我叫伊万·邦达连科(Ivan Bondarenko)。 自2005年左右以来,我一直在研究用于文本分析和口语的机器学习算法。 现在,我在莫斯科物理技术公司工作,是基于NTI人工智能MIPT能力中心和数据怪兽公司的业务解决方案实验室的领先科学开发人员,该公司致力于解决行业中各种问题的交互式系统的实际开发。 我也在我们的大学里教了一点。 我的故事将致力于聊天机器人是什么,如何使用机器学习算法和其他方法来使人机通信自动化以及在何处实现。
视频中可以看到我在“科学故事之夜”上的演讲的完整版,我将在下面的文本中提供简短摘要。

算法功能
首先,人机交互算法已成功应用于呼叫中心。 呼叫中心操作员的工作非常困难且昂贵。 而且,在许多情况下,几乎不可能完全解决人机通信问题。 当我们与通常有数千名客户的银行合作时,这是一回事。 您可以招募呼叫中心的工作人员,他们将为这些客户提供服务并与他们交谈。 但是,当我们解决更艰巨的任务时(例如,我们生产智能手机或其他一些消费类电子产品),我们的客户不是数千名,而是全球数千万。 我们想了解人们对我们的产品存在哪些问题。 通常,用户在论坛中彼此共享信息或写信给智能手机制造商的支持服务。 现场运营商将无法在庞大的客户群上应对工作,而这里的算法可以抢救出来,它们可以在多渠道模式下工作,为大量人员提供服务。
为了解决这些问题,为用于与人互动并从任意消息中提取含义,重要信息的对话系统建立算法,计算机语言学领域存在着一个领域,即对自然语言文本的分析。 机器人必须能够阅读,理解,听,说等等。 该区域-自然语言处理-分为几个部分。
理解文本(自然语言理解,NLU)。
当机器人与人交流并且有人向该机器人写东西时,您需要了解所写内容,用户想要的内容以及他在演讲中提到的内容。 了解用户的意图,即所谓的意图-一个人想要什么:重新发行银行卡或订购比萨饼。 以及命名实体的分配,即用户专门谈论的事情:如果是披萨,则是“玛格丽塔”或“夏威夷”,如果是卡,则是哪个系统-万事达卡,世界等。

最后,理解信息的语调-一个人处于何种情感状态。 该算法必须能够检测消息写入哪个密钥,这是新闻文本,还是该消息来自与我们的机器人进行通信的人员,以便充分响应该密钥。
 文本的生成(自然语言生成)
文本的生成(自然语言生成) -以相同的人类语言(自然语言)对人类请求的适当响应,而不是复杂的图板和形式短语。
语音识别和语音合成(语音到文本和语音到文本)。 如果聊天机器人不仅与人交谈,而且会讲话和倾听,则需要教他理解口语,将声音振动转换为文本,然后使用文本理解模块来分析此文本,然后从响应文本中生成声音振动然后该人,订户将听到。
聊天机器人的类型
聊天机器人包括几种关键体系结构。
回答最常见问题的聊天机器人(FAQ-chatbot)是最简单的选项。 我们总是可以提出人们提出的一系列模型问题。 对于提供即食餐点的站点,通常存在以下问题:“交付费用多少”,“您是否将其交付给Pervomaisky区”等。您可以根据几个类别,意图和用户意图对它们进行分组。 为每种意图选择典型的答案。
目标聊天机器人(面向目标的机器人)。 在这里,我试图展示这种聊天机器人的架构,该架构已在iPavlov项目中实现。 iPavlov是一个创建对话式人工智能的项目。 特别是,专注的聊天机器人可帮助用户实现某些目标(例如,在餐厅预订餐桌或订购披萨,或从银行了解有关问题的信息)。 它不仅是关于问题的答案(问题-答案-没有任何上下文)。 目标聊天机器人具有一个用于理解文本,对话管理的模块和一个用于生成响应的模块。
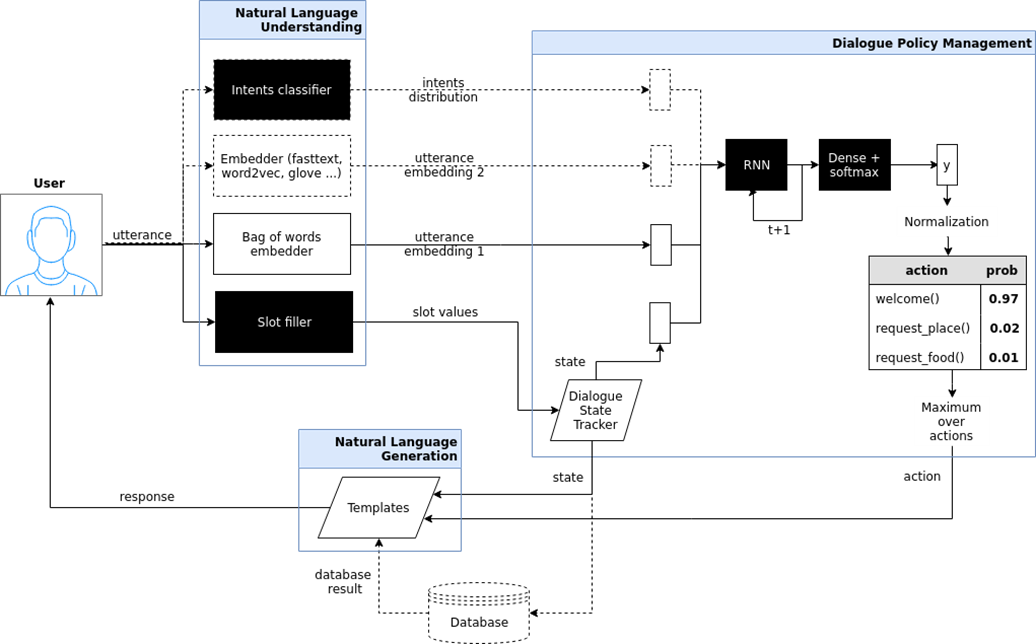 问答系统的聊天机器人,只是“谈话者”(聊天机器人)。
问答系统的聊天机器人,只是“谈话者”(聊天机器人)。 如果前两种聊天机器人要么回答最常见的问题,要么引导用户浏览对话框,最后帮助预订餐厅,弄清楚用户想要的是中国菜还是意大利菜等,那么问题就可以回答了。系统是另一种聊天机器人。 这样的聊天机器人的目标不是沿着对话栏移动,不只是对用户的意图进行分类,而是提供信息搜索-查找与该人的问题最匹配的文档以及该文档中包含答案的位置。 例如,大型零售商的员工不必记住管理工作的指令或寻找将荞麦放在哪里的答案,而可以基于问答系统向这样的聊天机器人提问。
机器学习的类型
意图的识别,命名实体的分配,文档中的搜索以及文档中与问题的语义相对应的位置的搜索-如果没有机器学习,没有某种统计分析,所有这些都是不可能实现的。 因此,现代聊天机器人的基础是机器学习-任务方法,大型数据集中存在的某些隐藏模式的近似以及这些模式的标识。 在存在模式,任务时采用这种方法很有意义,但是不可能提出一个简单的公式,形式主义来描述这种模式。
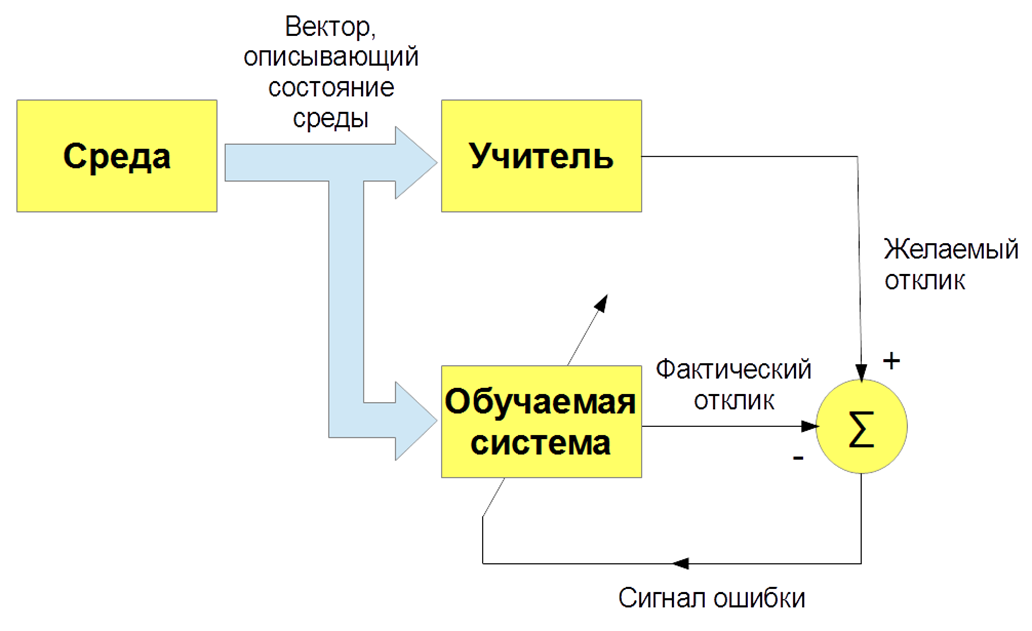
机器学习有几种类型:有老师(监督学习),没有老师(无监督学习),有强化(强化学习)。 我们最感兴趣的是与老师一起教学的任务-当有输入的图像和老师的指示(标签)以及这些图像的分类时。 或输入语音信号及其分类。 然后,我们教我们的机器人,我们的算法来重现老师的工作。
好吧,一切似乎都很酷。 以及如何教计算机理解文本? 文本是一个复杂的对象,字母如何变成数字并给出文本的矢量描述? 有一个最简单的选择-“单词袋”。 我们以整个系统的字典为例,例如,俄语中的所有单词,然后用单词频率表述这种非常稀疏的向量。 此选项适用于简单的问题,但不适用于更复杂的任务。
2013年,单词和文本建模发生了一场革命。 托马斯·米科洛夫(Thomas Mikolov)根据分布假设提出了一种有效的单词向量表示的特殊方法。 如果在相同的上下文中找到不同的单词,则它们具有某些共同点。 例如:“科学家进行了算法分析”和“科学家进行了算法研究”。 因此,“分析”和“研究”是同义词,指的是大致相同的事物。 因此,您可以教一个特殊的神经网络来按上下文预测单词,或按单词预测上下文。
最后,我们如何训练? 为了训练机器人了解意图和真实意图,您需要使用特殊程序手动标记一堆文本。 要教机器人了解命名实体-人名,公司名称,位置-您还需要放置文本。 因此,一方面,与老师的学习算法是最有效的,它允许您创建有效的识别系统,但另一方面,会出现问题:您需要大型的,标记的数据集,这既昂贵又耗时。 在标记数据集的过程中,可能存在人为因素引起的错误。
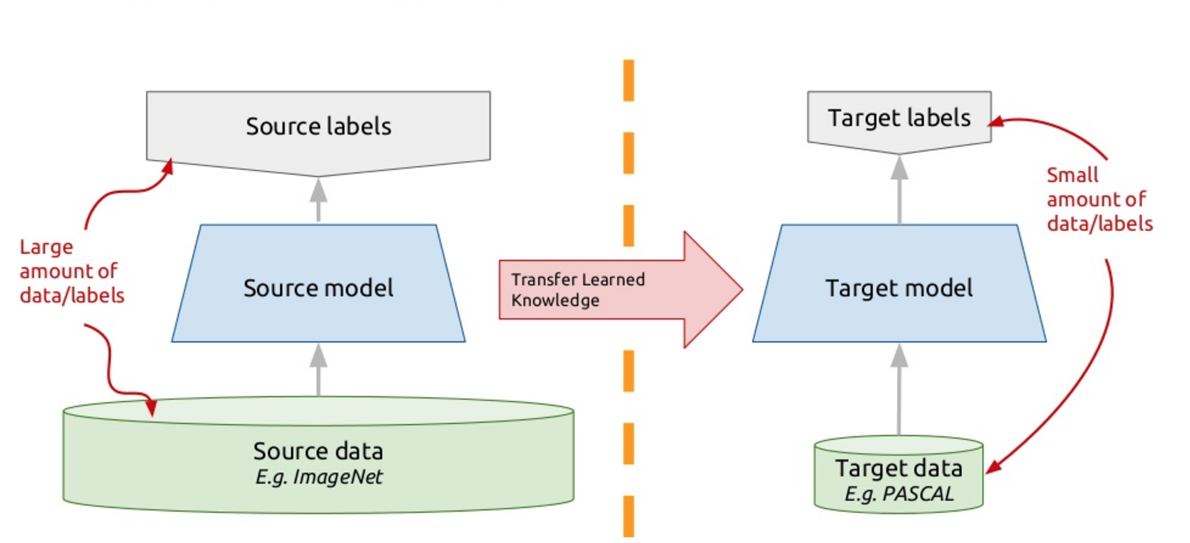
为了解决这个问题,现代的聊天机器人使用了所谓的转移学习-转移学习。 那些会说多种外语的人可能会注意到这种细微差别,以至于学习另一种外语比学习另一种外语要容易。 实际上,当您学习一些新任务时,您正在尝试利用过去的经验。 因此,转移学习基于此原理:我们讲授该算法来解决我们拥有大量数据集的一个问题。 然后,这个训练有素的算法(也就是说,我们不是从头开始使用该算法,而是训练它来解决另一个问题),我们训练来解决我们的问题。 因此,我们使用少量数据获得了有效的解决方案。
一种这样的模型是ELMo(语言模型的嵌入),例如芝麻街的ELMo。 我们使用循环神经网络,它们具有记忆力并可以处理序列。 例如:“程序员Vasya喜欢啤酒。 每天下班后的晚上,他去乔纳森(Jonathan),错过一两杯。” 那么,他是谁? 他是今天晚上,还是啤酒,还是程序员Vasya? 在给定上下文的情况下,将词作为序列元素处理的神经网络是递归神经网络,可以理解关系,解决此问题,并突出显示某种语义。
我们训练了一个如此深的神经网络来对文本进行建模。 形式上,这是与老师一起学习的任务,但老师本身就是未放置的文字。 课文中的下一个单词是与之前所有单词相关的老师。 因此,我们可以使用数十亿字节的文本,数十亿字节的文本,训练这些文本中的语义所强调的有效模型。 然后,当我们在输出模式下使用语言模型的嵌入(ELMo)时,将根据上下文给出单词。 不只是一根棍子,还让我们坚持。 我们看看神经网络在此时产生的信号。 考虑到其特定的语义意义,我们会催化这些信号,并在特定文本中获得该单词的矢量表示。
在文本分析中,还有一个功能:解决机器翻译任务时,相同的含义可以用一个英语单词和另一个俄语单词传达。 因此,没有线性比较,我们需要一种机制来关注某些文本,以便将它们适当地翻译成另一种语言。 最初,人们发现了机器翻译的注意事项-通过传统的递归神经系统将一种文本转换为另一种文本的任务。 为此,我们增加了一层特殊的注意力,它可以随时评估哪个单词对我们现在很重要。
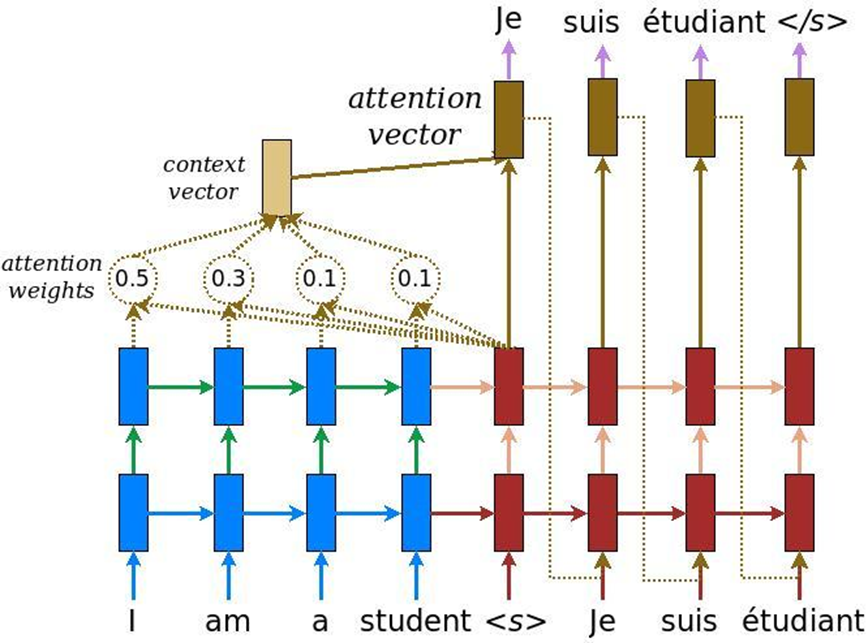
但是后来来自Google的人想到,为什么不使用没有递归神经网络的注意力机制-只是注意力。 他们提出了一种称为变压器的架构(BERT(来自变压器的双向编码器表示形式))。
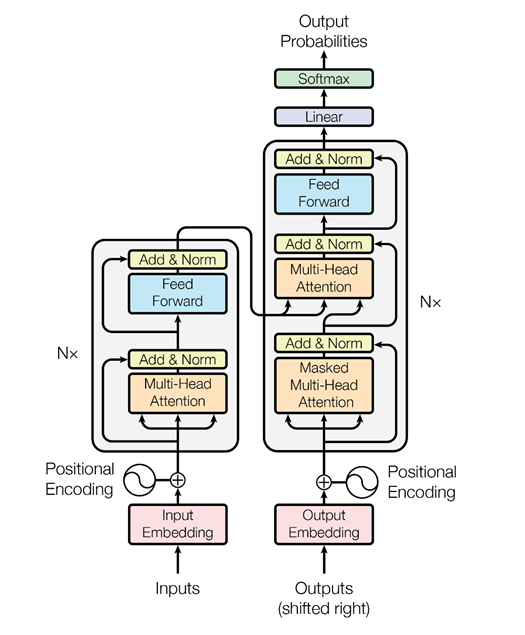
基于这样的体系结构,当只有多头注意力时,就发明了特殊的算法,该算法还可以分析文本中单词之间的关系,文本之间的关系-就像ELMo一样,更加巧妙。 首先,它是一个更酷,更复杂的网络。 其次,我们同时解决两个问题,而不是像ELMo那样解决一个问题-语言建模,预测。 我们正在尝试恢复文本中的隐藏单词并恢复文本之间的链接。 就是说:“程序员Vasya喜欢啤酒。 每天晚上他去酒吧。” 两个文本相互关联。 “程序员Vasya喜欢啤酒。 起重机在秋天飞向南方-这是两个无关的文本。 同样,可以从未分配的文本,经过训练的BERT中提取此信息,并获得非常出色的结果。
该文章于去年11月发表在“注意就是您所需要的一切”一文中,我强烈建议您阅读。 目前,这是在文本分析领域解决各种问题的最酷结果:用于文本分类(识别音调,用户意图); 用于问答系统; 用于识别命名实体等。 现代对话系统使用BERT,预训练的上下文嵌入(ELMo或BERT)来了解用户的需求。 但是对话管理模块仍然经常是基于规则设计的,因为特定的对话可能非常依赖于主题甚至任务。