
嗨,哈伯的读者。 通过本文,我们将开启一个循环,讨论我们开发的超融合系统AERODISK vAIR。 最初,我们希望第一篇文章介绍所有内容,但是系统非常复杂,因此我们将部分吃掉一头大象。
让我们从系统的历史着手,深入研究作为vAIR基础的ARDFS文件系统,还讨论了将该解决方案定位于俄罗斯市场的情况。
在以后的文章中,我们将更多地讨论不同的体系结构组件(集群,虚拟机管理程序,负载均衡器,监视系统等),配置过程,我们将提出许可问题,分别显示崩溃测试,以及当然会介绍负载测试和尺码。 我们还将在vAIR的社区版本上发表单独的文章。
飞碟是关于存储的故事吗? 还是为什么我们甚至开始超融合?
最初,创建自己的超融合的想法大约在2010年左右出现。 然后,市场上没有Aerodisk和类似的解决方案(商业盒装超融合系统)。 我们的任务如下:从一组通过本地互连通过以太网连接的本地磁盘的服务器中,我们必须扩展存储并在同一位置运行虚拟机和软件网络。 所有这些都需要在没有存储系统的情况下实现(因为根本没有用于存储及其绑定的资金,但我们尚未发明自己的存储系统)。
我们尝试了很多开放源代码解决方案,但是我们解决了这个问题,但是该解决方案非常复杂,并且很难重复。 此外,该决定来自“工作? 请勿触摸!” 因此,解决了这个问题后,我们没有进一步发展将工作成果转化为成熟产品的想法。
在那次事件之后,我们放弃了这个想法,但是我们仍然感到这项任务是完全可以解决的,而且这种解决方案的好处不言而喻。 随后,发布的外国公司的HCI产品仅证实了这种感觉。
因此,在2016年中,我们作为完整产品创建的一部分返回了此任务。 那时我们还没有与投资者建立任何关系,因此我们不得不用我们不大的钱来购买开发摊位。 在Avito BU-shyh服务器和交换机上打字后,我们开始工作。

最初的主要任务是创建您自己的,尽管简单但您自己的文件系统,该文件系统将能够在第n个通过以太网互连的群集节点上以虚拟块的形式自动均匀地分发数据。 在这种情况下,FS应该易于扩展且独立于相邻系统,即 以“仅存储”的形式与vAIR疏远。

VAIR First概念

我们有意拒绝使用现成的开源解决方案来组织扩展存储(ceph,gluster,lustre等),以支持我们的开发,因为我们已经在它们上面有很多项目经验。 当然,这些解决方案本身就是很棒的,在我们研究Aerodisk之前,我们与它们实施了多个集成项目。 但是,实现一个客户的特定任务,培训员工并可能为大型供应商购买支持是一回事,而创建易于复制的产品用于各种任务则是另一回事,作为供应商,我们甚至可能知道自己我们不会。 出于第二个目的,现有的开源产品不适合我们,因此我们决定亲自查看分布式文件系统。
两年后,几位开发人员(将vAIR的工作与经典存储引擎的工作相结合)取得了一定的成果。
到2018年,我们已经编写了最简单的文件系统并对其进行了必要的绑定补充。 系统通过内部互连将来自不同服务器的物理(本地)磁盘集成到一个平面池中,并将它们“切割”成虚拟块,然后从虚拟块创建具有不同容错程度的块设备,并在其上创建和执行虚拟KVM虚拟机管理程序汽车。
我们没有理会文件系统的名称,而是简单地将其称为ARDFS(猜测它如何解密)
这个原型看起来不错(当然,不是视觉上的,那时没有视觉设计),并且在性能和缩放方面显示出良好的结果。 在取得第一个实际结果之后,我们为这个项目设定了方向,组织了一个成熟的开发环境和一个仅从事vAIR的独立团队。
就在那时,该解决方案的通用体系结构已经成熟,直到现在还没有发生重大变化。
进入ARDFS文件系统
ARDFS是vAIR的基础,它提供了整个群集的分布式故障转移存储。 ARDFS的一个(但不是唯一)与众不同的功能是,它不使用任何其他专用服务器进行元数据和管理。 最初旨在简化解决方案的配置及其可靠性。
储存结构
在所有群集节点中,ARDFS从所有可用磁盘空间组织逻辑池。 重要的是要了解池不是数据,也不是格式化空间,而仅仅是标记,即 将添加了vAIR的任何节点添加到群集后,都会自动添加到共享ARDFS池中,并且磁盘资源会自动在整个群集之间共享(并且可用于将来的数据存储)。 这种方法使您可以动态添加和删除节点,而不会对已经运行的系统造成严重影响。 即 该系统非常容易使用“砖块”进行扩展,并在必要时添加或删除集群中的节点。
虚拟磁盘(虚拟机的存储对象)被添加到ARDFS池的顶部,该池由4 MB的虚拟块构建而成。 虚拟磁盘直接存储数据。 在虚拟磁盘级别,还定义了容错方案。
您可能已经猜到,对于磁盘子系统的容错能力,我们不使用RAID(独立磁盘的冗余阵列)的概念,而是使用RAIN(独立节点的冗余阵列)。 即 容错能力是根据节点而不是磁盘进行测量,自动化和管理的。 当然,磁盘也是一个存储对象,与其他所有磁盘一样,磁盘也是受监视的,您可以使用磁盘执行所有标准操作,包括构建本地硬件RAID,但是群集使用节点进行操作。
在您确实需要RAID的情况下(例如,在小型群集上支持多个故障的情况),没有什么可以阻止您使用本地RAID控制器,并在顶部进行扩展存储和RAIN体系结构。 该方案非常活跃,并得到我们的支持,因此我们将在有关使用vAIR的典型方案的文章中对此进行讨论。
存储故障转移方案
可能有两种vAIR虚拟磁盘弹性方案:
1)复制因子或仅仅是复制-这种容错方法很简单,就像“一根棍子和一根绳子”。 在节点之间以2(每个群集2个副本)或3(分别3个副本)的倍数执行同步复制。 RF-2允许虚拟磁盘承受群集中一个节点的故障,但是“吃掉”了一半的可用卷,RF-3承受了群集中2个节点的故障,但是它将保留2/3的可用卷供其使用。 此方案与RAID-1非常相似,也就是说,在RF-2中配置的虚拟磁盘可以抵抗群集中任何一个节点的故障。 在这种情况下,数据将没事,甚至I / O也不会停止。 当故障节点恢复运行时,将开始自动数据恢复/同步。
以下是正常模式和故障情况下RF-2和RF-3数据分布的示例。
我们有一个虚拟机,该虚拟机在4个vAIR节点上运行,容量为8MB的唯一(有用)数据。 显然,实际上不可能有这么少的金额,但是对于反映ARDFS逻辑的方案而言,此示例是最容易理解的。 AB是包含唯一虚拟机数据的4MB虚拟块。 使用RF-2,分别创建了这些块A1 + A2和B1 + B2的两个副本。 这些块由节点“布局”,避免了相同节点上相同数据的交集,也就是说,副本A1不会与副本A2处于同一音符上。 与B1和B2相似。
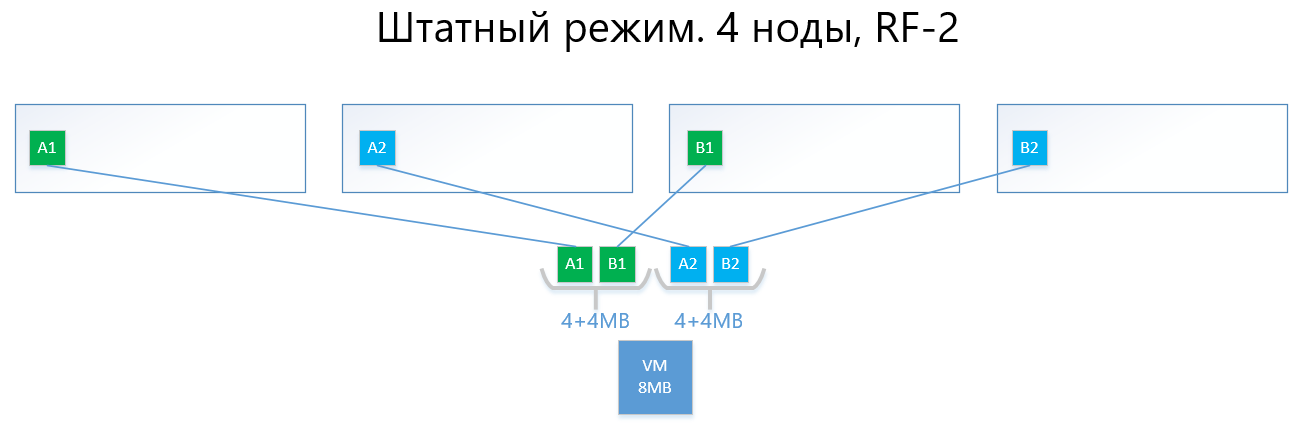
如果其中一个节点(例如,包含B1副本的节点3)发生故障,该副本将在没有其副本(即副本B2)的节点上自动激活。
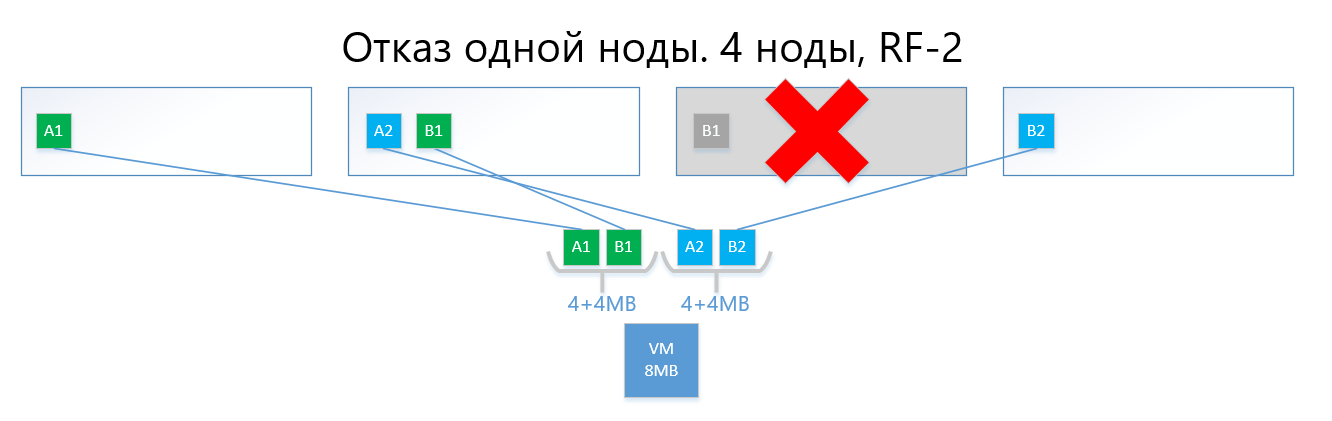
因此,在RF-2方案中,虚拟磁盘(和分别为VM)将很容易幸免于一个节点的故障。
具有复制功能的电路,由于其简单性和可靠性而遭受与RAID1相同的痛苦-几乎没有可用空间。
2)仅仅存在擦除编码或删除编码(也称为“冗余编码”,“擦除编码”或“冗余编码”)来解决上述问题。 EC是一种冗余方案,与复制相比,它具有较高的数据可用性,并具有较少的磁盘开销。 该机制的操作原理类似于RAID 5、6、6P。
在编码时,EC进程根据EC方案将虚拟块(默认为4 MB)划分为几个较小的“数据”(例如,2 +1方案将每个4 MB块划分为2个2 MB)。 此外,该过程为不多于一个先前分离的部分的“数据块”生成“奇偶校验块”。 解码时,EC会生成丢失的片段,并读取整个群集中的“剩余”数据。
例如,在集群的4个节点上实施的EC方案为2 + 1的虚拟磁盘可以像RF-2一样轻松承受集群中的单节点故障。 同时,间接成本会更低,特别是RF-2的容量系数为2,而EC 2 +1的容量系数为1.5。
如果更简单地描述,最重要的是将虚拟块划分为2-8(为什么从2到8,见下文)“件”,并为这些件计算相同体积的奇偶校验“件”。
结果,数据和奇偶校验均匀分布在群集的所有节点上。 同时,与复制一样,ARDFS会自动在节点之间分配数据,以防止在一个节点上存储相同数据(数据副本及其奇偶校验),从而消除了由于数据及其数据丢失而丢失数据的机会。奇偶校验将突然终止在同一存储节点上,这将失败。
下面是一个示例,它具有8 MB和4个节点的相同虚拟机,但是已经具有EC 2 +1方案。
块A和B分为两块,每块2 MB(由于2 +1,所以分为两个),即A1 + A2和B1 + B2。 与副本不同,A1不是A2的副本,它是一个虚拟块A,分为两个部分,也包括块B。总共,我们得到了两组4MB,每组包含2个2 MB的块。 此外,对于这些集合中的每一个,均以不超过一个(即2 MB)的容量计算奇偶校验,我们将获得额外的+ 2个奇偶校验块(AP和BP)。 总共我们有4x2数据+ 2x2奇偶校验。
接下来,片段被节点“布局”,以使数据不会与其奇偶校验重叠。 即 A1和A2将与AP不在同一个节点上。

如果一个节点发生故障(例如第三个节点),则掉落的块B1将自动从奇偶校验BP恢复,该奇偶校验BP存储在2号节点上,并将在没有B奇偶校验的节点上激活, 血压。 在此示例中,这是节点#1

我确定读者有一个问题:
“您描述的所有内容早已被竞争对手和开放源代码解决方案实施,您在ARDFS中实施EC有何区别?”
然后,ARDFS的工作将具有有趣的功能。
擦除编码,强调灵活性
最初,我们提供了一种相当灵活的EC X + Y方案,其中X等于2到8的数字,Y等于1到8的数字,但始终小于或等于X。提供这种方案是为了提高灵活性。 增加虚拟单元被划分为的数据(X)的数量允许减少开销,即,增加可用空间。
奇偶校验块(Y)数量的增加会增加虚拟磁盘的可靠性。 Y值越大,集群中可能发生故障的节点越多。 当然,奇偶校验的增加会减少可用容量的数量,但这是可靠性的代价。
性能对EC电路的依赖性几乎是直接的:“件数”越多,性能越低,这里当然需要平衡的外观。
这种方法使管理员可以最灵活地配置扩展存储。 在ARDFS池中,您可以使用任何容错方案及其组合,我们认为这也非常有用。
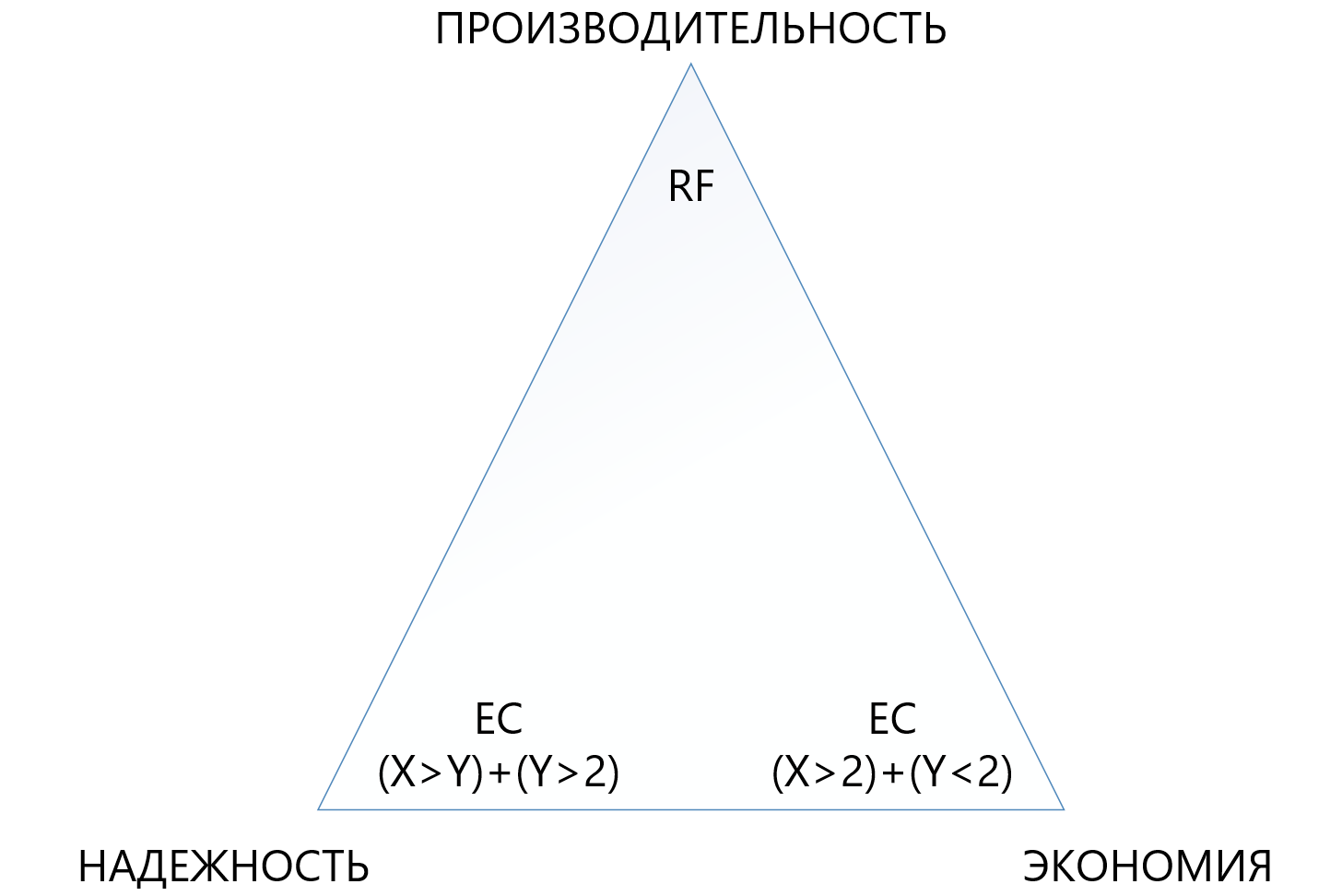
下表比较了几种(并非所有可能的)RF和EC电路。

该表显示,即使是EC 8 + 7的“ terry”组合,在一个集群中最多可以同时丢失7个节点,与标准复制相比,“占用”了更少的可用空间(1.875对2),并且保护了7倍,这使这种保护机制虽然更复杂,但是在需要磁盘空间不足的情况下需要确保最大可靠性的情况下更具吸引力。 同时,您需要了解X或Y的每个“加号”都是生产率的额外开销,因此您需要在可靠性,经济性和性能之间的三角中非常谨慎地选择。 因此,我们将在另一篇文章中专门介绍删除编码的大小。
文件系统的可靠性和自治性
ARDFS在群集的所有节点上本地运行,并通过专用以太网接口以自己的方式对其进行同步。 重要的一点是,ARDFS不仅可以独立同步数据,还可以同步与存储相关的元数据。 在研究ARDFS时,我们同时研究了许多现有解决方案,发现许多解决方案使用外部分布式DBMS进行文件系统元同步,我们也将其用于同步,但仅用于配置,而不用于FS元数据(关于此和其他相关子系统)在下一篇文章中)。
使用外部DBMS同步FS元数据固然是一种可行的解决方案,但是存储在ARDFS上的数据的一致性将取决于外部DBMS及其行为(坦率地说,她是一位反复无常的女士),这在我们看来是不好的。 怎么了 如果FS元数据被损坏,FS数据本身也可以说是“再见”,因此我们决定走一条更复杂但可靠的道路。
我们为ARDFS独立创建了元数据同步子系统,它完全独立于相邻子系统而存在。 即 没有其他子系统可以破坏ARDFS数据。 我们认为,这是最可靠,最正确的方法,真的如此-时间会证明一切。 另外,使用这种方法,还显示了另一个优势。 ARDFS可以独立于vAIR使用,就像扩展存储一样,我们肯定会在将来的产品中使用它。
结果,开发了ARDFS后,我们得到了一个灵活而可靠的文件系统,可以为您提供一个选择,您可以在其中节省容量或放弃所有性能,或者以适度的费用使存储高度可靠,但降低了性能要求。
加上简单的许可政策和灵活的交付模型(展望未来,它由vAIR按节点许可,可以通过软件或作为PAC交付),这使您可以非常精确地为客户量身定制解决方案,以满足客户的不同需求,并且将来可以轻松保持这种平衡。
谁需要这个奇迹?
一方面,我们可以说市场上已经有一些参与者在超融合领域以及我们的发展方向上做出了认真的决定。 这句话似乎是真的,但是...
另一方面,进入领域并与客户沟通时,我们和合作伙伴发现情况并非如此。 超融合存在许多问题,在某些地方人们根本不知道有这样的解决方案,在看起来昂贵的地方,在对替代解决方案的测试不成功的地方,但是由于制裁,他们通常禁止购买。 通常,没有耕地,所以我们去了处女地)))。
什么时候存储比GCS更好?
在与市场合作的过程中,经常有人问我们何时将经典方案与存储系统一起使用会更好,何时会超融合? 许多公司-GCS的制造商(尤其是其产品组合中没有存储的制造商)说:“存储已失效,只有超融合!” 这是一个大胆的声明,但并不能完全反映现实。
实际上,存储市场确实向着超融合和类似的解决方案进发,但总有一个“ but”。
首先,按照这种经典的带有存储系统的方案构建的数据中心和IT基础架构无法像这样轻松地进行重建,因此此类基础架构的现代化和完善仍然需要5-7年的时间。
其次,目前大部分正在建设的基础架构(即俄罗斯联邦)是根据经典方案使用存储系统进行构建的,并不是因为人们不了解超融合,而是因为超融合市场是新市场,因此尚未建立解决方案和标准,IT员工尚未接受培训,经验很少,因此我们需要在此时此地建立数据中心。 而且这种趋势还会持续3-5年(然后是另一个遗产,请参见第1段)。
第三,纯粹的技术限制是每次写入还有2毫秒的额外小延迟(当然不包括本地缓存),这是分布式存储的费用。
好吧,我们不要忘记使用喜欢磁盘子系统垂直扩展的大型物理服务器。
在许多必要且流行的任务中,存储系统的性能要优于GCS。 当然,在这里,那些产品组合中没有存储系统的制造商将与我们不同意,但是我们准备进行合理的辩论。 当然,作为将来出版物中这两种产品的开发者,我们肯定会比较存储系统和GCS,在此我们将清楚地证明在什么条件下哪种更好。
超融合解决方案在哪里比存储系统更好?
基于以上论述,得出三个明显的结论:
- 如果在任何产品上稳定发生另外2毫秒的记录延迟(现在我们不在谈论合成,您可以在合成上显示纳秒)都是非关键的,那么超融合将起作用。
- 在大型物理服务器的负载可以转变成许多小型虚拟服务器并由节点分配的情况下,超融合也将在那里很好地工作。
- 在水平缩放比垂直缩放更重要的地方,GCS在那里也可以正常工作。
这些解决方案是什么?
- 所有标准基础结构服务(目录服务,邮件,EDS,文件服务器,中小型ERP和BI系统等)。 我们称其为“通用计算”。
- 云提供商的基础架构,需要快速和标准化的水平扩展,并为客户端轻松“切片”大量虚拟机。
- 虚拟桌面(VDI)的基础架构,其中启动了许多小用户的virtuala,并在统一群集中悄悄地“浮动”。
- , , , 15-20 .
- (big data-, ). , «», «».
- , , , .
AERODISK vAIR ( ). , , .. .
…
, .
, .