
这篇文章是针对关键字识别的全面研究的一个小摘要。 语义抽取技术最初被应用于社交媒体的抑郁模式研究领域。 在这里,我专注于没有心理学解释的自然语言处理和数学方面。 显然,单字频率的分析是不够的。 集合的多次随机混合不会影响相对频率,但会完全破坏信息-单词袋效应。 我们需要更准确的方法来挖掘语义吸引子。
根据关系框架理论(RFT),实体的双向链接是基本的认知元素。 bigram词典的假设已得到检验。 我们探索了讲俄语的顶级帮助墙。 每天150,000次访问。 响应/请求收集已解析:2018年有25,000条记录。
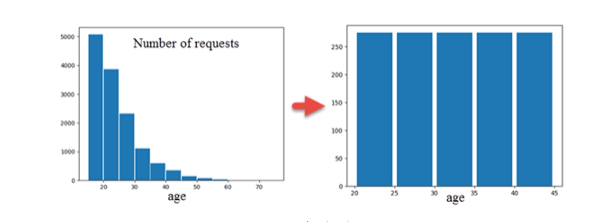
文本清理包括年龄/性别/文本和消息长度标准化。 通过[姓名-性别]认可达到性别标准化。 形态清洗和标记化允许以标准形式获得名词。 挖掘具有相应频率的二元词的词汇。 Bigram集按频率排序,并根据截止标准在两组中归一化为相等的体积。 每个组,请求/响应都具有唯一的双字母组矩阵。 显示出与香农熵成反比的信息增加:增量的30%。 3克I(3)-I(2)= 6%,[H(4)-H(3)] = 2%且N> 4小于1%。
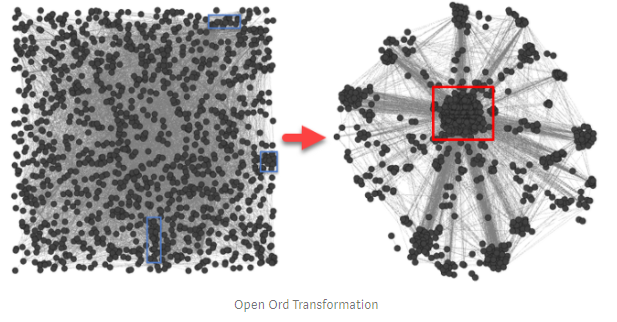
Bigram矩阵用作加权无向3D图的生成器。 转换是通过Open Ord力导向布局算法实现的。 它可以将2D矩阵转换为基于树的拓扑。 每个节点的权重对应于单个单词的频率(未显示),而边长则是双字频率的反函数。 我考虑了居中性(BC)并修改了最近的邻居。 具有超高BC的实体可以被视为信息中心,这会影响语义:移除这些实体主要会影响信息 。 最近邻居基于同现频率分析。 我考虑了修改后的邻居排序。 与共现距离(CD)成反比的邻居的BC用作加权函数:BC / CD。

我们检查了所选卑诗根附近的最近邻居:#Life。 #Man(No.1)的价值几乎与#Life吸引子融合在一起。 #Procreation(排名2),#Family(排名3)是BC / CD等级较低的下一个最接近实体。 响应值按以下顺序表示:#Man No.1,#Job No.2,#Procreation No.3。 应该注意的是,在回答组中显然存在话题偏见。 然而,尽管话题有些杂乱无章,但个人和团体价值观的分离(#Man Vice #Life)还是很明显的。 Graph基于10,000个最常见的二元组:44%的数据。 但是,按BC / CD排序的前5个实体在重新缩放为双链词典的50%和88%之后不会改变。
考虑的结果与心理学中的经验观察相关。 因此,他们初步确定了选择的BC / CD测距算法以识别语义吸引子。 如果您处理大噪音文本/语音数据,将非常方便。 它可以用于挖掘与所选实体相关的关键字或绝对术语。 您可以在这里阅读更多内容。 该仪器也可以在人力资源评估中应用。 作者在英语部分进行相关研究并寻求合作。 完整的研究版本尚待同行评审期刊上发表。 但是,您可以应个人要求索取汇票。 谢谢你
我感谢Dmitry Vodyanov的富有成果的讨论。