我们想概括性地概述有关
Cascadeur计划的角色动画深度学习的第一个成就。
在开发
Shadow Fight 3时 ,我们积累了很多战斗动画-大约1100个动作,平均持续时间约4秒。 在我们看来很久以前,这对于训练某种神经网络可能是一个很好的数据集。
一旦我们注意到动画师在纸上制作第一个想法草图时,他们只需要画一个字面意义上的粘人就可以想象角色的姿势。 我们认为,由于有经验的动画师可以以简单的模式很好地设置姿势,因此神经网络很可能可以处理它。 从这个观察结果中得出了一个简单的想法:让我们从每个姿势中仅取6个要点-手腕,脚踝,骨盆和脖子的底部。 如果神经网络只知道这些点的位置,它是否可以预测其余姿势-角色的其余37个点的位置?
从一开始就很清楚如何安排学习过程:在入口处,网络从特定姿势接收6点的位置,在输出处给出剩余37点的位置,然后将它们与初始位置进行比较。 在评估功能中,可以使用最小二乘法计算点的预测位置与源之间的距离。
对于训练数据集,我们使用了Shadow Fight 3中角色的所有动作。我们从每个帧中获取姿势,并获得了约115,000个姿势。 但这是特定的设置-角色几乎总是沿X轴看,而左腿在移动开始时始终在前面。 为了解决这个问题,我们通过生成镜像姿势以及在空间中随机旋转每个姿势来人为地扩展数据集。 这也使我们可以将数据集增加到200万个姿势。 我们将数据集的95%用于网络训练,并将5%用于参数化和测试。
我们采用了一种相当简单的神经网络架构-具有激活功能的全连接五层网络和
自归一化神经网络的初始化方法。 在最后一层,不使用激活。 每个节点有3个坐标,我们得到6 * 3个元素的输入层和37 * 3个元素的输出层。 我们搜索了隐藏层的最佳架构,并确定了一个五层架构,每个隐藏层上的神经元数量分别为300、400、300、200,但是,隐藏层较少的网络也产生了良好的效果。 网络参数的
L2正则化也非常有用,它使预测更平滑,更连续。
具有此类参数的神经网络可预测平均误差为3.5 cm的点的位置,这是一个非常高的误差,但必须考虑到问题的具体情况。 对于一组输入值,可能有许多可能的输出值。 因此,神经网络最终学会了发布最可能的平均预测。 但是,当输入点的数量增加到16时,误差减少了一半,实际上,这产生了一个非常准确的姿势预测。
但是同时,神经网络无法给出完全正确的姿势,无法保留所有骨骼的长度和正确的关节关节。 因此,我们另外启动了一个优化过程,该过程使我们的物理模型的所有实体和关节对齐。
实际上,结果令人信服-您可以在我们的视频中看到它们。 但是由于训练数据集是来自带有武器的格斗游戏的战斗动画,因此也具有特殊性。 例如,一个角色似乎假定他像在战斗中那样以一个肩膀朝敌人的方向转动,并因此转动了自己的脚和头。 当您伸出他的手时,刷子不会像用拳头击中一样转动,而是像被剑击中一样。
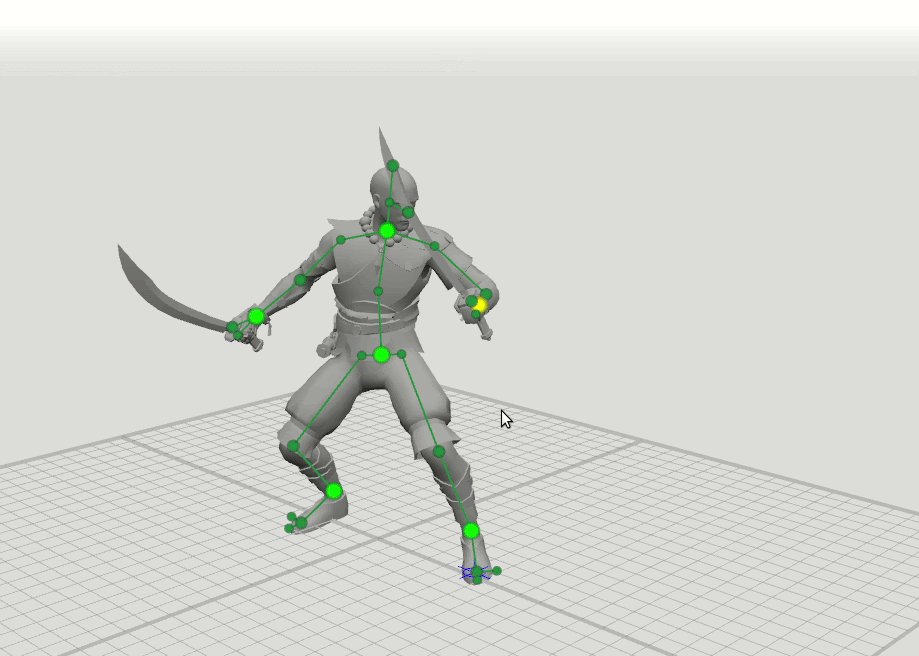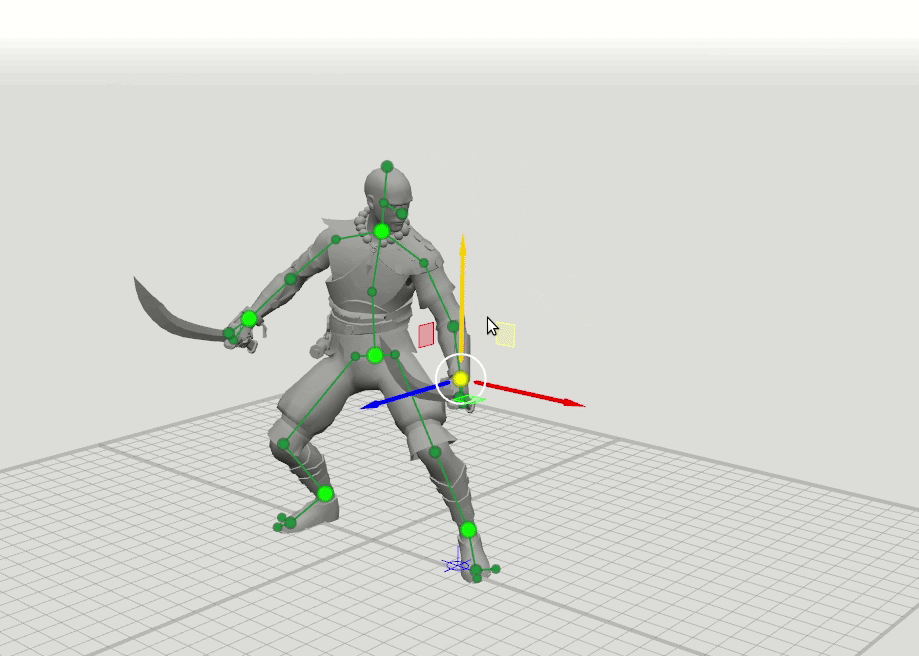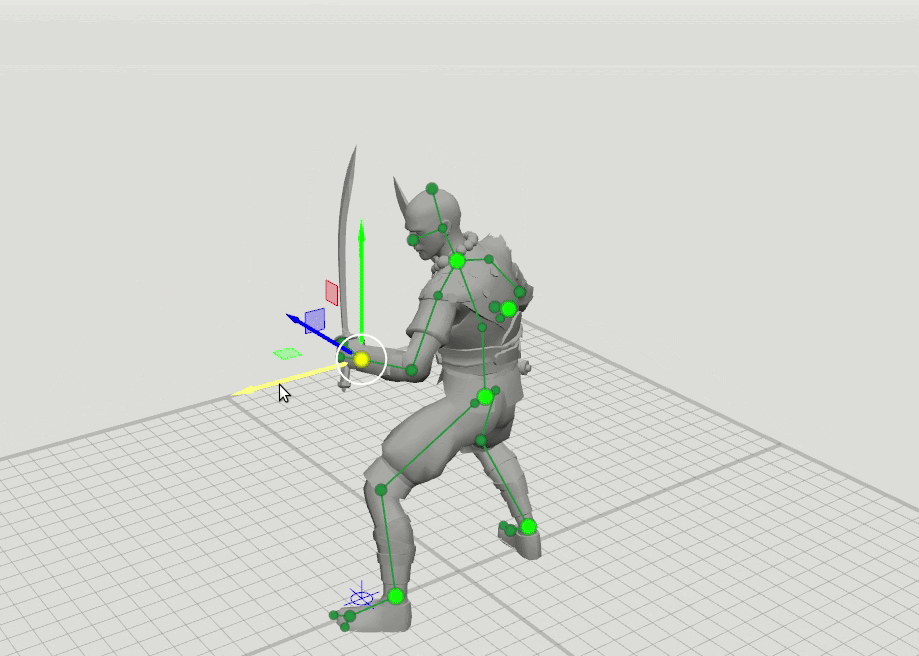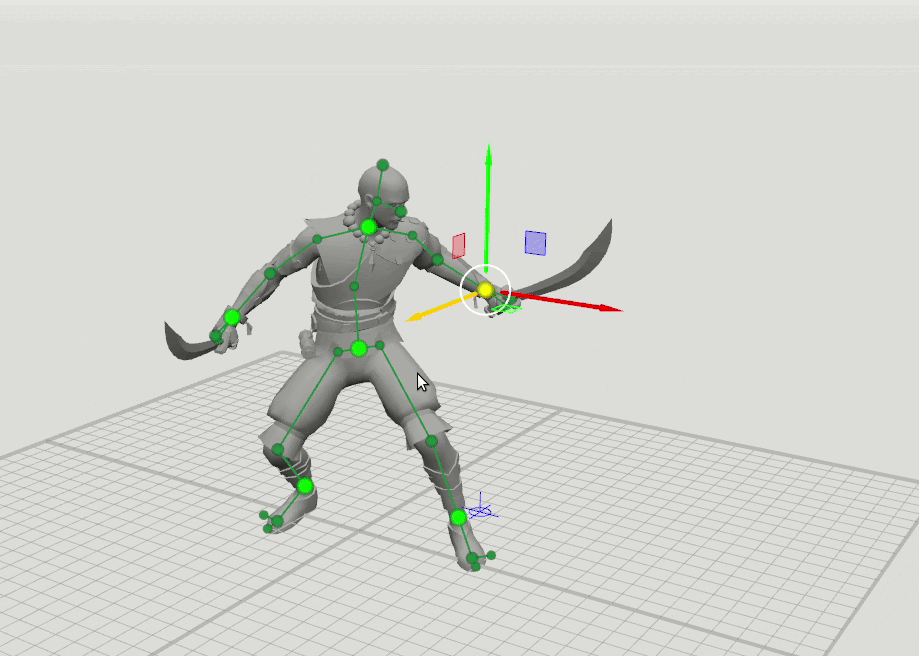
由此产生了下一步的逻辑思想-用扩展的点集训练更多的网络,这些点指定了手,脚和头的方向以及膝盖和肘部的位置。 我们添加了16点和28点方案。 事实证明,可以组合这些网络的结果,以便用户可以将位置设置为任意点集。 例如,用户决定移动左肘,但没有触摸右肘。 然后,以6点模式预测右肘和右肩的位置,并以16点模式预测左肩的位置。

看来,这对于处理角色姿势确实是一个非常有趣的工具。 它的潜力尚未被揭示到最后,我们对如何改进它并不仅将其用于姿势工作有想法。 当前版本的Cascadeur中已经提供了该工具的第一个版本。 如果您在我们的网站
cascadeur.com上注册了内测版,则可以尝试一下
我们很高兴知道您的意见并回答问题。
万岁游戏团队需要一名深度学习研究员。 在此处阅读有关空缺的更多信息。