ICD IT局集成项目支持部主管Mikhail Konovalov美好的一天,Khabrovites!
目的
一种管理下载的系统方法。 我们想告诉我们如何简化和自动化信息的填充,同时又不要混淆来自各种来源的信息流。
前言
迟早,任何一家公司的公司数据库中都会出现一个瞬间,当它的规模扩大到架构师的视线不再引起系统不确定性(混乱),并变成各种来源的各种下载的不可控制的数量时。
如果您的系统是从头开始开发的(从第一个表开始),并且是由一个架构师,一个开发人员和分析师团队运行的,那么您会很幸运。 此外,这位架构师还胜任了数据仓库模型的领导。 但是生活是多方面的,在大多数情况下DWH会自然增长,首先有30张桌子,然后我们根据需要添加了一些桌子,然后我们喜欢它,并开始为每一个机会添加,现在我们有五千多张,是的层,阶段和展示仍然出现。 所有这些“幸福”都归功于一个但非常方便的过程,这是一个艰难的因果关系:
- 该企业表示:“我们需要此类数据。 需要新报告»
- 分析师正在寻找
- 开发人员工具
- 架构师协调并贡献于数据模型
但是,通常而言,现实中的最后一点并不存在。 它仅在成长为DWH的大型公司中的某个时刻出现,在那里,一个精巧的架构师可以胜任地管理数据库中信息的完整性。 此类存储库是对先前结构的回顾,该结构已被重新记录并经常重新构建,着眼于先前(未记录)的版本。
因此,简要总结如下:- 没有立即诞生的DWH,并且以前不代表具有一组表的常规数据库;
- 由于以前的开发中的“苦涩经验”,所以获得了现在存在的所有内容,并且是经过明确算法化和记录的结构。
如果您是“正确的” DWH的快乐所有者,或者如果您是该快乐所有者的团队的成员,那么“理论上”的这篇文章可能对您来说很有趣。 而且,如果您只需要进行审查或(禁止)重建,那么本文可以极大地简化您的生活。
由于可能存在难以想象的信息源数量,因此至少存在相同数量的不同对象的下载和过载流,并且经常要更多,因为每个数据库对象在最终用户可以使用其数据来构建之前,都必须经过一个以上的转换。业务报告。 但这对他来说,对他的生意而言,而不是对他自己的乐趣,整个生态系统都是为“从一个船到另一个船的输血”而建立的。
Oracle被用作我们存储的数据库。 曾经,在创建阶段,我们数据库的中央核心由几百个表组成。 我们没有考虑过分期和商店橱窗。 但是,正如他们所说,“万事万物,万事万物都在变化”,现在我们已经成长了! 该业务提出了新的要求,并且已经出现了与各种MS SQL,SyBASE,Vertica,Access数据库的集成。 从那里信息不会流向我们,甚至出现了与第三方系统进行XML和JSON交换等异国情调,而且XLS文件作为信息源是完全不合时宜的。
生活使我们经历了审查并更新,维护和维护数据模型。 这是主要核心部分之一:
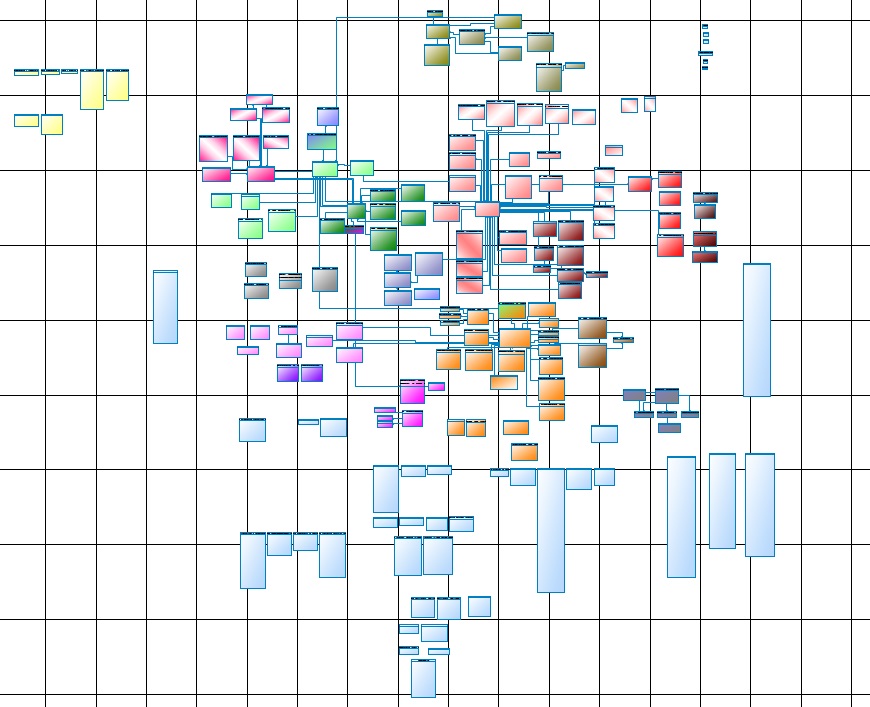 图 1个
图 1个它是给谁的,但对我来说-它只能在Whatman纸上阅读,并且A0会比4A0小一点,在屏幕上看不到或无法想象。
现在回想一下,这只是核心(核心数据层),或者更确切地说是其主要部分,完整核心由几个子系统组成,这些子系统与主要子系统相差无几。
主数据层和
数据集市层也添加到此。 此外,更多的是,主层从数据源接收其信息,如上所述,该信息来自各种数据库和文件。 另一方面,消费者将各种报告系统连接到商店橱窗层。
最初,当用PL / SQL实现的数据库表和加载算法很少时,在理解数据更新方面没有特别的困难。 但是随着DWH的兴起,一项战略决策是购买Informatica PowerCenter。 借助此工具的所有便利,无论是在加载的可靠性还是在开发的可视化方面,该工具都有一些缺点。 下图显示了用于加载DWH的启动顺序的模型。
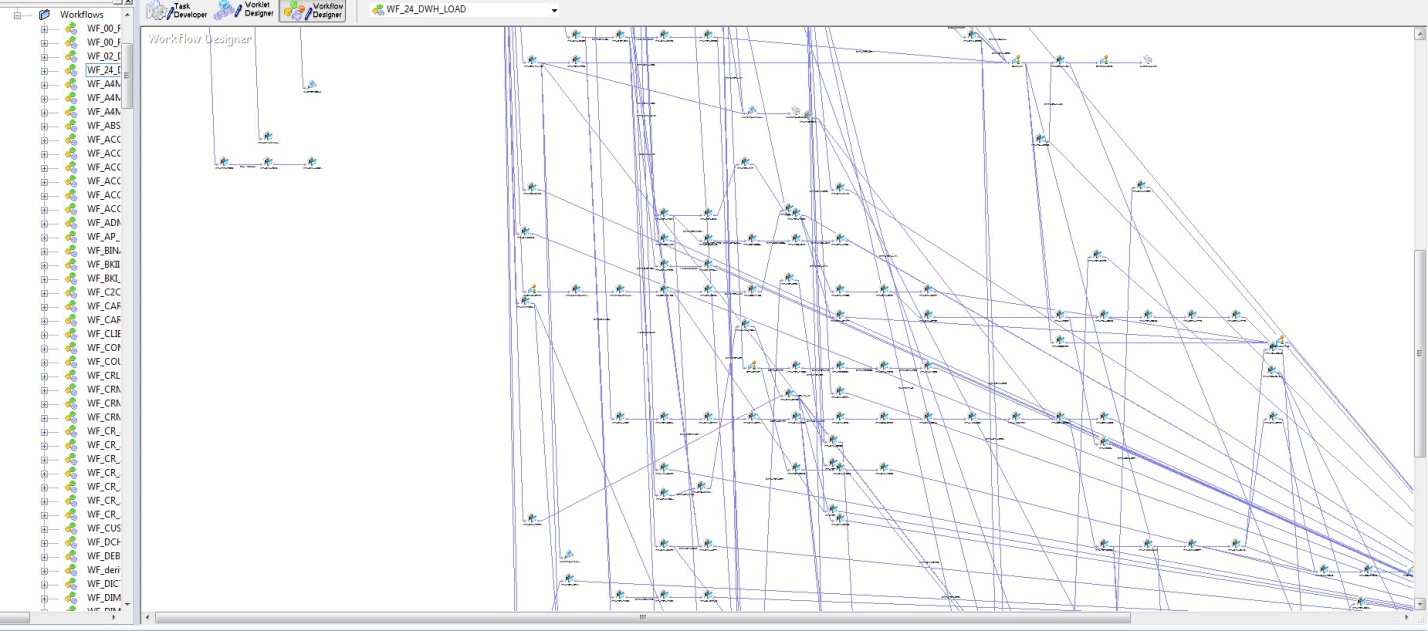 图 2
图 2最重要的缺点是主观性,或者说,只有架构师才能保证不会在帐单之前加载过帐。 不幸的是,随着DWH的增长,信息的熵也会增加。 考虑到物理数据模型(图1)和加载此数据的逻辑(图2),仍然可以得到构造。
您会问,怎么做以及如何操纵它。 自然地:拥有一个能理解这些错综复杂的所有关系的杰出建筑师。 它将监视所有流程,协调新流程,并防止过帐表早于帐户表加载。 当然,所有这些都被缝合到算法中,并由下载的截止时间来调节,但是最初,只有架构师才能理解和设置下载的严格顺序,并且通过这种分支,出错的可能性非常高。
理论
现在,我将尝试陈述数据模型字典的主要思想及其解决的任务。
由于存储中的数据在表中,并且数据源部分是表,部分是视图,因此后者本身就是表。 然后是一个简单的想法-创建一个
TABLE – TABLE依赖结构。
3NF形式非常适合此。
首先,填充DWH实体数据,在最一般的情况下,我们将其称为
(目标) ,可以表示为来自不同表的
select 。 不管是Oracle表,SyBase,MSSQL,xls文件还是其他东西,它都没有那么重要,所有这些我们称为它们的源
(source) 。 也就是说,我们有一个流入
target的
源 。
其次,每个DWH实体相互引用。
第三,开始下载各种DWH实体的时间表。
小型实施仍然是这样-如何? 从您的DWH的基础看来,架构师看起来非常简单,当实体
(目标)的下一个表格出现时,建筑师必须查看接收者实体和所有用作源的实体并将其放入字典中。 此外,在字典的第二个表中,指定select中这些实体源以及引用所引用的所有从属表之间的链接。 接下来,您可以将此实体的负载嵌入到存储下载链中。 仅解决了两个表-解决了在算法中考虑使用算法填充数据的顺序的可能性。
字典数据模型将解决以下问题:
- 查看依赖关系。 您可以查看从何处提取了哪些数据。 这对于总是被问题折磨的分析师很方便:“问题在哪里,谎言在哪里,一切从何而来”。 以树的形式在源代码中将其呈现在应用程序中,从源到目标 ,反之亦然:从目标到源 。
- 循环破裂。 在将下一个负载嵌入到已经工作的共享流中而没有数据模型字典的情况下,很可能会犯一个错误,并为在其源之一的前面加载下一个目标分配开始时间。 这将创建一个循环。 数据模型字典很容易避免这种情况。
- 您可以根据模型字典编写用于填充存储的算法。 在这种情况下,无需将下一个下载内容嵌入任何位置,只需将其反映在字典中即可,算法将确定其位置。 仍然可以单击令人垂涎的“全部制作”按钮。 引导加载程序将启动所有存储实体的雪崩式下载-从简单(独立)到复杂(独立)。
实作
从理论上讲,一切总是简单而美丽;在实践中,情况有所不同。 在上一节中所写的内容是当DWH从零开始开发时的理想情况,而架构师则与之分离。 如果您不走运,那么您已经安全地通过了所有这些工作,没有架构师,但是有一组庞大的表,那么总有一条出路。
现在,实际上,我将告诉您我们如何设法赶上并进行审核和重建,使其价格便宜。 我们的DWH通过有关即将发生的需求(DWH)的领导决策而开始发展。 作为一种工具,首先使用PL / SQL。 不久后切换到Informatica。 自然,首要的是创造的时机。 一段时间之后,PowerDesigner中的数据模型出现了,那时人们已经清晰地建立起人们无法清楚地想象出DWH完整而清晰的画面的信心。 我们在模型上呆了一段时间,当很明显我们无法应对整个系统的管理时,我们开始寻找一种解决方案,在此我将简要介绍一下。
数据模型字典本身就像棍子一样简单。 但是填充它是一个问题。 N个月的艰苦工作,最重要的是,仔细考虑以上三个部分:
- 存储库(目标)的每个实体由什么来源(来源)组成;
- 存储对象(引用)之间的关系是什么?
- 开始下载和填充存储库的时间顺序。
幸运的是,Oracle和Informatica帮助了我们,事实证明Informatica存储库位于Oracle数据库中非常成功。 以一个Informatica会话为DWH实体的加载原子为基础,在存储库中进行了挖掘,我们找到了所有源和目标。 也就是说,在一个会话的框架内,对于其所有目标(通常是一个目标),其所有来源都是来源。 因此,我们可以填写问题的第一个条件。 但是不要着急,源代码可以以非常聪明的select形式呈现,因此您必须编写一个解析器,提取出select中指定的所有表-这一点都不困难。 但这还不是全部,这些表本身实际上可以是表示形式。 使用DBA_VIEWS(或通过DBA_DEPENDENCIES)也解决了此问题。 我们从数据模型(图1)和DBA_CONSTRAINTS中提取了此三部曲的第二个条件。 我们还基于(图2)从Informatica存储库中获得了第三个条件。
这是怎么回事?- 首先,我们理清了DWH演进过程中我们绕过的所有循环。
- 其次,我们为分析师提供了一棵奇妙的树:

图 3 - 第三,我们的超载器,如图2所示。 2变得优雅(对不起,同事,但是图片的模糊是故意的,因为这是工作数据):
图 4
您可能有更多的方法来应用数据模型字典。
谢谢大家!