
两年前,由于不小心打开了电视,我在Vesti节目中看到了一个有趣的故事 。 据说莫斯科信息技术部正在创建一个神经网络,该网络将从照片中读取水表的读数。 在故事中,电视节目主持人请镇民帮助该项目,并将其仪表图发送到mos.ru门户,以便在其上训练神经网络。
如果您是莫斯科的一个部门,那么在联邦频道上发布视频并要求人们发送仪表的图像不是什么大问题。 但是,如果您是一家小型创业公司,却无法在电视频道上做广告怎么办? 在这种情况下如何获取50,000张柜台的图片? Yandex.Toloka来救助!
Yandex.Toloka是一个众包平台,来自世界各地的人们可以在此平台上执行简单的任务,并为此获得收益。 例如,漫游者可以在图像中找到行人, 训练语音助手等。 同时,不仅Yandex员工,而且任何希望的人都可以在Toloka上发布任务。
问题陈述
因此,我们要创建一个神经网络,该网络将从照片中确定计数器的读数。 从哪里开始,我们需要什么数据?
与同事协商后,我们得出结论,为了创建MVP,我们需要1000个计数器图像。 此外,对于每个计数器,我们想知道当前读数以及带有数字的窗口坐标。 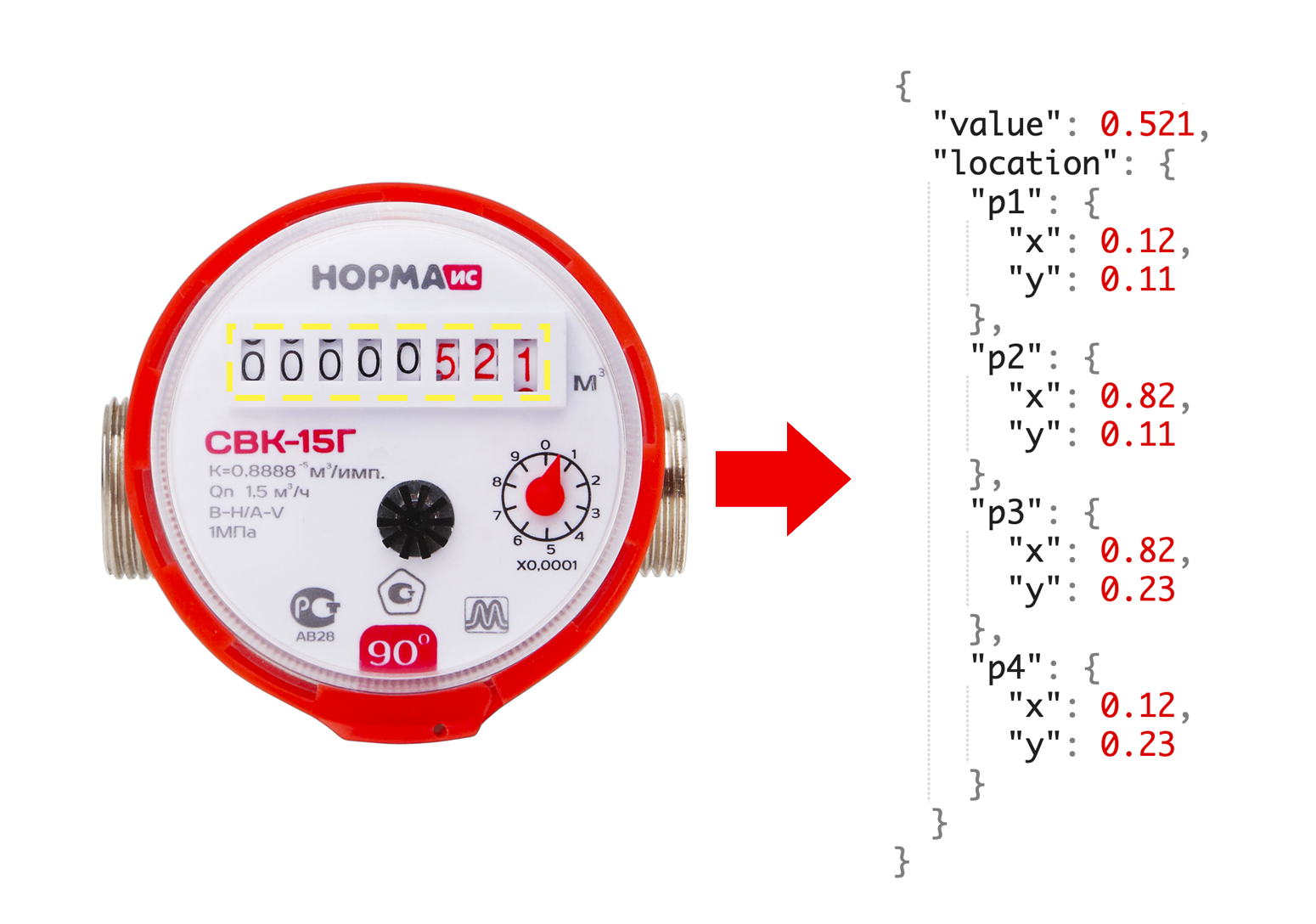
如果您从未与Toloka一起工作过,建议您阅读我一年前写的文章 。 由于当前文章在技术上会更加复杂,因此我将忽略上一篇文章中详细描述的几点。
致谢上一篇文章在ODS社区的文章排名中成为TOP-2。 感谢您发表评论并提出建议!)
第1部分。图像采集
有什么会更容易? 只需要求对方在手机上打开Yandex.Tolok应用程序并为其柜台拍照即可。 如果我几年没有与Toloka合作,我的指示将是: “您需要拍摄水表(冷或热)并向我们发送图像 。 ”
不幸的是,用这样的问题陈述,就不能收集好的数据集。 事实是,人们可以用不同的方式来解释该传统知识,因为这些说明没有正确完成任务的明确标准。 储物柜可以发送:
Toloka博客提供了有关如何编写指令的出色教程 。 跟随他,我得到了以下指示: 
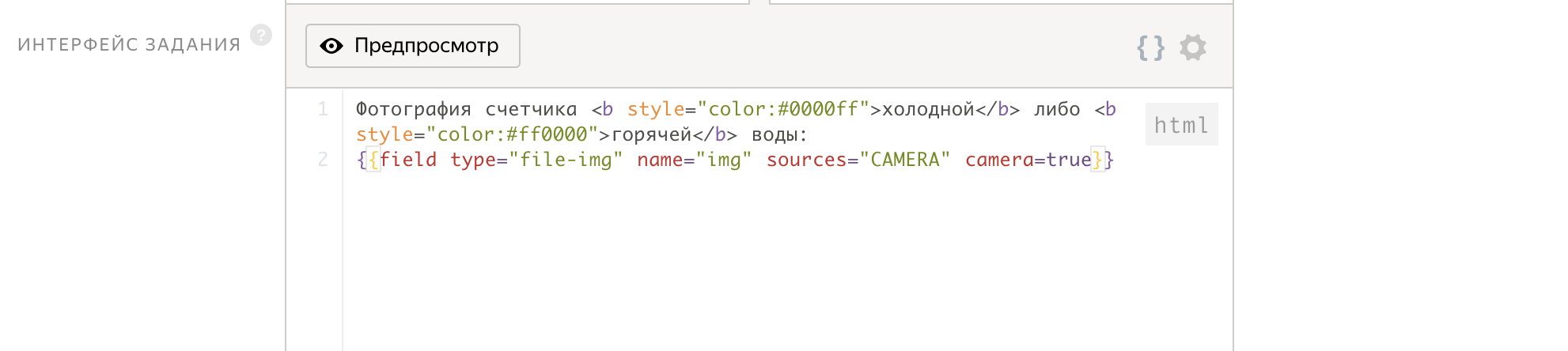
作为输入参数,我们传递任务的id,在输出处获得img文件,该文件将包含计数器的图像。

作业界面仅用2行编写!
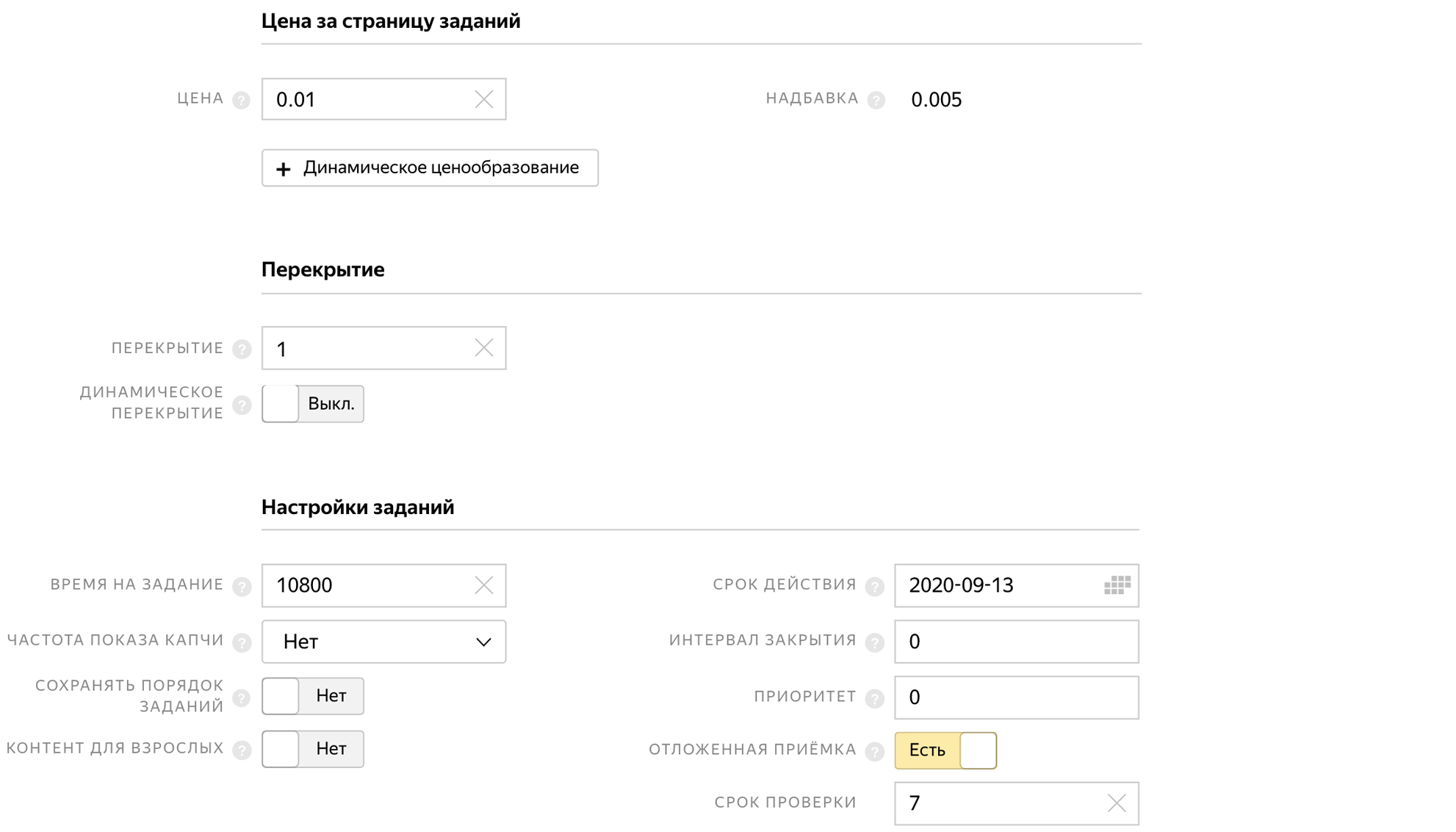
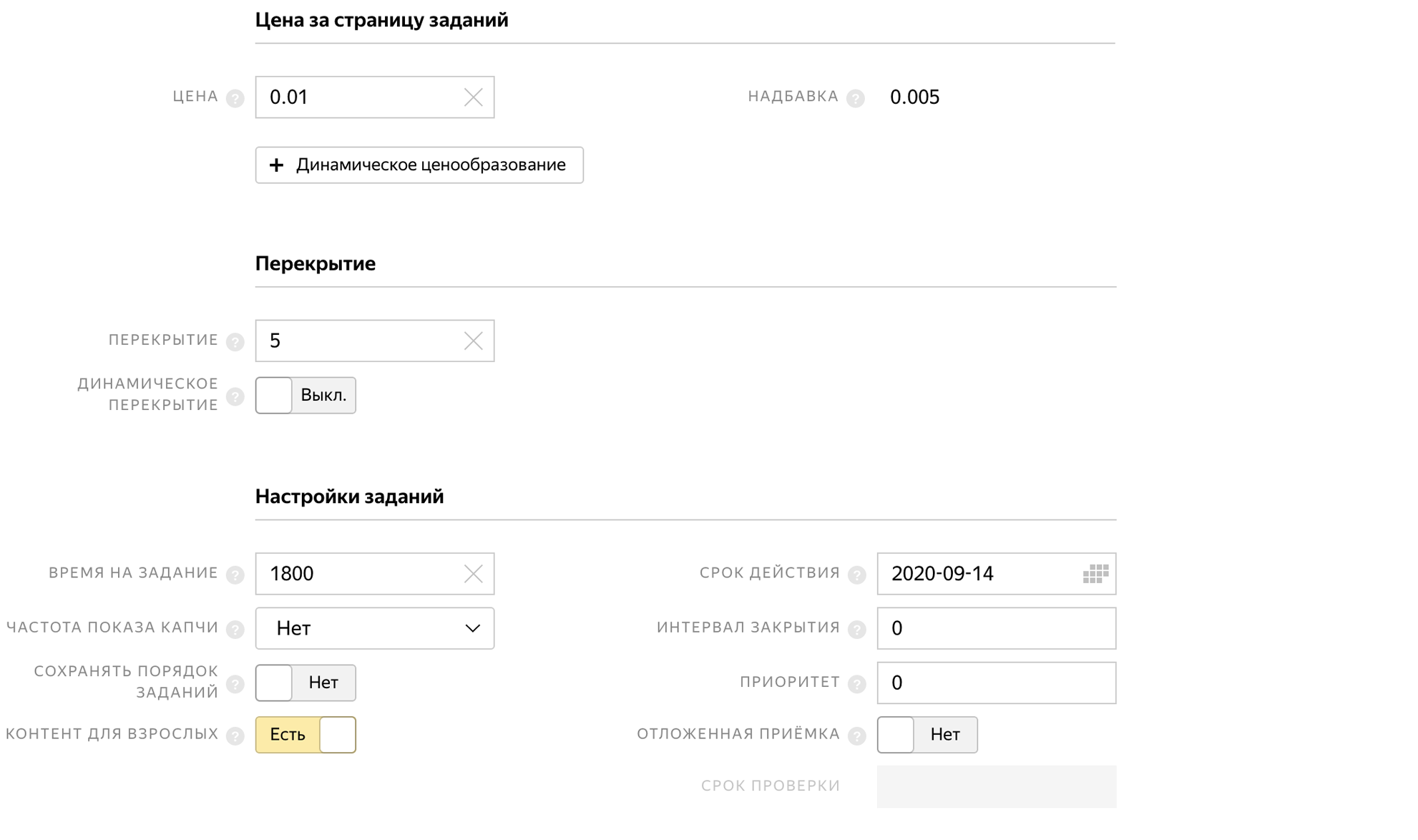
在创建池时,我们指示完成任务的时间,延迟接受和任务价格$ 0.01。
为了使人们不会多次完成任务并且不发送相同的照片,我们禁止在质量控制模块中重复执行任务。
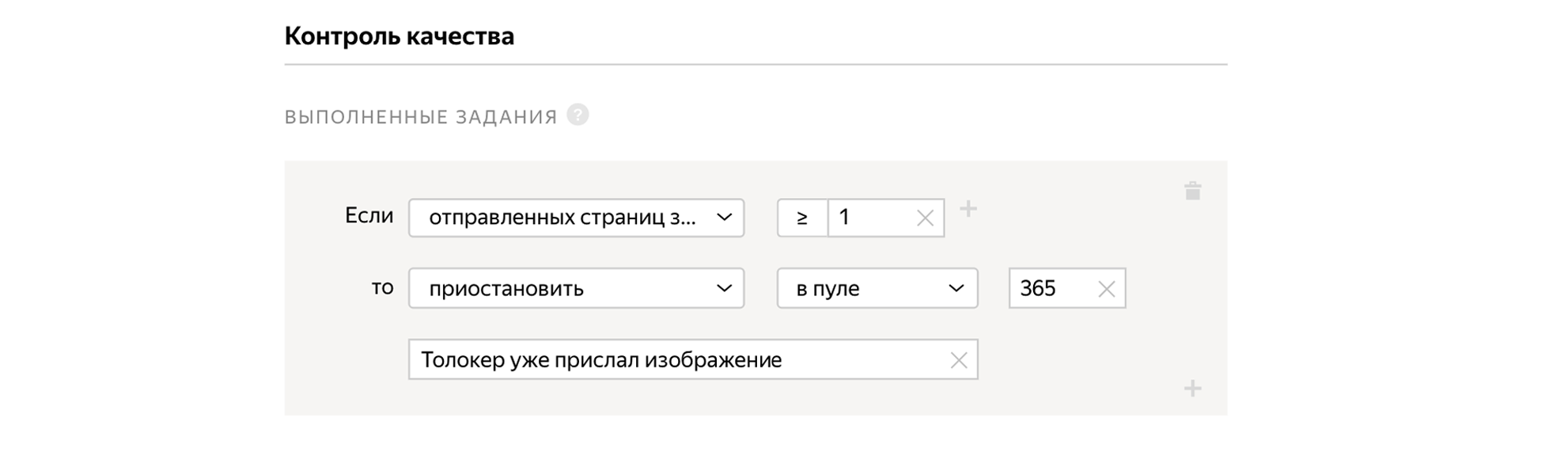
我们指出,我们需要说俄语的用户,这些用户通过Yandex.Tolok移动应用程序完成任务。
将任务下载到池中。
我们启动游泳池,欢欣鼓舞,等待用户回应! 这是我们的任务从交易者的角度来看的样子:
第2部分。任务的接受
在等待了几个小时之后,我们看到托勒斯人完成了任务。 由于延迟接受,因此奖励不会立即支付给承包商,而是冻结在客户的资产负债表上,现在我们必须检查所有发送的图像。 为使善意的表演者接受任务,以及为标准发送不合适的图像的表演者,请拒绝并写下拒绝的原因。
如果没有很多图片,那么我们可以查看并检查自己发送的所有图片。 但是我们要获得成千上万的图像! 检查此任务量将需要大量时间。 另外,此过程需要我们直接参与。
Toloka再次救援! 我们可以创建一个新任务“检查计数器图像”,并要求其他托槽者回答该图像是否符合我们的标准。 只需设置一次流程,便可以实现全自动数据收集和验证! 同时,数据收集可轻松扩展,如果我们需要多次增加数据集的大小,只需单击几个按钮即可。
听起来棒极了,不是吗?
然后是时候将这个想法付诸实践了!
首先,我们将定义我们认为照片良好的标准。
在以下情况下,照片很好:
- 照片中恰好有一个冷热水柜台。
- 柜台上的读数清晰可见。
在其他情况下,照片被认为是不良的。
我们整理了条件,现在正在编写说明! 
作为输入参数,我们将链接传递到图像。 输出将是两个标志:
- check_count-第一个问题的答案
- check_quality-第二个问题的答案
计数器将被写入值变量。
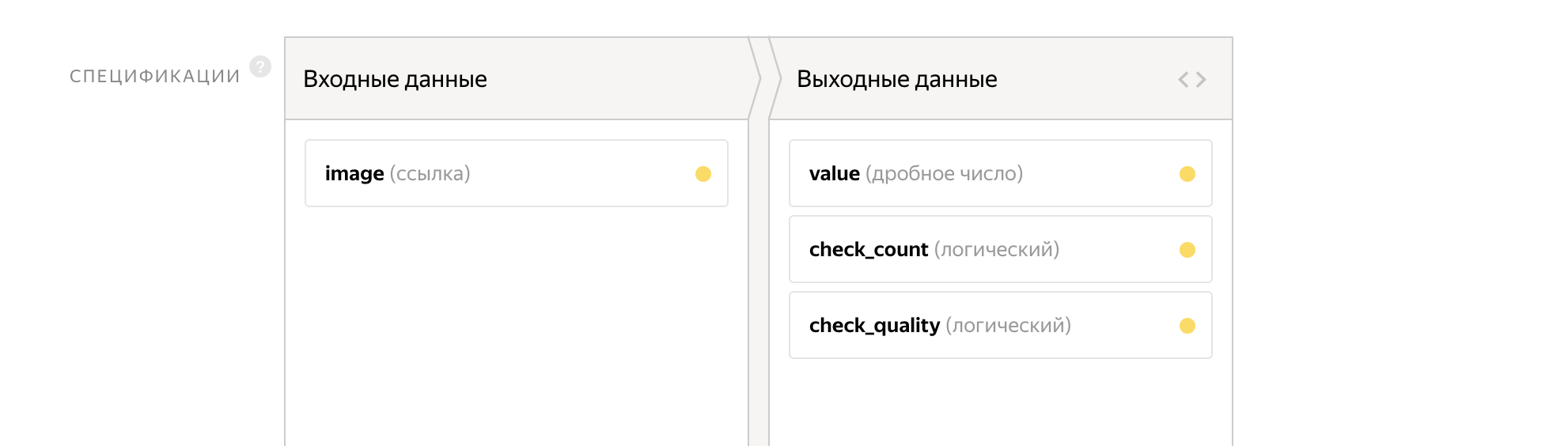
该任务的接口已经占用14行。
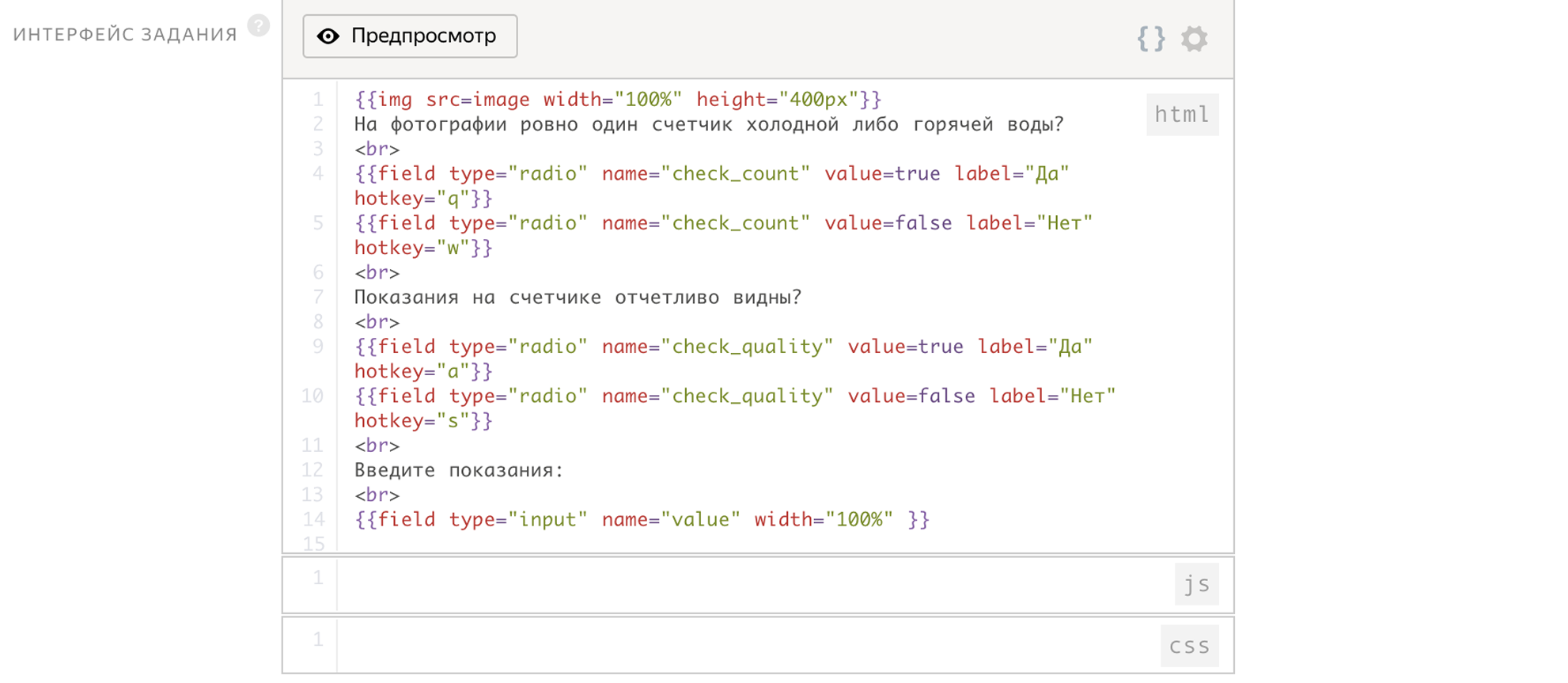
为了提高准确性,一张图像将由5个toker进行独立检查,为此,我们将重叠5个。然后,我们将查看5个人的回答方式,并假设正确答案是多数人投票赞成的答案。 该任务将不再延迟验收。
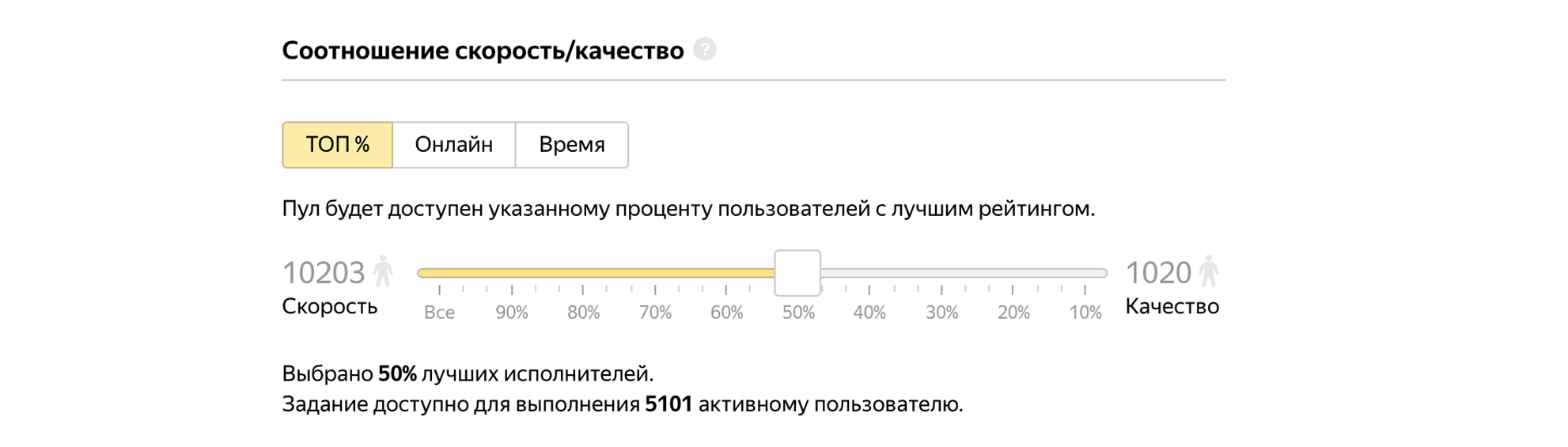
让我们承认50%表现最佳的人。
在没有延迟验收的任务中,每个人都会获得付款,无论他们是否正确执行任务。 但是我们希望通行者仔细阅读说明,尝试并正确完成任务。 如何做到这一点?
Tolok中有两个主要工具可让您保持良好的质量:
- 培训。 在完成主要任务之前,我们可以要求培训师接受培训。 在培训池中,为人们提供了我们事先知道正确答案的任务。 如果一个人回答不正确,则会显示一个错误并说明如何回答。 在完成培训之后,我们将看到执行者完成任务的百分比,并且只允许那些做得好的人进入主要任务池。
- 质量控制模块。 可能是训练池对表演者来说很棒,我们被允许这样做,但是五分钟后他离开去踢足球,将他三岁的哥哥留在电脑前。 幸运的是,Tolok中有许多方法可以让您跟踪人们如何完成任务。
使用培训池,一切都很简单:只需添加任务,在Yandex.Tolki界面中将其标记,并指定通过的阈值,我们就可以从该阈值开始允许人们执行主要任务。
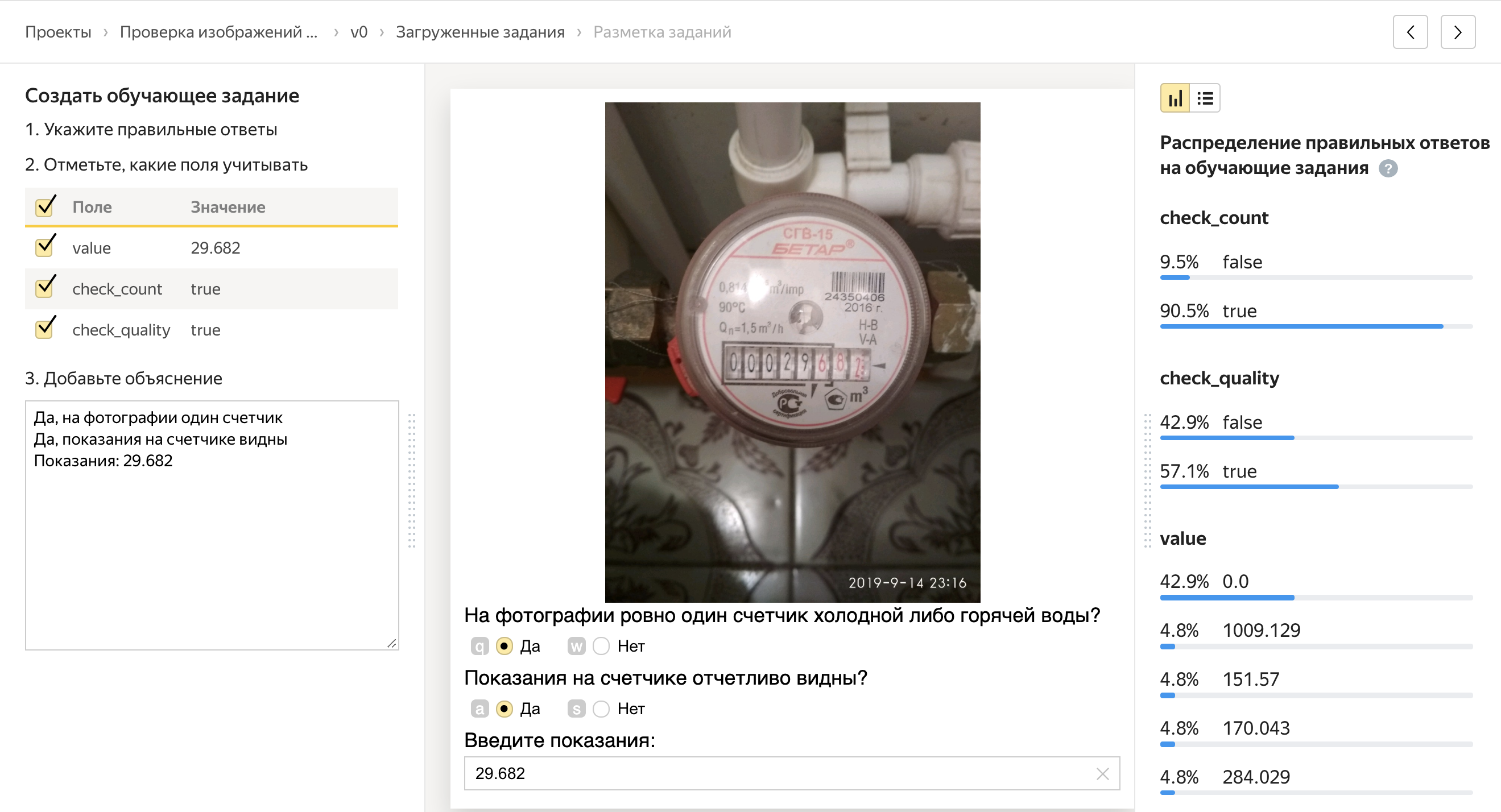
使用质量控制单元,一切都变得更有趣:它们很多,但是我将重点介绍两个最重要的单元。
多数意见
我们将任务分配给5个独立人员。 如果四个人对这个问题回答“是”,而第五个人回答“否”,那么第五个人可能就犯了一个错误。 因此,我们可以观察该人的答案与其他人的答案如何一致,并阻止与其他人做出不同反应的用户。
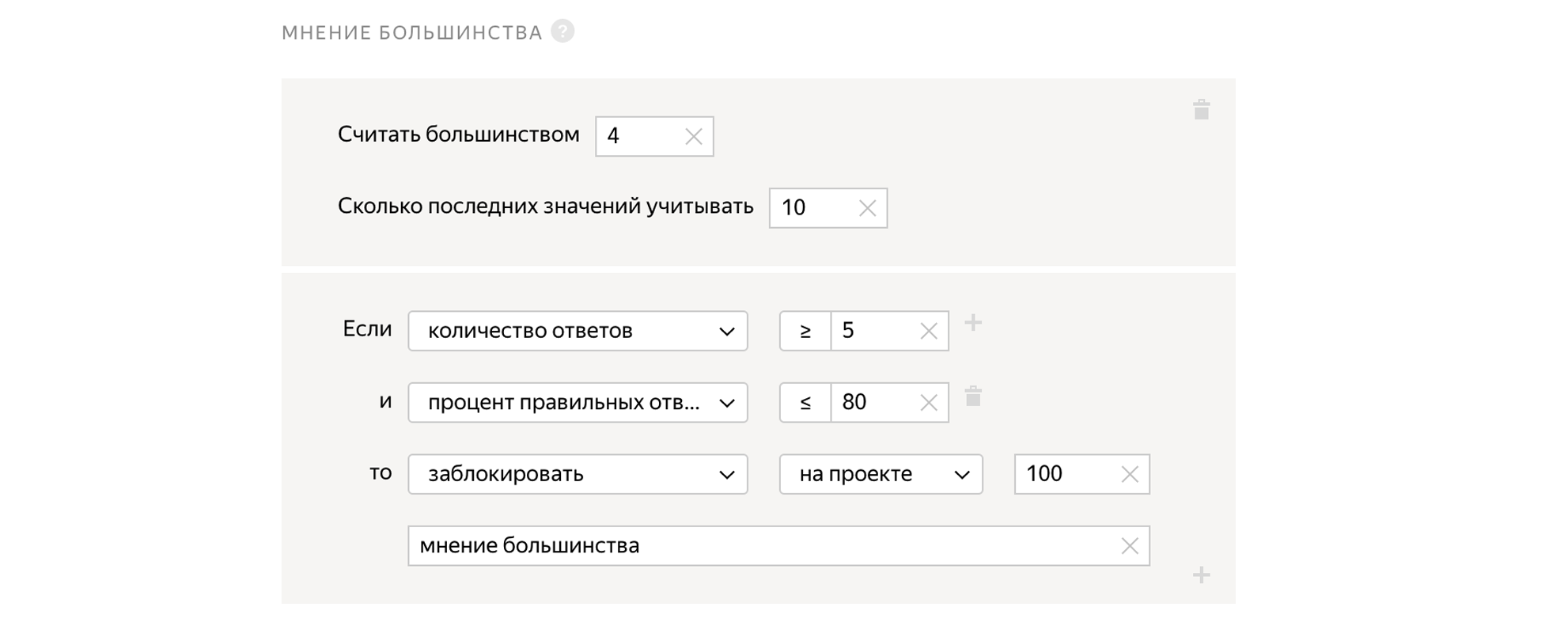
控制任务
我们可以将任务混合到池中,为此我们事先知道正确的答案。 同时,质量控制任务看起来与常规任务相同。 根据一个人是否正确地回答了控制任务,我们可以推断并假设他正确地解决了我们不知道答案的所有其他任务。 如果某人对控制任务的反应不佳,我们可以阻止他,如果一切都好,那就给与奖金。
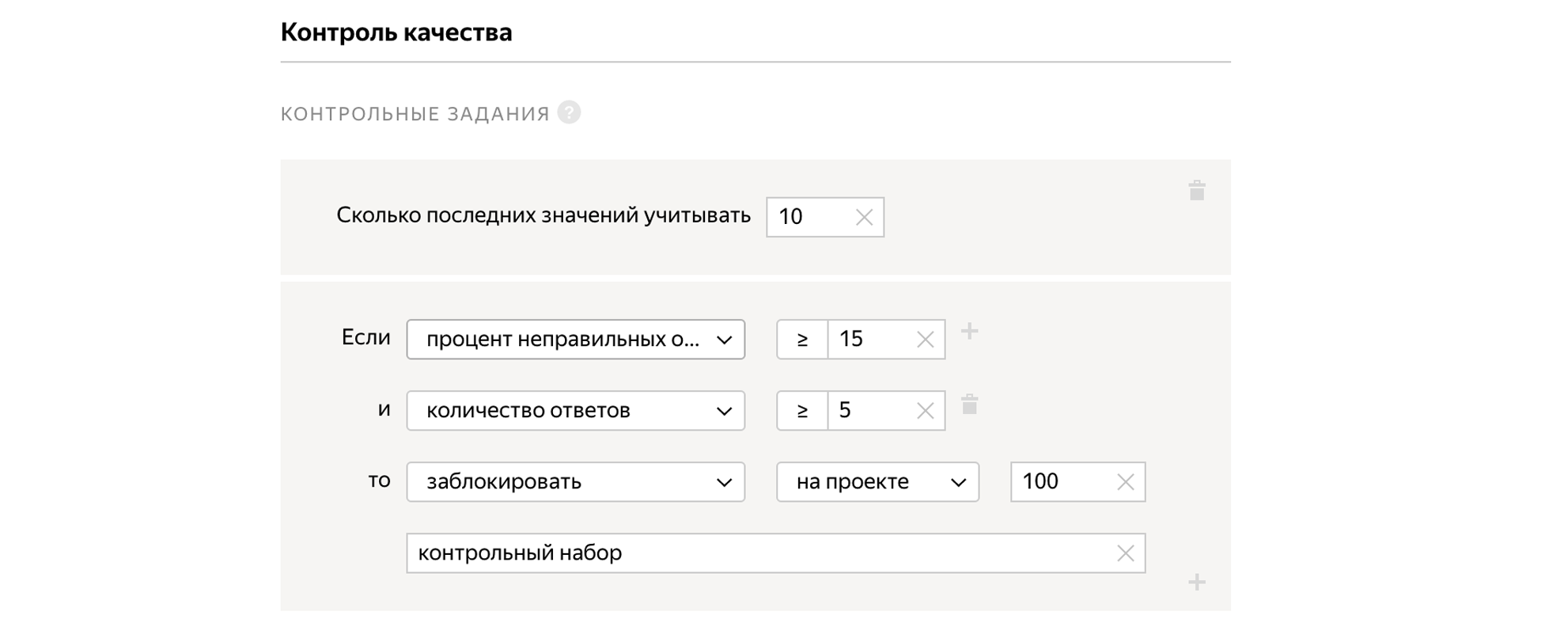
万岁,任务创建! 这是执行程序的界面外观:
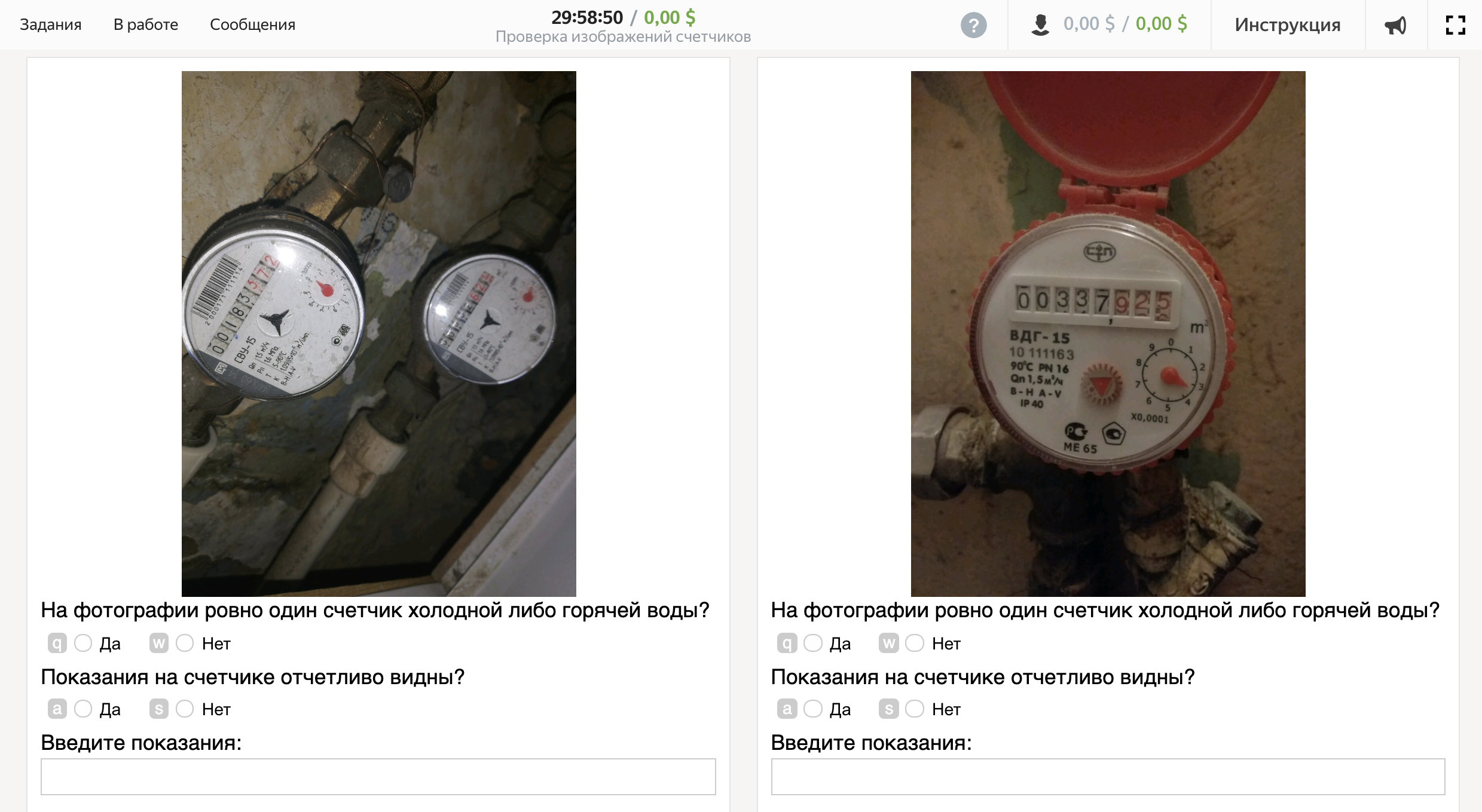
第3部分。加入工作
太好了,任务已经准备就绪! 但是问题来了,如何将任务相互连接? 在第一个任务之后如何进行第二次运行?
当然,您可以玩铃鼓并通过Toloka界面手动进行操作,但是有一种更简单,更快捷的方法! Yandex.Tolok有一个API ,使用它并编写一个python脚本!
我知道你们中的许多人不喜欢阅读代码,所以我将其隐藏在扰流器中import pandas as pd import numpy as np import requests import boto3
我们运行代码,这是期待已久的结果:871个计数器图像的数据集已准备就绪。

价钱
让我们评估项目的经济组成部分。
对于第一个任务中发送的图像,我们提供$ 0.01。
不幸的是,如果我们向表演者支付0.01美元,我们将不得不支付0.018美元。
怎么做?
- Yandex佣金是最低的(0.005.20%)。 对于价格为0.01 $的任务,佣金为50%;
- 增值税为20%。
为了检查柜台的10张图片,我们要支付$ 0.01。 在这种情况下,一张照片由独立人员检查5次。 我们总共给出一张图像进行检查:(0.01 x 5/10)x 1.2 x 1.5 = $ 0.009。
在发送的1000份意见书中,收到了871张图像,其中129张被拒绝。 因此,要获得871张图像的数据集,我们需要支付:
0.018 $ x 871 + 0.009 $ x 1000 = $ 25,您需要92,000卢布才能获得50,000张图像的数据集。 这绝对比在联邦渠道订购广告便宜!
但是这个数字实际上可以减少数倍。 您可以:
- 建议在第一个任务中拍摄一张照片,而不是几张。 同时提高价格,则Yandex佣金将不是50%,而是20%;
- 在第二个任务中使用动态重叠。 如果五分之四的人给出了相同的答案,那么将任务交给第五个人是没有意义的。
- 与Toloka一起作为外国法人实体。 在这种情况下,您无需支付增值税。
由于材料太多,我决定将文章分为两部分。 下次,我们将与您讨论如何使用Toloka选择图像中的对象以及如何为Computer Vision中的任务创建数据集。 并且为了不错过,订阅并喜欢!
聚苯乙烯
阅读该文章后,在您看来,这似乎是Yandex.Tolki的隐藏广告,但不是,不是。 Yandex没有付我任何钱,很可能不会付钱。 我只是想展示一个虚构但相关且有趣的示例,说明如何使用此服务快速,廉价地为任何任务组装数据集,无论是识别猫还是训练无人车辆。