
这是对Landsat 5卫星的多光谱图像进行分类的分步说明,如今,在许多领域,深度学习已成为解决复杂问题(包括地理空间问题)的主要工具。 希望您熟悉卫星数据集,尤其是Landsat 5 TM。 如果您对机器学习算法有点熟悉,这将帮助您快速学习本手册。 对于那些不了解的人,只要知道机器学习实际上就是在对象的几个特征(一组属性X)与其其他属性(值或标签,目标变量Y)之间建立关系就足够了。 我们为模型提供许多对象,这些对象的特征和目标指标/类别(标记数据)的值是已知的,并对其进行训练,以便它可以预测新数据(未标记)的目标变量Y的值。
卫星图像的主要问题是什么?
卫星图像中的两类或更多类对象(例如,建筑物,空地和基坑)可以具有相同的光谱值特征,因此,在过去的20年中,对其进行分类一直是一项艰巨的任务。
因此,可以在有老师和没有老师的情况下使用经典的机器学习模型,但是它们的质量将远远不够理想。 他们总是有相同的缺点。 考虑一个例子:

如果使用垂直线作为分类器并沿X轴移动,则对房屋图像进行分类将不容易。 数据是分布式的,因此不可能使用一条垂直线将它们分为几类(在这种情况下,据说“不同类的对象不能线性分离”)。 但这并不意味着根本不能对房屋进行分类!
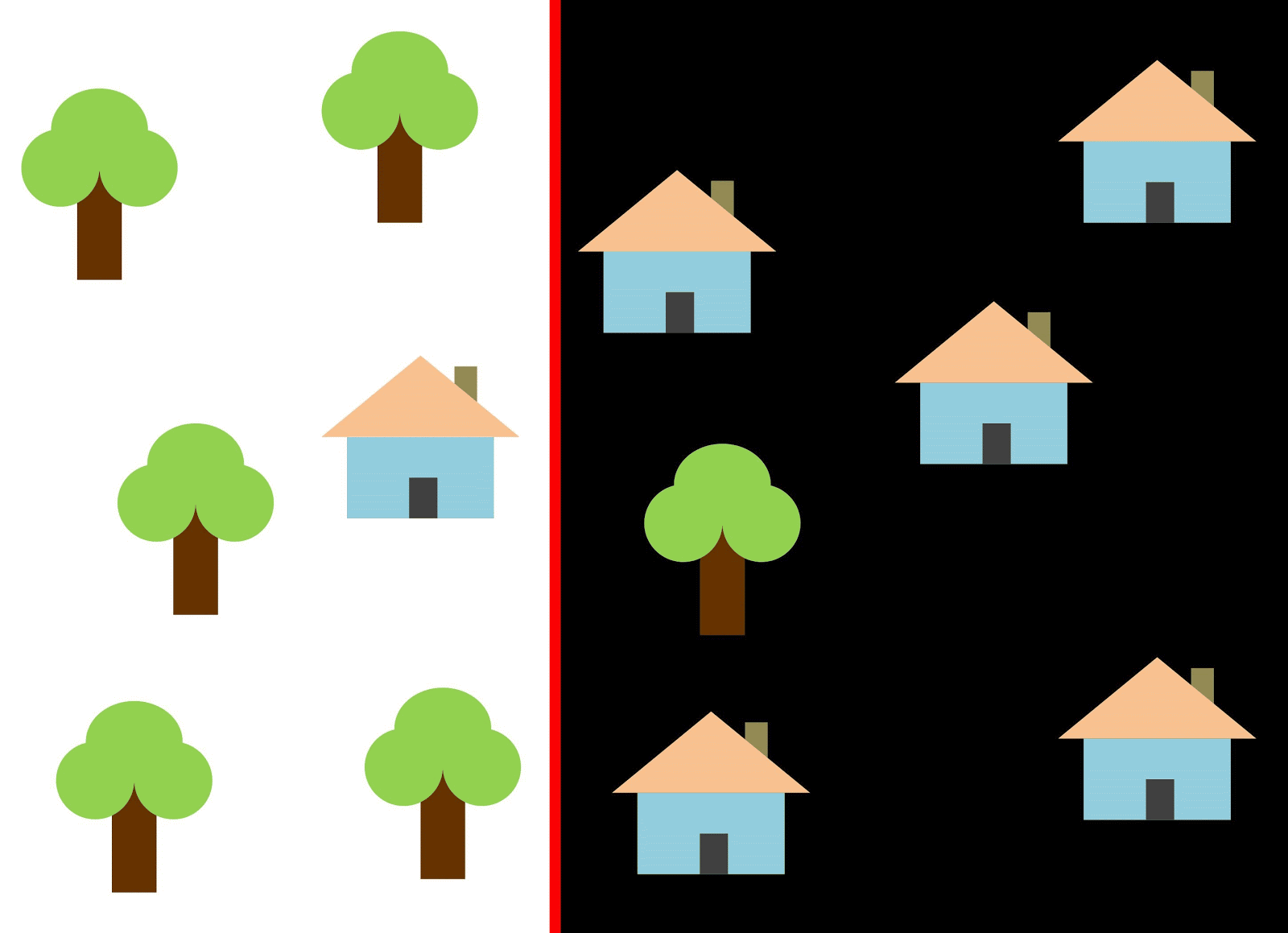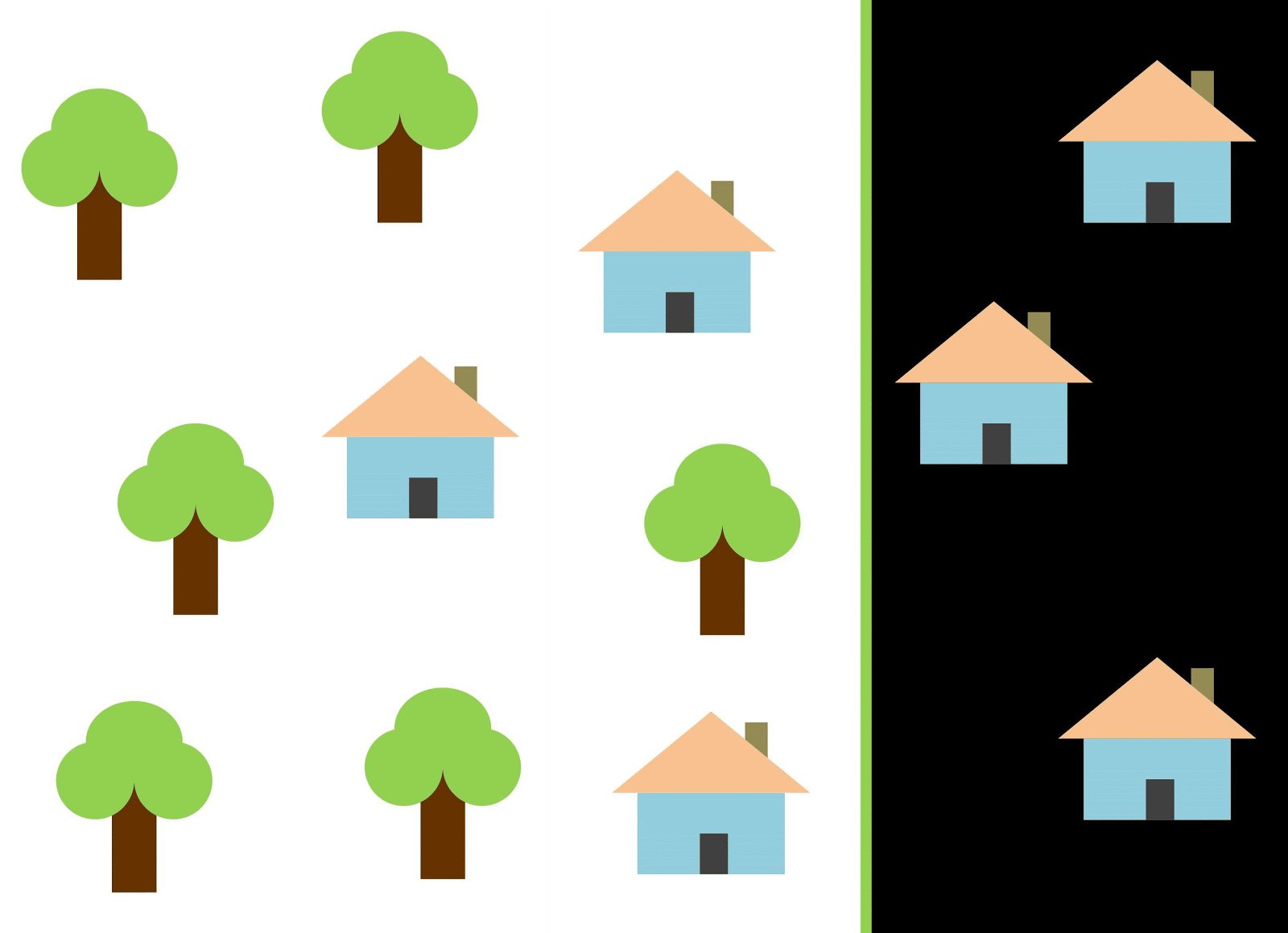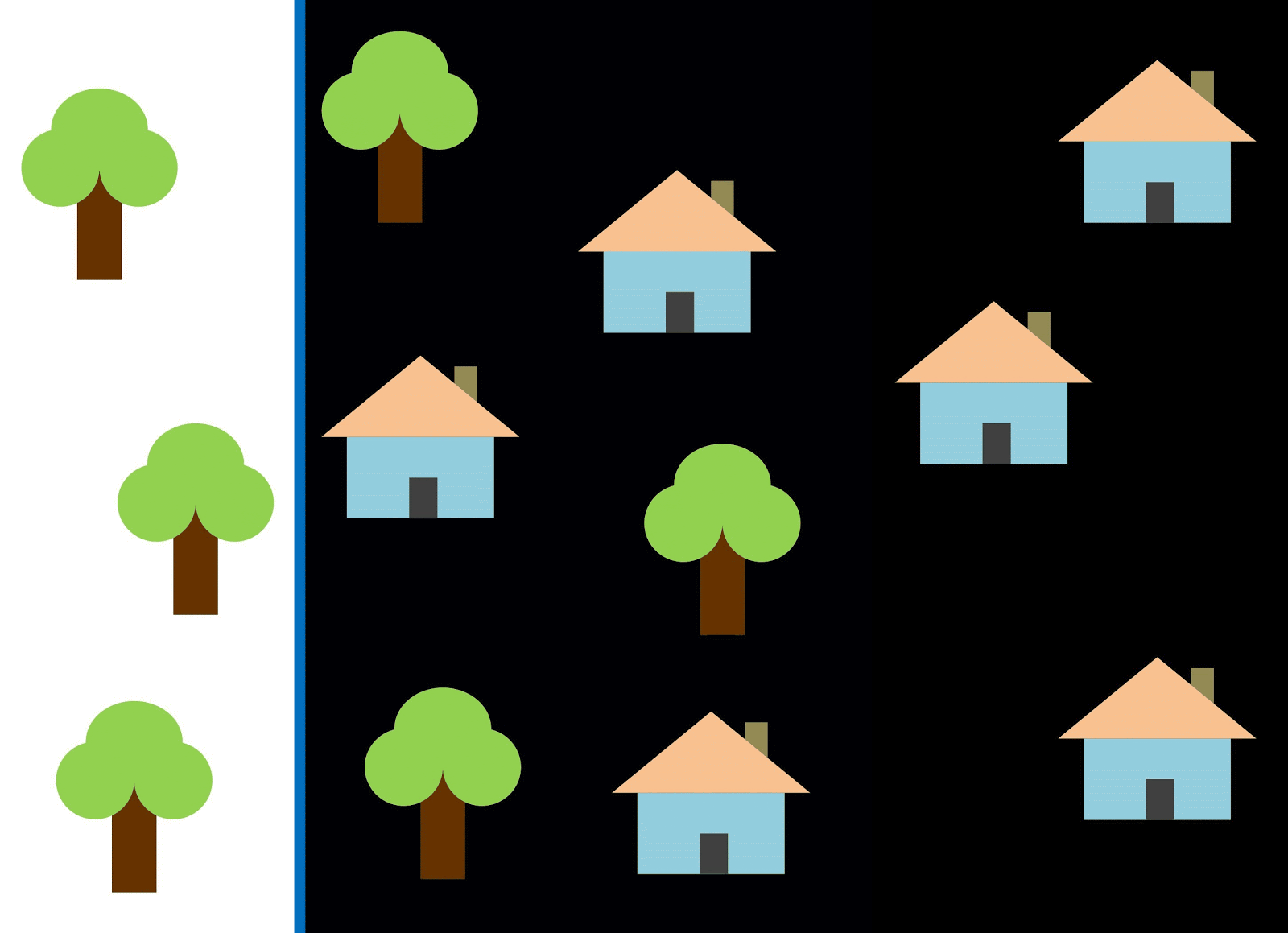
让我们用红线将这两个类分开。 在这种情况下,分类器识别了大多数房屋,但是没有将一所房屋分配给其类别,并且另外三棵树被错误地分配给了“房屋”。 为了不错过一所房子,您可以使用蓝线形式的分类器。 然后,所有内容都会在家中覆盖,也就是说,召回率指标(丰满度)很高。 但是,并非所有分类值都证明是房屋,也就是说,与此同时,我们获得的精度指标值较低。 如果使用绿线,则所有分类为房屋的图像实际上都是房屋,也就是说,分类器将显示较高的准确性。 在这种情况下,丰满度会降低,因为这三座房屋将无法计算。 在大多数情况下,我们必须在准确性和完整性之间找到折衷方案。
房屋和树木的问题类似于建筑物,空地和坑的问题。 卫星图像分类指标的优先级可能因任务而异。 例如,如果您需要确保所有建成区都无一例外地被分类为建筑物,并且准备好接受具有相似签名的其他类别的像素(它们也将被分类为建筑物),那么您将需要一个具有高度完整性的模型。 而且,如果不对建筑物进行分类而又不添加其他类别的像素,这对您而言更为重要,并且您准备放弃对混合领土的分类,那么请选择具有较高准确性的分类器。 对于房屋和树木,通常的模型将使用红线,以保持准确性和完整性之间的平衡。
使用数据
作为标志,我们将使用Landsat 5 TM的图像的六个范围(波段2-波段7)的值,并尝试预测二进制显影类别。 为了进行培训和测试,将使用班加罗尔2011年Landsat 5的多光谱数据(图像和具有二进制建筑等级的图层)。 为了进行预测,将使用2005年在海得拉巴获得的多光谱Landsat 5数据。
由于我们将标记的数据用于教学,因此称为与老师一起教学。
 多光谱训练数据和相应的二进制层一起发展。
多光谱训练数据和相应的二进制层一起发展。为了创建神经网络,我们将使用Python – Google Tensorflow库。 我们还将需要以下库:
- pyrsgis-用于读写GeoTIFF。
- scikit-learn-用于数据预处理和准确性评估。
- numpy-用于数组的基本操作。
现在,不用多说,让我们来编写代码。
将所有三个文件放在目录中,在脚本中输入输入文件的路径和名称,然后读取GeoTIFF文件。
import os from pyrsgis import raster os.chdir("E:\\yourDirectoryName") mxBangalore = 'l5_Bangalore2011_raw.tif' builtupBangalore = 'l5_Bangalore2011_builtup.tif' mxHyderabad = 'l5_Hyderabad2011_raw.tif'
pyrsgis软件包中的
raster模块读取GeoTIFF地理位置数据和数字编号(DN)值作为单独的NumPy数组。 如果您对细节感兴趣,请阅读
此处 。
现在,我们显示读取数据的大小。
print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
结果:
Bangalore multispectral image shape: 6, 2054, 2044 Bangalore binary built-up image shape: 2054, 2044 Hyderabad multispectral image shape: 6, 1318, 1056
如您所见,班加罗尔的图像具有与二元图层(对应于建筑物)相同的行数和列数。 班加罗尔和海得拉巴的多光谱图像中的层数也重合。 模型将学习基于所有6个光谱的对应值来确定哪些像素属于建筑物,哪些像素不属于建筑物。 因此,多光谱图像必须具有以相同顺序列出的相同数量的特征(范围)。
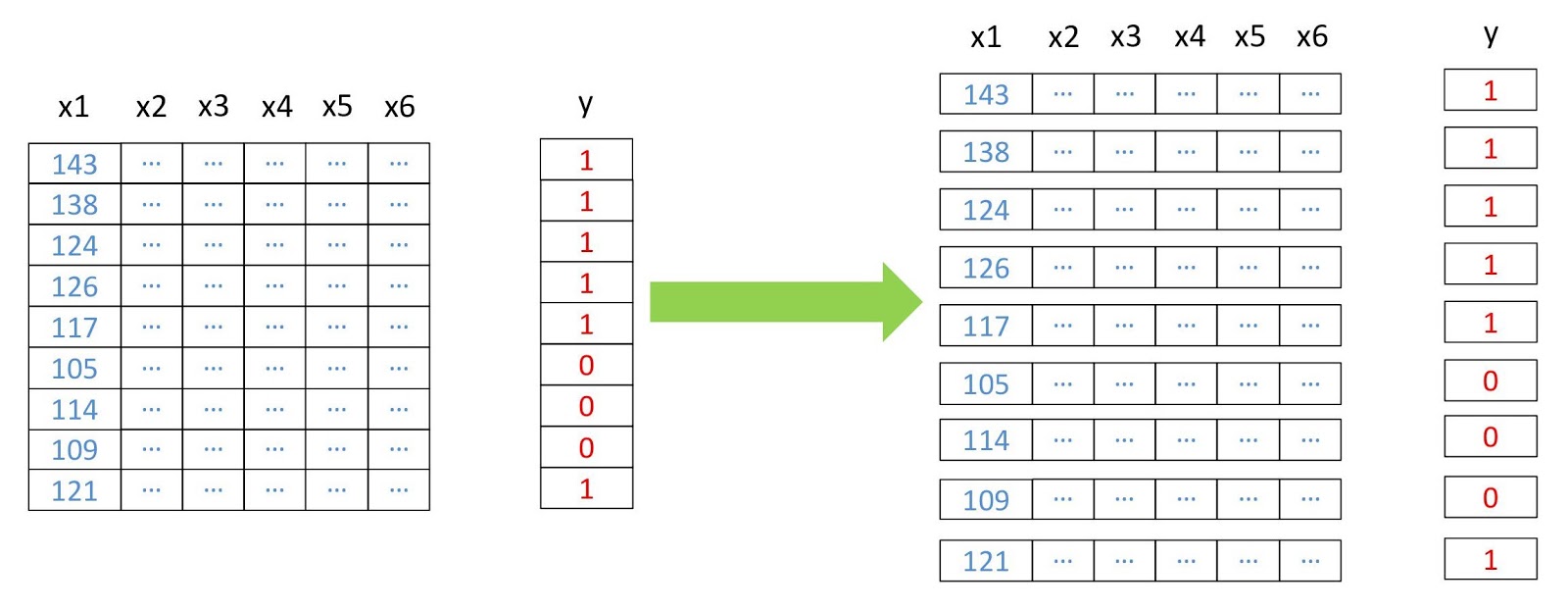
现在,我们将数组变成二维的,其中每一行代表一个单独的像素,因为这对于大多数机器学习算法的操作都是必需的。 我们将使用
pyrsgis软件包中的
convert模块执行此操作。
 数据重组方案。
数据重组方案。 from pyrsgis.convert import changeDimension featuresBangalore = changeDimension(featuresBangalore) labelBangalore = changeDimension (labelBangalore) featuresHyderabad = changeDimension(featuresHyderabad) nBands = featuresBangalore.shape[1] labelBangalore = (labelBangalore == 1).astype(int) print("Bangalore multispectral image shape: ", featuresBangalore.shape) print("Bangalore binary built-up image shape: ", labelBangalore.shape) print("Hyderabad multispectral image shape: ", featuresHyderabad.shape)
结果:
Bangalore multispectral image shape: 4198376, 6 Bangalore binary built-up image shape: 4198376 Hyderabad multispectral image shape: 1391808, 6
在第七行中,我们提取了所有值为1的像素。这有助于避免没有信息的像素(NoData)出现问题,这些信息通常具有极高或极低的值。
现在,我们将数据分为训练样本和验证样本。 这是必要的,这样模型就不会看到测试数据,并且在新信息下也能很好地工作。 否则,将对模型进行重新训练,并且仅在训练数据上才能很好地工作。
from sklearn.model_selection import train_test_split xTrain, xTest, yTrain, yTest = train_test_split(featuresBangalore, labelBangalore, test_size=0.4, random_state=42) print(xTrain.shape) print(yTrain.shape) print(xTest.shape) print(yTest.shape)
结果:
(2519025, 6) (2519025,) (1679351, 6) (1679351,) test_size=0.4
表示将数据按60/40的比例分为训练和验证。
许多机器学习算法,包括神经网络,都需要规范化的数据。 这意味着它们必须在给定范围内分配(在这种情况下,从0到1)。 因此,为了满足此要求,我们将症状标准化。 可以通过提取最小值,然后将其除以价差(最大值和最小值之间的差)来完成。 由于Landsat数据集是八位的,因此最小值和最大值将分别为0和255(
2⁸ = 256个值)。
请注意,为了进行标准化,总是最好根据数据计算最小值和最大值。 为了简化任务,默认情况下,我们将遵循八位范围。
初步处理的另一个阶段是将符号矩阵从二维转换为三维,以便模型将每一行视为一个单独的像素(一个单独的学习对象)。
结果:
(2519025, 1, 6) (1679351, 1, 6) (1391808, 1, 6)
一切准备就绪,让我们与
keras组装模型。 首先,让我们使用顺序模型,一个接一个地添加图层。 我们将有一个输入层,其节点数等于范围数(
nBands )-在我们的示例中为6。我们还将使用一个包含14个节点和
ReLu激活
ReLu隐藏层。 最后一层由两个节点组成,这些节点用于使用
softmax激活
softmax定义一个二进制建筑类,适用于显示分类结果。
在此处阅读有关激活功能的更多信息。
from tensorflow import keras
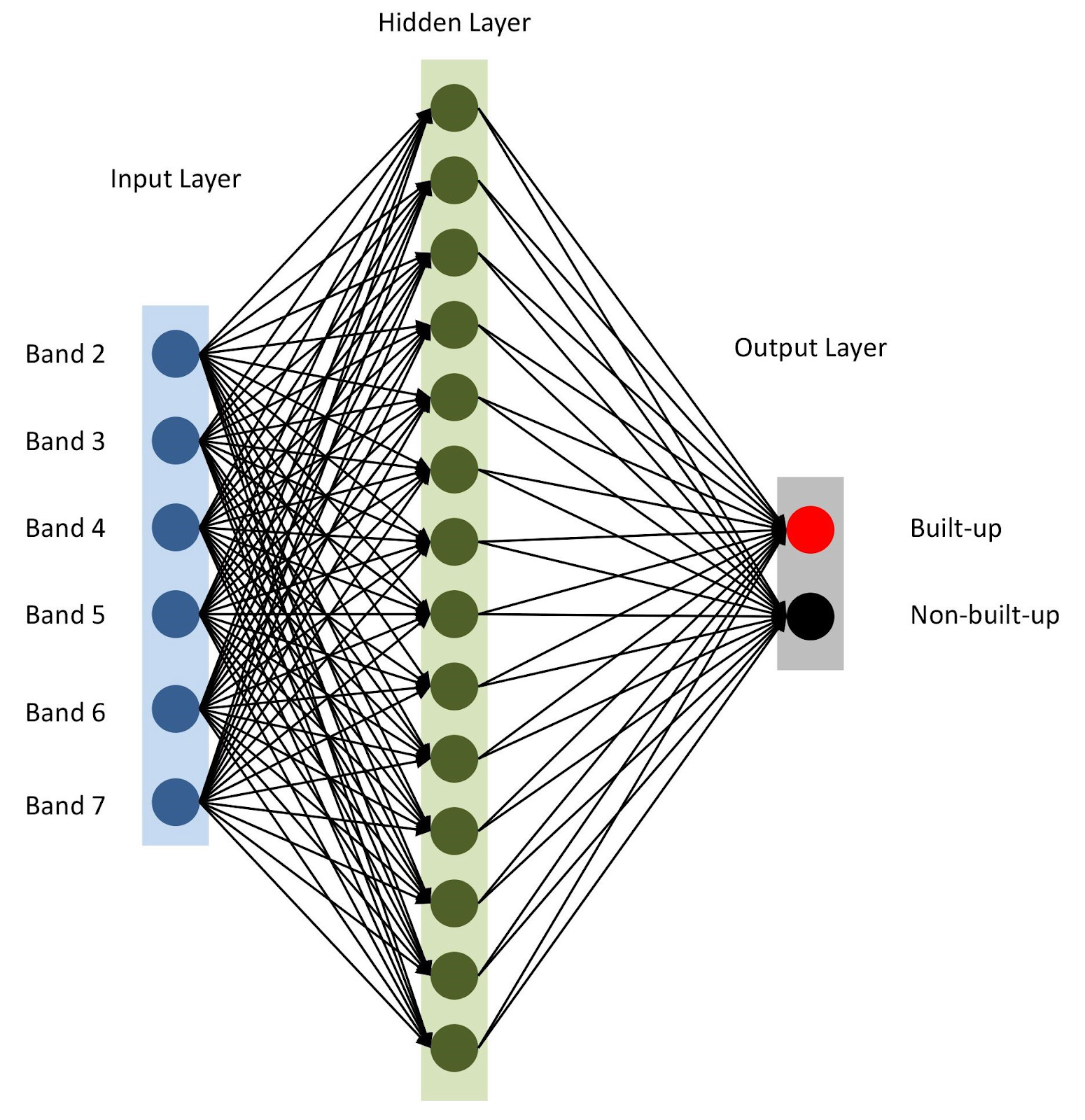 神经网络架构
神经网络架构如第10行所述,我们将
adam指定为模型优化器(还有
其他几个)。 在这种情况下,我们将交叉熵用作损失函数(例如,
categorical-sparse-crossentropy交叉熵-有关
此内容,请
categorical-sparse-crossentropy )。 为了评估模型的质量,我们将使用
accuracy指标。
最后,我们将开始在
xTrain和
yTrain上训练两个时代(或迭代)的
yTrain 。 这将需要一些时间,具体取决于数据的大小和处理能力。 编译后将显示以下内容:

让我们预测分别存储的验证数据的值,并计算各种准确性指标。
from sklearn.metrics import confusion_matrix, precision_score, recall_score
softmax函数为每个类别的概率值生成单独的列。 从上面代码的第六行可以看出,我们仅使用第一类的值(“有建筑物”)。 与其他经典的机器学习问题不同,评估地理空间分析模型的工作并不那么简单。 依靠广义的总误差将是不公平的。 成功的模型的关键是空间布局。 因此,混淆矩阵,准确性和完整性可以对模型的质量给出更正确的想法。
 因此,控制台将显示错误矩阵,准确性和完整性。
因此,控制台将显示错误矩阵,准确性和完整性。从混淆矩阵中可以看到,有成千上万个与建筑物相关的像素,但分类不同,反之亦然。 但是,它们在总数据量中所占的份额并不太大。 测试数据的准确性和完整性超过了阈值0.8。
您可以花费更多时间并执行几次迭代,以找到最佳的隐藏层数,每个隐藏层中的节点数,以及达到所需精度的时代数。 根据需要,可以将诸如NDBI或NDWI之类的遥感指数用作特征。 当达到所需的精度时,可使用该模型根据新数据预测开发并将结果导出到GeoTIFF。 对于此类任务,您可以使用具有较小更改的类似模型。
predicted = model.predict(feature2005) predicted = predicted[:,1]
请注意,我们导出的GeoTIFF具有预测的概率值,而不是其阈值二值化版本。 稍后在GIS环境中,我们可以设置float类型的图层的阈值,如下图所示。
 该模型基于多光谱数据对海得拉巴的堆积层进行了预测。
该模型基于多光谱数据对海得拉巴的堆积层进行了预测。模型的准确性已经通过精确度和召回率进行了测量。 您还可以在新的预测图层上执行传统检查(例如,使用kappa系数)。 除了上述的卫星图像分类困难之外,其他明显的局限性还包括不可能基于一年中不同时间和不同区域拍摄的图像进行预测,因为它们将具有不同的光谱特征。
本文中描述的模型具有用于神经网络的最简单的体系结构。 使用更复杂的模型(包括卷积神经网络)可以获得更好的结果。 这种分类的主要优点是训练模型后的可伸缩性(适用性)。
使用的数据和所有代码在
此处 。