不喜欢Java? 是的,您不知道如何烹饪! Mani Sarkar邀请我们熟悉Valohai工具,该工具可让您使用Java进行模型研究。
译者的免责声明我希望这不是广告刊物。 我不隶属于Valohai。 我刚刚翻译了我引用该链接的文章。 如果翻译得很笨拙,请加入PM。 如有必要,我可以删除链接并提及其他外部资源。 感谢您的理解。
引言
前一段时间,我遇到了一个名为Valohai的云服务,它的用户界面以及设计和布局的简单性令我感到满意。 我要求一名Valohai成员提供服务,并收到了演示版。 在此之前,我使用GNU Parallel,JavaScript,Python和Bash编写了一个简单的管道-另一个仅使用GNU Parallel和Bash的管道。
我还考虑过使用现成的任务/工作流管理工具,例如Jenkins X,Jenkins Pipeline,Concourse或Airflow,但出于各种原因,我决定不使用它。
我注意到许多Valohai的示例和文档都基于Python和R及其各自的框架和库。 我决定不要错过这个机会,并且想纠正缺少示例和文档的问题。
Valohai促使我使用著名的Java库
DL4J-Java深度学习来实现某些东西。
在对Valohai的设计,布局和工作流程感到满意之后,我对Valohai的第一次体验给我留下了很好的印象。 创建者已经考虑了开发人员的工作流程和基础架构的各个方面。 在我们的世界中,基础架构开发过程主要由DevOps或SysOps团队控制,我们知道与之相关的细微差别和痛点。
我们需要什么以及如何?
在任何机器学习项目中,都有两个重要的组件(从高层的角度来看)-一个将与模型一起工作的代码,以及将与整个基础结构生命周期一起执行的基础结构一起工作的代码。
当然,之前,之中和之后都将需要一些步骤和组件,但为简单起见,我们需要代码和基础结构。
代号
对于代码,我选择了一个使用DL4J的复杂示例,这是一个
MNist项目 ,训练集为60,000张图像,测试集为10,000张手写数字图像。 该数据集可通过DL4J库获得(就像Keras一样)。
在开始之前,建议您先看看我们将使用的源代码。 Java主类称为
org.deeplearning4j.feedforward.mnist.MLPMnistSingleLayerRunner 。
基础设施
我们决定尝试使用Valohai作为我们进行实验(训练和模型评估)的基础结构的Java示例。 Valohai可以识别git存储库并直接连接到它们,从而使我们无论平台或语言如何都能执行代码-因此,我们将了解其工作原理。 这也意味着,如果您使用GitOps或“基础结构即代码”,那么一切也将为您工作。
为此,我们只需要在Valohai开设一个帐户即可。 创建免费帐户后,我们可以访问各种配置的多个实例。 对于我们想做的事情,Free-Tier绰绰有余。
Java和Valohai的深度学习
我们将提供对Docker映像的所有依赖关系,并使用它来编译我们的Java应用程序,训练模型并使用位于项目存储库根文件夹中的简单
valohai.yaml文件在Valohai平台上对其进行评估。
Java深度学习:DL4J
最简单的部分。 我们不需要做很多事情,只需收集jar并将数据集加载到Docker容器中即可。 我们有一个预先创建的Docker映像,其中包含创建Java应用程序所需的所有依赖项。 我们将此图像放在Docker Hub中,您可以通过搜索dl4j-mnist-single-layer(我们将使用YAML文件中定义的特殊标记)来找到它。 我们决定将GraalVM 19.1.1用作该项目的构建和运行时Java环境,并且将其内置到Docker映像中。
从命令行调用uber jar时,我们将创建类MLPMnistSingleLayerRunner,该类根据传递给以下参数的参数告诉我们预期的操作:
public static void main(String[] args) throws Exception { MLPMnistSingleLayerRunner mlpMnistRunner = new MLPMnistSingleLayerRunner(); JCommander.newBuilder() .addObject(mlpMnistRunner) .build() .parse(args); mlpMnistRunner.execute(); }
传递给uber jar的参数将被此类接受,并由execute()方法处理。
我们可以使用--action训练参数来创建模型,并使用传递给Java应用程序的--action评估参数来评估创建的模型。
可以在以下各节中提到的两个Java类中找到完成此工作的Java应用程序的主要部分。
模型训练
致电
./runMLPMnist.sh --action train --output-dir ${VH_OUTPUTS_DIR} or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action train --output-dir ${VH_OUTPUTS_DIR}
此命令在执行开始时传递的--output-dir参数指定的文件夹中创建一个名为mlpmnist-single-layer.pb的模型。 从Valohai的角度来看,它应该放在$ {VH_OUTPUTS_DIR}中,我们可以这样做(请参阅文件
valohai.yaml )。
有关源代码,请参见
MLPMNistSingleLayerTrain.java类。
模型评估
致电
./runMLPMnist.sh --action evaluate --input-dir ${VH_INPUTS_DIR}/model or java -Djava.library.path="" \ -jar target/MLPMnist-1.0.0-bin.jar \ --action evaluate --input-dir ${VH_INPUTS_DIR}/model
假定在调用应用程序时通过的--input-dir参数指定的文件夹中将存在一个名称为mlpmnist-single-layer.pb的模型(在训练阶段创建)。
有关源代码,请参见类
MLPMNistSingleLayerEvaluate.java 。
我希望这段简短的插图可以阐明教导和评估模型的Java应用程序是如何工作的。
这就是我们所需要的,但不要犹豫,与其他
资源一起使用(以及
README.md和bash脚本),并满足您的好奇心和对如何实现的了解!
瓦洛海
Valohai允许我们自由链接我们的运行时,代码和数据集,如下面的YAML文件结构所示。 因此,各种组件可以彼此独立地开发。 因此,只有程序集和运行时组件才打包在我们的Docker容器中。
在运行时,我们将Uber JAR收集在Docker容器中,将其加载到内部或外部存储中,然后使用其他执行步骤从存储(或其他位置)中加载Uber JAR和数据集以开始训练。 这样,两个执行步骤就被断开了。 例如,我们可以一次编译一个jar,并在一个jar上完成数百个训练步骤。 由于程序集和运行时环境不必经常更改,因此我们可以对其进行缓存,并且可以在运行时动态访问代码,数据集和模型。
valohai.yaml将Java项目与Valohai基础结构集成的主要部分是确定位于项目文件夹根目录中的valohai.yaml文件中执行步骤的顺序。 我们的valohai.yaml看起来像这样:
--- - step: name: Build-dl4j-mnist-single-layer-java-app image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - ./buildUberJar.sh - echo "~~~ Copying the build jar file into ${VH_OUTPUTS_DIR}" - cp target/MLPMnist-1.0.0-bin.jar ${VH_OUTPUTS_DIR}/MLPMnist-1.0.0.jar - ls -lash ${VH_OUTPUTS_DIR} environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-train-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - echo "~~~ Unpack the MNist dataset into ${HOME} folder" - tar xvzf ${VH_INPUTS_DIR}/dataset/mlp-mnist-dataset.tgz -C ${HOME} - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to train model based on the the MNist dataset" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: dataset default: https://github.com/neomatrix369/awesome-ai-ml-dl/releases/download/mnist-dataset-v0.1/mlp-mnist-dataset.tgz description: MNist dataset needed to train the model parameters: - name: --action pass-as: '--action {v}' type: string default: train description: Action to perform ie train or evaluate - name: --output-dir pass-as: '--output-dir {v}' type: string default: /valohai/outputs/ description: Output directory where the model will be created, best to pick the Valohai output directory environment: aws-eu-west-1-g2-2xlarge - step: name: Run-dl4j-mnist-single-layer-evaluate-model image: neomatrix369/dl4j-mnist-single-layer:v0.5 command: - cd ${VH_REPOSITORY_DIR} - echo "~~~ Copying the build jar file from ${VH_INPUTS_DIR} to current location" - cp ${VH_INPUTS_DIR}/dl4j-java-app/MLPMnist-1.0.0.jar . - echo "~~~ Run the DL4J app to evaluate the trained MNist model" - ./runMLPMnist.sh {parameters} inputs: - name: dl4j-java-app description: DL4J Java app file (jar) generated in the previous step 'Build-dl4j-mnist-single-layer-java-app' - name: model description: Model file generated in the previous step 'Run-dl4j-mnist-single-layer-train-model' parameters: - name: --action pass-as: '--action {v}' type: string default: evaluate description: Action to perform ie train or evaluate - name: --input-dir pass-as: '--input-dir {v}' type: string default: /valohai/inputs/model description: Input directory where the model created by the previous step can be found created environment: aws-eu-west-1-g2-2xlarge
Build-dl4j-mnist-single-layer-java-app如何工作
从YAML文件中,我们看到我们定义了这一步骤,首先使用Docker映像,然后运行脚本来构建Uber JAR。 我们的Docker映像具有自定义的构建环境依赖项(例如GraalVM JDK,Maven等)以创建Java应用程序。 我们没有提供任何输入或参数,因为这是组装阶段。 构建成功后,我们将名为MLPMnist-1.0.0-bin.jar(原始名称)的超级jar复制到/ valohai / outputs文件夹(表示为$ {VH_OUTPUTS_DIR})。 此文件夹中的所有内容都会自动保存在项目的存储中,例如,在AWS S3回收站中。 最后,我们定义了AWS的工作。
注意事项免费的Valohai帐户无法从Docker容器进行网络访问(默认情况下处于禁用状态),请与支持人员联系以启用此选项(我必须这样做),否则我们将无法下载Maven和其他依赖项在组装过程中。
Run-dl4j-mnist-单层火车模型如何工作
该定义的语义与上一步相似,不同之处在于我们指定了两个输入:一个输入用于超级jar(MLPMnist-1.0.0.jar),另一个输入用于数据集(解压到文件夹$ {HOME} /。Deeplearning4j中)。 我们将传递两个参数---action train和--output-dir / valohai / outputs。 在此步骤中创建的模型内置于/ valohai /输出/模型(表示为$ {VH_OUTPUTS_DIR} /模型)。
注意事项在Valohai Web界面的``运行''选项卡上的输入字段中,除了使用基准://或http:/ URL,我们还可以使用运行编号(即#1或#2)选择以前运行的输出。 /,输入文件名的几个字母也有助于搜索整个列表。
Run-dl4j-mnist-单层-valu-model如何工作
同样,此步骤与上一步相似,除了我们将传递两个参数--action评估和--input-dir / valohai / inputs / model。 此外,我们在输入中再次指出:在YAML文件中定义的部分,名称分别为dl4j-java-app和model,这两个部分均没有默认设置。 这将使我们能够选择uber jar和我们要评估的模型-它是通过使用Web界面的Run-dl4j-mnist-single-layer-train-model步骤创建的。
希望以上解释了定义文件中的步骤,但是如果您需要进一步的帮助,请随时查看
文档和
教程 。
Valohai Web界面
收到帐户后,我们可以登录并继续创建名称为mlpmnist-single-layer的项目,并将git repo
github.com/valohai/mlpmnist-dl4j-example与该项目相关联,然后保存该项目。
现在,您可以完成该步骤,看看结果如何!
生成DL4J Java应用程序
转到Web界面中的“执行”选项卡,然后复制现有执行或使用[创建执行]按钮创建一个新的执行。 所有必需的默认参数将被填充。 选择Step Build-dl4j-mnist-single-layer-java-app。
对于
环境,我选择了AWS eu-west-1 g2.2xlarge,然后单击页面底部的[创建执行]按钮以查看执行开始。
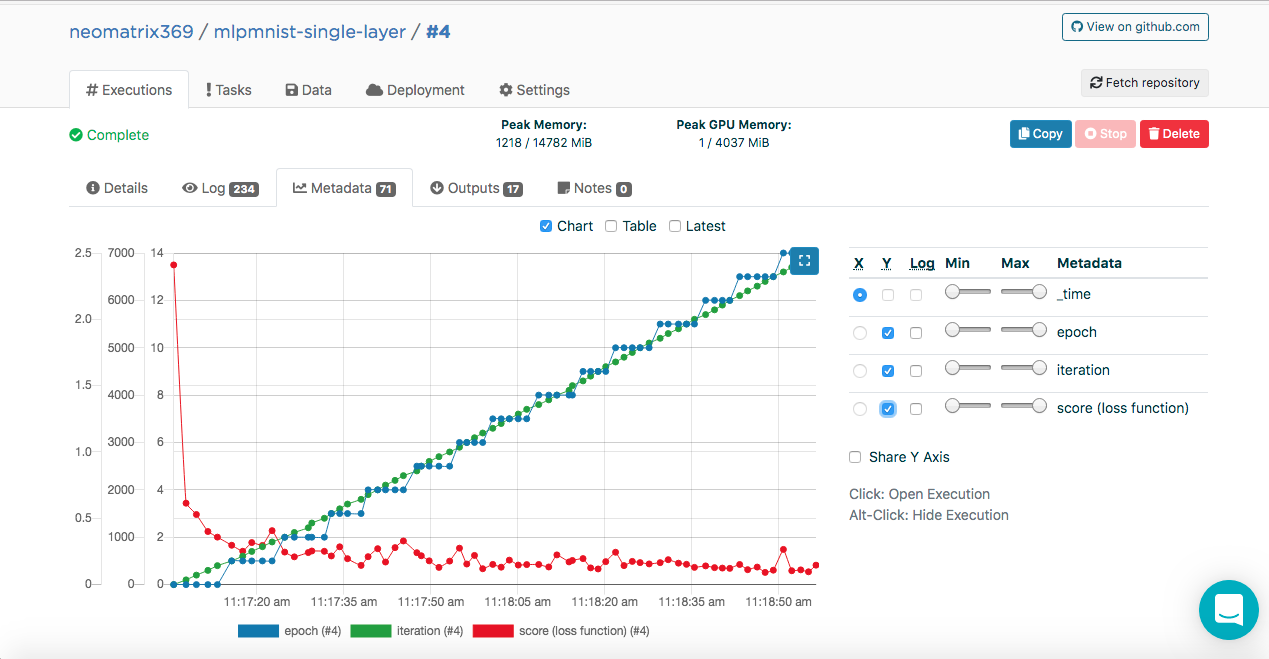
模型训练
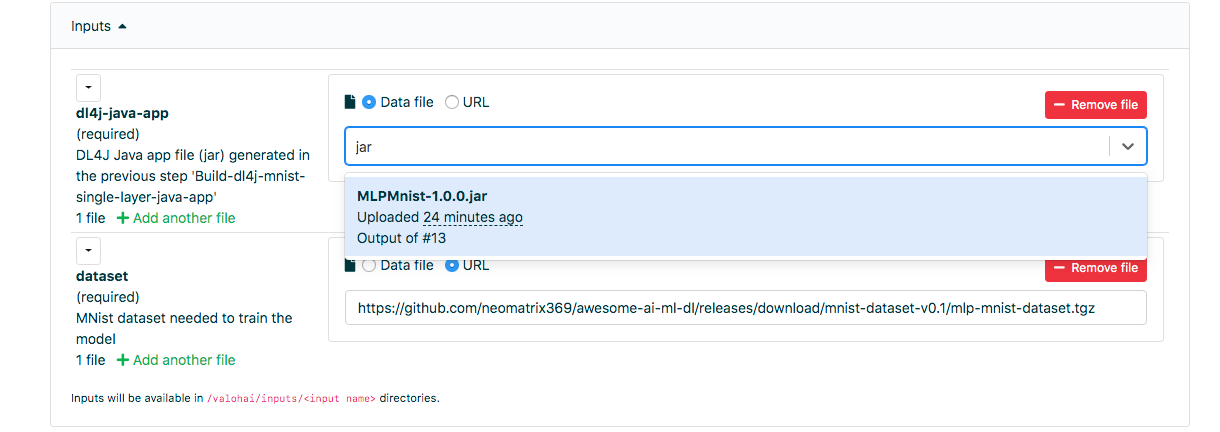
转到Web界面中的“执行”选项卡,并执行与上一步相同的操作,然后选择Run-dl4j-mnist-single-layer-train-model。 您将需要选择在上一步中创建的Java应用程序(只需在字段中输入jar)。 数据集已经使用valohai.yaml文件进行了预填充:
单击[创建执行]开始。
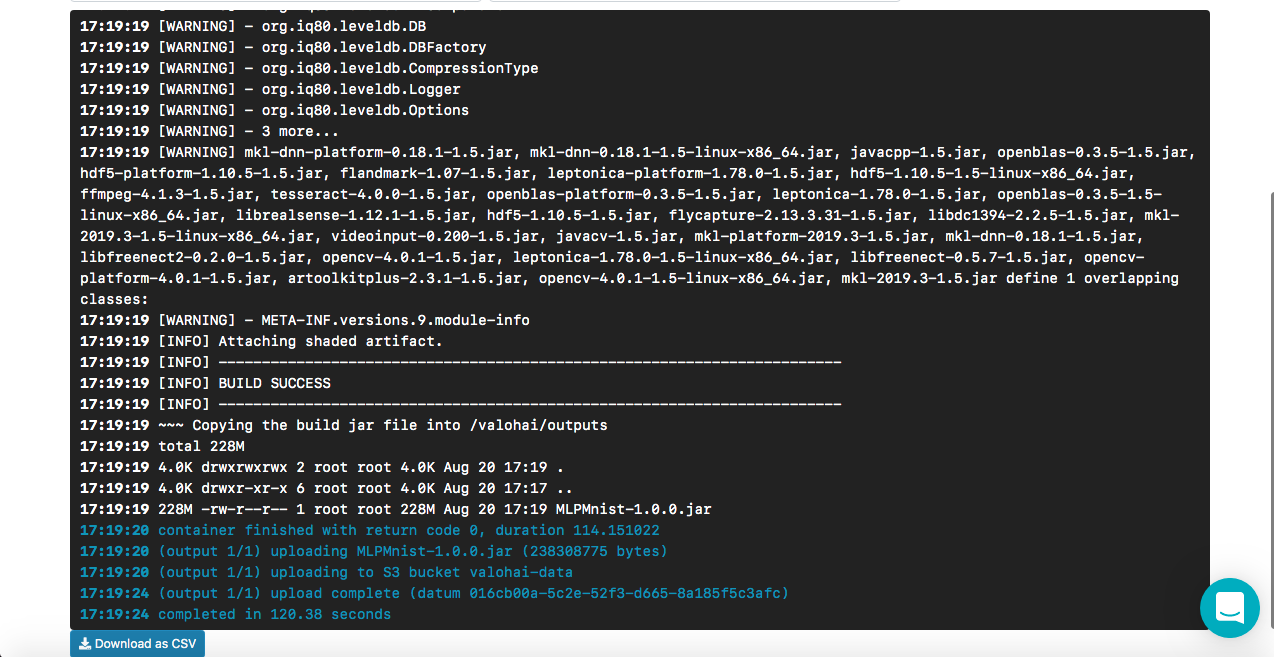
您将在控制台中看到结果:
[<--- snipped --->] 11:17:05 ======================================================================= 11:17:05 LayerName (LayerType) nIn,nOut TotalParams ParamsShape 11:17:05 ======================================================================= 11:17:05 layer0 (DenseLayer) 784,1000 785000 W:{784,1000}, b:{1,1000} 11:17:05 layer1 (OutputLayer) 1000,10 10010 W:{1000,10}, b:{1,10} 11:17:05 ----------------------------------------------------------------------- 11:17:05 Total Parameters: 795010 11:17:05 Trainable Parameters: 795010 11:17:05 Frozen Parameters: 0 11:17:05 ======================================================================= [<--- snipped --->]
在执行期间和执行之后,可以在“执行”主选项卡的“输出”选项卡上找到创建的模型:
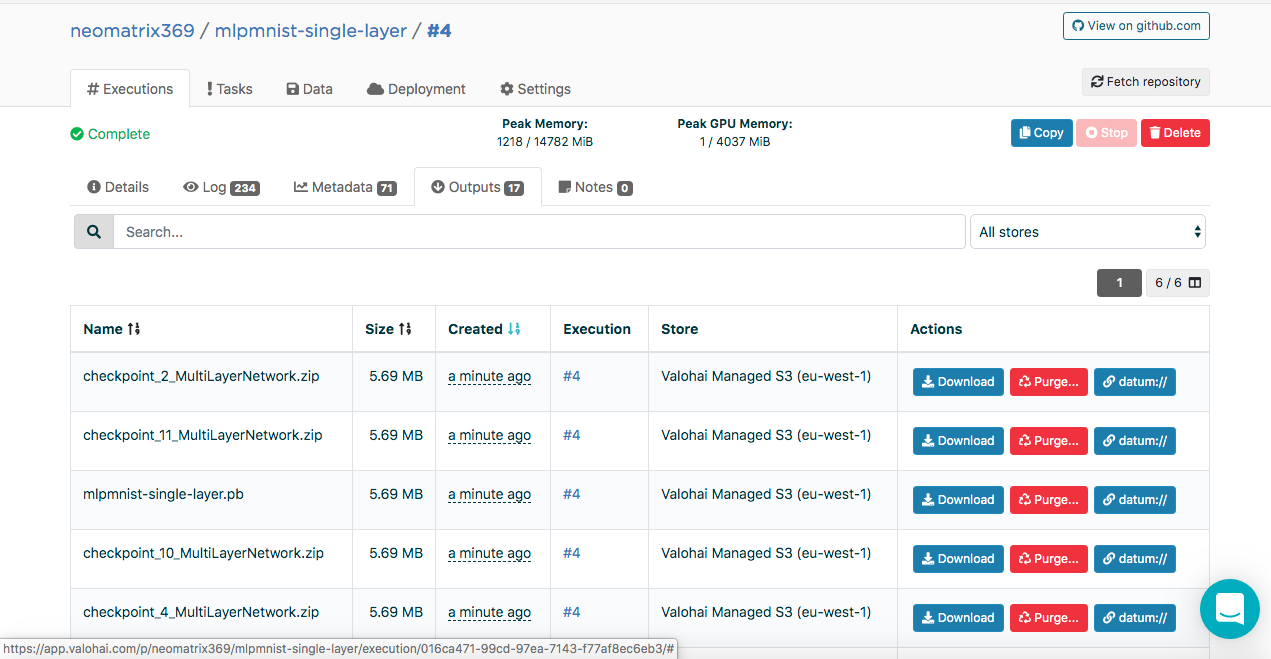
您可能会在Outputs子选项卡中注意到一些工件。 这是因为我们在每个时代的末期都维护着控制点。 让我们在日志中看一下:
[<--- snipped --->] 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
检查点在三个文件中包含模型的状态:
configuration.json coefficients.bin updaterState.bin
模型训练。 元数据
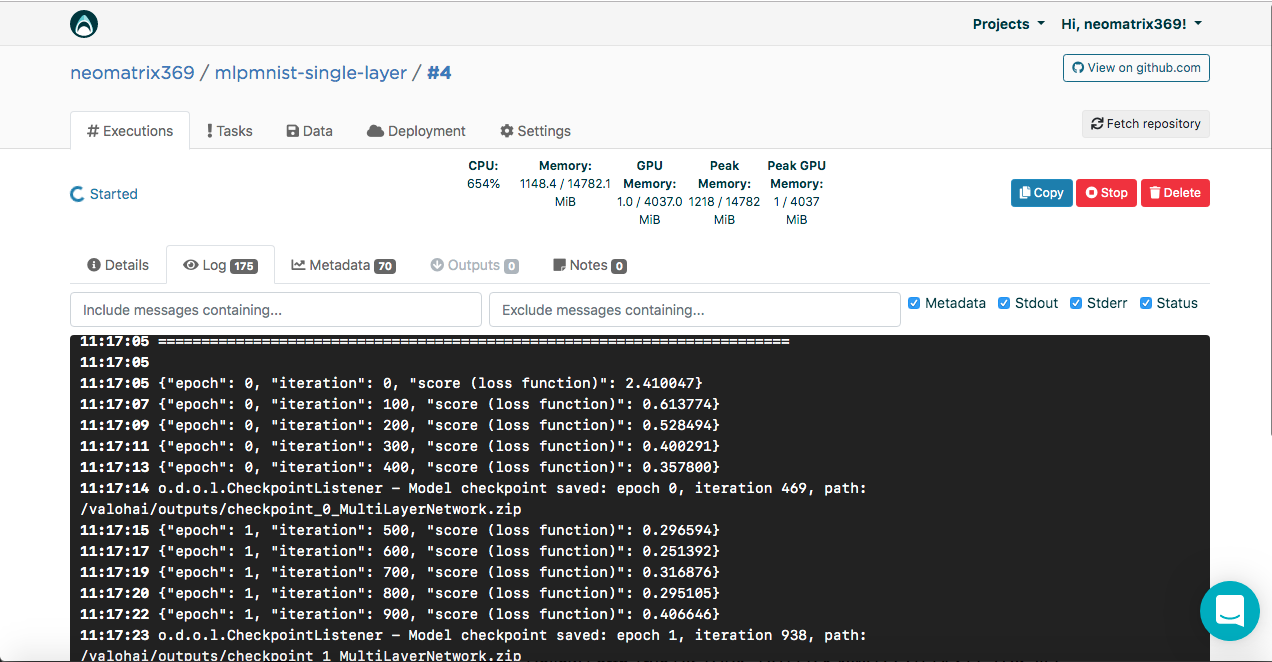
您可能已经在执行日志中注意到以下条目:
[<--- snipped --->] 11:17:05 {"epoch": 0, "iteration": 0, "score (loss function)": 2.410047} 11:17:07 {"epoch": 0, "iteration": 100, "score (loss function)": 0.613774} 11:17:09 {"epoch": 0, "iteration": 200, "score (loss function)": 0.528494} 11:17:11 {"epoch": 0, "iteration": 300, "score (loss function)": 0.400291} 11:17:13 {"epoch": 0, "iteration": 400, "score (loss function)": 0.357800} 11:17:14 odolCheckpointListener - Model checkpoint saved: epoch 0, iteration 469, path: /valohai/outputs/checkpoint_0_MultiLayerNetwork.zip [<--- snipped --->]
此数据使Valohai可以获取以下值(JSON格式),这些值将用于构建度量,这些度量可以在执行期间和执行后在“执行”主选项卡上的其他“元数据”选项卡上看到:
通过将ValohaiMetadataCreator类与模型连接,我们可以做到这一点,以便Valohai在训练期间引用该类。 在此类的情况下,我们得出了几个时代,即迭代次数和得分(损失函数的值)。 这是该类的代码片段:
public void iterationDone(Model model, int iteration, int epoch) { if (printIterations <= 0) printIterations = 1; if (iteration % printIterations == 0) { double score = model.score(); System.out.println(String.format( "{\"epoch\": %d, \"iteration\": %d, \"score (loss function)\": %f}", epoch, iteration, score) ); } }
模型评估
一旦在上一步中成功创建了模型,就应该对其进行评估。 我们以与以前相同的方式创建一个新的执行,但是这次选择Run-dl4j-mnist-single-layer -valu-model步骤。 在开始执行之前,我们将需要再次选择Java应用程序(MLPMnist-1.0.0.jar)和创建的模型(mlpmnist-single-layer.pb)(如下所示):
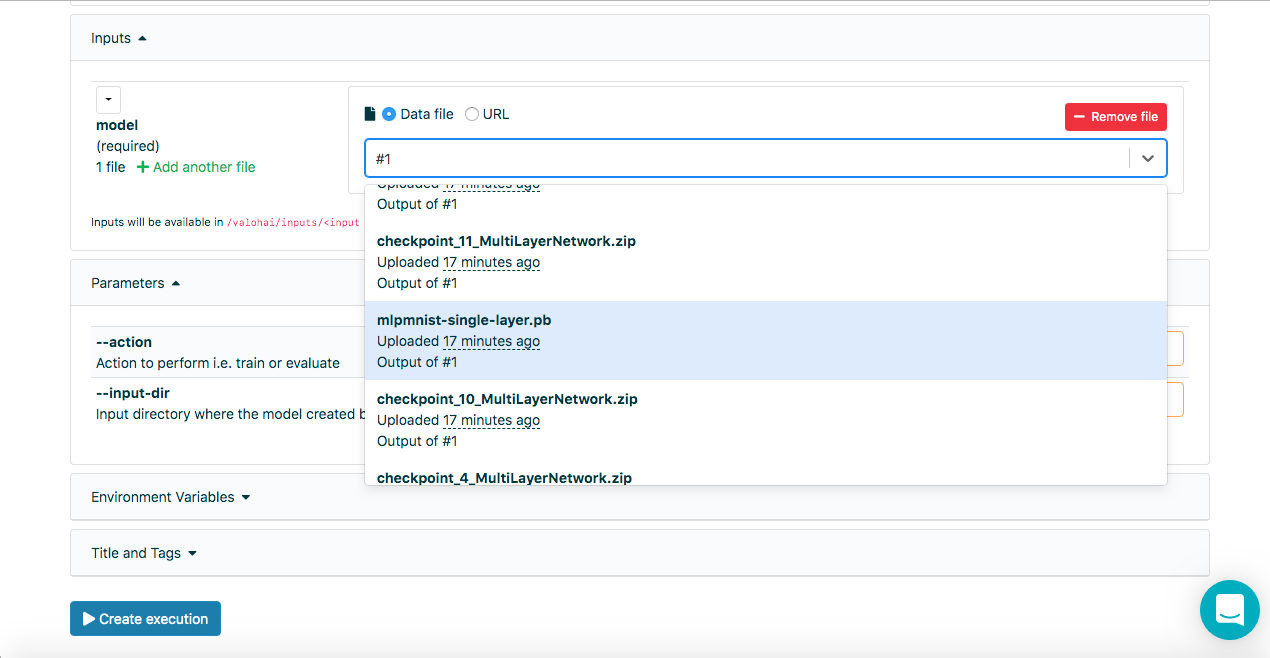
选择所需的模型作为输入后,单击[创建执行]按钮。 它的执行速度比上一个要快,我们将看到以下结果:
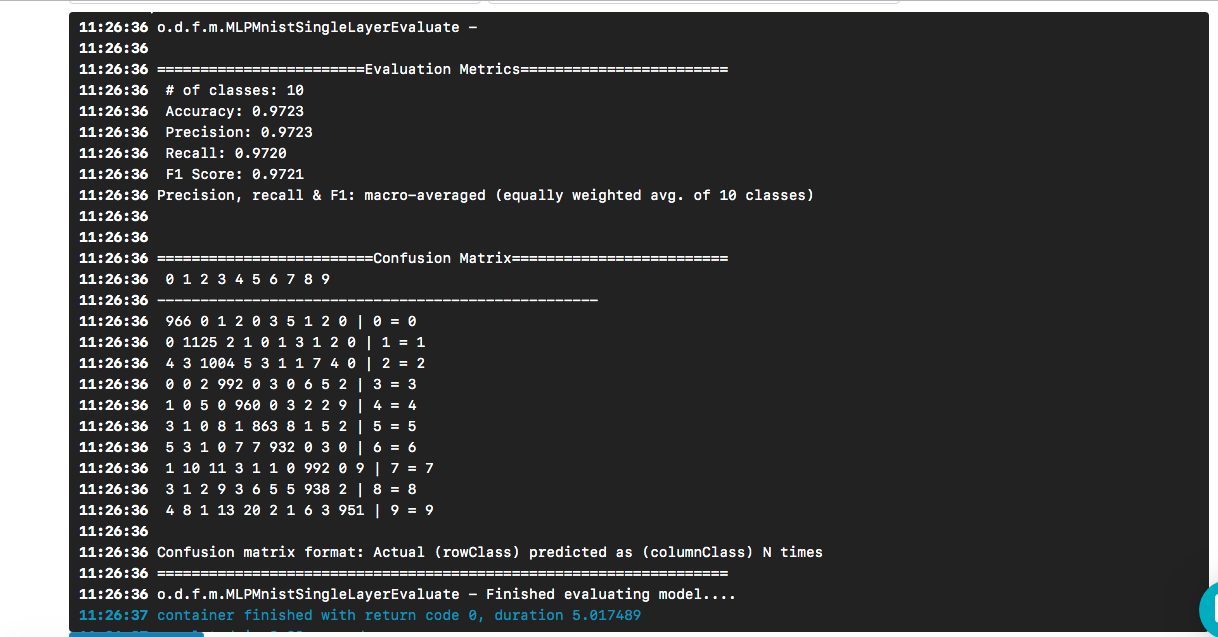
我们看到,“ hello world”导致了一个模型,根据测试数据集,该模型的准确性约为97%。 混淆矩阵有助于查找将某个数字错误地预测为另一个数字的情况。
问题仍然存在(并且不在本文的讨论范围之内)-当面对真实数据时,模型的质量如何?
要克隆git存储库,您需要执行以下操作:
$ git clone https://github.com/valohai/mlpmnist-dl4j-example
然后,我们需要将通过上一节中的Web界面创建的Valohai项目与存储在本地计算机(我们刚刚克隆的计算机)上的项目链接。 运行以下命令以执行此操作:
$ cd mlpmnist-dl4j-example $ vh project --help ### to see all the project-specific options we have for Valohai $ vh project link
您将看到如下所示:
[ 1] mlpmnist-single-layer ... Which project would you like to link with /path/to/mlpmnist-dl4j-example? Enter [n] to create a new project.:
选择1(或适合您的那个),您将看到以下消息:
Success! Linked /path/to/mlpmnist-dl4j-example to mlpmnist-single-layer.
在继续之前,还要做一件事,通过执行以下操作确保您的Valohai项目与最新的git项目同步:
$ vh project fetch
现在,我们可以使用以下命令从CLI完成步骤:
$ vh exec run Build-dl4j-mnist-single-layer-java-app
执行完成后,我们可以使用以下命令进行检查:
$ vh exec info $ vh exec logs $ vh exec watch
结论
如我们所见,与DL4J和Valohai一起工作非常方便。 此外,我们可以开发构成实验(研究)的各种组件,即构建/运行时环境,代码和数据集,并将它们集成到我们的项目中。
本文中使用的示例模板是开始创建更复杂项目的好方法。 您可以使用Web或命令行界面来与Valohai一起工作。 使用CLI,您还可以将其与安装和脚本(甚至与CRON或CI / CD作业)集成。
另外,很明显,如果我正在从事与AI / ML / DL相关的项目,则不必担心创建和维护端到端管道(过去许多人都必须这样做)。
参考文献
- GitHub上的mlpmnist-dl4j-examples项目
- 很棒的AI / ML / DL资源
- Java AI / ML / DL资源
- 深度学习和DL4J资源
感谢您的关注!