五年前,哈布雷(Habré)发表了一篇文章
“在纸上打印和再现声音” -有关创建和播放声
谱图的系统。 然后,一年半前,
Meklon发表了一项
任务 ,其中黑白对数频谱图成为其中一个阶段。 根据作者的意图,有必要将其打印在打印机上,使用带有播放器应用程序的智能手机对其进行扫描,并以这种方式使用“指定的”密码。
那时,我无法接触打印机或智能手机,因此我对任务的两个方面感兴趣:
- 没有附加设备也没有附加软件的最简单的解码频谱图的方法是-最好是在浏览器中?
- 是否可以完全不需任何软件即可“通过肉眼”对其进行解密?
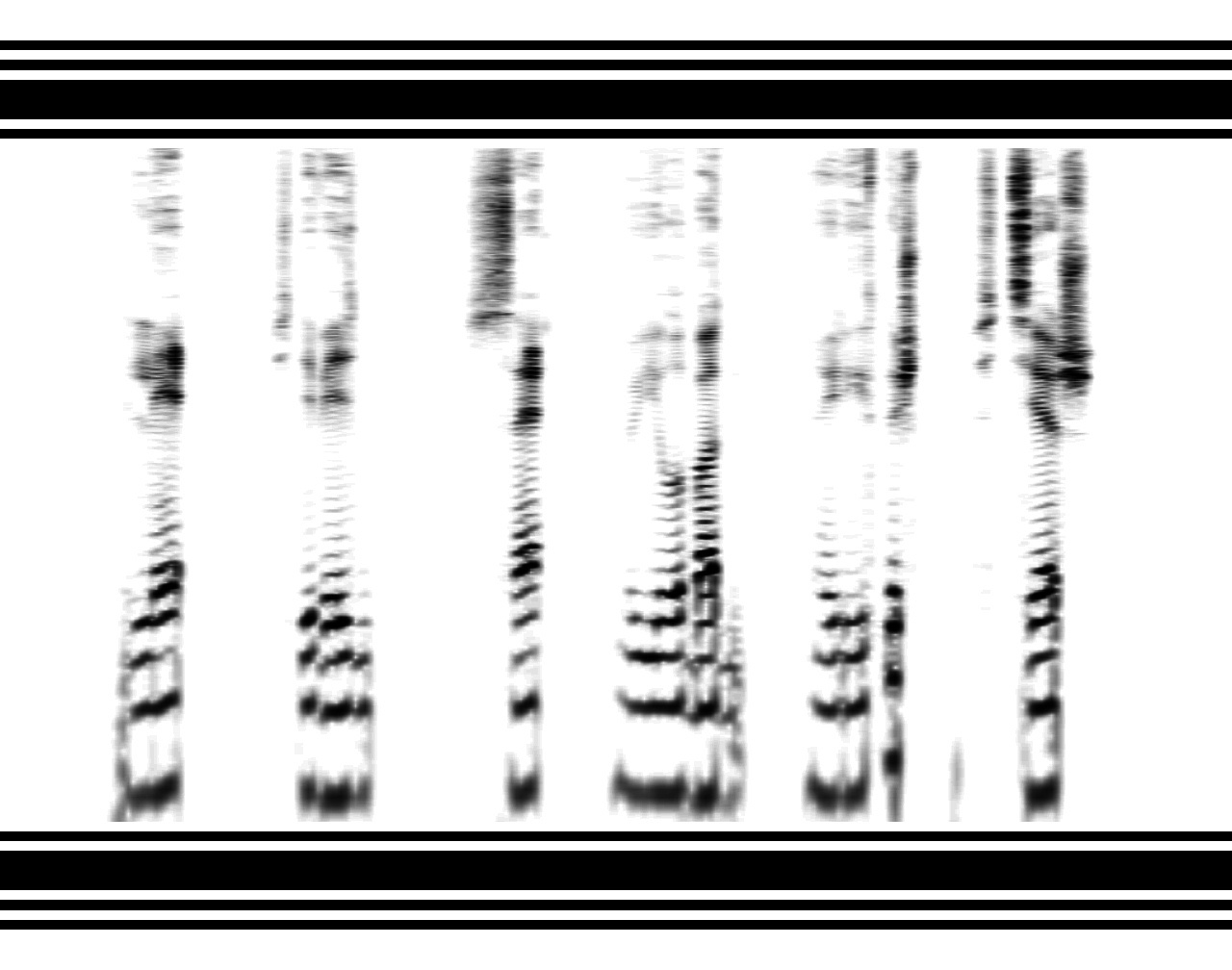
(对于那些第一次看频谱图的人来说,有必要澄清一下,这是一个曲线图,其中再现时间沿水平轴移动,声音频率沿垂直轴(对数),点的黑度表示该频率在给定时间的功率。)
尽管
AnalyserNode.getByteFrequencyData()的功能已内置在Web Audio API中,但我找不到用于复制频谱图的现成脚本,尽管
可以 很容易地找到逆向转换的示例(声音到频谱图
AnalyserNode.getByteFrequencyData() 。 但是,要将频率阵列转换为
PCM阵列以进行回放,您必须在脚本中实施
傅立叶逆变换 (DFT),然后才能进行。
*在第一个示例中,作为频谱分析的音频记录,“ “来自Aphex Twin:作为秘密信息,音乐家将自拍照嵌入了这首曲目,并显示在对数频谱图上。不幸的是,在此示例中,频谱图以线性方式显示,因此脸部在顶部被拉伸,在底部被压缩。
关于DFT的实现,很明显,纯JavaScript中的这种“崩溃”将缓慢而令人遗憾地起作用。 幸运的是,我在asm.js上发现了FFTW库的
现成端口 (“西方最快的傅立叶变换”),是低级代码的一种表示形式,通常用C编写,现代浏览器承诺以与编译成机器代码几乎相同的速度执行。 FFTW的绑定将黑白图像转换为WAV文件,我从
ARSS那里取来,并亲自用JavaScript重写了它。 与PhonoPaper相比,ARSS接受倒置的图像,但我没有更改。
您可以在
tyomitch.imtqy.com/#meklon.png欣赏的结果
在下面,您可以看到重复的水平条纹-
共振峰 ,通过其识别元音的位置。 在顶部-对应于
嘈杂辅音的垂直“爆发”:较宽-开槽(摩擦),较窄-有声。
对于高音辅音([r]和[l]),中频处的“云”相对应。

为了使用频谱图,我附加了一个原始绘图,该绘图几乎完全从画布绘图
教程复制而来。 “复制”按钮允许您将图像传输到红色通道(合成器将其忽略),并尝试“环绕”声音。
维基百科写道:
“据信,分配四个共振峰足以表征言语的声音 。
” 我们圈出共振峰F
2 -F
4 (由于某些原因,合成器会忽略F
1 ),并
确保元音被完全识别:

然后,我们圈出嘈杂的辅音:
从属词 [h]为[t],平滑变为[w]; 聋人[t]的浊音[d]的特征在于存在中频共振峰。 现在,
您可以区分数字“ six”和“ de'it”:
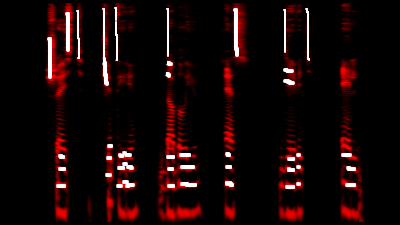
我们添加了深灰色的辅音:同时,我们注意到[p]稍微“提高”了元音共振峰,而[l]则相反。

仅唇音辅音[b]和[c]仍然被误解,但是即使没有它们,密码也
还是差不多的 。
是否可以从头开始绘制声音而无需跟踪录音的频谱图? 坦白说,我没有成功。 也许您想自己尝试一下?