无需专门代表FIAS基础:

您可以通过单击
链接进行下载,该数据库已打开,其中包含俄罗斯所有对象的地址(地址寄存器)。 对数据库的关注是由于该数据库包含的文件非常庞大。 因此,例如,最小为2.9 GB。 如果您在只有8 GB RAM的计算机上工作,建议停下来看看熊猫是否可以应付。 而且,如果您无法应付,可以使用哪些选项为熊猫喂食该文件。
亲切的我,我从未遇到过这个基础,这是另外一个障碍,因为 其中显示的数据格式尚不清楚。
在下载带有基础的fias_xml.rar存档后,我们从中获取文件-AS_ADDROBJ_20190915_9b13b2a6-b3bd-4866-bd1c-7ab966fafcf0.XML。 该文件为xml格式。
为了在熊猫中更方便地工作,建议将xml转换为csv或json。
但是,所有尝试转换第三方程序和python本身的尝试都会导致“ MemoryError”错误或冻结。
嗯 如果我剪切文件并将其部分转换怎么办? 这是个好主意,但是所有“工具”也都尝试将整个文件读入内存并挂起,遵循“工具”路径的python本身并没有将其剪切。 8 GB显然不够吗? 好吧,让我们看看。
Vedit程序
您必须使用第三方vedit程序。
该程序允许您读取2.9 GB的xml文件并使用它。
它还允许您拆分它。 但是有一个小技巧。
如您所见,在读取文件时,该文件除其他外还有一个开放的AddressObjects标签:

因此,创建此大文件的一部分时,您一定不要忘记关闭它(标记)。
也就是说,每个xml文件的开头将如下所示:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
和结束:
</AddressObjects>
现在,切断文件的第一部分(其余部分的步骤相同)。
在vedit程序中:
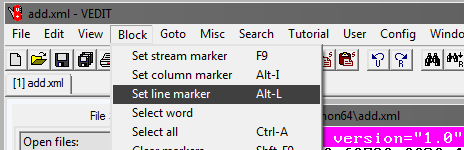
接下来,选择转到和行号。 在打开的窗口中,输入行号,例如1,000,000:

接下来,您需要调整选定的块,以使其在结束标记之前捕获数据库中的对象:
如果后续对象略有重叠也可以。
接下来,在vedit程序中,保存选定的片段-文件,另存为。
以同样的方式,我们创建文件的其余部分,以100万行为增量标记选择块的开始和结束。
如此一来,您应该获得第4个xml文件,其大小约为610 MB。
我们最终确定xml部分
现在,您需要在新创建的xml文件中添加标签,以使它们读为xml。
依次打开vedit中的文件,并在每个文件的开头添加:
<?xml version="1.0" encoding="utf-8"?><AddressObjects>
最后:
</AddressObjects>
因此,我们现在有分割源文件的4个xml部分。
Xml到csv
现在,通过编写python程序将xml转换为csv。
程式码
。
使用该程序,您需要将所有4个文件转换为csv。
文件大小将减小,每个将为236 MB(与xml中的610 MB相比)。
原则上,现在您已经可以通过excel或记事本++与它们合作。
但是,文件仍然是第4个而不是第4个,并且我们还没有达到目标-以大熊猫处理文件。
将文件胶合到一个
在Windows上,这可能是一项艰巨的任务,因此我们将在python中使用名为csvkit的控制台实用程序。 作为python模块安装:
pip install csvkit
*实际上,这是一整套实用程序,但是在那里需要一个实用程序。
在控制台中输入了要粘贴的文件的文件夹后,我们将粘贴到一个文件中。 由于所有文件都没有标题,因此我们在粘贴时将分配标准列名称:a,b,c等:
csvstack -H fias-0-10.csv fias-10-20.csv fias-20-30.csv fias-30-40.csv > joined2.csv
输出是完成的csv文件。
让我们在熊猫上优化内存使用
如果您立即将文件上传到熊猫
import pandas as pd import numpy as np gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a') print (gl.info(memory_usage='deep'))
并检查将占用多少内存,结果可能会令人意外地感到惊讶:

3 GB! 而且尽管有这样的事实,当读取数据时,第一列“作为索引列*”仍然存在,因此卷甚至更大。
*默认情况下,pandas设置自己的列索引。
我们将使用前
一篇文章和
文章中的方法进行优化:
-类别中的对象;
-uint8中的int64;
-float32中的float64。
为此,在读取文件时,添加dtypes并读取代码中的列将如下所示:
gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' })
现在,通过打开pandas文件,内存使用将是明智的:

如果需要,可以保留将其添加到csv文件中的实际行名称,以使数据有意义:
AOID,AOGUID,PARENTGUID,PREVID,FORMALNAME,OFFNAME,SHORTNAME,AOLEVEL,REGIONCODE,AREACODE,AUTOCODE,CITYCODE,CTARCODE,PLACECODE,STREETCODE,EXTRCODE,SEXTCODE,PLAINCODE,CODE,CURRSTATUS,ACTSTATUS,LIVESTATUS,CENTSTATUS,OPERSTATUS,IFNSFL,IFNSUL,OKATO,OKTMO,POSTALCODE
*您可以用此行替换列名,但随后必须更改代码。
保存熊猫文件的第一行
gl.head().to_csv('out.csv', encoding='ANSI',index_label='a')
看看在excel中发生了什么:

用于通过数据库优化打开csv文件的程序代码:
代号 import os import time import pandas as pd import numpy as np # : object-category, float64-float32, int64-int gl = pd.read_csv('joined2.csv',encoding='ANSI',index_col='a', dtype ={ 'b':'category', 'c':'category','d':'category','e':'category', 'f':'category','g':'category', 'h':'uint8','i':'uint8','j':'uint8', 'k':'uint8','l':'uint8','m':'uint8','n':'uint16', 'o':'uint8','p':'uint8','q':'uint8','t':'uint8', 'u':'uint8','v':'uint8','w':'uint8','x':'uint8', 'r':'float32','s':'float32', 'y':'float32','z':'float32','aa':'float32','bb':'float32', 'cc':'float32' }) pd.set_option('display.notebook_repr_html', False) pd.set_option('display.max_columns', 8) pd.set_option('display.max_rows', 10) pd.set_option('display.width', 80) #print (gl.head()) print (gl.info(memory_usage='deep')) # def mem_usage(pandas_obj): if isinstance(pandas_obj,pd.DataFrame): usage_b = pandas_obj.memory_usage(deep=True).sum() else: # , , usage_b = pandas_obj.memory_usage(deep=True) usage_mb = usage_b / 1024 ** 2 # return "{:03.2f} " .format(usage_mb)
总之,让我们看一下数据集的大小:
gl.shape
(3348644, 28)
330万行,28列。
底线:初始csv文件大小为890 MB,为了与熊猫一起使用而进行了“优化”,它占用了1.2 GB的内存。
因此,通过粗略的计算,可以假设可以以“打开”熊猫的方式打开大小为7.69 GB的文件,而之前已经对其进行了“优化”。