哈Ha! 我们Softpoint的朋友准备了一篇有关Microsoft SQL Server的有趣文章。 它分析了使用全文本搜索的两个实际示例:
- 在“无限”行中搜索(例如,注释),而不是通过LIKE进行常规搜索;
- 按带前缀的文件编号搜索。 通常无法使用全文搜索的地方:常量前缀会干扰全文搜索。 分析了两种方法:预处理文档编号和添加自己的库断字器。
立即加入!
 我请作者
我请作者有效搜索千兆字节的累积数据是会计系统的“圣杯”。 每个人都想找到他并获得不朽的荣耀,但是在反复搜索的过程中,事实证明,没有一个奇迹般的解决方案。
用户通常要搜索子字符串的事实使情况变得复杂-在某个地方,所需的合同编号被“埋没”在注释的中间; 在某个地方,操作员不记得确切的客户名称,但他记得自己的名字是“ Alexey Evgrafovich”; 在某个地方,您只需要省略BYUBL的重复所有权形式,并立即按组织名称进行搜索。 对于经典的关系型DBMS,这样的搜索是一个坏消息。 通常,这种子字符串搜索被简化为表中每一行的系统滚动。 这不是最有效的策略,尤其是当表的大小增长到几十GB时。
在寻找替代方案时,我经常想起“全文搜索”。 在粗略地回顾了现有实践之后,找到解决方案的乐趣通常很快就会消失。 很快发现,根据流行的观点,全文搜索是:
- 难以配置
- 慢慢更新
- 更新时挂起系统
- 具有某种
愚蠢的异常语法 - 找不到他们的要求
这套神话可以持续很长时间,但是甚至柏拉图也教导我们要持怀疑态度,不要盲目接受别人对信仰的看法。 让我们看看魔鬼是否像他被画的那样可怕?
并且,尽管我们并未深入研究,但我们将
立即就一个重要条件达成共识 。 全文搜索引擎可以做的比常规字符串搜索还多。 例如,您可以定义同义词词典,并使用单词“ contact”查找“ phone”。 或搜索单词而无需考虑形式和结尾。 这些选项对于用户可能非常有用,但是在本文中,我们仅将全文搜索视为传统行搜索的替代方法。 也就是说,
我们将仅搜索将在搜索栏中指定的子字符串 ,而无需考虑同义词,也不会将单词转换为“正常”形式和其他魔术。
MS SQL全文搜索的工作方式
MS SQL中的全文本搜索功能已部分地从主要DBMS服务中删除(在本文结尾处,我们将看到为什么这样做非常有用)。 为了进行搜索,与通常的平衡树不同,它的结构形成了一个特殊的索引。
为了创建全文搜索索引,重要的是,键表中必须存在唯一的索引,该索引仅由一列组成-它的全文搜索将用于标识表行。 通常,该表已经在主键上具有这样的索引,但是有时必须额外创建它。
全文搜索索引是异步填充的,没有事务。 更改表行后,将其排队等待处理。 更新索引的过程从表行(行)接收所有“订阅”到索引的字符串值,并将它们分解为单独的单词。 此后,可以将单词简化为某种“标准”形式(例如,不带结尾),以便更轻松地按单词形式进行搜索。 抛出“停止词”(介词,冠词和其他没有意义的词)。 其余的词对字符串链接匹配将写入全文搜索索引。
事实证明,索引中包含的表的每一列都通过这样的管道:
长行->断字器->组成部分(单词)->词干分析器->规范化单词-> [可选]停用单词异常->写入索引
如前所述,索引更新过程是异步的。 由此得出:
- 更新不会阻止用户操作
- 更新等待行更改事务的完成,并且不早于提交就开始应用更改
- 相对于主要事务,对全文索引的更改会有所延迟。 也就是说,在添加行与找到行之间,将存在延迟,具体取决于索引更新队列的长度
- 可以通过查询监视索引中包含的元素数:
SELECT cat.name, FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] FROM sys.fulltext_catalogs AS cat
实际测试。 搜索物理 人名
用数据填充表
为了进行实验,我们将使用一个表创建一个新的空基,其中将存储“对手”。 在“说明”字段中,将有一行带有合同名称的行,其中将提到交易对手的名称。 像这样:
“与Borovik Demyan Emelyanovich签订合同”
大概:
“狗。 和Borovik-Romanov Anatoly Avdeevich一起
是的,我想立即摆脱这种“架构”的束缚,但是,不幸的是,这样的“注释”或“描述”应用经常在企业用户中使用。
此外,我们添加了一些“重量”字段:如果表中只有2列,那么简单的扫描就会很快读取它。 我们需要“填充”表,以使扫描很长。 这使我们更接近实际的业务案例:我们不仅在表中存储“描述”,而且还存储许多其他[魔鬼]有用的信息。
create table partners (id bigint identity (1,1) not null, [description] nvarchar(max), [address] nvarchar(256) not null default N'107240, , ., 168', [phone] nvarchar(256) not null default N'+7 (495) 111-222-33', [contact_name] nvarchar(256) not null default N'', [bio] nvarchar(2048) not null default N' . , , . , . , . , , , , . . , , . , , . , , , . , , . . .') -- , ..
下一个问题是从哪里获得这么多独特的姓氏,名字和赞助人? 根据一个古老的习惯,我是一名普通的俄罗斯学生,即 去了维基百科:
- 从页面上获取的名字类别:俄罗斯男性名字
- 从名称手动改写中间名,更改结尾
- 有了姓氏,结果却变得有些复杂。 最后,找到了“同名”类别。 用Python进行的一点萨满教法,在一个单独的表中,结果得到了4.65万个名字。 (此处提供用于下载姓氏的脚本)
当然,姓氏之间会有奇怪的变化,但是出于研究目的,这是可以接受的。
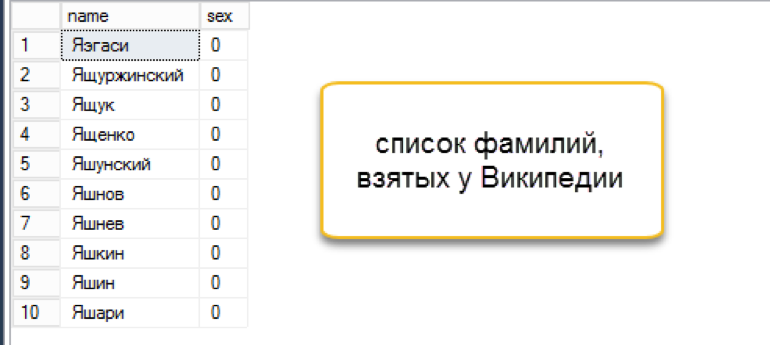
我写了一个sql脚本,在每个姓氏上附加了随机数量的名称和密码。 等待5分钟,在单独的表格中已经有450万个组合。 还不错! 每个姓氏有20至231个名字+中间名的组合,平均获得97个组合。 事实证明,按名称和主语的分布在“左侧”略有偏差,但是想出一个更加平衡的算法似乎是多余的。
数据准备好之后,我们就可以开始实验了。
全文搜索设置
在MS SQL级别上创建全文索引。 首先,我们需要为此索引创建一个存储库-全文目录。
USE [like_vs_fulltext] GO CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT AUTHORIZATION [dbo] GO
有一个目录,我们正在尝试为我们的表添加全文索引...而没有任何效果。
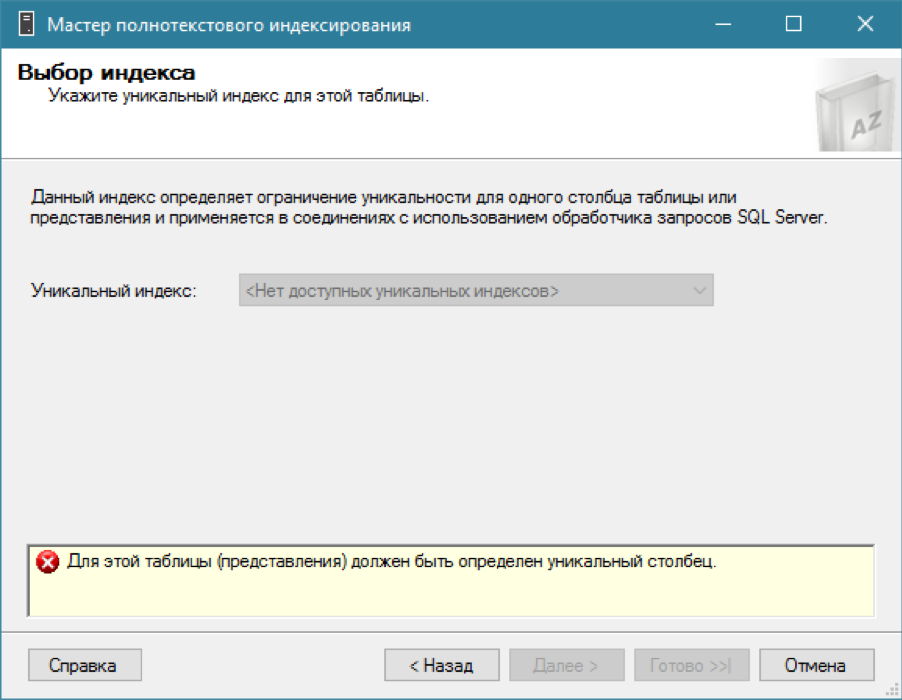
就像我说的那样,对于全文索引,您需要一个带有唯一列的常规索引。 我们记得,我们已经有必填字段-唯一的标识符ID。 让我们在其上创建一个唯一的集群索引(尽管一个非集群索引就足够了):
create unique clustered index ndx1 on partners (id)
创建新索引后,我们最终可以添加全文本搜索索引。 让我们等待几分钟,直到索引已满(请记住它是异步更新的!)。 您可以进行测试。
测试中
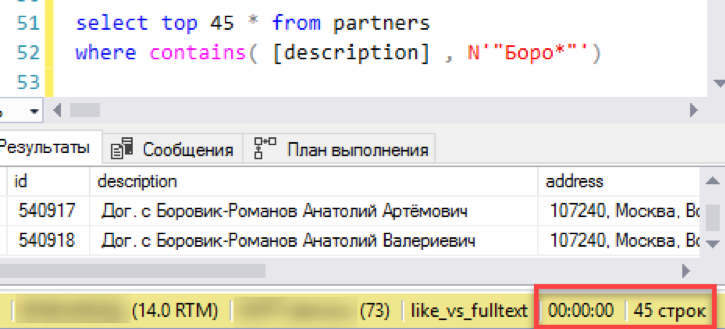
让我们从最简单的场景开始,靠近搜索的实际应用。 我们模拟了一个“列表视图”-用搜索掩码选择的45行窗口选择。 我们使用新的全文本索引执行请求,我们注意到时间-0秒-非常好!
现在是通过“喜欢”进行的古老的可靠搜索。 花了3秒钟形成了结果。 还不错,彻底失败没有用。 也许进行全文搜索是没有意义的-一切正常吗?
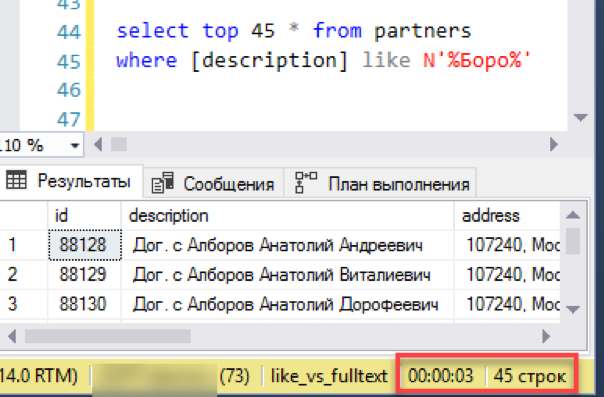
实际上,我们错过了一个重要的细节:请求没有排序就被执行了。 首先,与“选择前N条记录”配对的此类查询将返回不必要的结果。 每个开始都可以返回随机的N条记录,并且不能保证两个连续的开始将给出相同的数据集。 其次,如果我们谈论的是“使用滑动窗口查看列表”,通常,此“窗口”将按任何列(例如,名称)进行排序。 毕竟,操作员需要知道他移至下一个“窗口”时会得到什么。
纠正实验。 例如,按电话号码添加排序:
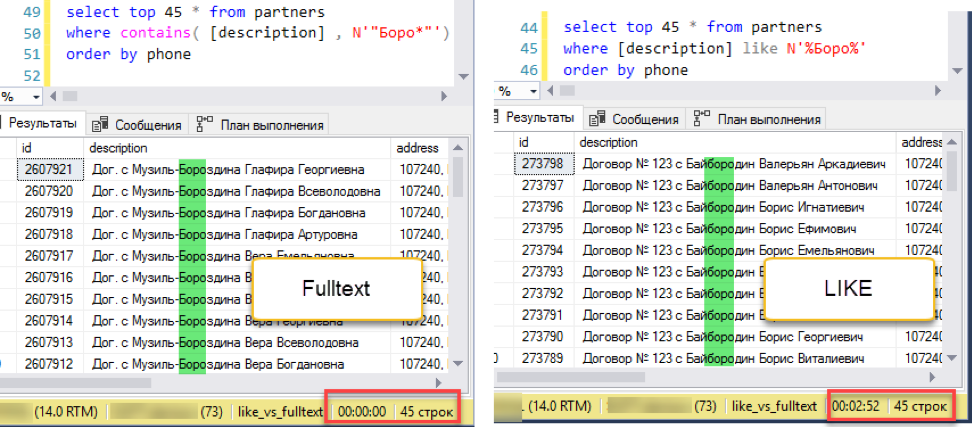 全文搜索以震耳欲聋的成绩获胜:0秒和172秒!
全文搜索以震耳欲聋的成绩获胜:0秒和172秒!如果查看查询计划,就会很清楚为什么会这样。 由于对查询文本添加了排序,因此在执行过程中出现了排序操作。 这就是所谓的“阻塞”操作,它无法完成请求,直到它接收到要分类的全部数据。 我们无法提取已有的前45条记录,我们需要对整个数据集进行排序。
在获取数据进行排序的阶段,会出现巨大的差异。 用“ like”搜索必须浏览整个可用表。 这需要172秒。 但是全文搜索具有其自身的优化结构,该结构立即返回所有必要条目的链接。
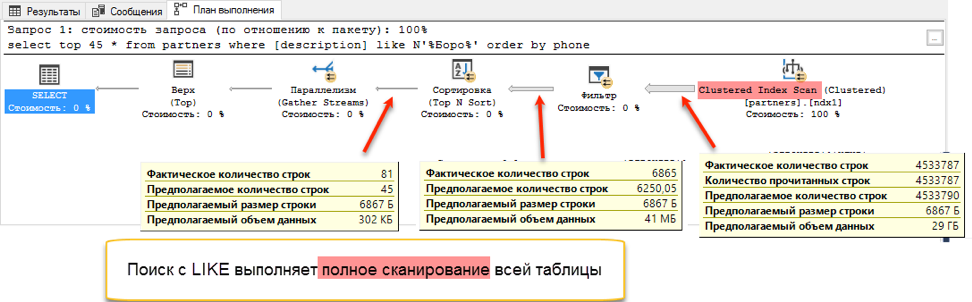
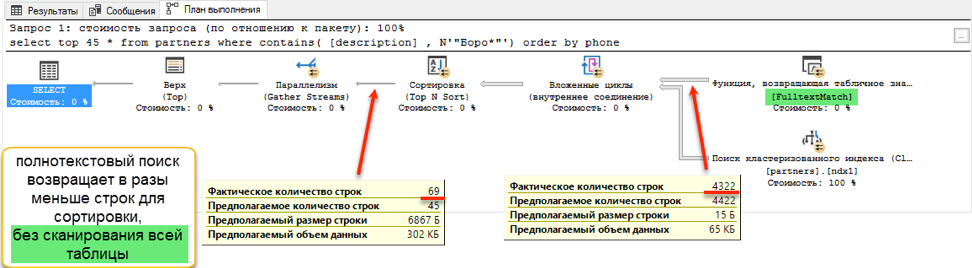
但是药膏中应该有蝇吗? 有一个。 如开头所述,全文搜索只能从单词的开头开始搜索。 如果要通过子字符串“ * Oak *”找到“ Ivan Poddubny”,则全文搜索将不会显示任何有用的内容。
幸运的是,按名称搜索不是最流行的情况。
按编号搜索文件
让我们尝试一些更复杂的事情。 搜索的第二个流行用例是按文档编号的一部分查找文档。 此外,文档编号通常由两部分组成:字母前缀和包含前导零的实际编号。
这些部分之间没有空格或服务字符。 同时,按整数进行搜索非常不便-您必须记住在前缀之后应在有效部分的开头之前有多少个前导零。 事实证明,在这种情况下,“开箱即用”的全文搜索根本没有用。 让我们尝试修复它。
为了进行测试,我创建了一个名为document的新表,在其中添加了1350万条具有“ ORG”类型唯一编号的记录。 编号按顺序进行,所有编号均以“ ORG”开头。 可以开始了。
预分割号码
全文搜索可以有效地搜索单词。 好吧,让我们帮助他,提前将“不舒服”的数字分解为方便的词。 行动计划如下:
- 在源表中添加一列,其中将存储经过特殊转换的数字
- 添加一个触发器,该触发器在更改数字时会将其分为几个小部分,并用空格隔开
- 全文搜索已经知道如何将字符串按空格分割成几部分,这样它将毫无问题地索引我们的修改后的数字
让我们看看这将如何工作。
在表中添加其他列。
alter table document add number_parts nvarchar(128) not null default ''
可以将填充新列的触发器写为“前额”,而忽略可能的重复项(数字“0000012”中有多少个重复的三元组?),并且您可以添加一些XML魔术并仅记录唯一的部分。 第一个实现将更快,第二个实现将提供更紧凑的结果。 实际上,选择是在写入速度和读取速度之间,选择哪种情况更重要。 现在,只需处理一个处理现有数字的
脚本即可 。
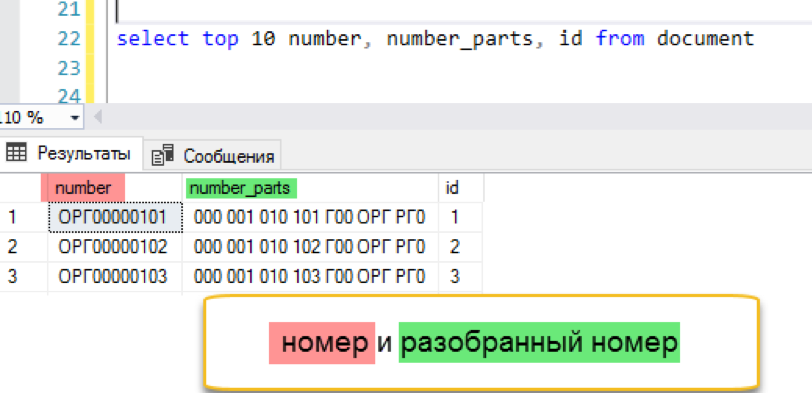
添加全文索引
create fulltext index on document (number_parts) key index ndx1 with change_tracking = Auto
并检查结果。 实验是相同的-为文档列表中的“窗口”选择建模。 我们不会重复前面的错误,而是立即对请求进行排序(在这种情况下按日期排序)。
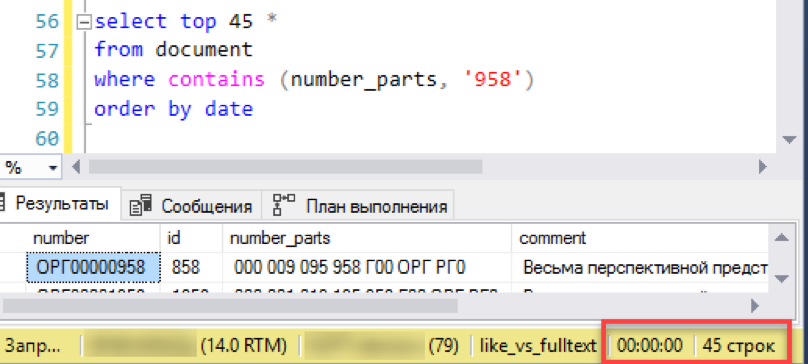
有效! 现在让我们尝试一个更真实的数字:
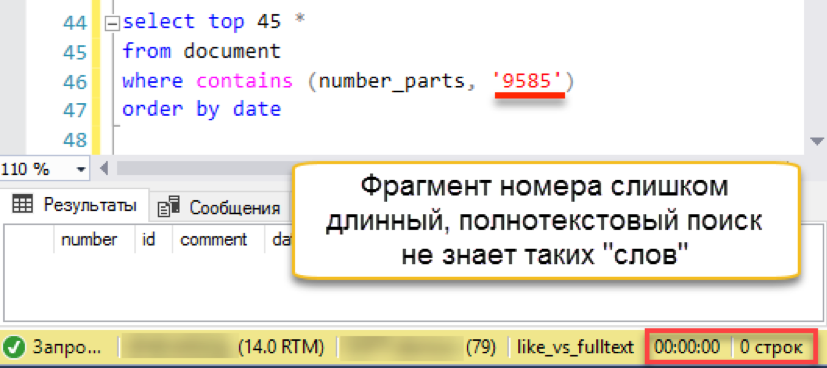
然后失火发生。 搜索字符串的长度比存储的“单词”的长度长。 实际上,搜索数据库根本没有一行包含4个字符的行,因此它实际上返回了一个空结果。 我们必须将搜索字符串分成多个部分:
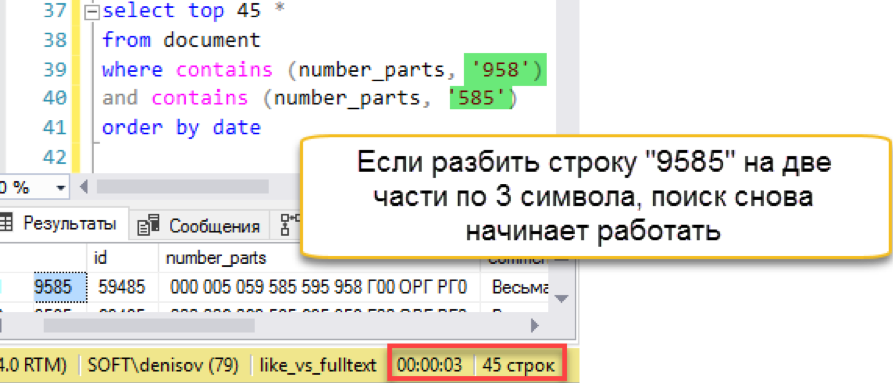
另一件事! 我们再次进行了快速搜索。 是的,他将维护费用强加于人,但结果比经典搜索快数百倍。 我们记下了尝试的次数,但是尝试以某种方式简化维护-在下一部分中。
我们将以自己的方式将其分解为文字!
实际上,谁说单词之间应该用空格隔开? 也许我希望单词之间为零! (以及(如果可能的话)前缀,以便以某种方式也忽略它,并且不会干扰脚下)。 通常,这没有什么不可能的。 让我们从文章开头回顾全文搜索操作方案-一个单独的组件wordbreaker负责分解为单词,幸运的是,Microsoft允许您实现自己的“ word breaker”。
从这里开始有趣。 Wordbreaker是连接到全文本搜索引擎的单独的dll。
官方文档说,制作这个库非常简单-只需实现IWordBreaker接口即可。 以下是C ++中的一些简短的初始化清单。 非常成功,我刚刚找到了合适的教程!

(
来源 )
严重的是,在Internet上创建自己的破坏者的文档非常少。 更少的示例和模板。 但是我仍然找到
一个用C ++编写的好人的
项目 ,该实现的实现不是通过分隔符而是通过三元组来分解单词(是的,就像上一节一样!)而且,项目文件夹已经包含一个经过仔细编译的二进制文件,您只需要用它即可连接到搜索引擎。
只是插入...其实不是很容易。 让我们完成以下步骤:
您需要使用SQL Server将库复制到文件夹:

在全文搜索中注册新的“语言”
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\CLSID\{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'Locale', 'REG_DWORD', 1 exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}' exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWARE\Microsoft\MSSQLSERVER\MSSearch\Language\ngram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}' exec sp_fulltext_service 'verify_signature' , 0; exec sp_fulltext_service 'update_languages'; exec sp_fulltext_service 'restart_all_fdhosts'; exec sp_help_fulltext_system_components 'wordbreaker';
手动编辑注册表中的几个键(作者将使该过程自动化,但是自2016年以来没有任何消息。但是,这原是一个“实现示例”,为此)
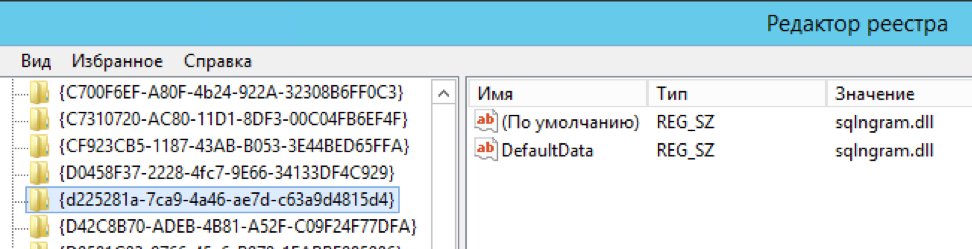
在项目页面上详细描述了这些步骤。
做完了 让我们删除旧的全文索引,因为一个表不能有两个全文索引。 创建一个新文件并索引我们的文件编号。 作为键列,我们指示数字本身,不再需要替代的预破损列。 确保使用新安装的断字程序指定“语言编号1”。
drop fulltext index on document go create fulltext index on document (number Language 1) key index ndx1 with change_tracking = Auto
检查吗
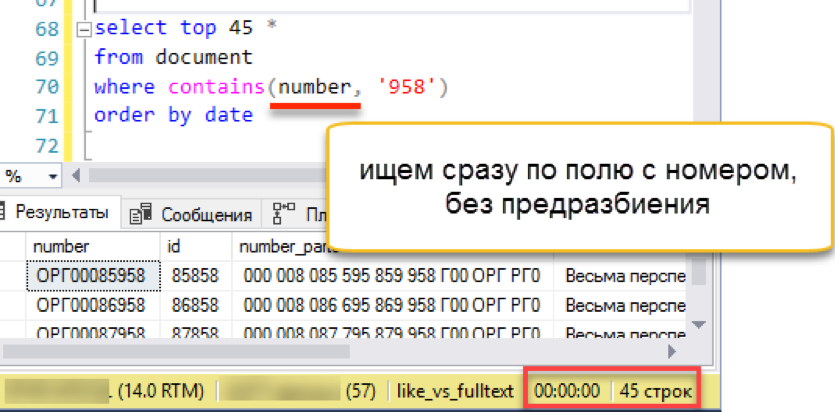
有效! 它的工作速度与上述所有示例一样快。
让我们检查一下上一个选项偶然碰到的长行:
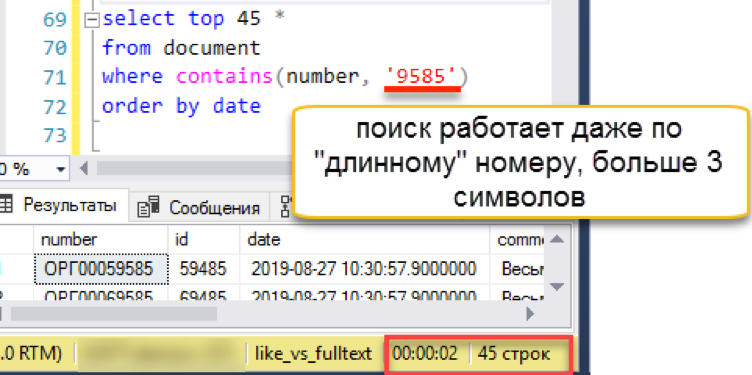
搜索对用户和程序员透明地工作。 分词系统将搜索字符串独立地分成多个部分,并找到所需的结果。
事实证明,现在我们不需要其他的列和触发器,也就是说,该解决方案比以前的尝试更简单(阅读:更可靠)。 好吧,就支持而言,这样的实现更简单,更透明,出错的机会更少。
那么,停下来,我说“更可靠”吗? 我们只是将一些第三方库连接到我们的DBMS! 如果她跌倒会怎样? 甚至会无意中拖出整个数据库服务!
在这里,您需要记住,在本文开头提到的全文搜索服务是如何与主要DBMS流程分开的。 从这里可以清楚看出为什么这很重要。 该库连接到全文索引服务,该服务可以以减少的权限运行。 而且,更重要的是,如果第三方组件下降,则只有索引服务下降。 搜索将停止一会儿(但它已经是异步的),并且数据库引擎将继续工作,好像什么都没发生。
总结一下。 添加自己的分词系统可能是一个很大的挑战。 但是,在“长期”玩耍时,这些努力会带来更大的灵活性和易于维护的回报。 像往常一样,选择是您的。
为什么这一切都是必要的?
一个好奇的读者可能不止一次想知道:“这一切都很棒,但是如果我无法在应用程序中更改搜索查询,该如何使用这些功能?” 合理的问题。 包含全文MS SQL搜索需要更改查询的语法,而这在现有体系结构中通常是不可能的。
您可以尝试通过“滑动”同名的表值函数而不是常规表来欺骗应用程序,该函数已经按照我们想要的方式执行了搜索。 您可以尝试将搜索绑定为一种外部数据源。 还有另一种解决方案-软点数据群集-一种特殊服务,该服务在源应用程序和SQL Server服务之间安装“转发”,侦听流量并可以根据特殊规则“即时”更改请求。 使用这些规则,我们可以使用LIKE查找常规查询,并通过全文搜索将其转换为CONTAINS。
为什么会有这样的困难? 尽管如此,搜索速度还是很吸引人的。 在操作员经常在数百万张表中查找记录的重载系统中,响应速度至关重要。 节省最频繁操作的时间会导致处理许多额外的应用程序,这是一笔不折不扣的金钱,任何企业都对此感到满意。 最后,几天甚至几周的时间来研究和实施该技术将为操作员提高效率带来回报。
文章中提到的所有脚本都可以在
github.com/frrrost/mssql_fulltext存储库中找到
关于作者
 Alexander Denisov
Alexander Denisov -MS SQL Server数据库性能分析师。 在过去的6年中,作为Softpoint团队的一员,我一直在帮助发现其他人的请求中的瓶颈,并从客户的数据库中获取最大的收益。