
大家好! 最近,举行了一个开放式网络研讨会
“提供容错存储” 。 它检查了体系结构设计中出现的问题,为什么服务器故障不是服务器崩溃的借口,以及如何将停机时间降至最低。 该网络研讨会由Citimobil服务器开发负责人,
“高负载
架构师”课程的老师
Ivan Remen主持。
为什么要打扰存储弹性?
考虑可伸缩存储的弹性并了解基本缓存问题应该
在启动阶段 。 显然,当您编写启动程序时,一开始就需要制作该产品的最低版本。 但是,您增长得越多,您就越快地投入生产,这可能会导致业务完全停止。 而且,如果您从投资者那里获利,那么他们当然也将需要持续增长和新的业务功能。 为了找到合适的平衡,您需要在速度和质量之间进行选择。 同时,您不能牺牲任何一个,如果您做出牺牲,则必须有意识地并在一定范围内。 但是,这里没有通用的配方以及理想的解决方案。
我们靠阅读的基础
这是第一种情况。 想象一下,我们有1台服务器,其处理器或硬盘驱动器上的负载为99%。 在这种情况下:
在这种情况下,最好的解决方案是考虑副本。 怎么了 这是最便宜,最简单的解决方案。
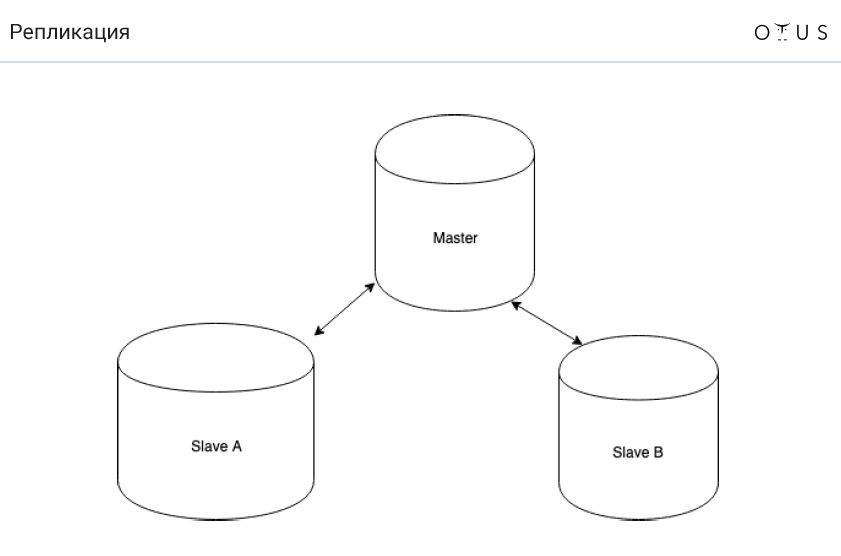
复制分类:
1.通过同步:
2.根据便携式数据:
3.通过每条记录的节点数:
4.通过发起者:
现在的
任务是要喝一桶水 。 假设我们有MySQL和异步主从复制。 DC正在进行清洁,结果是清洁剂跌倒了,并用主底座将一桶水倒在服务器上。 自动化成功地将最新的从设备之一切换到主设备模式。 一切继续进行。 渔获物在哪里?
答案很简单-我们丢失了我们无法复制的交易。 因此,ACID的属性D被侵犯。
现在让我们谈谈异步复制(MySQL)的工作原理:
- 将交易记录到存储引擎(InnoDB);
- 将交易记录在二进制日志中;
- 存储引擎中的交易完成;
- 返回确认给客户;
- 将部分日志传输到副本;
- 在副本上执行事务(第1-3页)。
现在的问题是,在以上各段中需要更改哪些内容,以便我们永远不会以复制结尾?
而且只需要交换两点:第四和第五(“将日志的一部分转移到副本”和“将确认返回给客户端”)。 因此,如果主节点跳出,我们将始终在某处有事务日志(第2点)。 而且,如果将交易记录在二进制日志中,那么交易也将在某个时间发生。
结果,我们得到了半同步复制(MySQL),其工作方式如下:
- 将交易记录到存储引擎(InnoDB);
- 将交易记录在二进制日志中;
- 存储引擎中的交易完成;
- 将部分日志传输到副本;
- 返回确认给客户;
- 在副本上执行事务(第1-3页)。
同步与半同步以及异步与半同步
由于某些原因,在俄罗斯,大多数人还没有听说过半同步复制。 顺便说一下,它在PostgreSQL中很好地实现了,而在MySQL中不是很好。
在这里阅读有关此内容的更多信息,但论文可以制定如下:
- 半同步复制仍比异步落后(但不多);
- 我们不会丢失交易;
- 仅将数据带到一个从站就足够了。
顺便说一下,在Facebook上使用了半同步复制。
我们反对记录基础
让我们谈谈完全相反的问题:
- 90%的请求-记录;
- 读取了10%的请求;
- 1台服务器;
- 负载-99%(处理器或硬盘)。
著名的分片在这里进行救援。 但是现在让我们谈谈其他事情:

在很多情况下,他们开始使用master-master。 但是,
在这种情况下它无济于事 。 怎么了 很简单:服务器上的记录不会变小。 毕竟,复制意味着所有节点上都有数据。 实际上,使用基于语句的复制,SQL将在所有节点上运行。 基于C的行稍微容易一些,但仍然很昂贵。 师父也有冲突的问题。
实际上,在以下情况下使用master-master是有意义的:
- 直写式容错(想法是您始终只写一个主机)。 您可以使用虚拟IP地址来实现;
- 地理分布系统。
但是,请记住,主-主复制始终很困难。 通常,主人-主人带来的问题多于解决的问题。
分片
我们已经提到了分片。 简而言之,分片是扩展记录的可靠方法。 我们的想法是我们在独立(但并非总是)服务器之间分配数据。 每个分片可以独立复制。
分片的第一个规则是,一起使用的数据必须位于同一分片中。 sharding_key -> shard_id公式
sharding_key -> shard_id起作用。 因此,一起使用的数据的
sharding_key必须匹配。 第一个困难是,如果您选择了错误的
sharding_key ,那么重新整理所有内容将非常困难。 其次,如果您有某种
sharding_key ,则某些请求将很难执行。 例如,您找不到平均值。
为了说明这一点,让我们想象一下,我们有两个分片,每个分片具有三个值:(1; 2; 3)(0; 0; 500)。 平均值等于(1 + 2 + 3 + 500)/ 6 = 84.33333。
现在假设我们有两个独立的服务器。 并分别重新计算每个分片的平均值。 在第一个上,我们得到2,在第二个上-166.66667。 即使将这些值取平均值,我们仍然会得到与正确值不同的数字:(2 + 166.66667)/ 2 = 86.33334。
也就是说,
均值的平均值并不等于所有值的平均值: avg(a, b, c, d) != avg(avg(a, b) + (avg(c, d))
简单的数学,但请务必记住。
分片任务
假设我们在社交网络中有一个对话系统。 对话中只能有2个人。 所有消息都在一个表中,其中有:
- 讯息编号
- 发件人ID
- 收件人ID
- 消息文本;
- 消息发送的日期;
- 一些标志。
基于我们具有上述第一个分片规则的事实,应该选择哪个分片密钥?
解决这个经典问题有几种选择:
- crc32(id_src // id_dst);
- crc32(1 // 2)!= crc32(2 // 1);
- crc32(从+到%)n;
- crc32(最小(从,到)。最大(从,到))%n。
快取
关于缓存的几句话。 我们可以说
缓存是一种反模式 ,尽管有人可以对此声明
提出异议 (许多人喜欢使用缓存)。 但是总的来说,只需要使用高速缓存来提高响应速度。 并且它们不能设置为承受负载。
结论很简单-我们应该在没有缓存的情况下安静地生活。 可能需要它们的唯一原因是处理器中完全相同的原因:提高响应速度。 如果由于缓存消失而导致数据库无法承受负载,那么这很不好。 这是一种极其不成功的架构模式,因此不应如此。 无论您拥有什么资源,总有一天,无论您做什么,缓存肯定都会掉下来。
缓存问题是以下问题:如果您仍然使用缓存,则一致的哈希将为您提供帮助。 这是一种创建分布式哈希表的方法,其中一个或多个存储服务器的故障不会导致需要对所有存储的键和值进行完全重定位。 但是,您可以
在此处了解更多信息。

好,谢谢收看! 为了不错过上一堂课的内容,最好
观看整个网络研讨会 。