当群集达到数百台(有时甚至几千台)计算机时,就会出现服务器状态相对于彼此的一致性的问题。 筏式分布式共识算法可提供最严格的一致性保证。 在本文中,我们将从工程师的角度考虑Raft,并尝试回答“如何?”的问题。 和“为什么?” 他正在工作。

文章作者: Dmitry Pavlushin (开发人员Dodo Pizza Engineering)。
Raft是
一种分布式共识算法 ,需要使多个参与者共同决定事件是否发生以及随后发生的事情。
Raft群集提供的数据是由记录组成的日志。 当用户想要更改存储在集群中的数据时,他尝试使用以下命令将新记录添加到日志中:
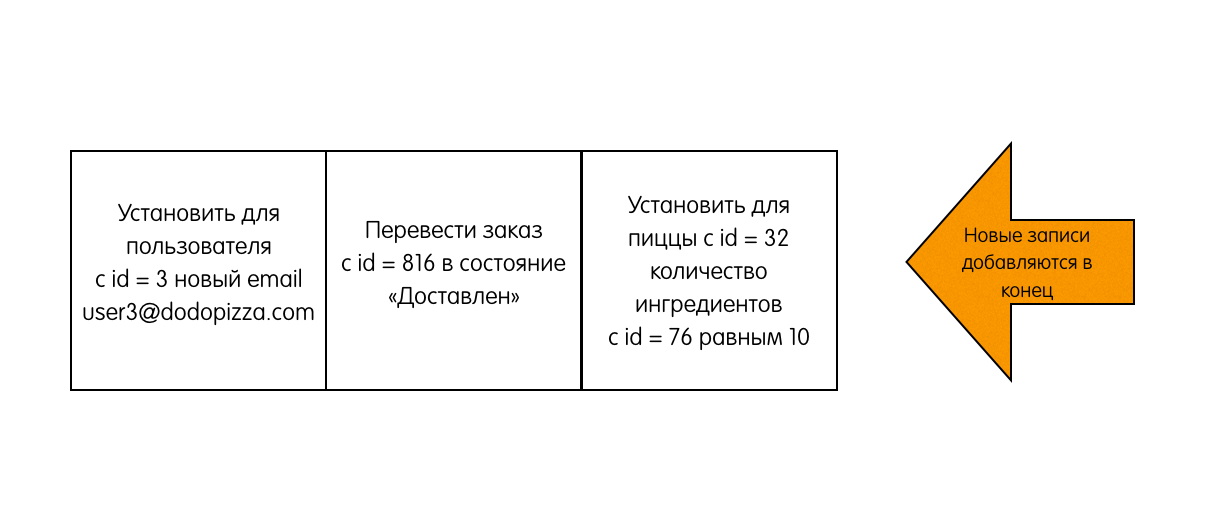
这些命令由分布式状态机执行。 为简单起见,在本文的框架中,我们将假定在读取给客户时仅给出这些记录,该客户基于已发生的事件来恢复系统的当前状态
(请参阅事件源) 。
为了确保在Raft中达成共识,首先要选择一个负责人,由他负责管理分布式日志。 领导者接受来自客户端的请求,并将其复制到群集中的其他服务器。 如果领导者失败,则会在集群中选择一个新的领导者。 这是短短的三句话。 详情将在后面。
基本概念
- 服务器状态 在Raft群集中,每个给定时间的每个服务器都处于以下三种状态之一:
- 领导者(leader)-处理所有客户端请求,是日志中所有数据的真实来源,支持跟随者日志。
- 追随者(追随者)是被动服务器,它仅“侦听”领导者的新日志条目,并将所有来自客户端的传入请求重定向到领导者。 实际上,它是领导者的热备份副本。
- 候选(candidate)是服务器的一种特殊状态,仅在选择新领导者时才有可能。
在群集中正常运行期间,只有一台服务器是领导者,其余所有服务器都是其跟随者。
关于异步这里值得注意的是条件是一个相对的概念。 由于服务器异步通信,因此不同的服务器可以在不同的时间观察其他服务器从一种状态到另一种状态的转换。
- 木筏将时间分成任意长度的段,称为截止时间 。 每个术语都有一个单调递增的数字。 该术语以当一个或多个服务器成为候选服务器时选举领导者开始。 如果候选人获得多数票,则他将成为领导人,直到这一时期结束为止。 如果对票进行了分割,并且没有候选人能获得多数票,则会触发超时,并且该时间段结束。 此后,新任期从新候选人和选举开始。 这种情况称为拆分投票。 下图中的第三个术语说明了一个示例:

术语数字在Raft群集中用作逻辑时间戳记。 它可以帮助服务器确定当前更相关的信息。
服务器交互规则和条款- 每个服务器跟踪其当前期限的编号。
- 服务器在每个发送的消息中都包括其到期号。
- 如果服务器收到的邮件的条款编号比其自己的邮件编号少,则它将忽略此邮件。
- 如果服务器接收到的消息的截止日期编号比其自己的消息的截止日期长,则服务器会更新其截止日期编号以匹配接收到的消息。
- 如果候选人或领导者收到的消息的截止日期比自己的截止日期长,则他知道其他服务器已经启动了新的截止日期,因此他的截止日期不再重要。 因此,除了更新其编号之外,它还从当前状态变为“从属”状态。
- 服务器通信。 Raft中的服务器通过交换请求和响应进行交互。 基本算法仅使用两种类型的调用:
- 候选人在选举期间使用RequestVote 。 该请求包含候选人的学期号和有关候选人日志的元数据,下面将对其进行详细讨论。 响应中包含响应服务器的截止日期编号,如果服务器对该候选人进行投票,则该值包含“ true”; 如果服务器对候选人投反对票,则为False。
- 领导者使用AppendEntries进行日志复制以及心跳机制。 该请求包含领导者的任期编号,需要添加到日志中的条目的集合(在心跳情况下为空集合),有关领导者日志的一些元数据,下面也将详细讨论。 如果关注者成功将条目添加到其日志中,则响应中包含关注者术语编号和值“ true”。 如果添加日志条目失败,则为“ False”。
工作算法
1.选择一个领导者
为了确定何时开始新的选举,Raft依靠心跳。 追随者一直是追随者,直到他从当前领导者或候选人那里收到消息为止。 领导者定期向所有其他服务器发送心跳。
如果追随者一段时间未收到任何消息,他很自然地会认为领导者已经死了,这意味着该是主动采取行动的时候了。 此时,前追随者开始选举。
要启动选举,关注者将增加其任期编号,切换为“候选”状态,对其进行投票,然后将“ RequestVote”请求发送给所有其他服务器。 之后,候选人等待以下三个事件之一:
- 候选人获得多数选票(包括他自己的选票)并赢得选举。 每个服务器在每个学期中只投票一次,才能获得第一个候选人(某些例外情况,将在下面讨论),因此,只有一个候选人可以在特定任期中获得多数票。 获胜的服务器将成为领导者,开始发送心跳并为群集提供客户端请求。
- 候选人从当前任期的当前领导者或任何具有较早任期的服务器接收消息 。 在这种情况下,候选人知道他参加的选举不再重要。 他别无选择,只能认出一个新的领导者/新任期并进入追随者状态。
- 在特定的超时时间内,候选人不会获得大多数选票。 当有几位追随者成为候选人,并且投票数在他们之中分配,从而没有人获得多数票时,就会发生这种情况。 在这种情况下,该任期在没有领导者的情况下结束,候选人立即开始下一任期的新选举。
2.我们复制日志
选择领导者后,他将负责管理分布式日志。 领导者接受包含一些团队的客户的请求。 领导者将包含命令的新记录放入其日志中,然后将“ AppendEntries”发送给所有关注者,以便用新记录复制该记录。
在大多数服务器上成功复制记录后,领导者将开始考虑关闭记录并响应客户端。 领导者跟踪哪个记录是最后一个。 它将此记录的编号发送到AppendEntries(包括心跳),以便关注者可以将记录提交给自己。
如果领导者无法联系到某些关注者,他将把AppendEntries追溯到无穷大。 下图显示了Raft群集中日志的组织方式:

每个框是日志中的一个条目。 每个记录存储一个命令,例如,x←3将值3分配给键x。 该记录还存储生成它的术语的编号。 在图片中,这由正方形顶部的数字表示。 正方形的彩色显示也表示项号。 每个记录都有一个序列号(日志索引)。
3.我们保证算法的可靠性
到目前为止,从我们的研究来看,目前尚不清楚筏是否可以至少提供一些保证。 但是,该算法提供了一组属性,这些属性共同保证了其执行的可靠性:
- 选举安全 :单个任期内最多只能选一位领导人。 此属性来自以下事实:每个服务器在每个术语内只投票一次,并且对于组长而言,需要多数票
- 仅限领导者追加 :领导者不会覆盖或擦除,不会移动其日志中的条目,只会添加新条目。 此属性直接来自算法的描述-领导者可以对其日志执行的唯一操作是在末尾添加条目。 就是这样。
- 日志匹配:如果两个服务器的日志包含具有相同索引和有效期号的条目,则直到并包括此记录,两个日志都是相同的。
使用数学归纳法和图片证明当第一步是证明一个简单案例的陈述时,数学归纳法就是一种证明方法。 在第二步中,我们接受对于某些情况X的陈述为true。基于此,我们尝试证明对某些相邻案例X + 1的陈述。 这两个步骤在一起可以帮助证明所有情况的陈述。
在我们的情况下,一个简单的情况是空日志。 没有记录,因此没有违反该财产的情况。
现在,让我们假设日志中有一些条目对应于我们的属性。 筏具有一种机制,可以防止在任何日志更改时损坏属性。 这种机制称为
一致性检查 。 让我们立即看一下示例。
很好的例子 。 例如,有一个第四届的领导者,有一个跟随者。 它们都有来自三个条目的匹配日志。
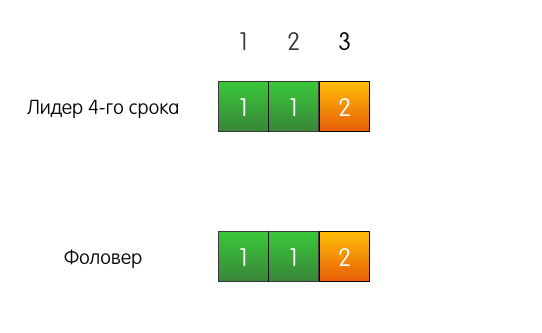
客户的请求传到了领导者,领导者将一个条目添加到他的日志中。

领导者将AppendEntries发送给关注者。 但是,除了增加最多的记录外,领导者还在请求中指出必须在索引4处添加该记录,并且在索引3之前必须在第2项中添加一条记录。
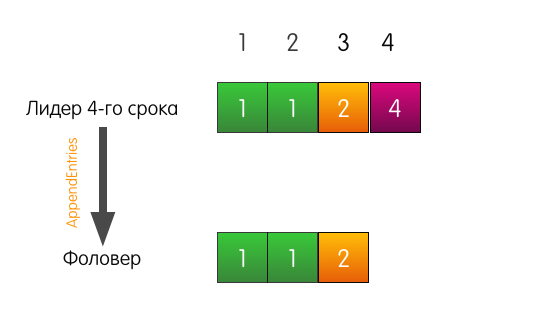
跟随者日志中索引3处的日志条目与请求中指定的条目匹配,因此跟随者将条目添加到他的日志中,并成功地响应领导者。 结束了。
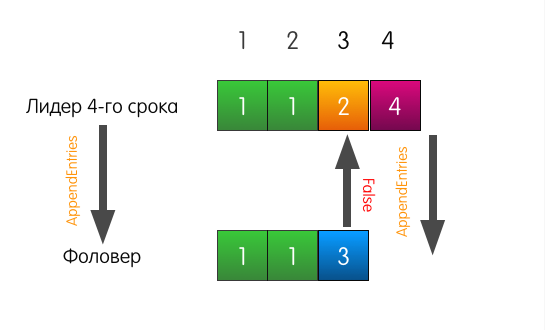
 也是一个很好的例子,但是有着悲惨的开始。
也是一个很好的例子,但是有着悲惨的开始。 现在,关注者的日志与当前领导者的日志不同。

领导者收到向日志中添加条目的请求时,他将发送与上一个示例相同的AppendEntries。

但是,这次,由于关注者与先前的记录不匹配,因此关注者失败。
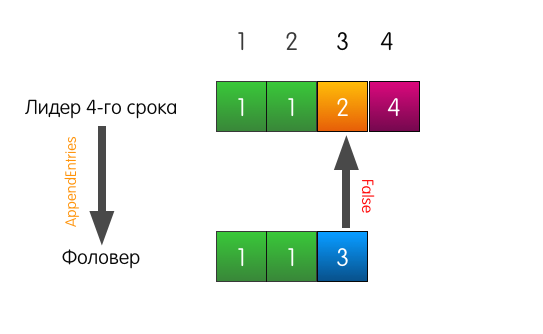
领导在这种情况下会做什么? 领导者只是略微回滚,并尝试向跟随者提供他本人认为站在索引3处的记录。他还将先前的记录包括在请求中。
现在,跟随者成功完成响应,并覆盖从索引3开始的日志中的条目。
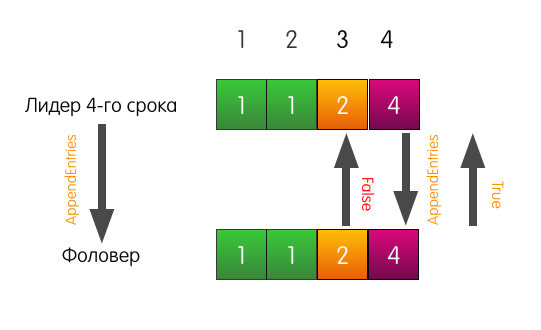
追随者的日志可能与领导者的日志有所不同。 其中可能没有足够的条目,其中可能有多余的条目。 无论如何,一致性检查可确保关注者的日志早晚与领导者的日志一致。
- 领导者完整性 :如果在给定时间提交了日志条目,则随后所有时期的领导者日志将包括该记录。 此属性为我们提供了耐用性保证。
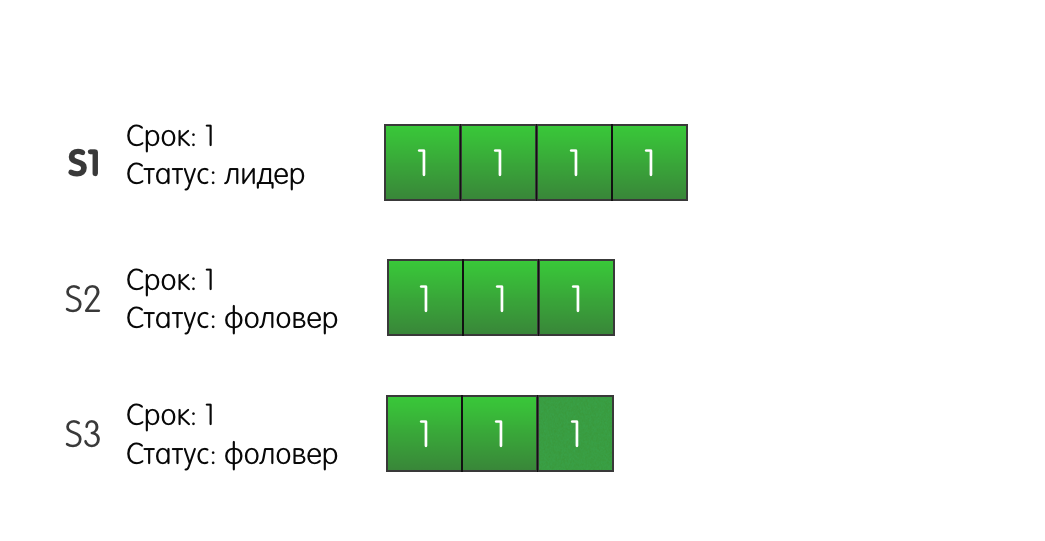
证明和图片请考虑以下情况:群集中的三台服务器。 服务器S1是当前第一任期的负责人。 所有服务器都有三个日志条目。

领导者S1收到来自客户端的请求,并将新记录添加到他的日志中,并将AppendEntries发送到其他S2和S3服务器。
记录成功到达S2,但是S1和S3之间的网络闪烁,并且请求丢失。 由于S1知道该记录存在于三个服务器中的两个中,因此它可以确定该记录已提交并成功响应客户端。
S1还将重试向S3添加一个条目,直到成功为止。 但是,如果S1发生故障并关闭,会发生什么? 而且,如果S3是第一个厌倦了等待并成为候选者的人,将会发生什么? S2将投票支持它,S3将成为第二任期的领导者,并且在下一个添加记录的请求下,S3是否会覆盖我们的记录?
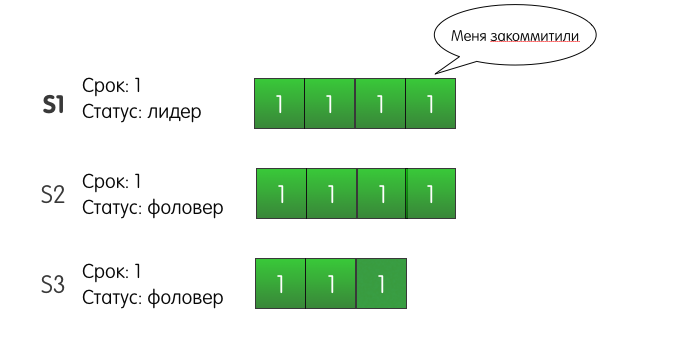
实际上,这种情况不会在Raft集群中发生。 这里的问题是S2不会投票给S3。 怎么了 因为投票时的S3服务器日志不如S2服务器日志重要。 这种机制称为
选举限制 -只有当候选人的日志与投票人的日志相关程度不低时,服务器才会投票给另一台服务器。
Raft通过两种方式比较日志的相关性:
候选人在RequestVote请求中包括这两个参数,以便关注者可以将其日志与候选人日志的相关性进行比较。
“最重要”是最后一条记录较旧的日志。

如果最后一个条目的术语编号一致,则“ main”是更长的日志。

如果它们两者重合,则日志是同等相关的,并且,如先前属性所述,它们也是绝对相同的。
事实证明,具有安全记录的服务器日志将始终比没有安全记录的服务器更为相关。 具有安全记录的服务器将不会投票给没有安全记录的服务器。 而且,由于大多数服务器上都有记录的记录,因此没有此记录的候选人将无法获得大多数选票并成为领导者,以便将该记录从其他服务器上删除。
- 状态机安全 :此属性最初是按照分布式状态机描述的,就我们的文章而言,此属性可以描述如下:当服务器提交具有特定索引的记录时,没有其他服务器为此索引提交另一条记录。
此属性来自过去。 如果追随者在索引N处提交某些记录,那么他的日志与领导者直至N(包括N)的日志相同。 领导者完整性属性保证所有后续领导者也将在索引N处包含此安全记录,这意味着在后续期间在索引N处提交记录的关注者将提交相同的值。
链接到进一步研究的材料