哈Ha
本文将采用“星期五”格式,今天我们将介绍NLP。 NLP不是关于地下通道出售哪些书籍的书,而是有关
自然语言处理正在处理自然语言的书。 作为这种处理的示例,将使用使用神经网络的文本生成。 我们可以创建任何语言的文本,从俄语或英语到C ++。 结果非常有趣,您可能可以从图片中猜测出来。

对于那些对发生的事情感兴趣的人,其结果和源代码已被削减。
资料准备
为了进行处理,我们将使用一类特殊的神经网络-所谓的递归神经网络(RNN)。 该网络与常规网络的不同之处在于,除了常规单元之外,它还具有存储单元。 这使我们能够分析更复杂的结构的数据,实际上是更接近人类记忆的数据,因为我们也不是“从头开始”。 编写代码时,我们将使用
LSTM (长期短期记忆)网络,因为Keras已支持它们。
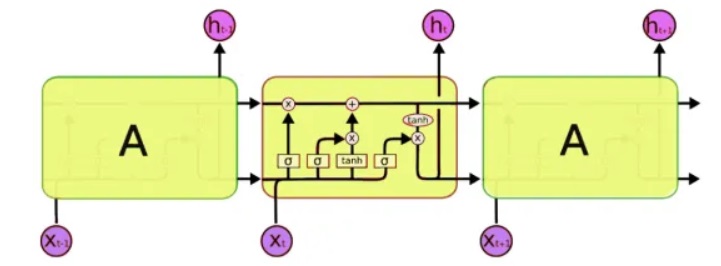
实际上,下一个需要解决的问题是处理文本。 这里有两种方法-将符号或整个单词提交给输入。 第一种方法的原理很简单:将文本分为多个短块,其中“输入”是一段文本,而“输出”是下一个字符。 例如,对于最后一个短语,“输入是一段文本”:
input: output: ""
input: : output: ""
input: : output:""
input: : output: ""
input: : output: "".
依此类推。 因此,神经网络在输入处接收文本片段,并在输出处接收应形成的字符。
第二种方法基本相同,只使用整个单词而不是单词。 首先,编辑单词词典,然后在网络输入中输入数字而不是单词。
当然,这是一个相当简化的描述。 Keras
已经有文本生成的示例,但首先,没有对它们进行详细描述,其次,所有英语教程都使用相当抽象的文本,例如莎士比亚,这对于本地人来说很难理解。 好吧,我们正在我们强大而强大的神经网络上测试一个神经网络,它当然会更加清晰和易于理解。
网络培训
作为输入文本,我使用了... ... Habr的注释,源文件的大小为1 MB(当然,注释实际上确实更多,但是我只需要使用一部分,否则该网络将被训练一个星期,而读者在星期五之前将不会看到此文本)。 让我提醒您,只有字母被输入到神经网络的输入中,该网络对语言或其结构一无所知。 我们开始网络培训。
5分钟的训练:到目前为止,还不清楚,但是您已经可以看到一些可识别的字母组合:
. . . «
15分钟的训练:结果已经明显好了:
« » — « » » —由于某种原因,所有文本都被证明没有点和大写字母,也许utf-8处理未正确完成。 但总的来说,这令人印象深刻。 通过仅分析和记住符号代码,该程序实际上“独立地”学习了俄语单词,并且可以生成看起来可信的文本。
同样有趣的是,该程序可以很好地记住文本样式。 在下面的示例中,一些法律的文字被用作教具。 网络培训时间为5分钟。
"" , , , , , , , ,
在这里,将药物的医学注释用作输入集。 网络培训时间为5分钟。
, ,
在这里,我们看到几乎整个短语。 这是由于以下事实:原始文本很短,而神经网络实际上“整体”存储了一些短语。 此效果称为“再培训”,应避免。 理想情况下,您需要在大型数据集上测试神经网络,但是在这种情况下进行的训练可能会花费很多小时,而且不幸的是,我没有额外的超级计算机。
使用这种网络的一个有趣示例是名称生成。 通过将男性和女性名字列表上传到文件中,我得到了非常有趣的新选项,这些选项非常适合科幻小说:Rlar,Laaa,Aria,Arera,Aelia,Ninran,Air。 他们身上有些感觉到埃夫雷莫夫和仙女座星云的风格...
C ++
有趣的是,总的来说,神经网络就像记忆。 下一步是检查程序如何处理源代码。 作为测试,我采用了不同的C ++源并将它们组合到一个文本文件中。
老实说,结果比俄语更令人惊讶。
5分钟的训练该死的,这几乎是真正的C ++。
if ( snd_pcm_state_channels = 0 ) { errortext_ = "rtapialsa::probedeviceopen: esror stream_.buffer stream!"; errortext_ = errorstream_.str(); goto unlock; } if ( stream_.mode == input && stream_.mode == output || false; if ( stream_.state == stream_stopped ) { for ( unsigned int i=0; i<stream_.nuserbuffer[i] ) { for (j=0; j<info.channels; } } }
30分钟的训练 void maxirecorder::stopstream() { for (int i = 0; i < ainchannels; i++ ) { int input=(stream, null; conternallock( pthread_cond_wate);
如您所见,该程序已经“学习”了编写完整的函数。 同时,它完全“人为”地将功能与带星号的注释分开,在代码中添加注释,以及所有这些。 我想以这样的速度学习一种新的编程语言...当然,代码中有错误,当然也不会编译。 顺便说一句,我没有格式化代码,该程序还学会了在方括号和缩进“我自己”中添加文字。
当然,这些程序没有主要
含义 -
含义 ,因此看起来像是在梦中写的,或者不是由一个完全健康的人编写的,因此具有超现实感。 然而,结果令人印象深刻。 也许更深入地研究不同文本的产生将有助于更好地理解真实患者的某些精神疾病。 顺便说一句,正如评论中所建议的那样,确实存在这样一种精神疾病,即一个人说出与语法相关但完全没有意义的文本(
精神分裂症 )。
结论
娱乐神经网络被认为非常有前途,与没有内存的MLP等“普通”网络相比,这确实是向前迈出了一大步。 确实,神经网络存储和处理相当复杂的结构的能力令人印象深刻。 正是在这些测试之后,当我写道未来的AI可能是“对人类最大的风险”时,我才以为Ilon Mask可能是正确的-即使简单的神经网络可以轻松记住并复制相当复杂的模式,数十亿个组件的网络能做什么? 但是另一方面,请不要忘记我们的神经网络无法
思考 ,它本质上只是机械地记住字符序列,而不是理解它们的含义。 这一点很重要-即使您在超级计算机和庞大的数据集上训练神经网络,充其量也只能学会在语法上生成100%正确但完全没有意义的句子。
但是它不会在哲学上被删除,对于实践者而言,该文章仍然更多。 对于那些想要自己进行实验的人,Python 3.7中的
源代码位于破坏者之下。 这段代码是来自各个github项目的汇编,不是最佳代码的示例,但似乎可以执行其任务。
使用该程序不需要编程技能,足以知道如何安装Python。 从命令行开始的示例:
-创建和训练模型以及生成文本:
python \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000
-仅文本生成而无需模型训练:
python \ keras_textgen.py --text = text_habr.txt --epochs = 10 --out_len = 4000-生成
我认为这是一个非常
时髦的工作文本生成器,
对于在Habr上写文章很有用 。 在大文本和大量迭代培训上进行测试特别有趣,如果任何人都可以使用快速计算机,则查看结果将很有趣。
如果有人想更详细地研究该主题,可以在
http://karpathy.imtqy.com/2015/05/21/rnn-efficiency/上找到有关使用RNN的详细说明和详细示例。
PS:最后,还有几节经文;)有趣的是,不是我本人来格式化文本甚至添加星号,而是“是我自己”。 下一步很有趣,可以检查绘制图片和创作音乐的可能性。 我认为神经网络在这里很有前途。
xxx
对于某些人来说,它们被夹在饼干中-祝一切顺利。
晚上从玉置
在蜡烛下爬山。
xxx
很快,儿子在蒙大拿州的电车
看不见的欢乐的气味
这就是为什么我在一起成长
您不会为未知而生病。
交错的小仓鼠的心
麦片粥还没老,
我守卫通往抢球的桥梁。
用与多巴(Doba)的达里纳(Darina)相同的方式,
我听见心中有雪。
我们唱白多少柔弱的杜美
我把矿石野兽拒之门外。
xxx
兽医用咒语把油条钉死
并洒在被遗忘的下方。
和你一样,古巴的分支
在其中闪耀。
在zakoto开心
随着牛奶的飞行。
哦,你是一朵玫瑰,轻盈
手上有云光:
在黎明时滚动
你好,我的骑士!
他在晚上服务,而不是骨子里
晚上在Tanya的蓝光
像一种悲伤最后几节经文学习模式。 在这里,韵律消失了,但是出现了一些含义(?)。
和你,从火焰中
星星。
跟远方的人说话。
担心您的罗斯,明天。
“鸽子雨,
和凶手的家,
给公主的女孩
他的脸。
xxx
噢,牧羊人,摇荡房间
在春天的树林里。
我要穿过房子的中心到池塘
和老鼠活泼
下诺夫哥罗德的钟声。
但不要担心,晨风,
一条小路,一个铁棍,
和牡蛎一起思考
藏在池塘上
在贫困的拉基特。