本指南和以下指南将指导您完成基于Discovery.js项目的解决方案的创建过程。 我们的目标是为NPM依赖关系创建一个检查器,即用于检查node_modules结构的node_modules 。
注意:Discovery.js处于开发的早期阶段,因此随着时间的流逝,某些事情将会简化并变得更加有用。 如果您有关于如何改进的想法,请给我们写信 。
注解
您将在下面找到Discovery.js关键概念的概述。 您可以在GitHub上的存储库中了解整个手册代码,也可以尝试在线使用它 。
初始条件
首先,我们需要选择一个项目进行分析。 这可以是新创建的项目,也可以是现有的项目,主要是它包含node_modules (我们分析的对象)。
首先,安装discoveryjs核心软件包及其控制台工具:
npm install @discoveryjs/discovery @discoveryjs/cli
接下来,启动Discovery.js服务器:
> npx discovery No config is used Models are not defined (model free mode is enabled) Init common routes ... OK Server listen on http://localhost:8123
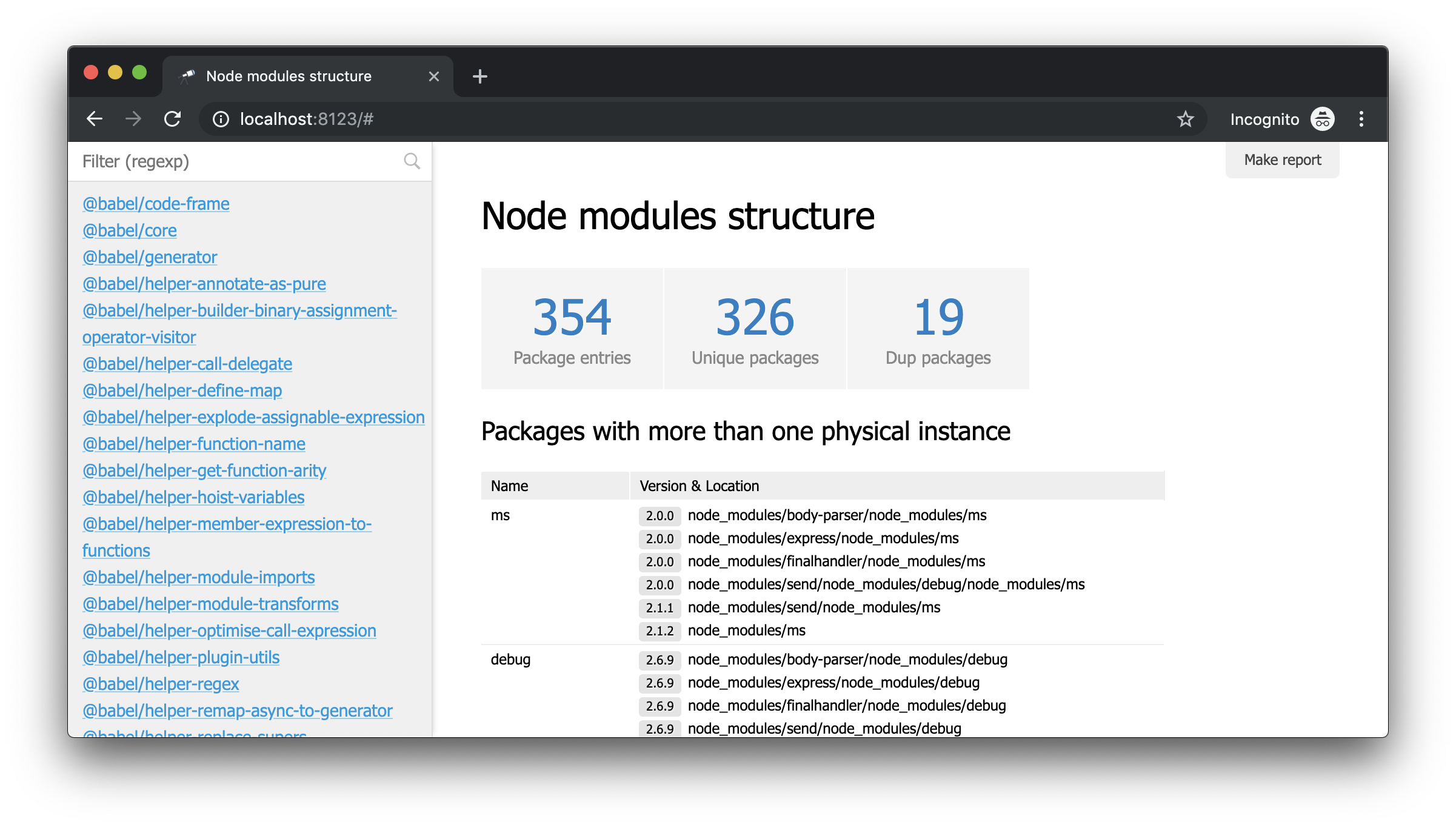
如果在浏览器中打开http://localhost:8123 ,则可以看到以下内容:

这是没有模型的模式,即没有任何配置的模式。 但是现在,使用“加载数据”按钮,您可以选择任何JSON文件,也可以将其拖到页面上并开始分析。
但是,我们需要一些特定的东西。 特别是,我们需要获取node_modules结构的视图。 为此,请添加配置。
添加配置
您可能已经注意到,服务器启动时会显示消息No config is used 。 让我们创建一个.discoveryrc.js配置文件,其中包含以下内容:
module.exports = { name: 'Node modules structure', data() { return { hello: 'world' }; } };
注意:如果您在当前工作目录(即项目的根目录)中创建文件,则不需要任何其他操作。 否则,您需要使用--config选项将路径传递到配置文件,或在package.json设置路径:
{ ... "discovery": "path/to/discovery/config.js", ... }
重新启动服务器,以便应用配置:
> npx discovery Load config from .discoveryrc.js Init single model default Define default routes ... OK Cache: DISABLED Init common routes ... OK Server listen on http://localhost:8123
如您所见,现在使用了我们创建的文件。 并且应用了我们描述的默认模型(发现可以在许多模型的模式下工作,我们将在以下手册中讨论此功能)。 让我们看看浏览器中发生了什么变化:
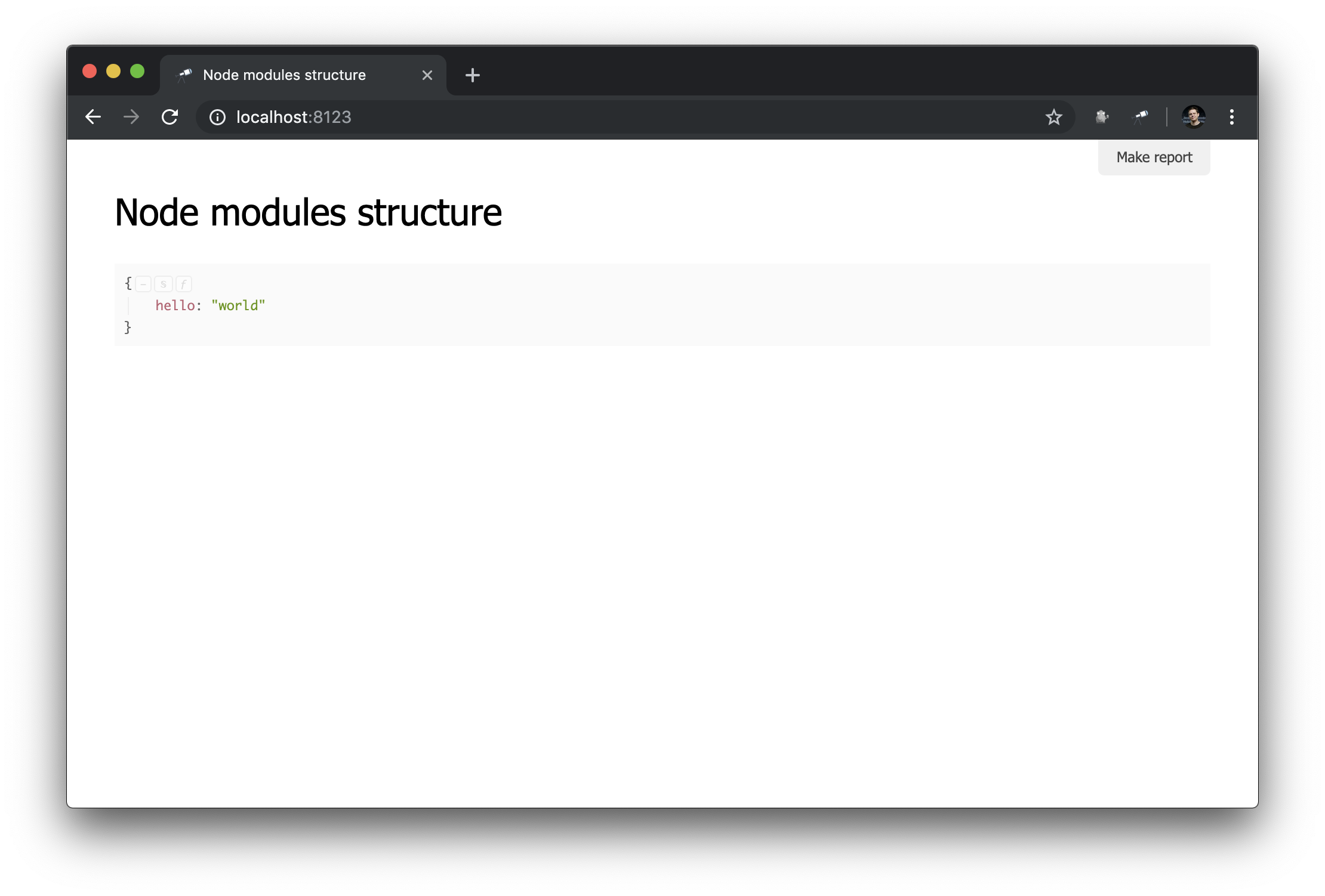
在这里可以看到:
name用作页面标题;- 调用
data方法的结果显示为页面的主要内容。
注意: data方法必须返回data或Promise,然后解析为data。
基本设置已完成,您可以继续。
语境
让我们看一下自定义报告页面(点击生成Make report ):
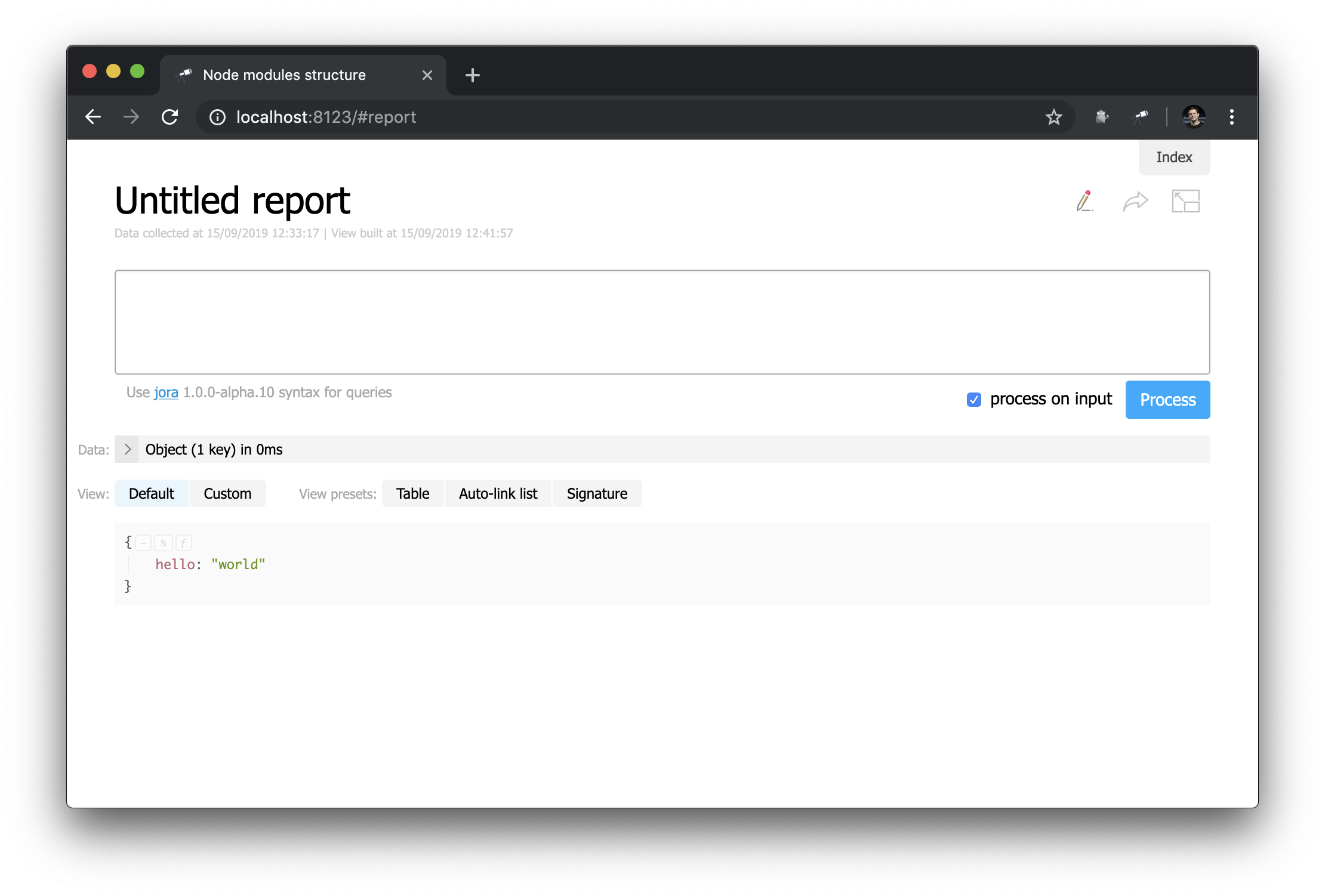
乍一看,这与开始页面并没有太大的区别……但是您可以在此处进行所有更改! 例如,我们可以轻松地重新创建起始页面的外观:
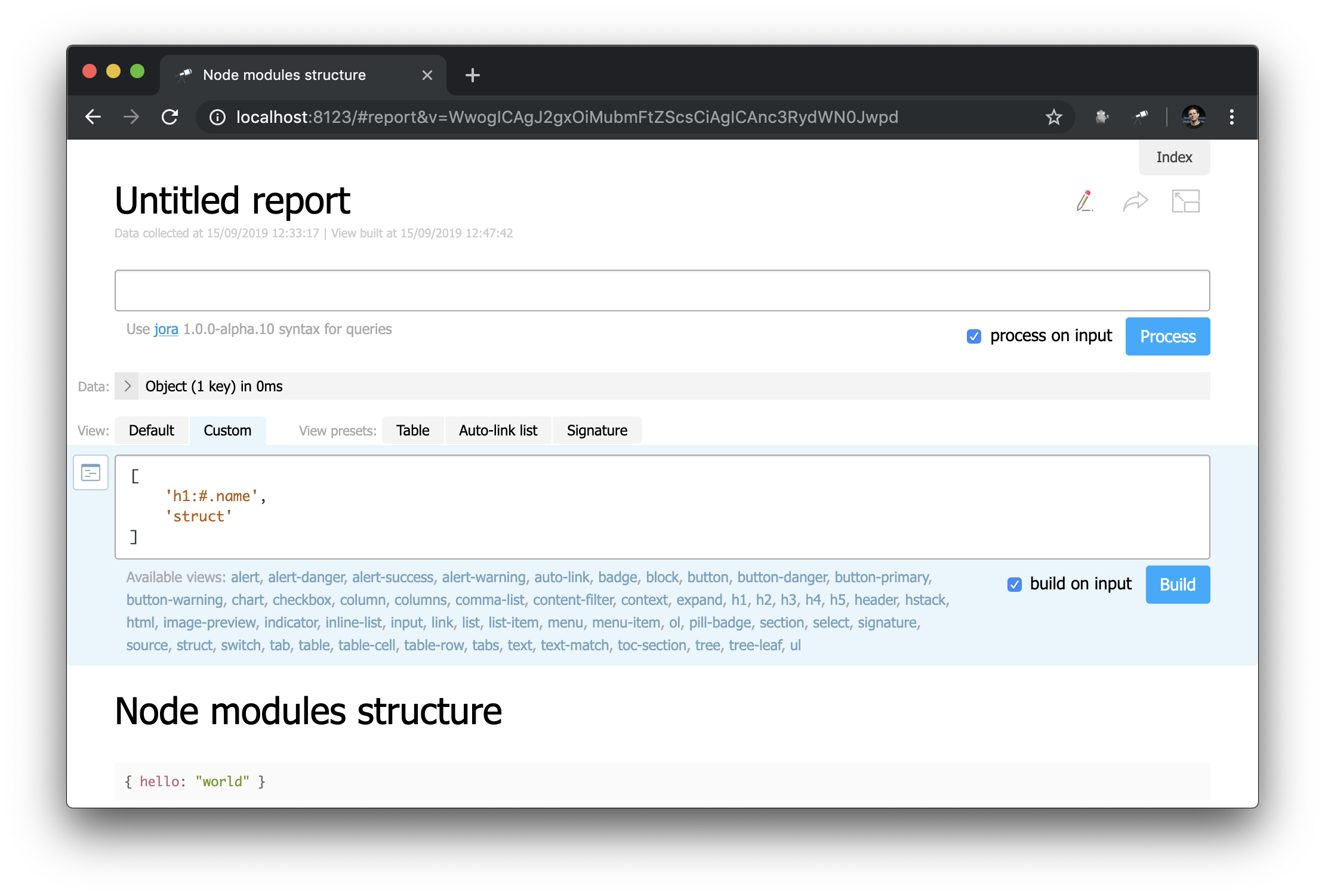
请注意标题的定义方式: "h1:#.name" 。 这是具有#.name内容的第一级标头,这是一个Jora请求。 #表示请求上下文。 要查看其内容,只需在查询编辑器中输入#并使用默认显示:
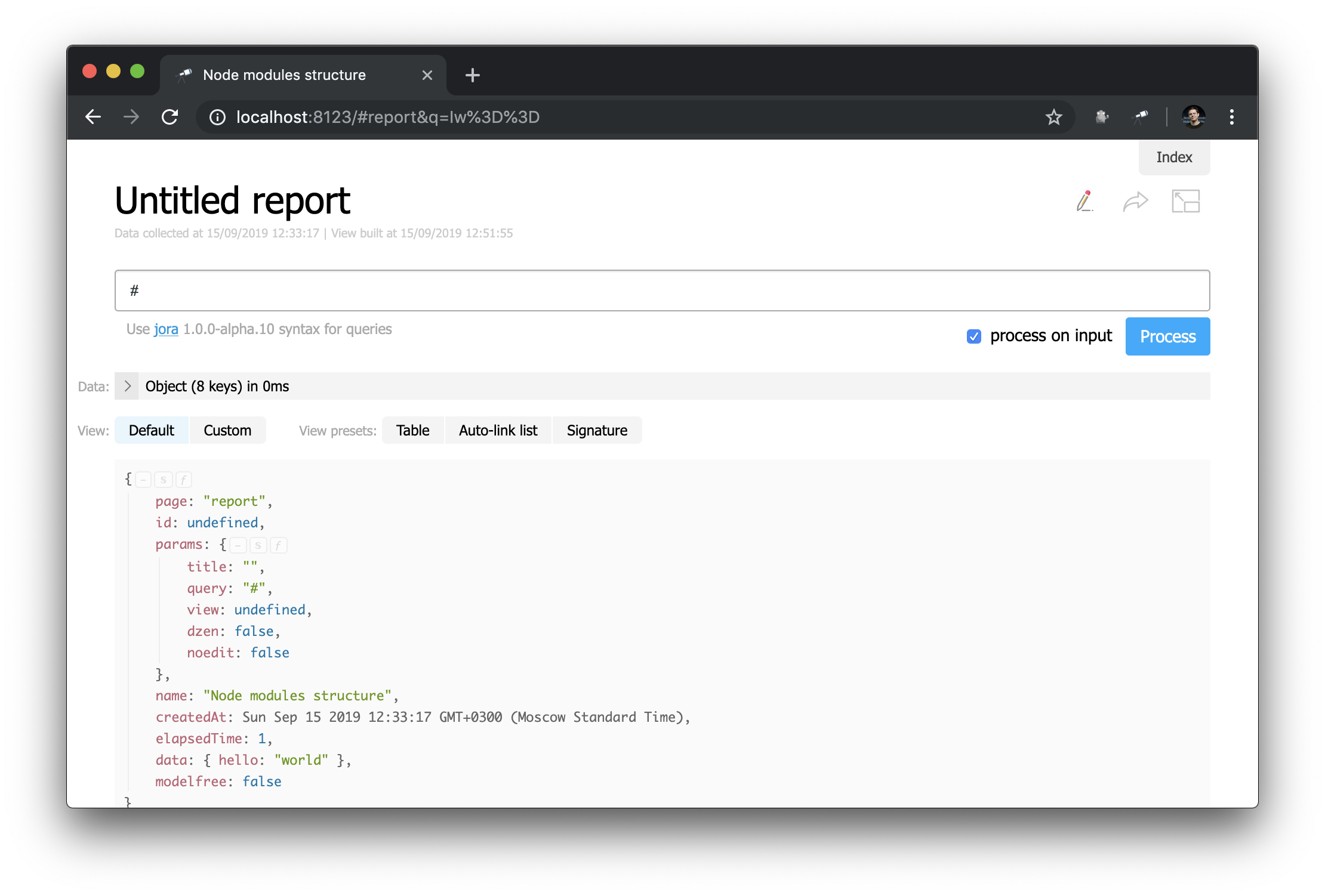
现在,您知道如何获取当前页面的ID,其参数和其他有用的值。
资料收集
现在,我们在项目中使用存根而不是真实数据,但是我们需要真实数据。 为此,请创建一个模块并在配置中更改data值(顺便说一下,在进行这些更改之后,无需重新启动服务器):
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data') };
collect-node-modules-data.js :
const path = require('path'); const scanFs = require('@discoveryjs/scan-fs'); module.exports = function() { const packages = []; return scanFs({ include: ['node_modules'], rules: [{ test: /\/package.json$/, extract: (file, content) => { const pkg = JSON.parse(content); if (pkg.name && pkg.version) { packages.push({ name: pkg.name, version: pkg.version, path: path.dirname(file.filename), dependencies: pkg.dependencies }); } } }] }).then(() => packages); };
我使用了@discoveryjs/scan-fs软件包,该软件包简化了文件系统扫描。 在自述文件中描述了使用该软件包的示例,我以此示例为基础并根据需要最终确定。 现在我们有了一些有关node_modules内容的node_modules :
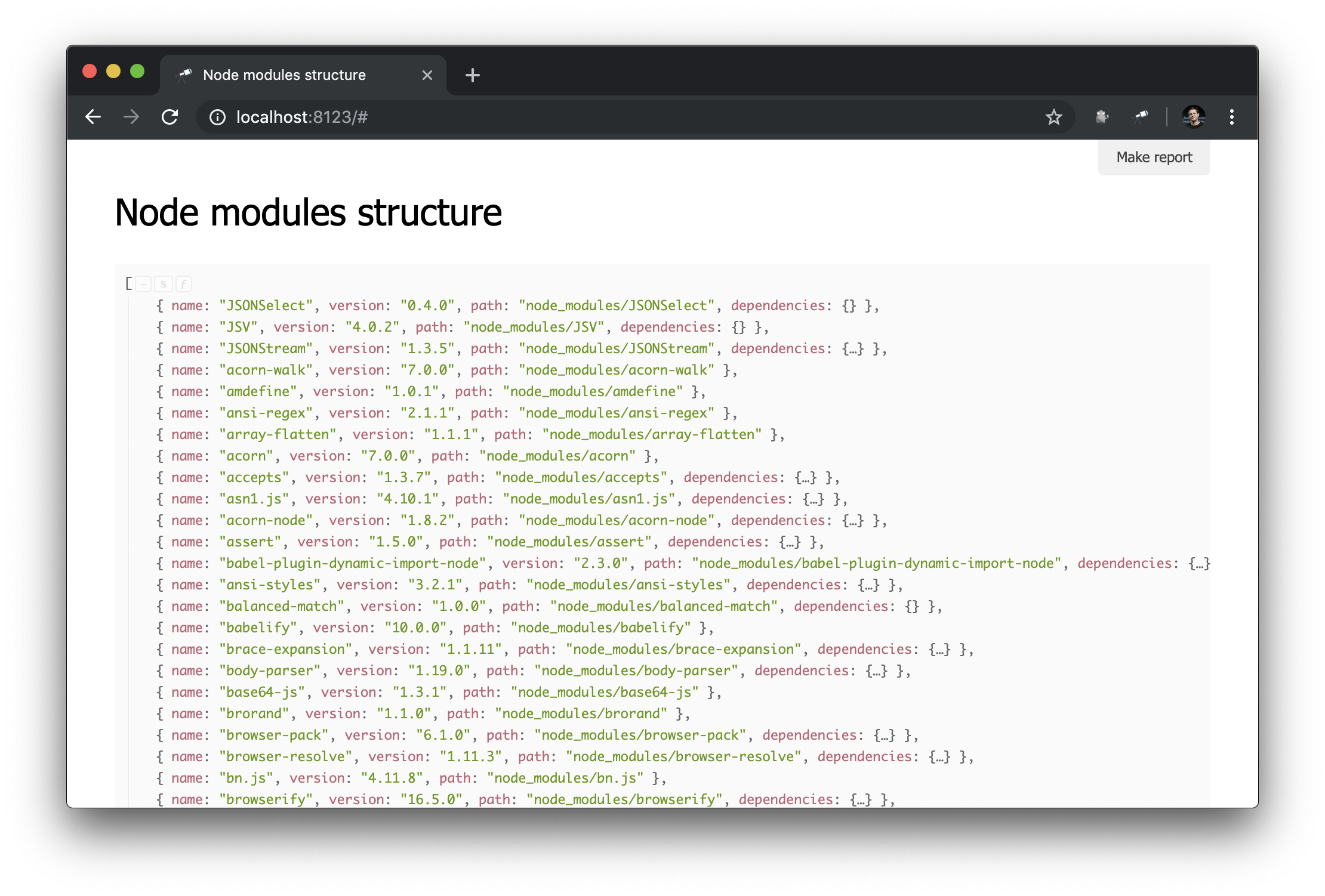
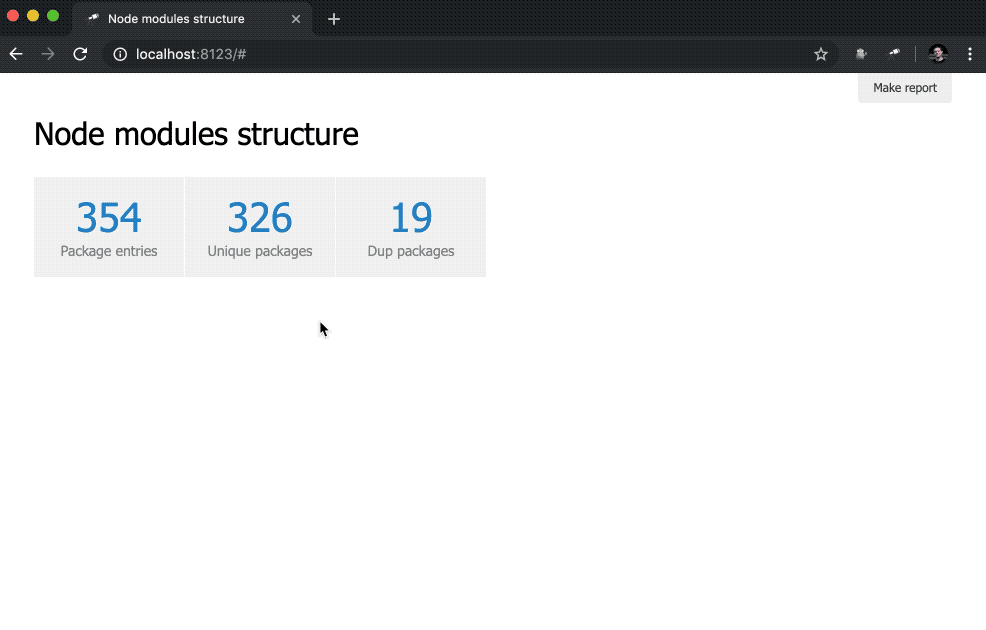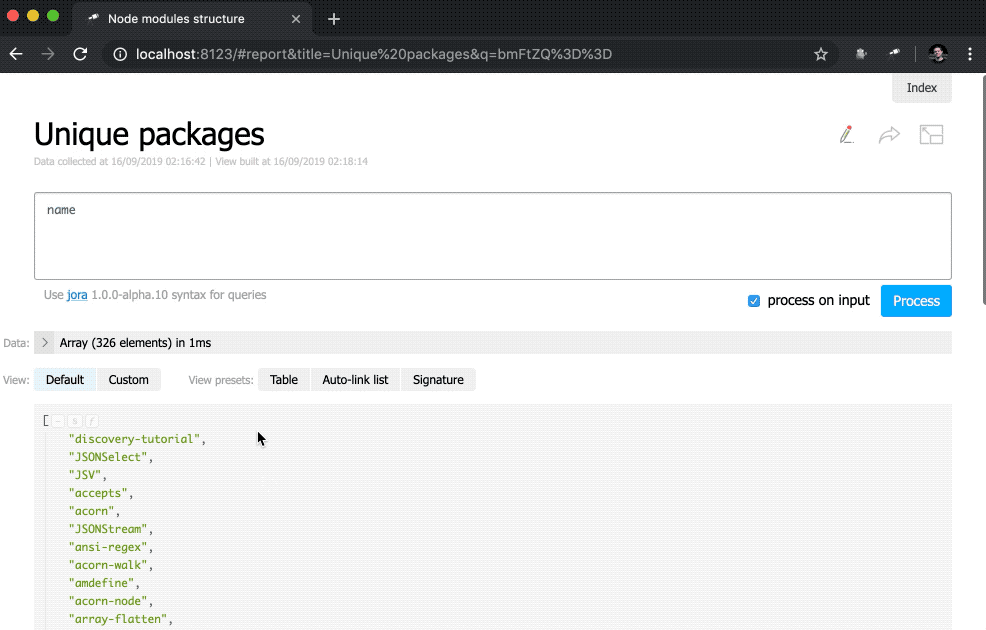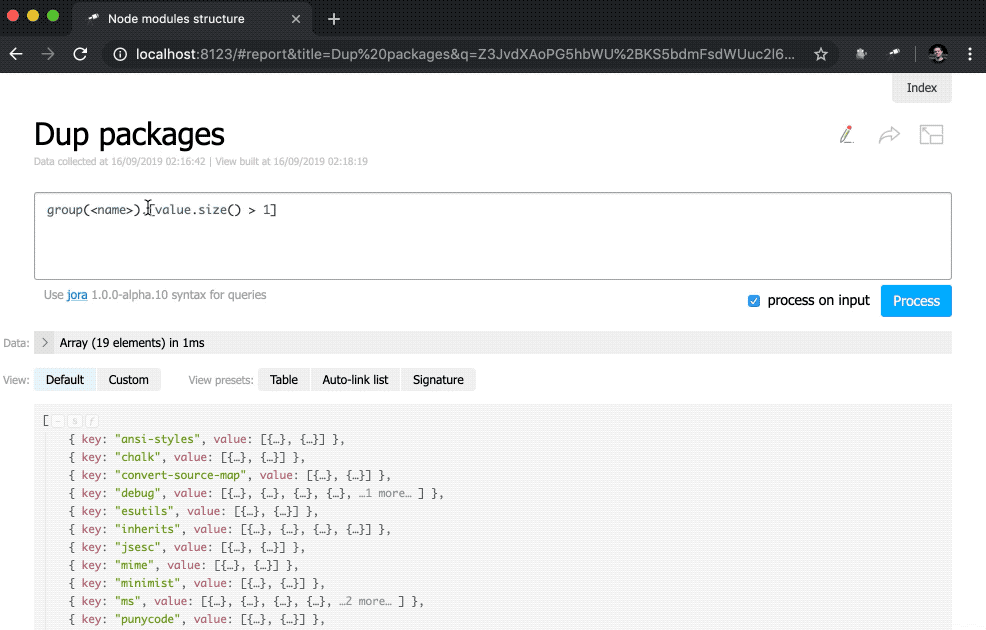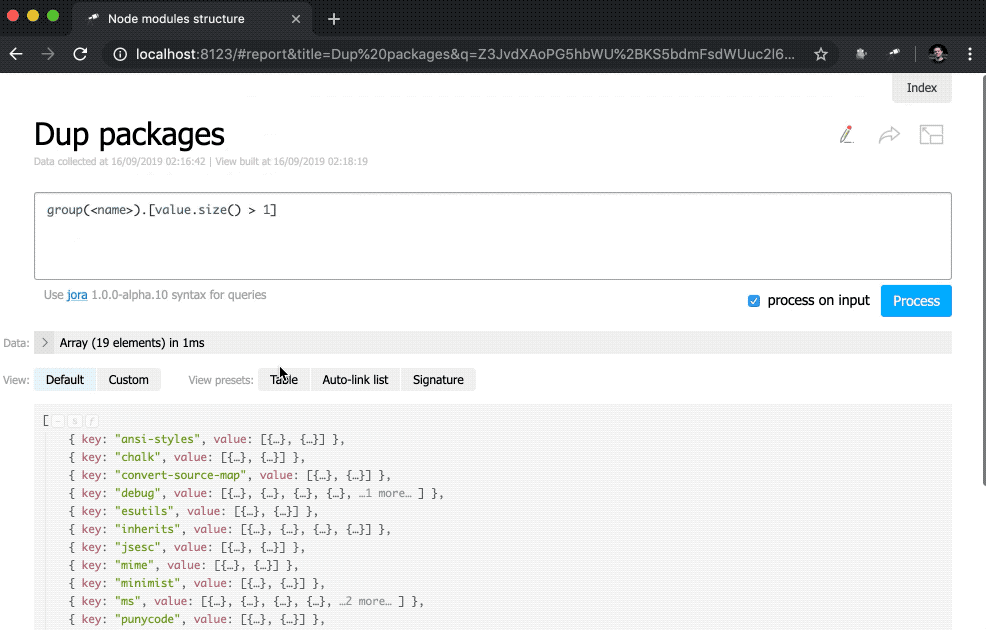
你需要什么! 尽管这是普通的JSON,但我们已经可以对其进行分析并得出一些结论。 例如,使用数据结构的弹出窗口,您可以找出数据包的数量,并找出其中有多个物理实例的数据包(由于版本差异或重复数据删除问题)。
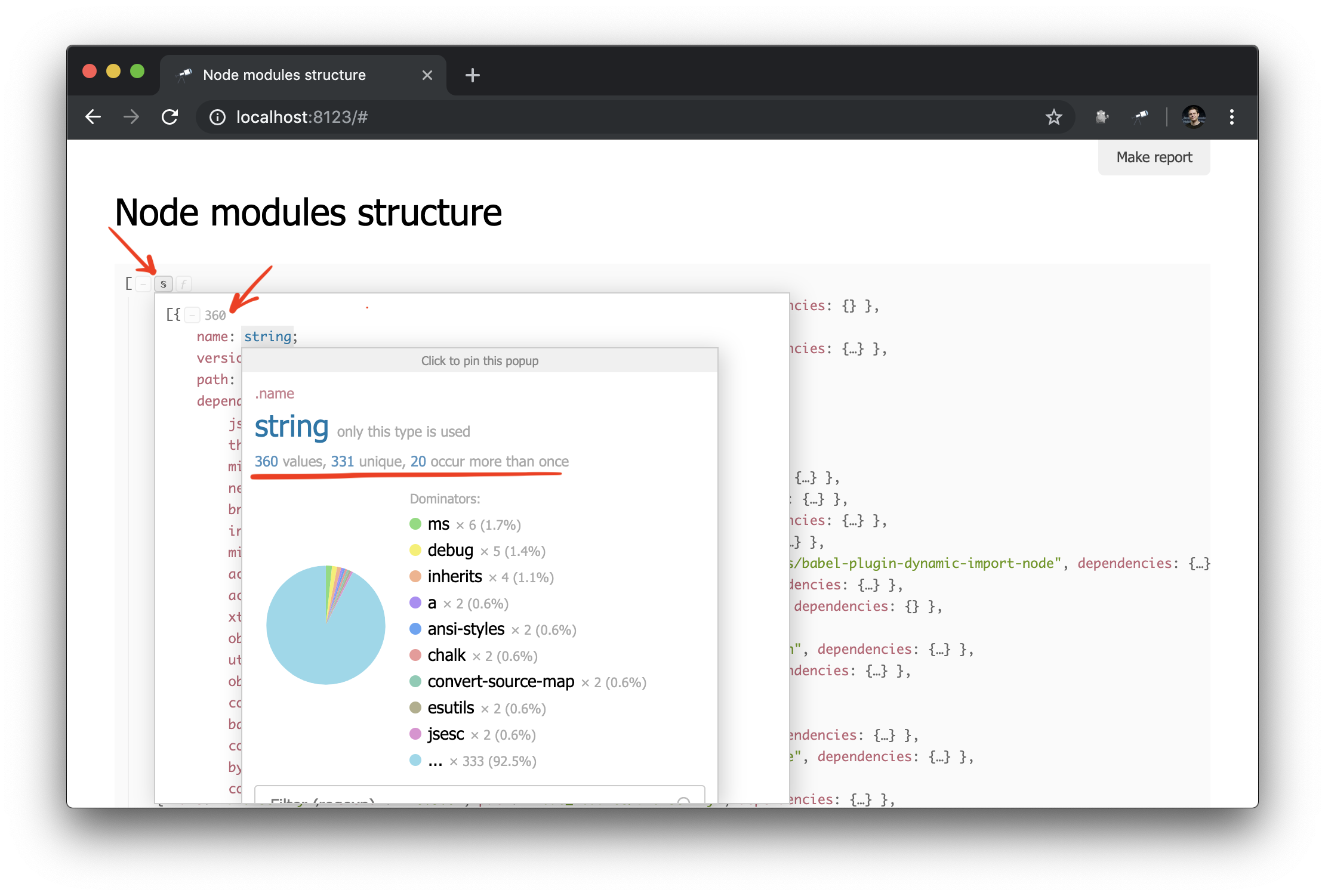
尽管我们已经有了一些数据,但我们需要更多详细信息。 例如,很高兴知道哪个物理实例可以解析特定模块的每个声明的依赖关系。 但是,改进数据提取的工作不在本指南的范围之内。 因此,我们将其替换为@discoveryjs/node-modules程序包(它也基于@discoveryjs/scan-fs )以检索数据并获取有关程序包的必要详细信息。 结果,大大简化了collect-node-modules-data.js :
const fetchNodeModules = require('@discoveryjs/node-modules'); module.exports = function() { return fetchNodeModules(); };
现在,有关node_modules的信息如下所示:
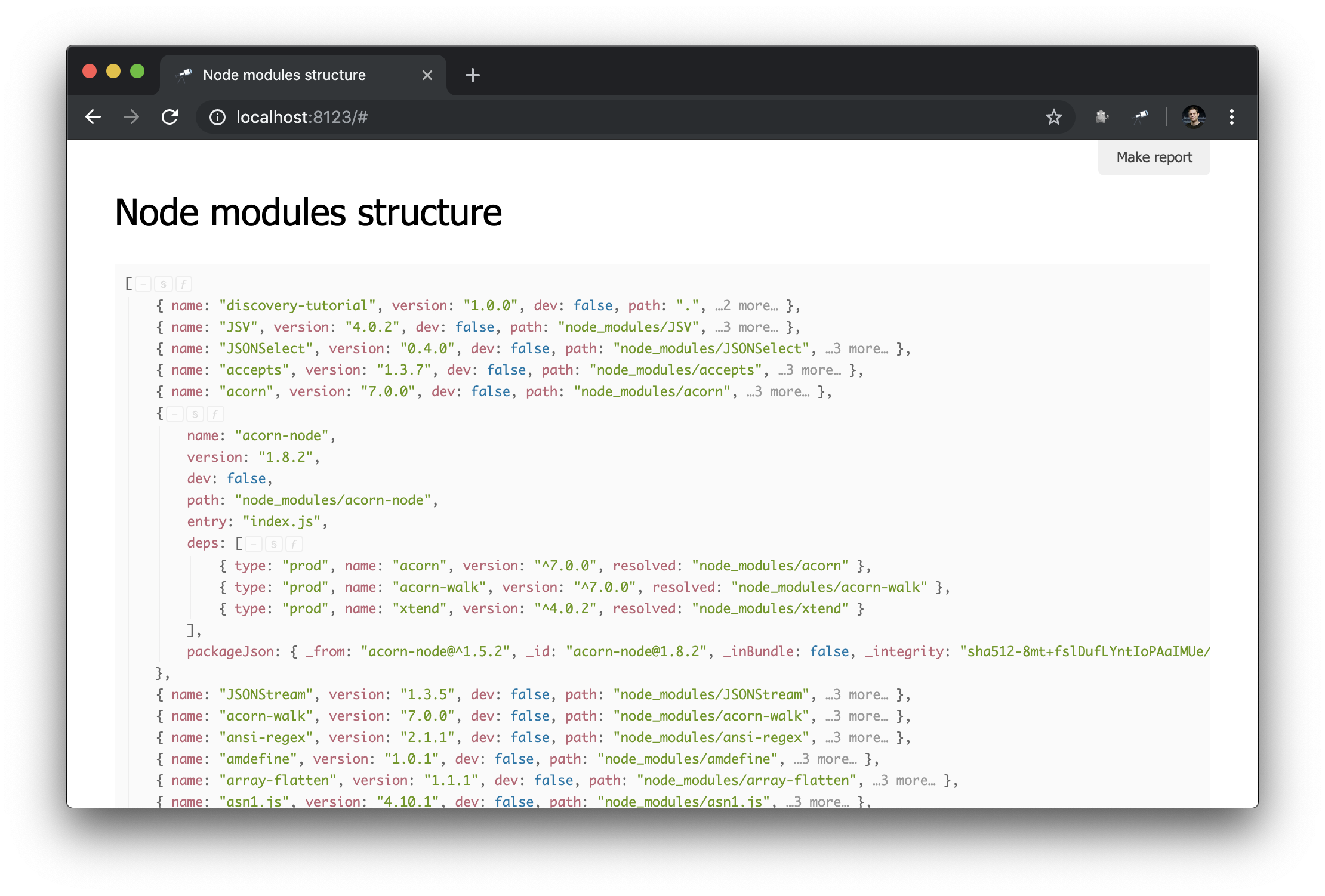
准备脚本
您可能已经注意到,一些描述软件包的对象包含deps依赖关系列表。 每个依赖项都有一个可resolved字段,其值是对包物理实例的引用。 这样的链接是包之一的path值,它是唯一的。 要解析到包的链接,您需要使用其他代码(例如, #.data.pick(<path=resolved>) )。 当然,如果这样的链接已被解析为对象引用,将会更加方便。
不幸的是,在数据收集阶段,我们无法解析链接,因为这将导致循环连接,这将产生以JSON形式传输此类数据的问题。 但是,有一个解决方案:这是一个特殊的prepare脚本。 它在配置中定义,并在每次将新数据分配给发现实例时调用。 让我们从配置开始:
module.exports = { ... prepare: __dirname + '/prepare.js',
定义prepare.js :
discovery.setPrepare(function(data) {
在此模块中,我们为发现实例定义了prepare函数。 每次在将数据应用于发现实例之前都会调用此函数。 这是允许在对象引用中使用值的好地方:
discovery.setPrepare(function(data) { const packageIndex = data.reduce((map, pkg) => map.set(pkg.path, pkg), new Map()); data.forEach(pkg => pkg.deps.forEach(dep => dep.resolved = packageIndex.get(dep.resolved) ) ); });
在这里,我们创建了一个包索引,其中的键是包path值(唯一)。 然后,我们遍历所有包及其依赖项,并在依赖项中将resolved值替换为对包对象的引用。 结果:
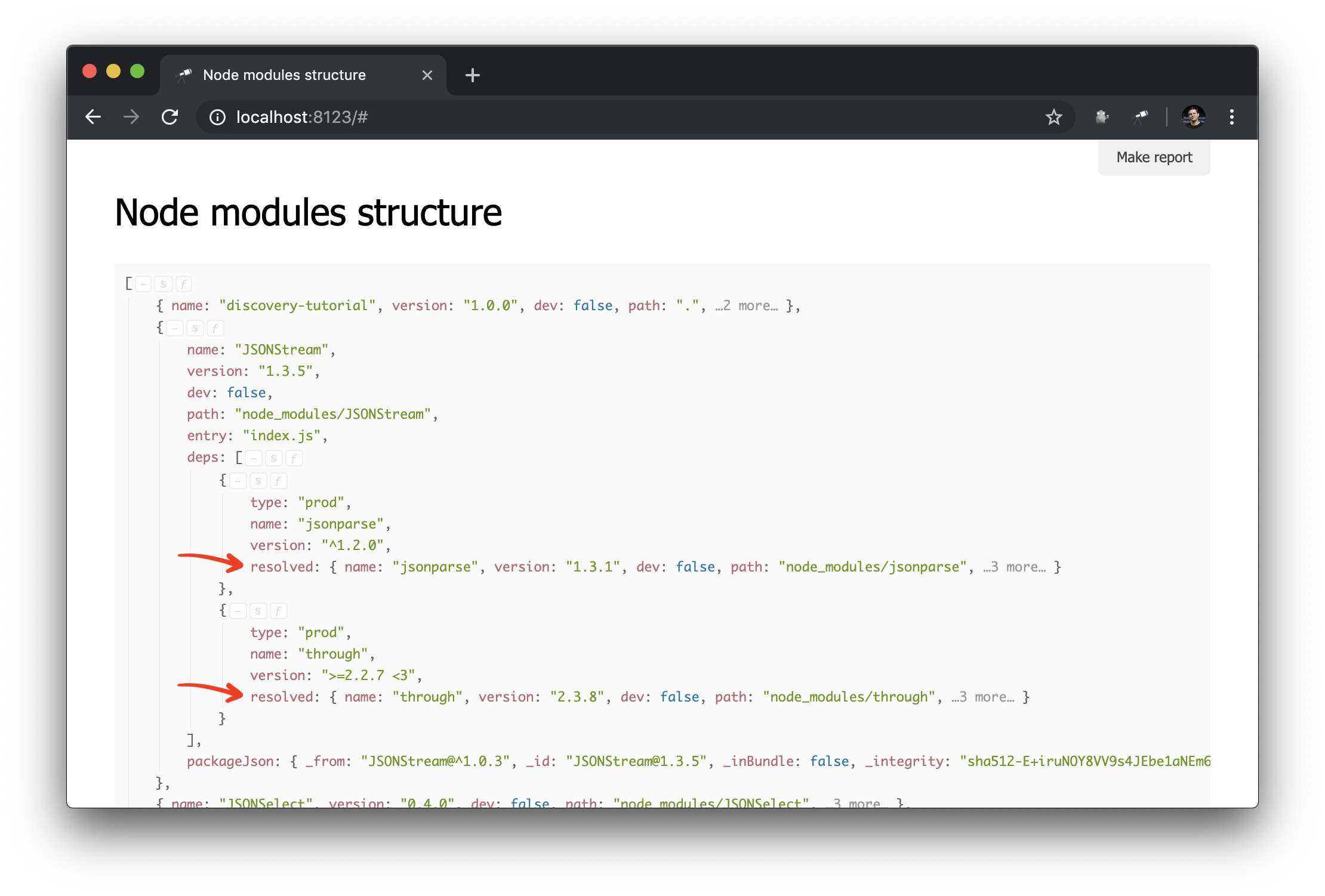
现在,进行依赖关系图查询要容易得多。 这是如何获取特定程序包的依赖项群集(即依赖项,依赖项依赖项等)的方法:
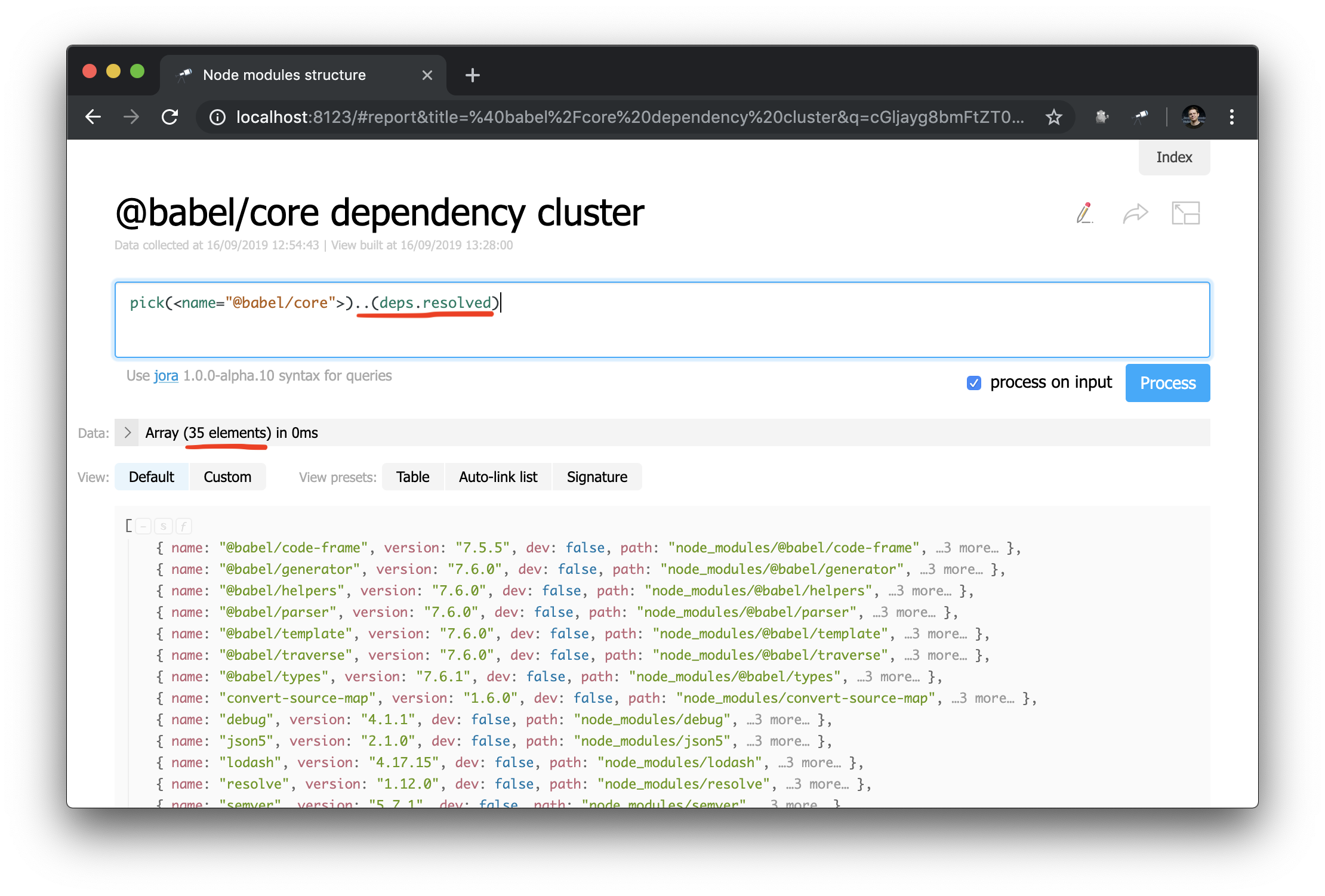
一个出乎意料的成功故事:在编写本手册期间研究数据时,我在@discoveryjs/cli发现了一个问题(使用查询.[deps.[not resolved]] ),该问题在peerDependencies中有错字。 该问题立即得到解决 。 该案例是此类工具如何提供帮助的一个很好的例子。
也许现在是时候在首页上显示几个编号和包装的价格。
自定义起始页
首先,我们需要创建一个页面模块,例如pages/default.js 。 我们使用default ,因为这是起始页面的标识符,我们可以覆盖它(在Discovery.js中,您可以覆盖很多东西)。 让我们从简单的例子开始,例如:
discovery.page.define('default', [ 'h1:#.name', 'text:"Hello world!"' ]);
现在,在配置中,您需要连接页面模块:
module.exports = { name: 'Node modules structure', data: require('./collect-node-modules-data'), view: { assets: [ 'pages/default.js'
签入浏览器:
有效!
现在让我们得到一些计数器。 为此,请更改pages/default.js :
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', item: 'indicator', data: `[ { label: 'Package entries', value: size() }, { label: 'Unique packages', value: name.size() }, { label: 'Dup packages', value: group(<name>).[value.size() > 1].size() } ]` } ]);
在这里,我们定义了指标的内联列表。 data值是创建记录数组的Jora查询。 软件包列表(数据根)用作查询的基础,因此我们获得列表长度( size() ),唯一软件包名称的数量( name.size() )和重复的软件包名称的数量( group(<name>).[value.size() > 1].size() )。
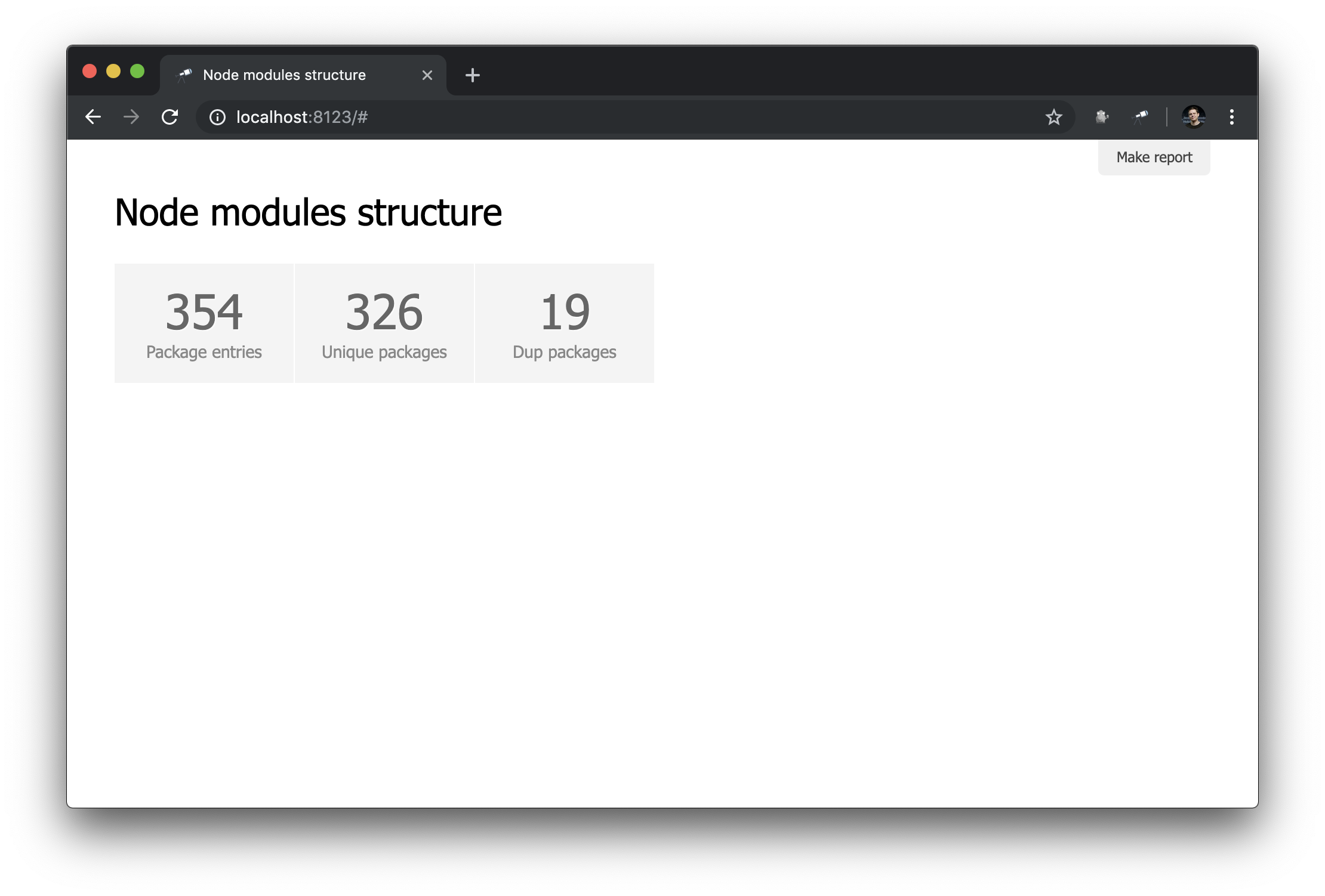
还不错 尽管如此,最好还有链接到相应样本的链接:
discovery.page.define('default', [ 'h1:#.name', { view: 'inline-list', data: [ { label: 'Package entries', value: '' }, { label: 'Unique packages', value: 'name' }, { label: 'Dup packages', value: 'group(<name>).[value.size() > 1]' } ], item: `indicator:{ label, value: value.query(#.data, #).size(), href: pageLink('report', { query: value, title: label }) }` } ]);
首先,我们更改了data的值,现在它是带有某些对象的常规数组。 此外, size()方法已从值请求中删除。
此外,子查询已添加到indicator视图。 这些类型的查询会为其中计算了value和href每个元素创建一个新对象。 对于value ,将使用query()方法执行query() ,从上下文将数据传输到该查询,然后将size()方法应用于查询结果。 对于href ,使用pageLink()方法,该方法生成具有特定请求和标题的报告页面的链接。 在完成所有这些更改之后,指示器变为可单击的(请注意,其值已变为蓝色),并且更具功能性。
为了使起始页更有用,请添加包含重复包的表。
discovery.page.define('default', [
该表使用与“ Dup packages指示器相同的数据。 软件包列表按组大小反向排列。 其余设置与列相关(顺便说一下,通常无需配置)。 对于“ Version & Location列,我们定义了一个嵌套列表(按版本排序),其中每个元素都是一对版本号和实例路径。
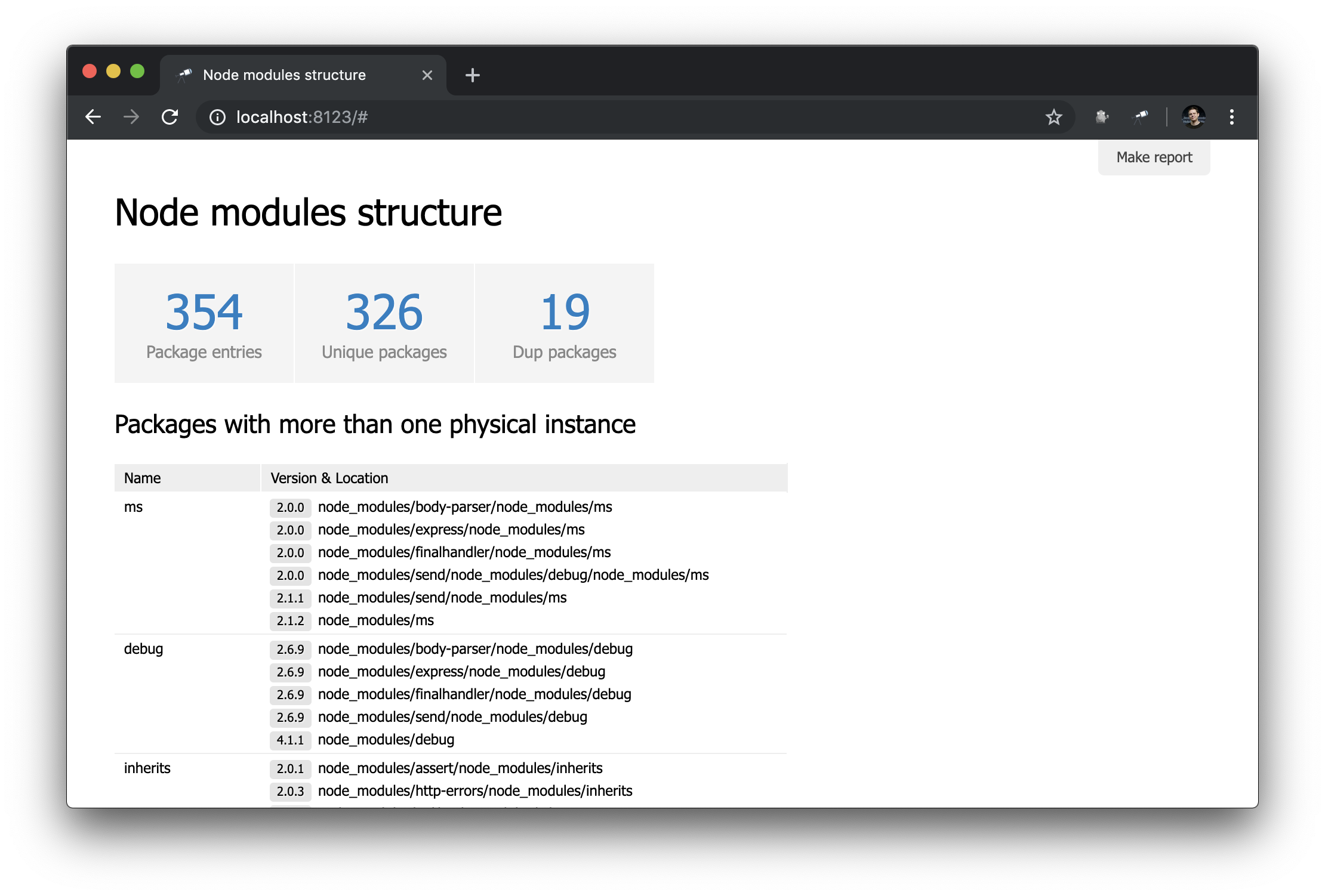
套餐页面
现在,我们只有软件包的一般概述。 但是,提供一个页面,其中包含有关特定软件包的详细信息将很有用。 为此,创建一个新的模块pages/package.js并定义一个新页面:
discovery.page.define('package', { view: 'context', data: `{ name: #.id, instances: .[name = #.id] }`, content: [ 'h1:name', 'table:instances' ] });
在此模块中,我们使用标识符package定义了页面。 context组件用作初始表示。 这是一个非可视的组件,可以帮助您定义嵌套映射的数据。 请注意,我们使用#.id来获取包的名称,该包的名称是从类似http://localhost:8123/#package:{id}的URL中检索的。
不要忘记在配置中包括新模块:
module.exports = { ... view: { assets: [ 'pages/default.js', 'pages/package.js'
结果在浏览器中:
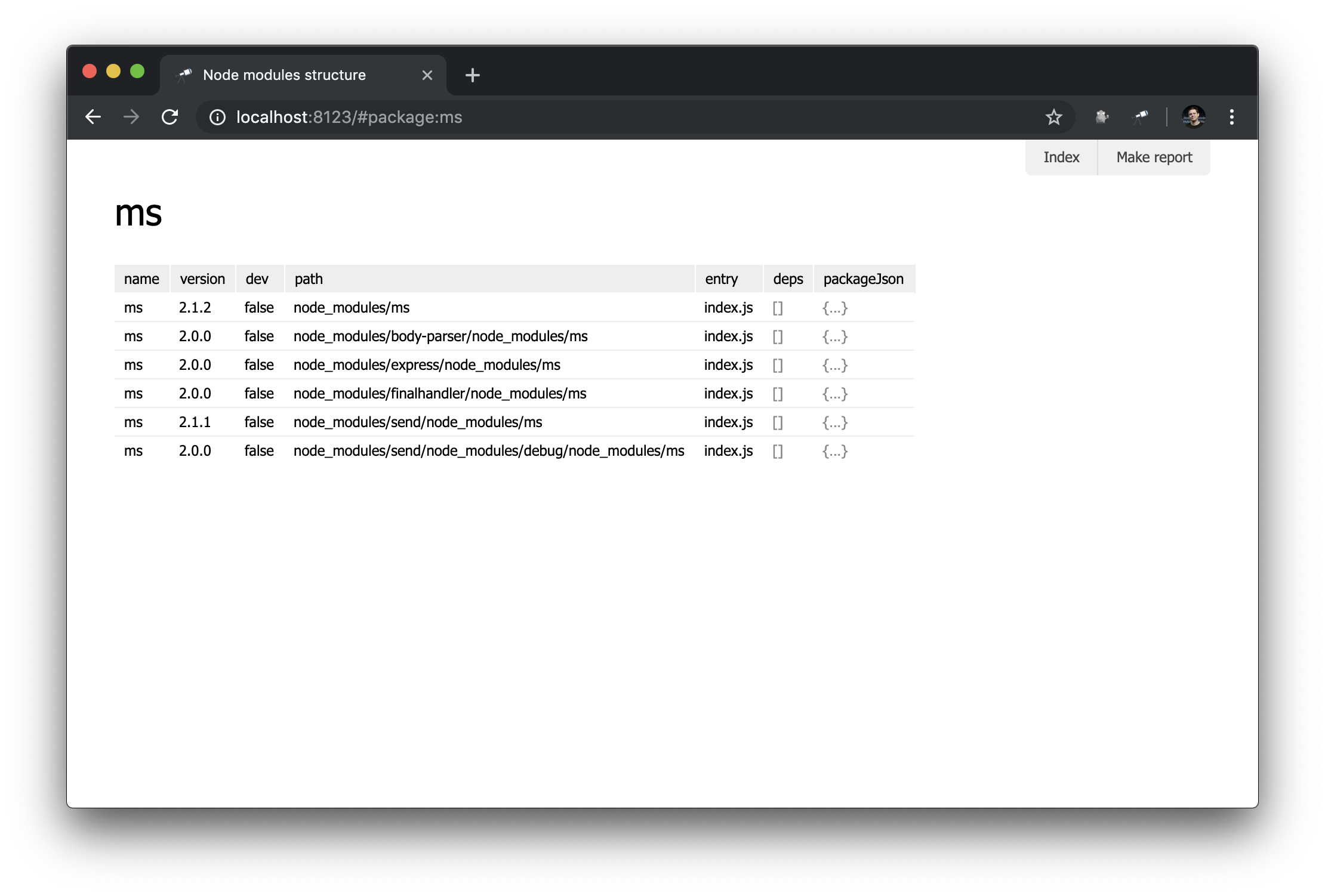
不太令人印象深刻,但现在。 我们将在后续手册中创建更复杂的映射。
侧板
由于我们已经有了一个软件包页面,因此拥有所有软件包的列表将是一件很不错的事情。 为此,您可以定义一个特殊的视图sidebar ,如果已定义,则会显示该视图(默认情况下未定义)。 创建一个新的模块views/sidebar.js :
discovery.view.define('sidebar', { view: 'list', data: 'name.sort()', item: 'link:{ text: $, href: pageLink("package") }' });
现在,我们有了所有软件包的列表:
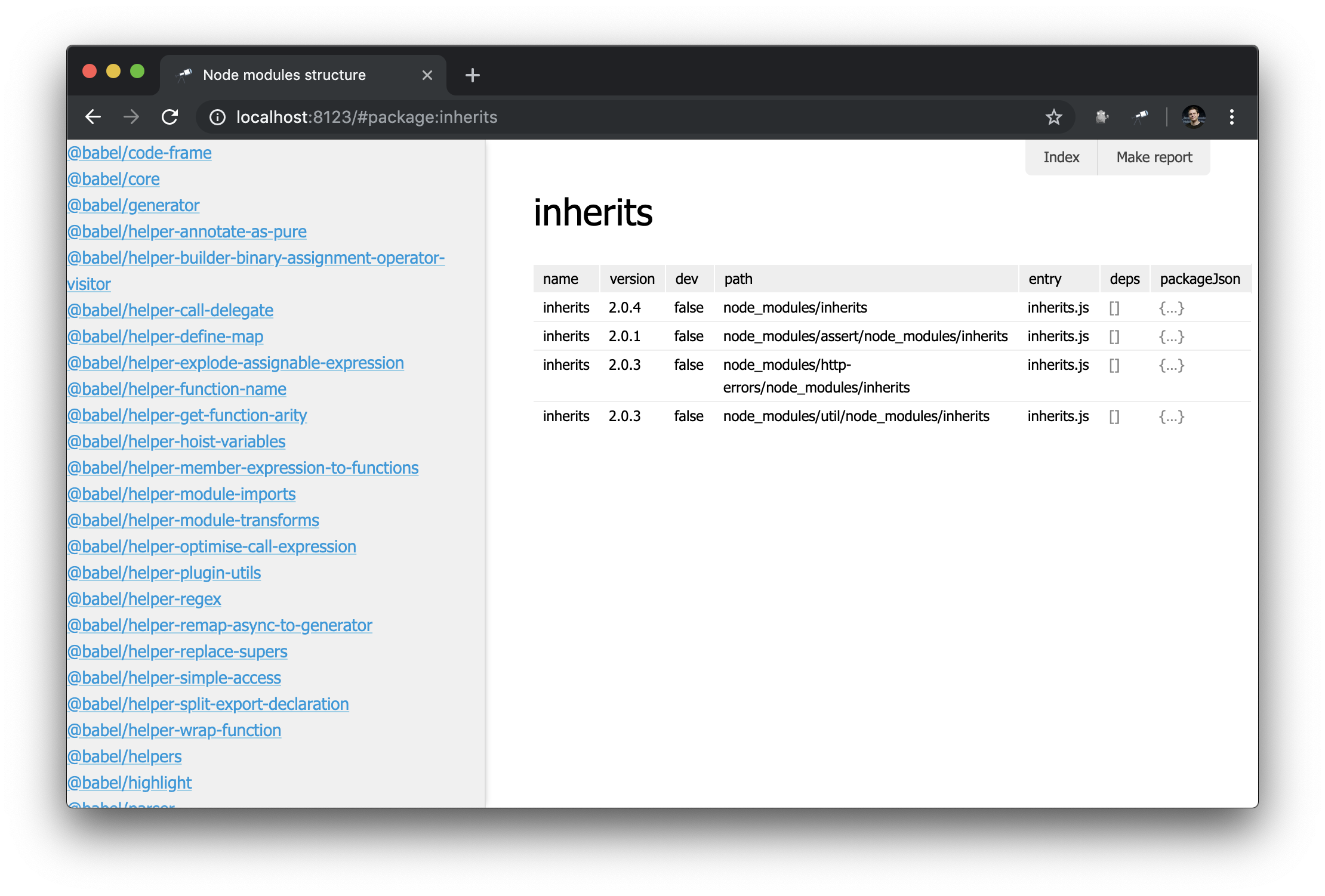
看起来不错 但是有了过滤器,效果会更好。 我们扩展sidebar的定义:
discovery.view.define('sidebar', { view: 'content-filter', content: { view: 'list', data: 'name.[no #.filter or $~=#.filter].sort()', item: { view: 'link', data: '{ text: $, href: pageLink("package"), match: #.filter }', content: 'text-match' } } });
在这里,我们将列表包装在content-filter组件中,该组件将输入字段中的输入值转换为正则表达式(如果该字段为空,则为null )并将其另存为上下文中的filter值(可以使用name选项更改name )。 同样,为了过滤列表中的数据,我们使用#.filter 。 最后,我们应用链接映射来突出显示具有text-match匹配部分。 结果:

如果您不喜欢默认设计,则可以根据需要自定义样式。 假设您要更改侧边栏的宽度,为此,您需要创建一个样式文件(例如, views/sidebar.css ):
.discovery-sidebar { width: 300px; }
并在配置中添加指向该文件以及JavaScript模块的链接:
module.exports = { ... view: { assets: [ ... 'views/sidebar.css',
自动连结
本指南的最后一章专门介绍链接。 之前,使用pageLink()方法,我们链接到了包页面。 但是,除了链接之外,还必须设置链接文本。 但是,我们如何使它变得更容易呢?
为了简化链接的工作,我们需要定义一个生成链接的规则。 最好在prepare脚本中完成此操作:
discovery.setPrepare(function(data) { ... const packageIndex = data.reduce( (map, item) => map .set(item, item)
我们添加了新的程序包映射(索引),并将其用于实体解析器。 如果可能,实体解析器尝试将传递给它的值转换为实体描述符。 描述符包含:
type -实体类型id对链接中用作ID的实体实例的唯一引用name -用作链接文字
最后,您需要将此类型分配给特定的页面(链接应指向某个地方,对吗?)。
discovery.page.define('package', { ... }, { resolveLink: 'package'
这些更改的第一个结果是,现在在struct视图中的某些值已标记为指向软件包页面的链接:
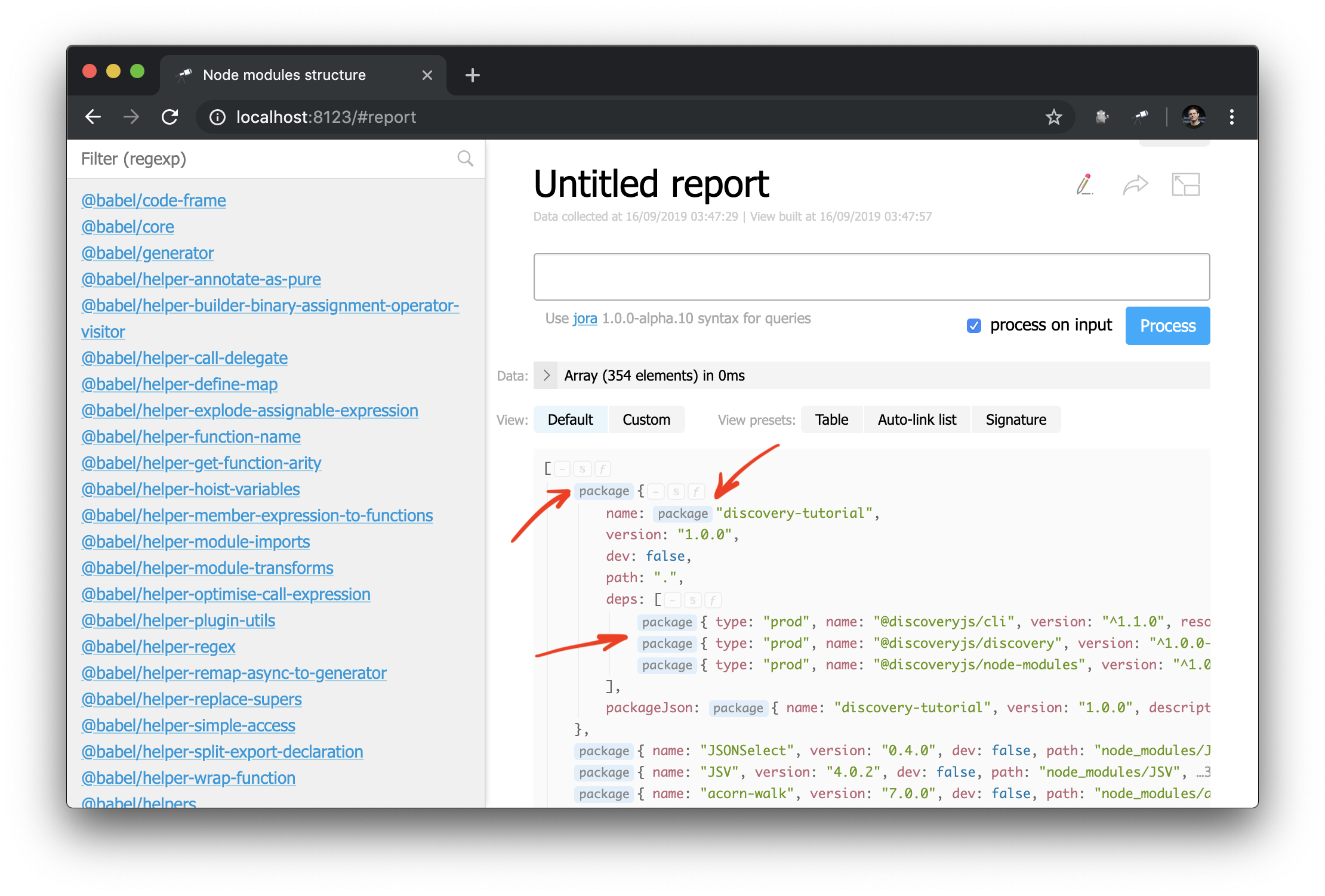
现在,您还可以将auto-link组件应用于对象或包名称:
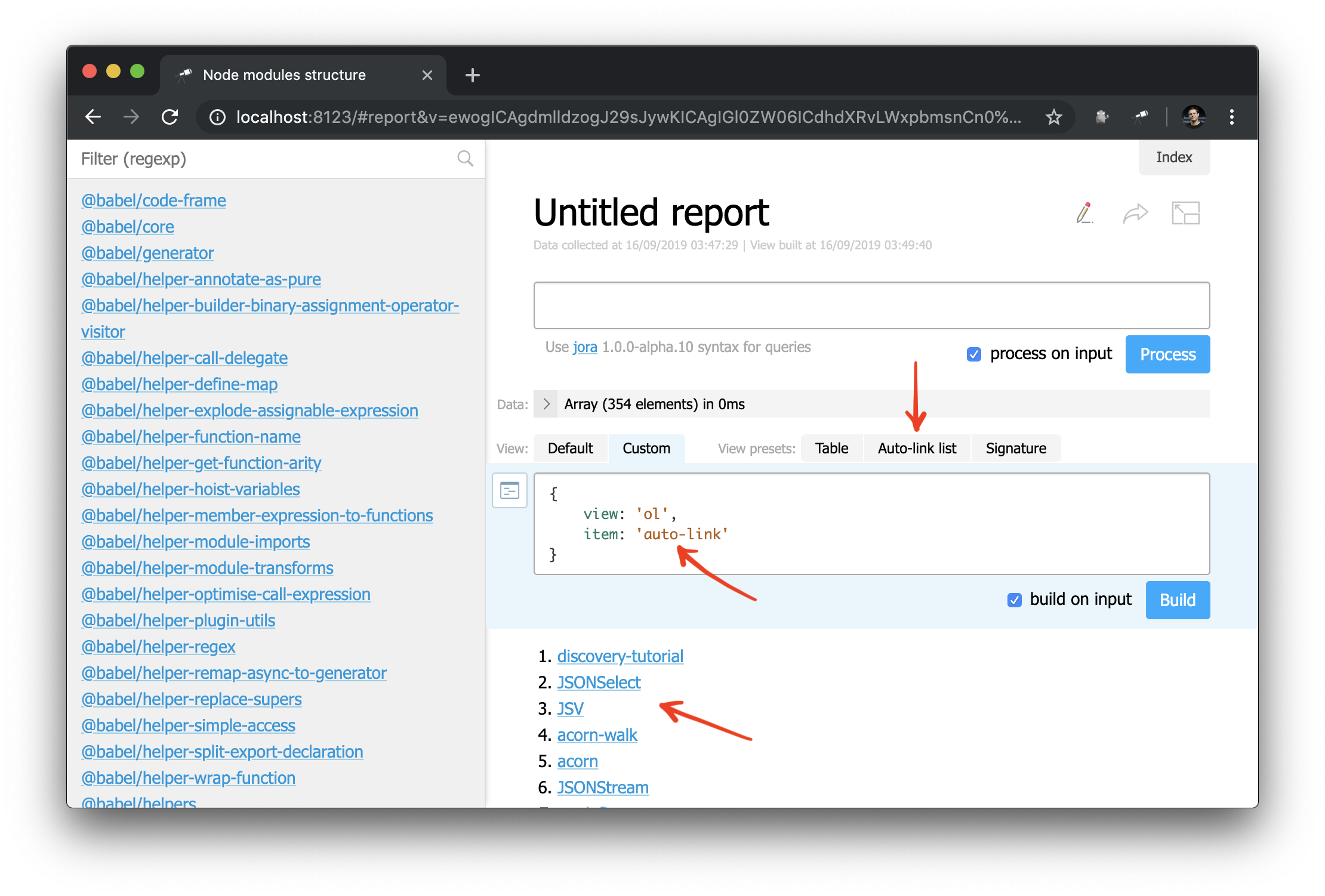
并且,例如,您可以对侧边栏稍做修改:
结论
现在,您对Discovery.js的关键概念有了基本的了解。 在以下指南中,我们将仔细研究所涵盖的主题。
您可以在GitHub上的存储库中查看该指南的完整源代码,也可以尝试在线上工作 。
在Twitter上关注@js_discovery以了解最新消息!