家用铁上的AI
我们讨论如何将神经网络和面部识别系统的框架移植到俄罗斯Elbrus处理器。
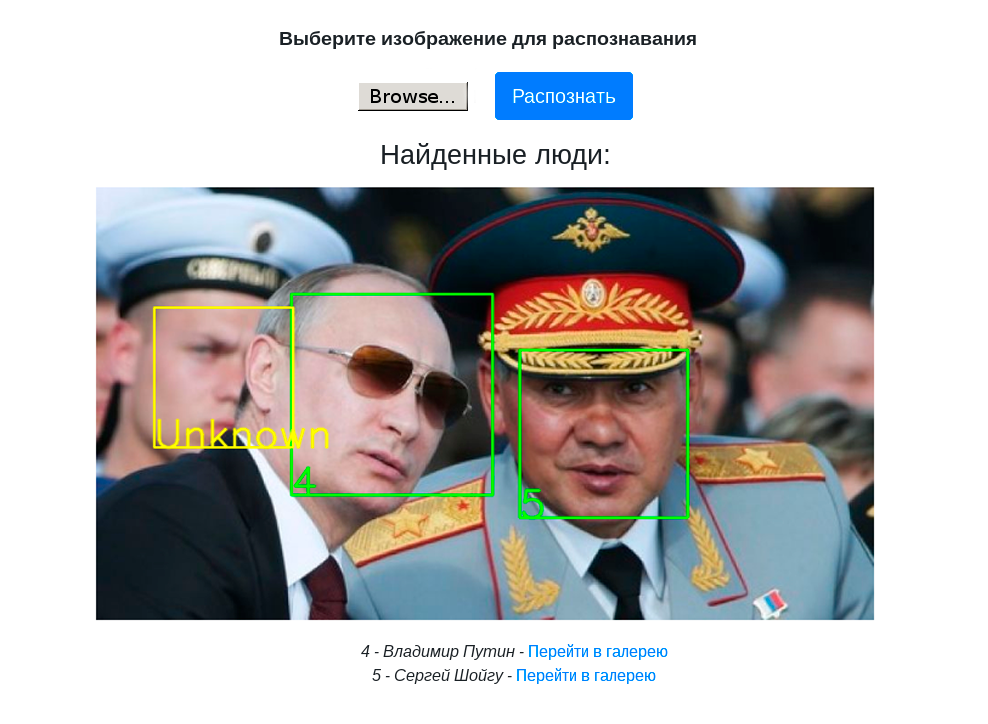
这是一项有趣的任务,在2019年春季,我们在Yandex办公室关于Elbrus的大型会议上讨论了这一问题,现在我们正在与Habr分享。
简要地说-什么是Elbrus
这是在
MCST开发的具有自己架构的俄罗斯处理器。 Maxim Gorshenin在他的频道上对他的评价很好:
www.youtube.com/watch?v = H8eBgJ58EPY简要地说-什么是PuzzleLib
这是我们自2015年以来一直在开发和使用的神经网络平台。 类似于Google TensorFlow和Facebook PyTorch。 有趣的是,PuzzleLib不仅支持NVIDIA和Intel处理器,而且还支持AMD视频卡。
尽管我们有一个小型图书馆(TensorFlow大约有200万行,但我们有10万行),但我们的速度更好-有点,但更好=)
我们尚未开源,该库用于我们的项目。 该库很完整:它支持神经网络的训练阶段和推理阶段。 您可以构建循环卷积神经网络,还有一个用于创建任意计算图的界面。
PuzzleLib有
- 用于组装神经网络的模块(激活(Sigmoid,Tanh,ReLU,ELU,LeakyReLU,SoftMaxPlus),AvgPool(1D,2D,3D),BatchNorm(1D,2D,3D,ND),Conv(1D,2D,3D,ND) ,CrossMapLRN,Deconv(1D,2D,3D,ND),Dropout(1D,2D)等)
- 优化程序(AdaDelta,AdaGrad,Adam,Hooks,LBBFG,MomentumSGD,NesterovSGD,RMSProp等)
- 即用型神经网络(Resnet,Inception,YOLO,U-Net等)
对于神经网络的所有相关人员来说,这些是熟悉的,熟悉的内容,是神经网络设计人员的模块(因为任何框架都是由典型的计算模块和算法组成的构造函数)。
我们有一个想法来启动关于Elbrus体系结构的库。
我们为什么要支持Elbrus?
- 这是唯一的俄语处理器,我想了解它的运行情况以及使用它的难度。
- 我们认为,对于国家组织来说,我们正在开发的俄语软件可以在俄语硬件上运行可能会很有趣。
- 当然,我们只是感兴趣,因为Elbrus是VLIW处理器 ,也就是说,具有长指令的处理器,而且世界上还没有这样成熟的通用处理器。
一切始于我们与MCST会面,交谈并借出
Elbrus 401计算机进行开发的事实。
我喜欢的东西 :Linux在Elbrus上运行,该Linux中有python,它不能在仿真模式下工作-它是为Elbrus组装的完整的本机python。 还有一大堆标准python库,例如numpy,所有开发人员都非常喜欢。
还有一些任务需要我们另外收集库:例如,在PuzzleLib中,我们使用hdf格式存储神经网络的权重,因此,我们必须使用lcc编译器来构建libhdf和h5py库。 但是我们没有组装问题。
OpenCV计算机视觉库也已经编译,但是python没有绑定到它-我们单独构建了它。
著名的dlib库也很容易编译。 仅有一些小困难:这个开源项目的某些文件没有用于确定utf-8的bom标记,这使lcc lexer感到不适。 实际上,仅存在一种不正确的文件格式,必须在源文件中对其进行更正。
我们决定首先开始人脸识别。 对于使用这种技术的许多人来说,这是一个可以理解的用例。 像其他库一样,PuzzleLib具有相当大的后端部分,即特定于不同处理器体系结构的代码库。
我们的后端:- CUDA(NVIDIA)
- 打开CL + MI打开(AMD)
- mlkDNN(Intel)
- CPU(numpy)
在Elbrus上,我们启动了一个numpy后端,这非常简单,因为该平台几乎不需要任何东西:
平台-> c90编译器-> python-> numpy我们拥有一个没有任何复杂因素的库(例如,没有任何特殊的组装系统),此外我们还需要收集某些活页夹。 我们进行了测试,一切正常-卷积网格和递归网格。 基于Inception-ResNet,我们启动的面部识别非常简单。
工作的初步结果在Intel Core i7 7700上,一幅图像的处理时间为0.1秒,此处为15。必须进行优化。
当然,希望numpy能够在运行中正常运行是错误的。
我们如何优化计算
我们通过python探查器测量了推理速度,发现几乎所有时间都花在乘以numpy中的矩阵上。 对于该示例,他们编写了矩阵的最简单的手动乘法,尽管结果不清楚,但事实证明它更快。
看起来numpy.dot应该比这种简单的乘法少一些天真。 尽管如此,我们还是确信,检查-结果更快(每帧12秒而不是15秒)。
接下来,我们了解了由ICST开发的线性代数库EML,并用cblas_sgemm替换了np.dot调用。 它变得快了10倍(1.5秒)-我们感到非常高兴。
接下来是一些逐步优化。 由于我们仅运行人脸识别,而不是一般的任意数据,因此我们决定仅在4d张量下优化我们的操作,然后进行Fusion处理(此后处理时间减少2倍)至0.75秒。
说明:融合是将几种操作组合在一起的一种操作,例如,卷积,规范化和激活。 而不是在三个循环中通过,而是执行一次通过。
此类库可从NVIDIA(
TensorRT )获得。 将计算图加载到其中,并且库会生成优化的加速图,特别是由于它可以将操作折叠为一个事实。 英特尔也有类似的产品(nGraph和
OpenVINO )。
然后我们看到,由于Inception-ResNet中存在许多1x1卷积,因此我们进行了额外的数据复制。 我们决定专注于以下事实:我们从1张照片开始批量处理(即,不批量处理100张照片,而是提供流式传输模式)-在某些用例中,您不需要使用存档,而是使用流(例如,用于视频监控或ACS)。 我们创建了一个不
包含im2col的专业文章(已删除大量副本)-变为0.45秒。
然后我们再次查看分析器,我们以相同的方式进行操作-尽管所有阶段的时间都缩短了,但我们仍然有80%的时间花在了卷积推理块的计算上。
我们意识到我们需要并行化
gemm (通用矩阵乘法)。 在EML中,该gemm原来是单线程的。 因此,我们必须自己编写多线程的gemm。 想法是这样的:将大矩阵划分为子块,然后将这些小矩阵相乘。 我们用OpenMP编写了一个gemm,但是它不起作用,错误崩溃了。 我们采用了一个手动线程池,并行化每帧提供0.33秒的时间。
接下来,我们可以使用
Elbrus 8C远程访问功能更强大的服务器,其速度提高到每帧0.2秒。
以下视频显示了带Elbrus 4C处理器的Elbrus 401-PC计算机上具有面部识别功能的演示台的工作:
结论和未来计划
- 我们不仅在工作上进行人脸识别,而且在原则上是神经网络框架,因此我们可以收集任何检测器,分类器并在Elbrus上运行它们。
- 我们已经使用Web-UI组装了一个演示台,以在PuzzleLib上演示人脸识别。
- Elbrus上的人脸识别已经足够快,可以完成实际任务,然后可以根据需要加快速度。
- 您可以与Elbrus合作。 我们曾经使用过奇异的处理器-例如,使用仍在开发中的张量俄罗斯处理器,AMD视频卡及其软件。 那里的一切都不那么好简单。 也就是说,如果我们采用AMD的MI Open库,这是一个编写得很差的库,其中跨步,填充和过滤器大小的所有组合都无法成功进行计算。 Elbrus的工具质量很好-如果您有Python,C或C ++项目,那么在Elbrus上运行它一点也不难。
- 还值得注意的是,我们谈到的逐步优化工作并不是在Elbrus中进行特定的操作。 这些是标准的多核处理器操作。 我们认为,这是一个很好的信号,表明该处理器可以与Intel / NVIDIA的常规处理器一起使用。
计划:
- 由于Elbrus具有VLIW处理器的特殊性,因此可以执行某些针对Elbrus的优化。
- 进行量化(使用int8而不是float32),这可以节省内存并提高速度。 因此,在这种情况下,当然可能会降低计算质量,但事实并非如此。 在实践中我们注意到了这两种情况。
我们计划进一步了解,探索VLIW处理器的功能。 实际上,到目前为止,我们只是信任编译器,因为如果我们编写良好的代码,则编译器会对其进行优化,因为它了解Elbrus的功能。
总的来说,这很有趣,我们将进一步理解。 这并没有花费太多时间-所有移植操作总共花费了一周的时间。
在2020年1月,我们计划将PuzzleLib放到开源中,我们将在这里写更多信息=)
感谢您的关注!