客户知道有必要更改软件开发流程,那么该阶段就开始了“漫长,昂贵,甚至一点都不出色”。
我们查看两个或三个项目,选择所有文档,存储库,采访人员。 接下来,我们准备用于新文档的模板,准备程序,查看用于管理需求和测试的工具。 并且我们帮助实施。 有时仅就更改内容提出意见就足够了,有经验的首席信息官(CIO)有了预算。 有时有必要直接注入鲜血和眼泪。
从错误的架构选择到工作流的某些功能开始,任何事情都可能成为痛苦。
这些示例与全国各地不同公司的流程游戏有关。
关于数据库优化,这是一个典型示例。 有一个医疗系统(跌倒者之一)。 他们叫我们去观看。 当他们已经关闭了所有模块(医生的工作流程除外)时,我们到达了,以便至少可以进行分析并通过注册表进行记录。 尤其是在线记录是禁用的模块之一。 我设法在一周内解决了所有问题。 最初,客户认为问题出在应用程序层:超时失败,线程挂起。 我们发现问题出在数据库上。 有一个复杂的结构,按日和月进行了大量的剖切。 原来,他们忘记了几个索引,开发人员并不完全知道随着时间的推移会变成什么-这就是结果。 大约相同的一组操作加上搜索限制(当您需要在某个日期范围内卸载某些内容时,最好在这些日期之间查找而不是在整个数据库中查找)。
显然,这种优化并不总是能够解决问题。 例如,(按体系结构)能源部门:客户要求查看系统挂了什么。 交付时一切都飞起来了,但是几年之后,文件又增加了很多,一切都制动得很好。 客户在操作员的工作场所坐在秒表旁说:现在,此操作需要31秒,我们需要3秒。这是40秒,我们需要2秒。依此类推。 显然,用这种方法测量不是很正确,但是任务很具体,可以很容易地以客观标准的形式提出。 我们没有做任何事情,大约花了六个月的时间来“清理”。 在大多数情况下,逻辑已转移到异步执行,一些数据库已更改为noSQL,安装了Solar搜索引擎,在某一部分中,有必要选择最热的数据库并将其存储在内存中。 结果,大约90%的需求都已解决,但在某些地方,它们无法减少延迟。 这是第三方库的工作,平台的物理限制等。 所有这些都通过监视进行监视,并且能够清楚地证明确切的位置和速度。
为什么还需要这种监视?
我们使用不同的监控软件来快速找到抑制过程并对其进行优化。 其中一位主要客户的IT团队研究了我们如何做到这一点,并要求在其中一个设施中将其作为永久性工具来实施。 好的,监视所有流程和节点,为任务定制其系统,工作了将近四个月,但制作了一套支持它们的工具。 有8万用户,内部有第一和第二行,经常有第三行-有承包商,也有内部。
第二行就是这套工具。 现在,在大约50%的情况下,他们使用监视来诊断,搜索瓶颈和冻结原因,以便他们自己的开发人员可以看到,理解和优化。 快速确定问题原因可以节省大量支持时间。 试点后按交易规模扩大。 那花了四个月的时间:任何行动都要进行业务运营。 打开证件卡是一项商业交易。 登录工作流系统是一项业务交易。 报告上传或搜索。 描述了四个月中进行的1,500次此类业务操作,以了解在何处有效。 监视之前看到了http调用,看到了被调用的方法和函数,看到了特定的请求。 在此之前,只有开发人员才知道这是协议协议或搜索。 为了使监视系统显示不同支持热线和业务的相关数据,我们设置了所有这些捆绑包。

该公司还开始削减自己的IT开发报告。 日志上没有更多人特别选择。
顺便说一下,关于为什么需要
APM类系统的所有内容以及如何选择它们,我们将
在10月1日的
网络研讨会上讨论。
技术方面还有什么“插头”?
还有更多示例。 一家大型外国银行,在俄罗斯设有代表处。 我们支持Oracle DB和Oracle Weblogic。 在系统中观察到生产率逐渐下降,业务操作进行得越来越慢,操作员的工作效率越来越低,并且在导入和与NSI同步期间,所有操作都完全冻结了。 在这种情况下,我们使用标准的Java和Oracle工具来收集数据:我们收集线程转储,在免费服务中对其进行分析,或者使用自行编写的分析工具,查看AWR,跟踪SQL查询的执行,分析计划和执行统计信息。 结果,除了优化索引组成和调整查询计划等标准操作外,我们还建议通过划分数据来引入分区。 结果分为两个部分:历史部分(保留在HDD上)和可操作部分-放置在SSD上。 在此之前,很难理解什么数据与什么有关,因为无论是在长报告还是在常规操作中,历史数据仍然必须定期下降。 正确分离的结果是,超过98%的主要业务没有纳入缓慢的历史数据中。 重要的是,无需进入系统代码。 碰巧我们的某些建议要求更改应用程序代码,但我们不支持,因此我们通常会同意。
第二个例子:轻工业和快速消费品领域的国际制造商。 主站点的停机时间造成的损失约为2000万卢布。 基础上的平均负载为200 AS(活动会话),峰值最大为800-1000。 查询优化器会失去头脑,计划开始变得不那么好,缓冲器竞争开始激烈竞争。 没有人会因此而感到安全,但是您可以降低可能性:在两个月的时间里,我们从PL / SQL代码的侧面监视了系统,分析了负载分布,熄灭了火灾,调整了索引和分区方案,数据处理逻辑。 在这里,您需要了解,在不断发展的系统中,应该定期进行这样的审核,尽管压力测试会有所帮助,但并非总是如此。 公司通过邀请第三方甲骨文专家进行审计,但是很少有审计员沉入业务逻辑层次,并准备在与开发人员进行交互时深入研究数据。 我们做。
好吧,我想说的是,问题并不总是缺乏定期清洁或适当的支持。 通常在过程中存在问题。
为什么我们需要他们的实时开发人员提供此类服务?
因为企业喜欢决策,而不是流程。 这是主要原因。
第二个问题是,并不是每个人都可以分配资源来搜索应用程序中的瓶颈,特别是如果它是第三方应用程序。 远非总是一支团队,而是拥有必要能力的人。 现在,我们拥有系统工程师,网络工程师,Oracle和1C专家,能够优化Java的人员以及我们团队中的前端。
好吧,如果您有兴趣深入了解细节,那么
10月1日将举行我们的网络研讨会 ,讨论在一切落空之前您可以提前做些什么。 这是我发问的邮件-sstrelkov@croc.ru。