什么是End2End语音识别,为什么需要它? 与经典方法有何不同? 为什么要训练一个好的基于End2End的模型,我们需要大量的数据-在我们今天的帖子中。
语音识别的经典方法
在讨论End2End方法之前,您应该首先讨论语音识别的经典方法。 他是什么样的人?

特征提取
实际上,这不是动作块的完全线性序列。 让我们更详细地介绍每个块。 我们有某种输入语音,它落在第一个块上-Feature Extraction。 这是从语音中提取信号的块。 必须牢记,言语本身是一件相当复杂的事情。 您需要能够以某种方式使用它,因此存在用于从信号处理理论中分离特征的标准方法。 例如,梅尔倒谱系数(MFCC)等。
声学模型
下一个组件是声学模型。 它可以基于深度神经网络,也可以基于高斯分布和隐马尔可夫模型的混合。 它的主要目标是从声学信号的一部分中获得这一部分中各种音素的概率分布。
接下来是解码器,它根据最后一步的结果在图中搜索最可能的路径。 评分是识别的最终方法,其主要任务是重新权衡假设并得出最终结果。
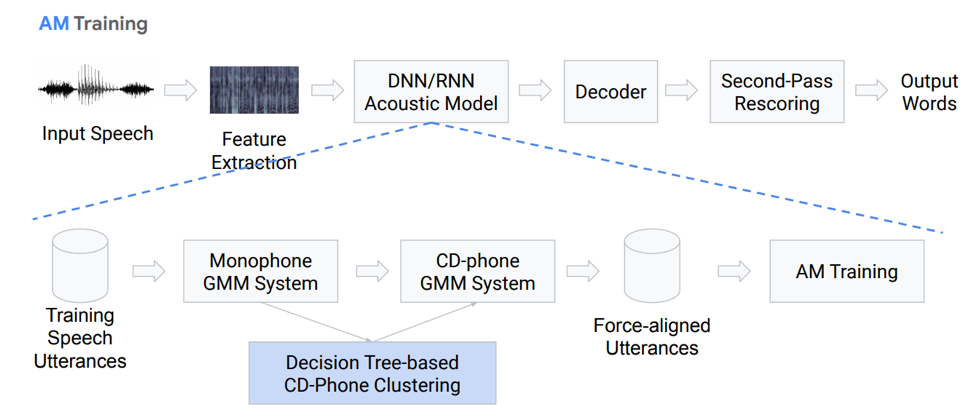
让我们详细介绍一下声学模型。 她是什么样的人? 我们有一些语音记录基于GMM(单声道Gausovy混音)或HMM进入特定系统。 也就是说,我们使用音素形式表示,我们使用单音素,即上下文无关音素。 此外,我们根据上下文相关的音素对高斯分布进行混合。 它使用基于决策树的聚类。
然后,我们尝试建立对齐方式。 这种完全非平凡的方法使我们可以获得声学模型。 听起来不是很简单,实际上更复杂,有很多细微差别和功能。 但是结果是,经过数百小时训练的模型能够很好地模拟声学。

解码器
什么是解码器? 该模块根据HCLG图选择最可能的过渡路径,该模块包括4个部分:
基于HMM的H模块
C上下文依赖模块
l发音模块
G语言模型模块
我们在这四个分量上建立一个图表,在此基础上,我们将把声学特征解码成某些言语结构。
加号或减号很明显,经典方法相当麻烦且困难,难以训练,因为它由大量独立的部分组成,您需要为每个部分准备自己的数据以进行训练。
II End2End方法
那么End2End语音识别是什么?为什么需要它? 这是一个确定的系统,旨在直接在字素(字母)或单词的序列中反映声学符号的序列。 您也可以说这是一个优化标准的系统,该标准直接影响质量评估的最终指标。 例如,我们的任务专门是单词错误率。 正如我所说,只有一种动机-将这些复杂的多级组件呈现为一个简单的组件,可以直接从输入语音中显示,输出单词或字素。
模拟问题
在这里,我们马上遇到一个问题:语音是一个序列,在输出端我们还需要给出一个序列。 直到2006年,还没有足够的方法对此进行建模。 建模的问题是什么? 每个记录都需要创建复杂的标记,这意味着我们在什么时候发音特定的声音或字母。 这是一个非常麻烦的复杂布局,因此尚未对此主题进行大量研究。 2006年,Alex Graves发表了一篇有趣的文章“连接主义的时间分类”(CTC),从原则上解决了这个问题。 但是这篇文章已经发表,当时没有足够的计算能力。 真正可行的语音识别算法出现的时间要晚得多。
总的来说,我们有:CTC算法由Alex Graves于13年前提出,它是一种无需复杂的标记即可进行训练/训练声学模型的工具-输入和输出序列帧的对齐。 基于此算法,最初出现的工作尚未完成end2end;因此发出了音素。 值得注意的是,基于STS的上下文相关音素在识别言论自由方面取得了最好的结果之一。 但也值得注意的是,这种直接应用于单词的算法目前仍然落后。

什么是STS
现在,我们将更详细地讨论STS是什么,以及为什么需要它,它执行什么功能。 为了训练声学模型而无需在声音和转录之间进行逐帧对齐,STS是必需的。 逐帧对齐是指我们说声音中的特定帧与转录中的这种帧相对应。 我们有一个传统的编码器,它接受声学符号作为输入-它给出某种状态的隐藏,在此基础上,我们可以使用softmax获得条件概率。 编码器通常由LSTM或RNN的其他变体的几层组成。 值得注意的是,STS除了普通字符之外还具有称为空字符或空白符号的特殊字符。 为了解决由于以下事实而引起的问题:并非每个声音帧都有一个转录帧,反之亦然(也就是说,我们的字母或声音听起来要长得多,而声音又短又重复),因此这个空白符号。
STS本身旨在最大化字符序列的最终概率并概括可能的对齐方式。 由于我们想在神经网络中使用该算法,因此我们必须了解它的前进和后退操作方式是如何工作的。 我们将不讨论此算法运算的数学依据和特征,否则将花费很长时间。
我们所拥有的:基于STS算法的第一个ASR于2014年问世。 同样,Alex Graves提出了一种基于逐字符STS的出版物,该出版物直接显示单词序列中的输入语音。 他们在本文中发表的评论之一是,使用外部声音模型对于获得良好的结果很重要。
5种改进算法的方法
上述算法有许多不同的变化和改进。 例如,这是最近最受欢迎的五个。
•在第一遍解码中包含语言模型
o [Hannun等人,2014] [Maas等人,2015]:使用LM直接进行首遍解码,而不是像[Graves&Jaitly,2014]那样进行记录
o [Miao等,2015]:EESEN框架,用于使用WFST进行解码,开源工具包
•在GPU上进行大规模培训; 数据扩充 几种语言
o [Hannun等,2014; DeepSpeech] [Amodei et al。,2015; DeepSpeech2]:大规模GPU培训; 数据扩充 普通话和英语
•使用长单位:用单词代替字符
o [Soltau等人,2017]:单词级CTC目标,经过125,000小时的语音训练。 即使不使用LM,性能也接近或优于常规系统!
o [Audhkhasi et al。,2017]:配电板上的直接声学到文字模型
值得关注的是将DeepSpeach的实现作为端到端CTC解决方案的一个很好的例子,以及使用语言级别的变体。 但是有一个警告:要训练这样的模型,您需要125,000小时的标记数据,实际上在严酷的现实中很多。
关于STS的重要注意事项
- 问题或遗漏。 为了提高效率,对独立性进行假设很重要。 也就是说,STS假定网络在不同帧中的输出在条件上是独立的,这实际上是不正确的。 但是,这种假设是为了简化,没有它,一切都会变得更加复杂。
- 为了从STS模型获得良好的性能,需要使用外部语言模型,因为直接贪婪解码无法很好地工作。
注意事项
对于此STS,我们有什么选择? 对于任何人来说,可能都没有什么秘密,例如Attention或“ Attention”,它在某种程度上发生了革命,并直接脱离了机器翻译的任务。 现在,大多数序列-序列建模决策都基于这种机制。 他是什么样的人? 让我们尝试找出答案。 关于语音识别任务中的注意力的第一次,出版物出现在2015年。 Chen和Cherowski有人同时发行了两个相似和相异的出版物。
让我们关注第一个-叫做“听,参加和拼写”。 在我们的经典模拟中,按照我们拥有编码器和解码器的顺序,添加了另一个元素,称为注意。 echnoder将执行声学模型用来执行的功能。 它的任务是将输入语音转换为高级声学功能。 我们的解码器将执行我们之前执行的语言模型和发音模型(词典)的任务,并将根据先前的输出标记自动回归预测每个输出标记。 并且注意力本身将直接说出哪个输入帧最相关/最重要,以便预测此输出。
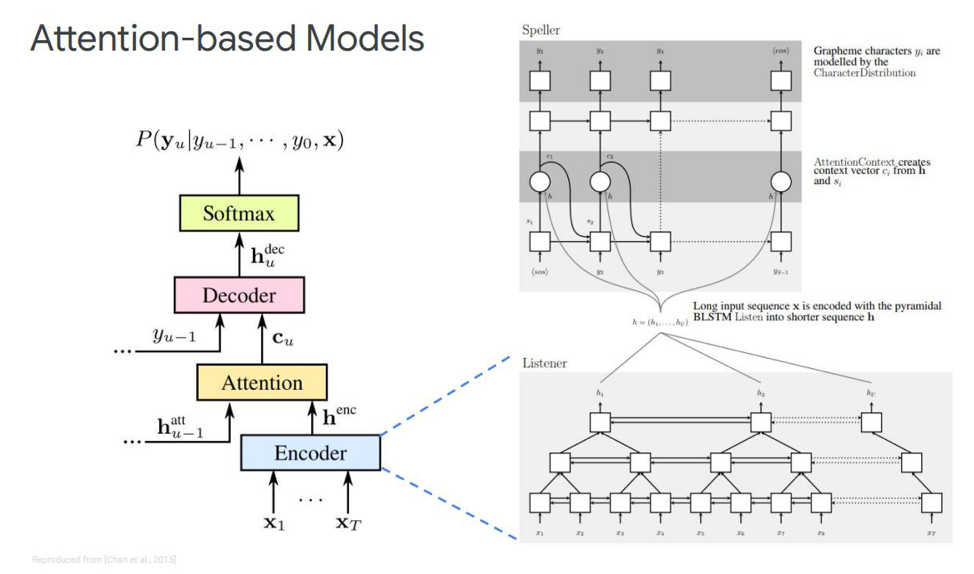
这些块是什么? 本文中的eco编码器被描述为侦听器,它是基于LSTM或其他东西的经典双向RNN。 通常,没有什么新鲜的-系统仅将输入序列模拟为复杂的功能。
另一方面,注意力会从这些向量中创建一个特定的上下文向量C,这将有助于直接正确地解码解码器,解码器本身(例如还有一些LSTM)也会从该注意层解码为输入序列,该注意层已经突出显示了最重要的状态符号,一些字符输出序列。
此注意事项本身也有不同的表示形式-这是Chen和Charowski发行的这两种出版物之间的区别。 他们使用不同的注意力。 Chen使用点乘积注意,而Charowski使用加性注意。

接下来要去哪里?
这是迄今为止在非在线语音识别方面获得的所有主要成就的正负。 这里可能有什么改进? 接下来要去哪里? 最明显的是在单词上使用模型,而不是直接使用字素。 它可以是一些单独的语素或其他。
使用单词切片的动机是什么? 通常,与字素水平相比,言语水平的语言模型具有更少的困惑。 对单词建模可以使您构建语言模型的更强大的解码器。 对更长的元素建模可以提高基于LSTM的解码器的存储效率。 它还可以使您潜在地记住频率词的出现。 较长的元素允许以较少的步骤进行解码,这直接加速了此模型的推断。
此外,基于单词的模型使我们能够解决语言模型中出现的OOV(词汇量)单词的问题,因为我们可以使用单词对任何单词进行建模。 值得注意的是,对此类模型进行了训练,以使语言模型在训练数据集上的可能性最大化。 这些模型是位置相关的,我们可以使用贪婪算法进行解码。
除了单词模型之外,还有哪些其他改进? 有一种机制称为多头注意力。 它于2017年首次描述用于机器翻译。 多头注意表示一种机制,该机制具有多个所谓的头,可让您生成同一注意的不同分布,从而直接改善结果。
在线模型
我们转到最有趣的部分-这些是在线模型。 重要的是要注意,LAS没有流式传输。 即,该模型不能在在线解码模式下工作。 我们将考虑迄今为止两个最受欢迎的在线模型。 RNN传感器和神经传感器。
RNN传感器是Graves在2012-2017年提出的。 主要思想是在递归模型的帮助下使我们的STS模型更加复杂。
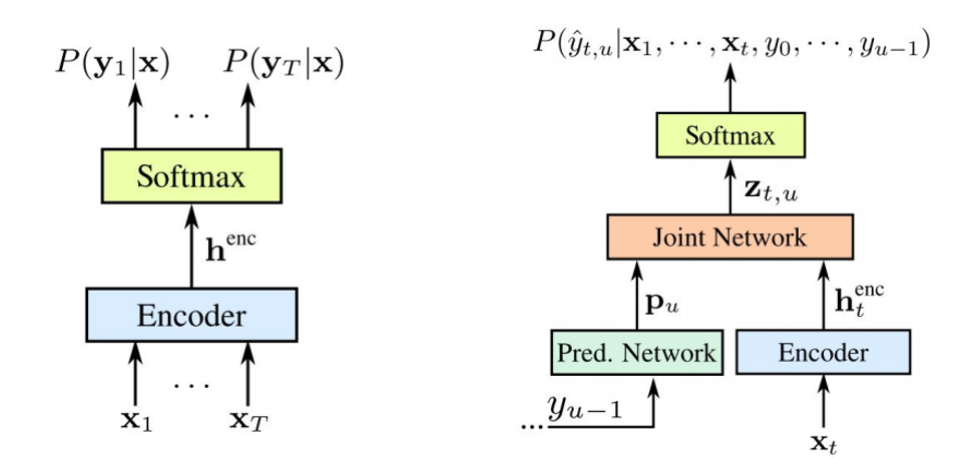
值得注意的是,两个组件都在可用的声学数据上一起训练。 像STS一样,此方法不需要训练数据集中的帧对齐。 如图所示:左边是经典的STS,右边是RNN传感器。 我们有两个新元素-
预测网络和
加入网络 。
STS编码器完全相同-这是输入电平RNN,它确定所有输出序列不超过输入序列长度的所有比对中的分布-Graves在2006年对此进行了描述。 但是,这种文本到语音转换的任务也被排除在外,其中比STS的输入序列长的输入序列不对输出之间的关系建模。 换能器扩展了这个STS,确定了所有长度的输出序列的分布,并共同建模了输入-输出和输出-输出的依赖性。
事实证明,我们的模型最终能够处理输入的输出和最后一步的输出的依存关系。
那么什么是
预测网络或预测网络? 她尝试在考虑先前元素的情况下为每个元素建模,因此,它与标准RNN相似,具有下一步的预测功能。 只有具有做零假设的能力。
如图所示,我们有一个预测网络,它接收输出的先前值,还有一个编码器,它接收输入的当前值。 在输出端,我们再次具有当前值
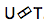
。
神经传感器 。 这是经典seq-2seq方法的复杂之处。 编码器处理输入的声音序列,以在每个时间步创建隐藏状态向量。 一切似乎和往常一样。 但是,还有一个额外的Transducer元素,该元素在每个步骤接收一个输入块,并使用此输入上方基于seq-2seq的模型生成最多M个输出令牌。 换能器通过使用与先前时间步长的周期性连接来保持其状态为块状。
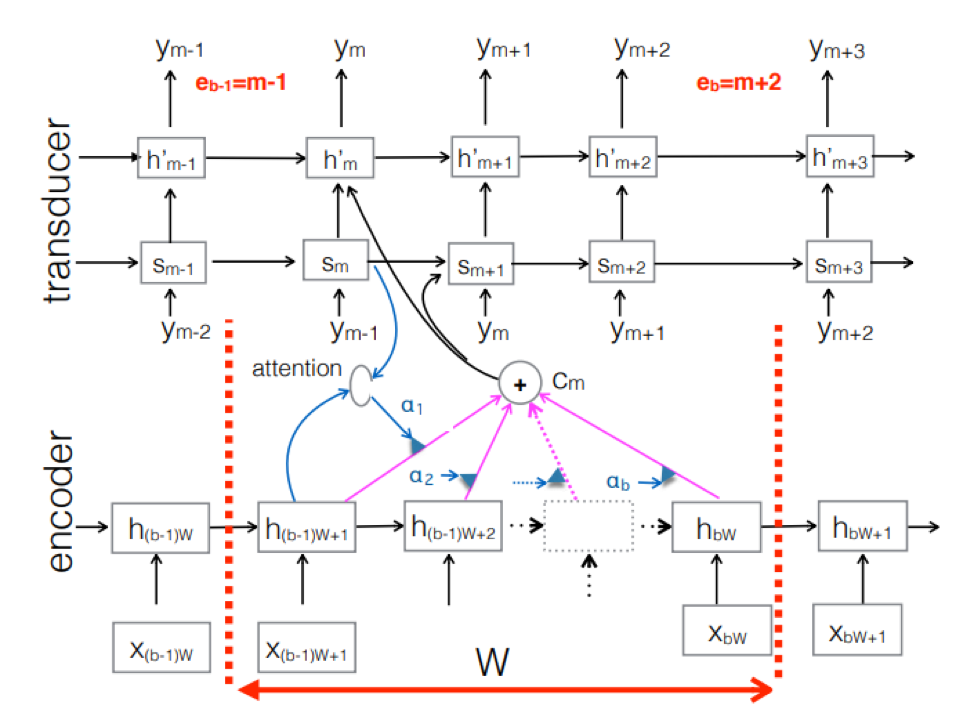 该图显示了传感器,为相应的Ym块中使用的序列的块生成令牌。
该图显示了传感器,为相应的Ym块中使用的序列的块生成令牌。因此,我们基于End2End方法研究了语音识别的当前状态。 值得一提的是,不幸的是,今天的这些方法需要大量数据。 通过经典方法获得的真实结果(需要标记200到500个小时的声音记录以训练基于End2End的良好模型)将需要数倍甚至数十倍的数据。 现在,这是这些方法的最大问题。 但是也许很快一切都会改变。
AI MTS中心Nikita Semenov的首席开发人员。