本文是我对以下几个方面的看法:
- 什么是学习速度因素,其价值是什么?
- 训练模型时如何选择该系数?
- 为什么在训练模型时需要改变学习速度的系数?
- 使用预训练模型时如何处理学习速度因子?
这篇文章的大部分内容都是基于
fast.ai编写的
材料 :[1],[2],[5]和[3]-代表其工作的简明版本,旨在最快速地理解问题的实质。 为了使自己熟悉这些细节,建议单击下面给出的链接。
什么是学习速度因子?
学习速度系数是一个超参数,它决定了我们如何考虑梯度下降中的损失函数来调整尺度的顺序。 值越低,我们沿倾斜方向移动的速度就越慢。 尽管在使用较低的学习速度系数时,我们会获得积极的效果,因为我们不会错过任何一个局部最小值,但这也意味着我们将不得不花大量时间进行收敛,尤其是在高原地区。
下式说明了这种关系
 学习速度因子较小(顶部)和较大(底部)的梯度下降。 资料来源:吴安德(Andrew Ng)的Coursera机器学习课程
学习速度因子较小(顶部)和较大(底部)的梯度下降。 资料来源:吴安德(Andrew Ng)的Coursera机器学习课程
通常,学习速度因数是由用户任意设置的。 在最佳情况下,为了直观地了解哪个值最适合确定学习速度的系数,他可以依靠以前的实验(或另一种培训材料)。
本质上,选择正确的值已经足够困难。 下图说明了用户独立调整学习速度时可能出现的各种情况。
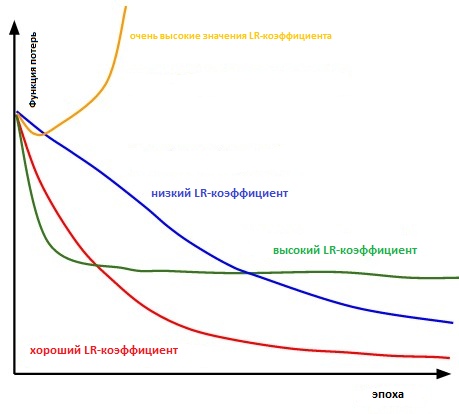 各种学习率因素对收敛的影响。 (图信用:cs231n)
各种学习率因素对收敛的影响。 (图信用:cs231n)
此外,学习速度因素会影响我们的模型达到局部最小值的速度(又将达到最佳准确性)。 因此,从一开始就进行正确的选择可确保减少训练模型的时间。 培训时间越短,在云中花在GPU计算能力上的钱就越少。
有没有更方便的方法来确定学习系数的比率?
在第3.3段。 “
神经网络的循环学习速率系数 ” Leslie Smith捍卫了以下观点:可以通过以初始设置的低学习速度训练模型来估算学习速度的有效性,然后在每次迭代中以线性或指数方式增加学习速度。
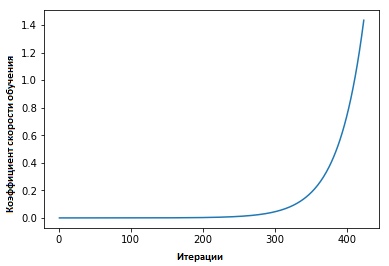 每个微型包装后,学习速度因子都会增加。
每个微型包装后,学习速度因子都会增加。
在每次迭代中固定指标的值时,我们将看到随着学习速度的提高,到达一个点(在该点处)损失函数的值停止减小并开始增加。 在实践中,理想情况下,我们的学习速度应位于图表底部的左侧(如下图所示)。 在这种情况下(值将是)从0.001到0.01。
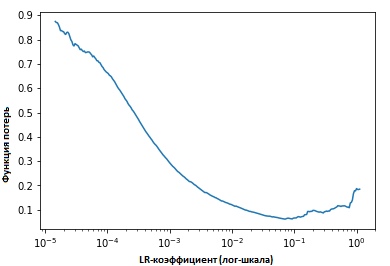
上面看起来很有用。 如何开始使用它?
目前,由Jeremy Howard开发的
fast.ia软件包中有一个现成的函数,这是pytorch库之上的一种抽象/附加组件(类似于在Keras和Tensorflow中的实现方式)。
仅需要输入以下命令,才能开始(开始)训练神经网络之前搜索最佳学习速度系数。
learn.lr_find() learn.sched.plot_lr()
改善模型
因此,我们讨论了学习速度的系数是多少,它的价值是什么,以及在开始训练模型本身之前如何实现其最佳值。
现在,我们将重点介绍如何将学习速度因子用于调整模型。
传统智慧
通常,当用户设置学习速度系数并开始训练模型时,他需要等待直到学习速度系数开始下降并且模型达到最佳值。
但是,从梯度达到平稳的那一刻起,在训练模型时,很难改善损失函数的值。 在[3]中,多芬表达了一种观点,认为使损失函数最小化的困难在于鞍点,而不是局部最小值。
 错误表面上的鞍点。 鞍点是指功能定义范围内的一个点,该点对于给定功能是固定的,但不是其局部极值
错误表面上的鞍点。 鞍点是指功能定义范围内的一个点,该点对于给定功能是固定的,但不是其局部极值 。 (图片来源:safaribooksonline)
那么如何避免这种情况呢?
我建议考虑几种选择。 其中之一,一般来说,使用[1]中的引号,
...如果不使用固定值作为学习速度系数并随时间降低它,则如果训练不再使我们的损失变得平滑,我们将根据某个循环函数f在每次迭代中更改学习速度系数。 就迭代次数而言,每个循环都有固定的长度。 这种方法允许学习速度的系数在合理的边界值之间变化。 这确实有帮助,因为当卡在鞍点上时,通过增加学习速度的系数,我们可以更快地获得鞍点高原的交点
在[2]中,莱斯利提出了一种“三角法”,其中学习速度的系数在多次迭代后都进行了修改。

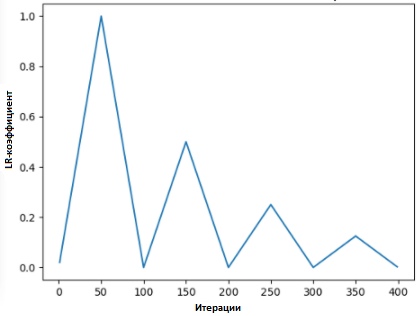 “三角形的方法”和“三角形的方法2”是Leslie N. Smith提出的循环测试学习率系数的方法。 在上方的图中,最小和最大Ir保持相等。
“三角形的方法”和“三角形的方法2”是Leslie N. Smith提出的循环测试学习率系数的方法。 在上方的图中,最小和最大Ir保持相等。Lonchilov&Hutter [6]提出了另一种同样流行的方法,称为“带热复位的随机梯度下降”。 该方法基于使用余弦函数作为循环函数,在每个循环的最大点重新启动学习速度的系数。 “热”位的出现是由于以下事实:重新启动学习率系数时,它不是从零级开始,而是从模型已达到上一步的参数开始。
由于此方法具有变化,因此下图显示了其应用方法之一,其中每个周期都绑定到相同的时间间隔。
 SGDR-图,学习率系数与 迭代
SGDR-图,学习率系数与 迭代
因此,我们可以通过不时简单地跳过“峰值”来缩短培训时间(如下所示)。
 固定和循环学习率系数的比较
固定和循环学习率系数的比较 (img信用:
arxiv.org/abs/1704.00109根据研究,除了节省时间外,此方法还可以提高分类精度,而无需进行调整且迭代次数更少。
转移学习中的转移学习比率
在
fast.ai的过程中
,重点是管理预训练模型以解决人工智能问题。 例如,在解决图像分类问题时,会教给学生如何使用预先训练的模型(例如VGG和Resnet50)并将它们链接到需要预测的图像数据样本。
为了概括如何在
fast.ai程序中构建模型(不要与
fast.Ai 软件包混淆-该程序中的软件包),以下是在通常情况下我们将采取的步骤:
- 启用数据扩充和预计算= True
- 使用Ir_find()可以找到最高的学习率系数,但损耗仍在明显改善。
- 训练1-2时代的预计算激活的最后一层。
- 以_len 1个周期训练最后一层的数据增益(即,calculate = false),持续1-2个纪元。
- 解冻所有图层。
- 将较早的图层放置在比下一个较高图层低3到10倍的学习速度因子下
- 重用Ir_find()
- 以周期_mult = 2 = 2训练一个完整的网络,直到开始重新训练。
您可能会注意到,(上述)步骤二,五和七与学习率有关。 在文章的较早部分,我们着重提到了第二个步骤的要点-在开始训练模型之前,我们谈到了如何获得最佳的学习速度系数。
在下一段中,我们讨论了如何使用SGDR来减少训练时间,并通过定期重新启动学习速度因子来提高准确性,从而避免出现梯度接近零的区域。
在最后一部分中,我们将介绍差异学习的概念,并说明当训练模型与预训练模型关联时如何使用它来确定学习速度的系数。
什么是差异学习
这是一种在训练期间在网络上设置各种训练速度因子的方法。 它为用户通常调整学习速度因子的方式提供了一种替代方法,即在培训过程中通过网络使用相同的学习速度因子。
 我喜欢Twitter的原因是该人本人的直接回应。
我喜欢Twitter的原因是该人本人的直接回应。
(在撰写本文时,杰里米与塞巴斯蒂安·鲁德(Sebastian Ruder)发表了一篇文章,后者更加深入地探讨了这个话题。因此,我相信学习速度的微分系数现在有了另一个名字-歧视性精确调整:)
为了更清楚地说明这一概念,我们可以参考下图,其中将预训练模型“分为”三组,每组随学习速度系数的增加值进行调整。
 具有差分学习率系数的CNN示例
具有差分学习率系数的CNN示例 。 图片信用来自[3]
这种配置方法具有以下理解:前几层通常包含非常小的数据细节,例如直线和角度-我们将不会尝试对其进行太多更改并尝试保存其中包含的信息。 通常,没有必要将其重量改变为任何数量。
相反,对于随后的图层(例如绿色的图片中的图层),我们可以获得详细的数据符号(例如,眼睛,嘴巴或鼻子的白色),因此不再需要保存它们。
与其他微调方法相比如何?
在[9]中,证明了微调整个模型的成本太高,因为用户可以获得100多个层。 人们通常会一次一次地优化模型。
但是,这就是许多要求的原因,所谓的 干扰并发性,并且需要通过数据集进行多个输入,这会导致对小集合进行过度训练。
我们还表明,[9]中提出的方法能够提高准确性,并减少与NRL分类有关的各种任务中的错误数量。
 结果取自来源[9]
结果取自来源[9]参考文献:
[1]改善学习率的工作方式。
[2]循环学习率技术。
[3]使用差异学习率进行转移学习。
[4] Leslie N. Smith。 训练神经网络的循环学习率。
[5]估计深度神经网络的最佳学习率
[6]随机梯度下降与热重启
[7] 2017年深度学习重点优化
[8]第1课笔记本,fast.ai第1部分V2
[9]用于文本分类的微调语言模型