我叫Azat Razetdinov,我在Yandex工作了12年,负责管理Y. Real Estate的界面开发服务。 今天,我想谈一个单一存储库。 如果您只有一个资料库在工作-恭喜,您已经住在一个资料库中。 现在介绍为什么其他人需要它。
Yandex.Map API开发服务负责人Marina Pereskokova表示,我的祖父种植了monorepa,并且monorepa变得非常大。
-Yandex的我们尝试了几种服务的不同使用方式,并注意到-一旦您拥有一项以上的服务,不可避免的常见部分开始出现:模型,实用程序,工具,代码段,模板,组件。 问题是:将所有这些放在哪里? 当然,您可以复制粘贴,我们可以做到,但是我要漂亮。
我们甚至为那些记得的人尝试了像SVN外部对象这样的实体。 我们尝试了git子模块。 当它们出现时,我们尝试了npm软件包。 但是,这一切都花了多长时间,还是什么。 您支持任何软件包,发现错误,进行更正。 然后,您需要发布新版本,浏览服务,升级到该版本,检查一切正常,运行测试,查找错误,返回库存储库,修复错误,发布新版本,浏览服务,更新等等。圈子。 只是变成了痛苦。

然后,我们考虑是否应该将它们合并到一个存储库中。 利用我们所有的服务和库,在一个存储库中进行转移和开发。 有很多优点。 我并不是说这种方法是理想的,但是从公司乃至几个小组的部门的角度来看,都显示出明显的优势。
对我个人而言,最重要的是提交的原子性,作为开发人员,我可以修复库,绕过所有服务,进行更改,运行测试,验证一切正常,将其推送到主数据库中,而所有这些只需一次更改。 无需重建,发布或更新任何内容。
但是,如果一切都很好,为什么还没有所有人都迁移到单一存储库呢? 当然,它也有缺点。

Yandex.Map API开发服务负责人Marina Pereskokova表示,我的祖父种植了一个monorepa,并且monorepa变得越来越大。 这是事实,不是开玩笑。 如果您在一个存储库中收集许多服务,则不可避免地会增长。 而且,如果我们谈论的是git,它将为您的代码的存在而提取所有文件及其全部历史记录,那么这是一个相当大的磁盘空间。
第二个问题是注入母版。 您准备了一个池请求,进行了审核,您可以将其合并。 事实证明,有人设法超越您,您需要解决冲突。 您解决了冲突,再次准备加入,又没有时间。 解决此问题的方法是,存在合并队列系统,当特殊的机器人将这项工作自动化时,可以缓冲池请求,并尝试解决冲突(如果可以的话)。 如果不能,他请作者。 但是,存在这样的问题。 有一些解决方案可实现这一目标,但您需要牢记这一点。
这些是技术要点,但也有组织要点。 假设您有几个团队提供几种不同的服务。 当他们转移到单个存储库时,他们的责任开始削弱。 由于他们发布了产品,因此正式投入生产-出现了问题。 我们开始汇报。 事实证明,这是另一个团队的开发人员,已对通用代码进行了某些操作,我们将其拉出,未发布,没有看到,一切都崩溃了。 目前尚不清楚谁负责。 重要的是要理解和使用所有可能的方法:单元测试,集成测试,轻巧-一切可能减少一个代码对所有其他服务的影响的问题。
有趣的是,除了Yandex和其他参与者以外,还有谁在使用单一存储库? 很多人。 这些是React,Jest,Babel,Ember,Meteor,Angular。 人们理解-与从多个小型存储库相比,从单个存储库开发和发布npm软件包更容易,更便宜,更快速。 最有趣的是,随着这一过程,用于单一存储库的工具开始开发。 关于他们,我想谈谈。
这一切都始于创建一个单一存储库。 世界上最著名的前端工具称为lerna。

只需打开您的存储库,运行npx lerna init,它将询问您一些提示性问题并将一些实体添加到您的工作副本中。 第一个实体是lerna.json配置,它指示至少两个字段:所有软件包的端到端版本以及软件包在文件系统中的位置。 默认情况下,所有软件包都添加到packages文件夹中,但是您可以根据需要进行配置,甚至可以将它们添加到根目录,lerna也可以选择它。
下一步是如何将您的存储库添加到mono存储库,如何转移它们?
我们要实现什么? 您很可能已经有了某种存储库,在这种情况下为A和B。

这是两个服务,每个服务都在其自己的存储库中,我们希望将它们转移到packages文件夹中的新Mono存储库中,最好具有提交历史记录,以便使git blame,git log等成为可能。

为此有一个lerna导入工具。 您只需指定存储库的位置,然后lerna便将其转移到您的monorepo。 同时,她首先获取所有提交的列表,修改每个提交,将文件的路径从根目录更改为packages / package_name,然后一个接一个地应用它们,并将其强加到您的单一存储库中。 实际上,每个提交都会进行准备,更改其中的文件路径。 本质上,Lerna为您提供了git magic。 如果您阅读源代码,则仅会按特定顺序执行git命令。
这是第一种方式。 它有一个缺点:如果您在一家有生产流程的公司工作,人们已经在写某种代码,并且打算将它们转换为monorep,那么您不太可能在一天内完成。 您将需要弄清楚,配置,验证一切是否开始,测试。 但是人们没有工作,他们继续做某事。

为了更顺利地过渡到Mono-Rap,提供了git subtree这样的工具。 这是更复杂的事情,但同时也是git的本机,它不仅使您可以通过某种前缀将单个存储库导入到单个存储库中,而且还可以来回交换更改。 也就是说,提供服务的团队可以轻松地在自己的存储库中进一步开发,同时您可以通过git subtree pull来进行更改,进行自己的更改,然后通过git subtree push进行回退。 并在过渡期内像您这样长期生活。
完成所有设置后,检查是否正在运行所有测试,部署是否正常,配置了整个CI / CD,就可以说是时候继续进行了。 对于过渡时期,我建议一个很好的解决方案。
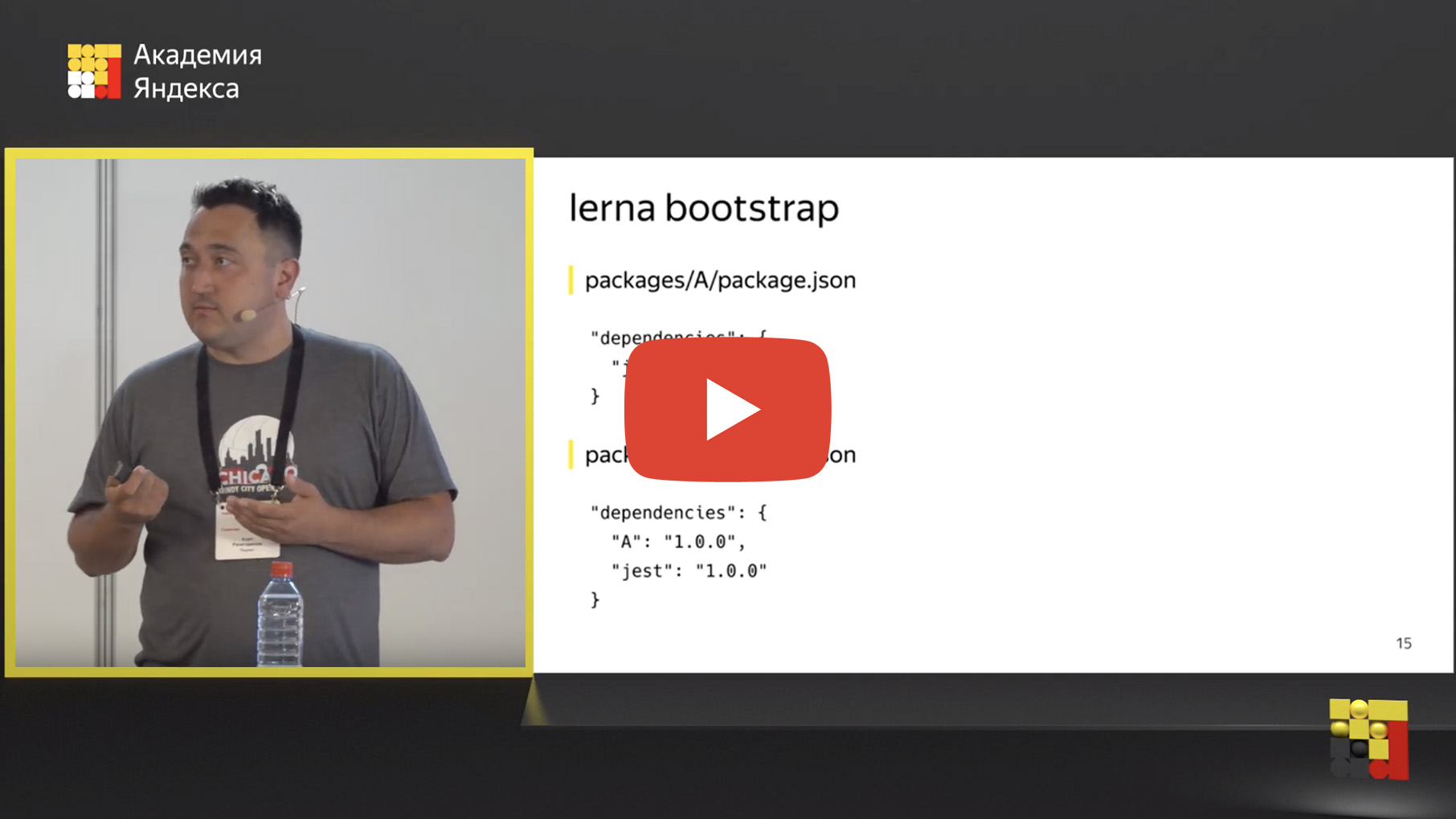
好吧,我们将存储库移动到一个单一存储库中,但是魔术在哪里呢? 但是,我们要突出显示通用部分并以某种方式使用它们。 为此,存在“依赖关系绑定”机制。 什么是依赖项绑定? 有一个lerna bootstrap工具,该命令类似于npm install,仅在所有软件包中运行npm install。

但这还不是全部。 此外,她正在寻找内部依赖项。 您可以在存储库中的一个包中使用另一个。 例如,如果您有依赖于Jest的程序包A,则有依赖于Jest和程序包A的程序包B。如果程序包A是一个通用工具,一个通用组件,则程序包B是具有它的服务用途。
Lerna定义了这种内部依赖关系,并使用文件系统上的符号链接以物理方式替换了此依赖关系。


运行lerna bootstrap之后,就在node_modules文件夹内部而不是物理文件夹A内,出现一个符号链接,该链接指向包含程序包A的文件夹。这非常方便,因为您可以编辑程序包A中的代码并立即检查程序包B中的结果。 ,运行测试,集成,单位,无论您想要什么。 开发过程大大简化,您不再需要重新组装软件包A,发布,连接软件包B。只需在此处进行固定,然后在此处进行检查即可。
请注意,如果您查看node_modules文件夹,并且那里开玩笑,我们已经复制了已安装的模块。 通常,启动lerna bootstrap的时间很长,要等到一切停止之后,由于存在许多重复的工作,因此每个程序包中都有重复的依赖项。
为了加快依赖关系的安装,使用了提高依赖关系的机制。 这个想法很简单:您可以将常规依赖项带到根node_modules。

如果指定--hoist选项(这是英语的升级),那么几乎所有依赖项都将简单地移至根node_modules。 而且它几乎总是有效。 Noda的安排如此,如果她没有在其级别上找到依赖项,那么她将开始搜索更高的一个级别(如果不存在),再搜索更高的一个级别,依此类推。 几乎没有任何变化。 但是实际上,我们获取了依赖项并对其进行了重复数据删除,然后将依赖项转移到了根目录。
同时,勒娜足够聪明。 如果存在任何冲突,例如,如果程序包A使用的是Jest版本1,而程序包B使用的是版本2,则其中一个将弹出,而第二个将保持其级别。 这大约是npm在普通的node_modules文件夹内实际执行的操作,它还会尝试消除重复项依赖,并最大程度地将其携带到根目录。
不幸的是,这种魔力并不总是有效,尤其是对于工具,Babel和Jest。 他经常启动,因为Jest有自己的模块解决系统,所以Noda开始落后,抛出错误。 尤其是在这种情况下,如果该工具无法解决根目录下的依赖项,则存在nohoist选项,该选项可让您指出这些软件包不会转移到根目录,而将其保留在原位。

如果指定--nohoist = jest,则除jest外的所有依赖项都将进入根目录,并且jest将保留在数据包级别。 难怪我举了这样一个例子-开玩笑地说这种行为有问题,而nohoist对此有所帮助。
依赖恢复的另一个优点:

如果在此之前,对于每个服务,每个程序包,您都有单独的package-lock.json,那么在租用过程中,所有内容都移到顶部,并且仅剩下一个package-lock.json。 从倒入母版,解决冲突的角度来看,这很方便。 一旦所有人被杀,就是这样。
但是lerna如何做到这一点? 她对npm相当激进。 当您指定提升器时,它会将您的package.json放在根目录中,进行备份,替换为另一个,将所有依赖项聚合到其中,运行npm install,几乎所有内容都放在根目录中。 然后此临时package.json删除,恢复您的。 如果之后使用npm运行任何命令,例如npm remove,npm将不了解发生了什么,为什么所有依赖项突然出现在根目录下。 Lerna违反了抽象级别,她爬入了低于其级别的工具。
来自Yarn的家伙是第一个注意到这个问题的人,他们说:我们要折磨什么,让我们为您做一切本来的事情,以便一切开箱即用。

Yarn可以开箱即用地做同样的事情:依赖关系,如果他发现程序包B依赖程序包A,他将免费为您建立符号链接。 他知道如何提高依赖关系,默认情况下会执行此操作,一切都加到根。 像lerna一样,它可以在存储库的根目录中保留唯一的yarn.lock。 其他所有人都不再需要您。

它的配置方式类似。 不幸的是,yarn假设所有设置都已添加到package.json中,我知道有些人试图从那里删除工具的所有设置,仅保留最低限度。 不幸的是,yarn尚未学会在另一个文件中指定此名称,只有package.json。 有两个新选项,一个是新选项,另一个是强制性选项。 由于假定根存储库将永远不会发布,因此yarn要求在此处指定private = true。
但是工作空间的设置存储在同一密钥中。 该设置与lerna设置非常相似,这里有一个packages字段,您可以在其中指定软件包的位置,还有一个nohoist选项,与lerna中的nohoist选项非常相似。 只需指定这些设置并获得与lerna中相同的结构即可。 所有常见的依赖关系都移到了根目录,而nohoist键中指定的依赖关系仍处于其级别。

最好的部分是lerna可以处理纱线并调整其设置。 在lerna.json中指定两个字段就足够了,lerna会立即了解您正在使用yarn,进入package.json,从那里获取所有设置并使用它们。 这两个工具已经彼此了解并且可以一起工作。

如果这么多大公司使用单一存储库,为什么还没有在npm提供支持?

他们说一切都会实现,只是在第七版中。 基本支持在第七,扩展-在第八。 这个帖子是一个月前发布的,但与此同时,何时发布第七个npm的日期仍然未知。 我们正在等待他最终赶上纱线。
当您在一个单一存储库中有多个服务时,不可避免地会出现一个问题,即如何管理它们,以便不转到每个文件夹,而不运行命令? 为此有大量的操作。


Yarn有一个yarn工作区命令,后跟程序包的名称和命令的名称。 由于盒中的yarn与npm不同,可以完成所有三件事:运行自己的命令,添加对jest的依赖项,运行package.json中的脚本(例如test),以及运行node_modules / .bin文件夹中的可执行文件。 他将在启发式教学的帮助下教您,他将了解您的需求。 使用纱线工作区在一个包装上进行点操作非常方便。
有一个类似的命令,可让您在拥有的所有软件包上执行命令。

仅使用所有参数指示您的命令。

对于专业人士来说,经营不同的团队非常方便。 例如,在这些缺点中,不可能运行shell命令。 假设我要删除所有节点模块文件夹,则无法运行yarn工作区,运行rm。
无法指定软件包列表,例如,我只想依次或单独删除两个软件包中的依赖项。
好吧,他在第一个错误时就崩溃了。 如果我想从所有软件包中删除依赖关系-实际上,只有两个拥有依赖关系,但是我不想考虑它在哪里,而只是想删除它-然后yarn将不允许它,它将在第一种情况下崩溃该程序包不在依赖项中的位置。 这不是很方便,有时您想忽略所有程序包中的错误。

Lerna有一个更有趣的工具包,有两个单独的run和exec命令。 Run可以从package.json执行脚本,并且与yarn不同,它可以按包过滤所有内容,您可以指定--scope,可以使用星号,glob,所有内容都很通用。 您可以并行运行这些操作,可以通过--no-bail开关忽略错误。

Exec非常相似。 与yarn不同,它不仅允许您运行来自node_modules.bin的可执行文件,还可以执行任何任意的Shell命令。 例如,您可以随意删除node_modules或运行一些make。 并且支持相同的选项。

非常方便的工具,有些优点。 lerna在正确的抽象水平上撕裂纱线时就是这种情况。 这正是lerna所需要的:在monorepe中简化几个软件包的工作。
带有monorep的负数要少一。 当您拥有CI / CD时,就无法对其进行优化。 您拥有的服务越多,花费的时间就越长。 假设您开始测试每个池请求的所有服务,并且数量越多,工作时间就越长。 选择性操作可用于优化此过程。 我将列举三种不同的方式。 如果您出于某些原因不使用这些方法,则前两个方法不仅可以在monorep中使用,还可以在您的项目中使用。
第一个是lint-stages,它允许您仅对已更改或将在此提交中提交的文件运行linter,测试,所需的所有内容。 不在整个项目上运行整个lint,而仅在已更改的文件上运行。


设置非常简单。 放上短绒,沙哑,预先提交的钩子,并说在更改任何js文件时,您需要运行eslint。 因此,大大加快了提交前检查。 尤其是如果您有许多服务,则是非常大的单一存储库。 然后在所有文件上运行eslint太昂贵了,您可以通过这种方式优化lint上的precommit-hooks。

如果您在Jest上编写测试,则它也具有用于选择性运行测试的工具。

通过此选项,您可以为其提供源文件列表,并查找以某种方式影响这些文件的所有测试。 什么可以与lint-staged一起使用? 请注意,此处我未指定所有js文件,而仅指定了源文件。 我们不使用内部测试来排除js文件本身,我们仅查看源代码。 我们将启动findRelatedTests并极大地加速单元运行以进行预提交或预按您的期望。
第三种方法与单一存储库相关联。 这是lerna,可以确定与基本提交相比哪些软件包已更改。 这更可能与挂钩无关,而与您的CI / CD:Travis或您使用的其他服务有关。


run和exec命令具有since选项,该选项允许您仅在自某种提交以来已更改的软件包中运行任何命令。 在简单的情况下,如果将所有内容倒入向导中,则可以指定一个向导。 如果您想更准确地进行,最好通过CI / CD工具指定池请求的基本提交,这将是更诚实的测试。
由于lerna知道软件包中的所有依赖关系,因此它也可以检测间接依赖关系。 如果您更改了库B,该库A在服务B中使用,而库B在服务C中使用,则lerna会理解这一点。 , . , C — , . lerna .
, :
c lerna ,
yarn workspaces
.
, . , . . ? , , , . , , . , - . , Babel. , , . . , .
:
mishanga . , , . , .