pprof是Go中的主要配置工具。 探查器包含在Go标准库中,多年来,已经对此进行了很多撰写。 要将pprof连接到现有应用程序,您只需要添加一行代码:
import _ “net/http/pprof”
在默认的HTTP服务器net/http.DefaultServeMux ,发送分析结果的处理程序将沿着/debug/pprof/路径注册。
curl -o cpu-profile.pb.gz http://<server-addr>/debug/pprof/profile
(有关更多详细信息,请参见https://godoc.org/net/http/pprof )
但是从经验来看,这并不总是那么简单,在实践中在战斗中使用pprof确实存在陷阱。
首先,我们不希望探查器处理程序在Internet上突出显示。 就开销而言,概要分析很便宜,但不是免费的,概要文件本身包含有关应用程序内部结构的信息,通常不建议向外部人员开放。 您必须确保未经授权的用户无法访问/debug路径。 可以在代理服务器端限制访问,也可以将pprof服务器移到单独的端口,只有通过特权主机才能访问该端口。
但是,如果应用程序根本不涉及HTTP访问,例如,它是脱机队列处理器,该怎么办?
根据公司基础架构的状态,应用程序内部的“突然” HTTP服务器可能会引起运营部门的疑问;)该服务器还限制了水平扩展功能,因为 仅在同一主机上运行该应用程序的多个实例将不起作用-进程将冲突,尝试为pprof服务器打开相同的TCP端口。
通过隔离容器中的每个应用程序进程(或在唯一端口或UNIX套接字上运行pprof服务器)来解决问题是“简单的”。 将服务水平扩展到数百个实例并“分布”在多个数据中心的服务,您再也不会感到惊讶。 在非常动态的基础架构中,带有应用程序的容器可以定期出现和消失。 而且我们仍然需要以某种方式与分析器联系。 这意味着无论选择哪种缩放方法,都需要针对特定应用程序实例和相应的pprof服务器端口的搜索机制。
根据公司的特征,是否存在访问与服务的主要生产活动无关的内容的能力可能会引起安全部门的疑问;)我在一家公司工作,出于客观原因,可以访问任何东西生产完全在运营部门进行。 在正在运行的应用程序上运行事件探查器的唯一方法是在操作错误跟踪器中打开一个任务,其中描述了哪个curl命令,在哪个DC中,要在哪个服务器上运行,期望得到的结果以及如何对其进行处理。
或想象一个情况:一个工作的早晨。 您打开了Slack,发现在晚上某个生产服务流程中“出问题了”,“某处发生了什么事”,“关闭”,“内存开始流动”,“ CPU图形爬升”或该应用程序刚刚开始出现紧急情况。 值班操作团队(或OOM Killer)没有深入研究,只是重新启动了应用程序或回滚了前一天的最新版本。
事实上,要了解这种情况并不容易。 如果可以在测试环境中(或您可以访问的产品的孤立部分)重现问题,那就太好了。 您可以使用手边的所有工具收集必要的数据,然后找出问题所在的组件。
但是,如果没有明显的方法可以重现该问题,那么我们是否只剩下昨天的日志和指标了? 在这种情况下,总是不能回溯到生产中出现问题的那一刻,并迅速收集所有必要的配置文件,以便以后以安静的方式进行分析,这总是令人遗憾的。
但是,如果pprof相对便宜,为什么不每隔一段时间就自动收集概要分析数据,并将其存储在与生产环境不同的位置,您可以在其中访问所有感兴趣的人?
Google在2010年发布了《 Google概要分析:数据中心的连续概要分析基础结构》文档,其中介绍了对公司系统进行连续概要分析的方法。 几年后,该公司推出了一项持续的配置服务-Stackdriver Profiler-每个人都可以使用。
操作原理很简单:与应用程序连接的是堆栈驱动程序代理,而不是pprof服务器,该驱动程序直接使用runtime/pprof API,定期从应用程序收集不同类型的配置文件并将配置文件发送到云。 开发人员需要的所有内容,都可以使用Stackdriver控制面板在所需的可用区中选择所需的应用程序实例,之后,您就可以在过去的任何时间分析该应用程序。
其他SaaS提供程序也提供类似的功能。 但是,您公司的安全规则可能会禁止将数据导出到自己的基础架构之外。 我还没有看到可以在您自己的服务器上部署连续配置系统的服务。
上面描述的所有困难和想法都不只是新的,而且不仅仅针对Go。 有了它们,一种形式或另一种形式,开发人员几乎在我工作过的所有公司中都面临着。
在某个时候,我很好奇,试图为可以解决上述问题的任意Go服务构建Stackdriver Profiler的类似物。 作为一个业余爱好项目,我在业余时间从事profefe( https://github.com/profefe/profefe )-一种连续分析的开放式服务。 该项目仍处于实验和定期讨论的阶段,但已经适合进行测试。
我为项目设置的任务:
- 该服务将部署在公司的内部基础架构上。
- 该服务将用作公司的内部工具。 您可以信任数据的供应商和消费者:在早期阶段,您可以省略对写入/读取请求的授权,而不必事先保护自己免受恶意使用。
- 该服务对公司的基础架构不应有任何特殊的期望:一切都可以存在于云中或位于其自己的DC中; 概要分析的应用程序可以在容器内运行(“一切都由Kubernetes控制”),也可以在裸机上运行。
- 该服务应该易于操作(在一定程度上,Prometheus就是一个很好的例子)。
- 应当理解,所选架构可能不满足将使用服务的条件。 最有可能的是,您将需要具有扩展/替换系统组件以“现场”扩展的能力。
- 根据(4),我们必须尝试最小化所需的外部依赖性。 例如,服务必须以某种方式寻找配置文件应用程序的实例,但是至少在初始阶段,我想在没有显式服务发现的情况下进行操作。
- 该服务将存储和分类Go应用程序的配置文件。 我们期望一个pprof文件占用100KB-2MB( 堆配置文件通常比CPU配置文件大得多 )。 从一个已配置的实例中,每分钟发送N个以上的配置文件是没有意义的(一个Stackdriver代理平均每分钟发送2个配置文件)。 值得立即计算出,单个应用程序可以具有数百到数百个实例。
- 通过该服务,用户将在一段时间内搜索应用程序或应用程序的特定实例的不同类型的配置文件(cpu,堆,互斥锁等)。
- 用户将通过该服务从搜索结果中请求一个单独的pprof配置文件。
现在,利润由两个部分组成:
profefe-collector是具有简单RESTful API的服务收集器。
收集器的任务是获取pprof文件和一些元数据,并将其保存在永久存储中。 该API还允许客户在特定时间窗口内通过元数据搜索配置文件,或从商店中读取特定的配置文件(或一组相同类型的配置文件)。
agent-一个可选的库,应该连接到应用程序而不是pprof服务器。 在应用程序内部,代理在单独的goroutine中定期启动分析过程(使用runtime/pprof ),并将接收到的pprof配置文件以及元数据发送到收集器。
元数据是描述应用程序或其单个实例的任意键值集。 例如:运行应用程序的服务名称,版本,数据中心和主机。

Profefe组件交互图
我在上面提到代理是可选组件。 如果无法将其连接到现有应用程序,但是该应用程序中已经连接了net/http/pprof服务器,则可以使用任何外部工具删除配置文件,并通过HTTP API将pprof文件发送到收集器。
例如,在主机上,您可以配置cron任务,该任务将定期从正在运行的实例中收集配置文件并将其发送到profefe进行存储;)
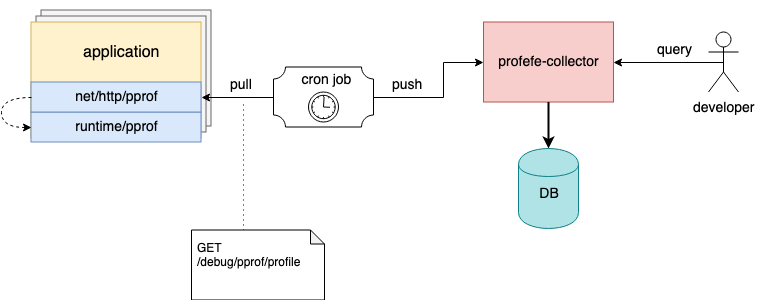
Cron任务收集应用程序配置文件并将其发送到专业收集器
您可以在GitHub的文档中阅读有关profefe API的更多信息。
计划
到目前为止,与profefe收集器进行交互的唯一方法是HTTP API。 未来的任务之一是组装一个单独的UI服务,通过它可以直观地显示存储的数据:搜索结果,群集性能的一般概述等。
收集和存储概要分析数据还不错,但是“没有应用程序,数据就没有用了”。 我工作的团队有一组实验工具,用于从服务中收集多个pprof配置文件的基本统计信息。 这在分析更新应用程序的关键依赖性的后果或大型重构的结果方面有很大帮助( 不幸的是,基于隔离基准测试的发布和测试环境中的性能分析,生产性能并不总是符合预期 )。 我想添加类似的功能来比较和分析profefe API中存储的配置文件。
尽管profefe的主要重点是对Go服务进行连续分析,但pprof配置文件格式与Go完全无关。 对于Java,JavaScript,Python等,有一些库可让您以这种格式获取分析数据。 可能对于使用其他语言编写的应用程序,性能可能已成为有用的服务。
除其他事项外,该存储库还有许多在GitHub上的项目跟踪器中描述的开放性问题。
结论
在过去的几年中,开发人员已经树立了一个流行的想法:要实现服务的“ 可观察性 ”,需要三个组件:度量,日志和跟踪(“ 可观察性的三个支柱 ”)。 在我看来,可见性是有效回答有关系统及其组件运行状况的问题的能力。 度量和跟踪使您可以了解整个系统。 日志涵盖了系统刻意描述的部分。 分析是获得可见性的另一个信号,它使您可以从微观角度了解系统。 在一段时间内进行连续分析还有助于了解各个组件和环境如何影响并影响整个系统的可操作性和生产率。