UPD:根据评论中的要求,我添加了指向Javascript旋转架构的链接
不幸的是,无法将javascript代码插入帖子的正文中
下午好 最近,我读了一个都市人的博客,他在讨论理想的地铁方案应该是什么样的,可以根据以下两个原则得出地铁方案:
- 该电路应方便,易于记忆和定向。
- 该方案应与城市的地理位置相对应
显然,这些原则是互斥的,第一个原则要求对地理现实的严重扭曲。
只需用漂亮的圆环和直线来回想一下莫斯科地铁计划的样子就足够了:
并与地理位置准确的计划进行比较:

该计划表明,环网根本没有完全平滑和同心,线弯曲得比方案中的弯曲程度大得多,而且市中心的车站密度很高,以致几乎无法弄清计划。
而且,尽管第二张图片可以更准确地反映现实,但很明显,使用第一张图片规划地铁中的路线会更方便。
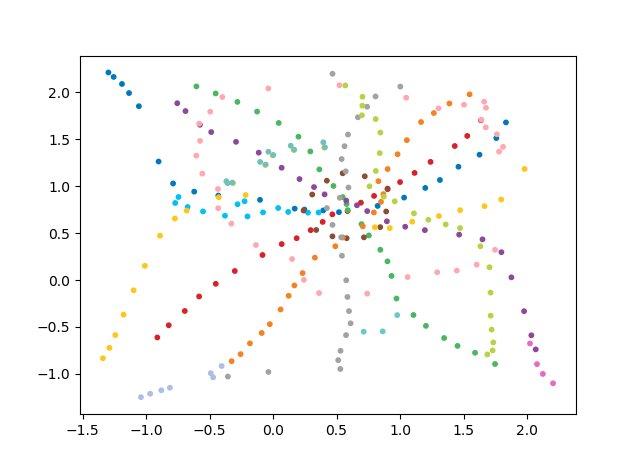
然后我想到了以下想法:“如果建造电路的标准是从一个车站到另一个车站所需的时间,那么地铁会是什么样?” 也就是说,如果您可以快速从一个站点到达另一个站点,则在空间上它们将位于图中的附近。
显然,在二维空间中,由于地铁图的复杂拓扑,不可能绘制这样一种方案,其中两个站点之间的距离等于一个站点到另一个站点的行进时间。
还有一种预感,当在高维空间中构建方案时,这是完全可能的(最高估计值为n-1,其中n是站数)。 对于具有少量尺寸的空间,只能近似构造这种方案。
通过行驶时间构造地铁地图的任务看起来像一个典型的优化任务。
假设我们拥有所有测站(X,Y,Z)的初始坐标集和成对时间(距离)的目标矩阵。 可以构造给定坐标集的“不正确”度量,然后通过梯度下降法针对每个测站的每个坐标将其最小化。 作为度量,我们可以采用距离标准偏差的简单函数。
好吧,剩下的唯一一件事就是获取有关从莫斯科地铁的任何车站到任何其他车站旅行应该花费多少时间的数据。
首先想到的是检查Yandex Metro API并从那里获取这些数据。 不幸的是,找不到api描述。 长时间观察应用程序中的时间(地铁中有268个站,时间矩阵的大小为268 * 268 = 71824)。 因此,我决定了解Yandex Metro的源数据。 由于无法访问服务器,因此下载了带有该应用程序的apk文件,并找到了必要的数据。 有关Metro的所有信息均以JSON格式显着构造并存储在应用程序资产/ metrokit / apk存档文件夹中。 所有数据都存储在不言自明的结构中。 Meta.json包含有关应用程序中存在其方案的城市的信息,以及这些方案的ID。
{ "id": "sc77792237", "name": { "en": "Nizhny Novgorod", "ru": " ", "tr": "Nizhny Novgorod", "uk": "і " }, "size": { "packed": 30300, "unpacked": 145408 }, "tags": [ "published" ], "aliases": [ "nizhny-novgorod" ], "logoUrl": "https://avatars.mds.yandex.net/get-bunker/135516/f2f0e33d8def90c56c189cfb57a8e6403b5a441c/orig", "version": "2c27fe1", "geoRegion": { "delta": { "lat": 0.168291, "lon": 0.219727 }, "center": { "lat": 56.326635, "lon": 43.992153 } }, "countryCode": "RU", "defaultAlias": "nizhny-novgorod" }
通过该方案的ID,我们找到带有与Moscow相关的JSON的文件夹。
data.json文件包含有关都市图的基本信息,包括该图的节点名称,节点ID,节点的地理坐标,有关从一个站点到另一个站点的转换的信息(id,转换时间,转换类型-不论是开车还是步行,是否在大街上,时间)我们对秒数感兴趣),还提供了大量有关车站出入口的信息。 这很容易弄清楚。 让我们开始编写代码以构建电路。
我们导入必要的库:
import numpy as np import json import codecs import networkx as nx import matplotlib.pyplot as plt import pandas as pd import itertools import keras import keras.backend as K from mpl_toolkits.mplot3d import Axes3D from mpl_toolkits.mplot3d.proj3d import proj_transform from matplotlib.text import Annotation import pickle
python词典和列表的结构与json格式的结构完全一致,因此我们读取Metro信息并创建与json对象相对应的对象。
names = json.loads(codecs.open( "l10n.json", "r", "utf_8_sig" ).read() ) graph = json.loads(codecs.open( "data.json", "r", "utf_8_sig" ).read() )
我们创建了一个字典,用于映射图和站点的节点(这是必需的,因为站点是分配给名称的,而不是图的节点)
另外,以防万一,我们将保存节点的坐标,以便构建地理地图(归一化为0-1的范围)
nodeStdict={} for stop in graph['stops']['items']: nodeStdict[stop['nodeId']]=stop['stationId'] coordDict={} for node in graph['nodes']['items']: coordDict[node['id']]=(node['attributes']['geoPoint']['lon'],node['attributes']['geoPoint']['lat']) lats=[] longs=[] for value in coordDict.values(): lats.append(value[1]) longs.append(value[0]) for k,v in coordDict.items(): coordDict[k]=((v[0]-np.min(longs))/(np.max(longs)-np.min(longs)),(v[1]-np.min(lats))/(np.max(lats)-np.min(lats)))
创建具有连接的Metro图形。 我们设置每个连接的权重。 重量对应于旅行时间。 我们将删除不是车站的节点(我认为,这些是地铁的出口,Yandex卡在计算时间时需要连接它们,但并不能完全理解),创建一个节点ID字典-俄语的真实姓名
G=nx.Graph() for node in graph['nodes']['items']: G.add_node(node['id'])
我们定义每个节点属于哪个分支(哪个分支ID)(稍后需要在图中为地铁线着色)
def getlines(graph, G): nodetoline={} id_from={} id_to={} for lk in graph['tracks']['items']: id_from[lk['id']]=lk['fromNodeId'] id_to[lk['id']]=lk['toNodeId'] for line in graph['linesToTracks']['items']: if line['trackId'] in id_from.keys(): nodetoline[id_from[line['trackId']]]=line['lineId'] nodetoline[id_to[line['trackId']]]=line['lineId'] return nodetoline lines=getlines(graph,G)
networkx库允许您使用nx.shortest_path_length(G,id1,id2,weight ='length')函数找到从一个节点到另一节点的最短路径长度,因此我们可以假设我们已经完成了数据准备。 接下来要做的是准备一个模型,以优化测站的坐标。
为此,我们将弄清楚输入,输出将得到什么,以及如何优化测站坐标矩阵。
假设我们有一个所有坐标的矩阵(3x268)。 用该坐标矩阵乘以维度268的一个热点向量(一个向量,其中一个单位坐标代替n,处处都是0),将得到3个对应于测站n的坐标。 如果我们采用一对单热矢量并将它们乘以必要的矩阵,则会得到两个三重坐标。 从一对坐标中,您可以计算站点之间的欧几里得距离。 因此,我们可以确定模型的架构:
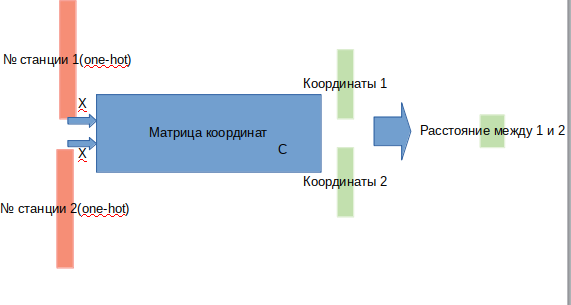
在入口处,我们给出了两个测站,在输出处,我们得到了它们之间的距离。
在确定用于训练模型的数据格式之后,我们将使用图形上的距离搜索来准备数据:
myIDs=list(G.nodes()) listofinputs1=[] listofinputs2=[] listofoutputs=[] for pair in itertools.product(G.nodes(), repeat=2): vec1=np.zeros((len(myIDs))) vec2=np.zeros((len(myIDs))) vec1[myIDs.index(pair[0])]=1 vec2[myIDs.index(pair[1])]=1 listofinputs1.append(vec1) listofinputs2.append(vec2)
我们使用梯度下降法优化站坐标矩阵。
如果我们使用keras框架进行机器学习,则会得到以下信息:
np.random.seed(0) initweightmatrix=np.zeros((len(myIDs),3)) for i in range(len(myIDs)): initweightmatrix[i,:2]=coordDict[myIDs[i]] initweightmatrix[i,2]=np.random.randn()*0.001 def euclidean_distance(vects): x, y = vects sum_square = K.sum(K.square(x - y), axis=1, keepdims=True) return K.sqrt(K.maximum(sum_square, K.epsilon())) def eucl_dist_output_shape(shapes): shape1, shape2 = shapes return (shape1[0], 1) inp1=keras.layers.Input((len(myIDs),)) inp2=keras.layers.Input((len(myIDs),)) layer1=keras.layers.Dense(3,use_bias=None, activation=None) x1=layer1(inp1) x2=layer1(inp2) x=keras.layers.Lambda(euclidean_distance, output_shape=eucl_dist_output_shape)([x1, x2]) out=keras.layers.Dense(1,use_bias=None,activation=None)(x) model=keras.Model(inputs=[inp1,inp2],outputs=out) model.layers[2].set_weights([initweightmatrix]) model.layers[2].trainable=False model.compile(optimizer=keras.optimizers.Adam(lr=0.01), loss='mse')
请注意,我们使用真实的地理坐标作为第1层中的初始坐标-这是必要的,以便不落入标准偏差函数的局部最小值。 我们将第三个坐标初始化为一个非零的坐标以获得一个非零的梯度(如果在开始时地图是绝对平坦的,则任何桩号的上移或下移将是相同的,因此梯度为0并且z不会被优化)。 模型的最后一个元素(密集(1))会影响方案的缩放以适应时间轴。
我们将以小时而不是秒为单位来测量距离,因为距离的数量级大约为1小时,并且为了更有效地训练模型,重要的是所有值(输入数据,权重,目标)都应近似相同的数量级。 如果这些值接近1,则可以使用标准步长值进行优化(0.001-0.01)。
线model.layers [2] .trainable = False冻结站点的坐标,并且在第一阶段更改一个参数-比例。 选择方案的比例尺后,我们将解冻坐标并对其进行优化:
hist=model.fit([listofinputs1,listofinputs2],listofoutputs,batch_size=71824,epochs=200) model.layers[2].trainable=True model.layers[-1].trainable=False model.compile(optimizer=keras.optimizers.Adam(lr=0.01), loss='mse') hist2=model.fit([listofinputs1,listofinputs2],listofoutputs,batch_size=71824,epochs=200)
我们看到,我们一次向所有对站进料,在所有距离的出口处进给,而我们的优化是全批次梯度下降(对所有数据执行一步操作)。 在这种情况下,损失函数为标准偏差,您可以看到在训练结束时它为0.015,这意味着任何一对站的标准偏差都小于1分钟。 换句话说,通过生成的方案,您可以准确地知道从一个站点到另一个站点所需的距离,即两个站点之间的直线距离为+ -1分钟!
但是,让我们看看我们的电路是什么样的!
获取测站的坐标,对线进行颜色编码,并构建带有签名的3d图像(用于显示签名的漂亮代码
来自此处 ):
class Annotation3D(Annotation): '''Annotate the point xyz with text s''' def __init__(self, s, xyz, *args, **kwargs): Annotation.__init__(self,s, xy=(0,0), *args, **kwargs) self._verts3d = xyz def draw(self, renderer): xs3d, ys3d, zs3d = self._verts3d xs, ys, zs = proj_transform(xs3d, ys3d, zs3d, renderer.M) self.xy=(xs,ys) Annotation.draw(self, renderer) def annotate3D(ax, s, *args, **kwargs): '''add anotation text s to to Axes3d ax''' tag = Annotation3D(s, *args, **kwargs) ax.add_artist(tag) fincoords=model.layers[2].get_weights() ccode={} for obj in graph['services']['items']: ccode[obj['id']]=('\#'+obj['attributes']['color'])[1:] xn = fincoords[0][:,0] yn = fincoords[0][:,1] zn = fincoords[0][:,2] l=[labels[idi] for idi in myIDs] colors=[ccode[lines[idi]] for idi in myIDs] xyzn = zip(xn, yn, zn) fig = plt.figure() ax = fig.gca(projection='3d') ax.scatter(xn,yn,zn, c=colors, marker='o') for j, xyz_ in enumerate(xyzn): annotate3D(ax, s=labels[myIDs[j]], xyz=xyz_, fontsize=9, xytext=(-3,3), textcoords='offset points', ha='right',va='bottom') plt.show()
由于将浏览器转换为交互式3d格式存在困难,因此我发布了gif文件:
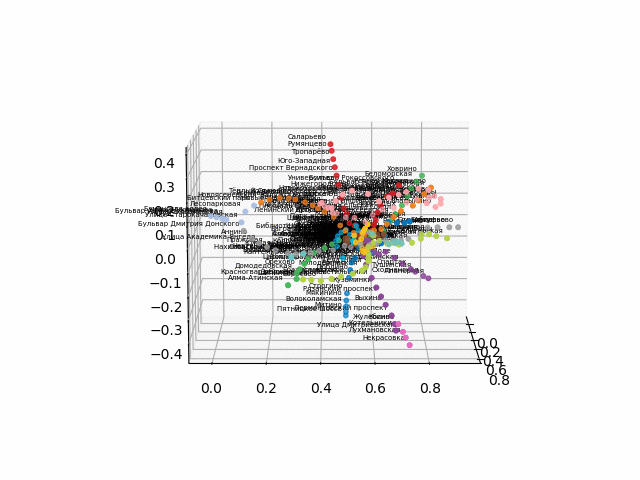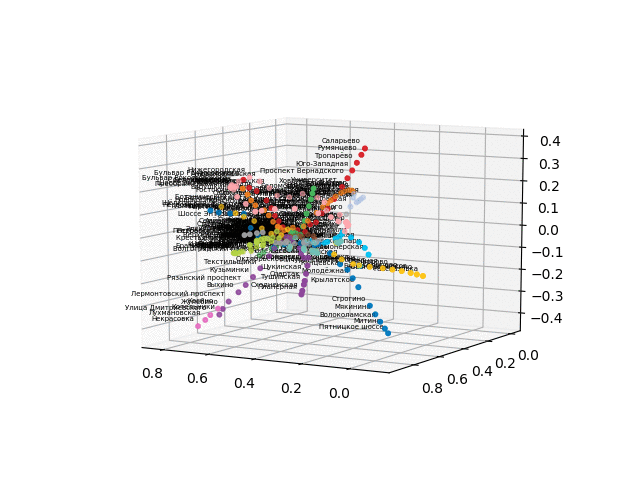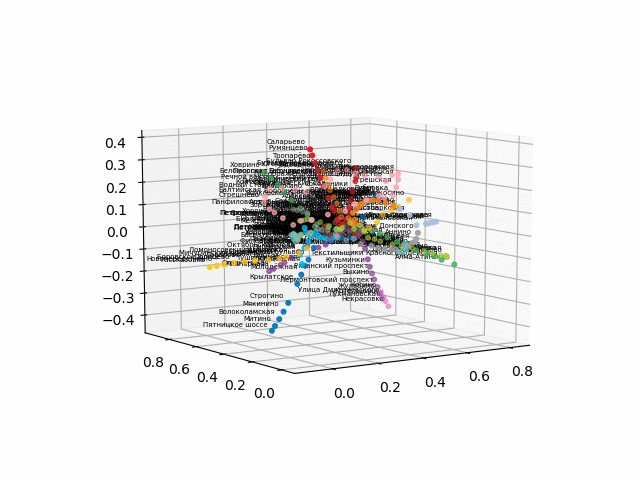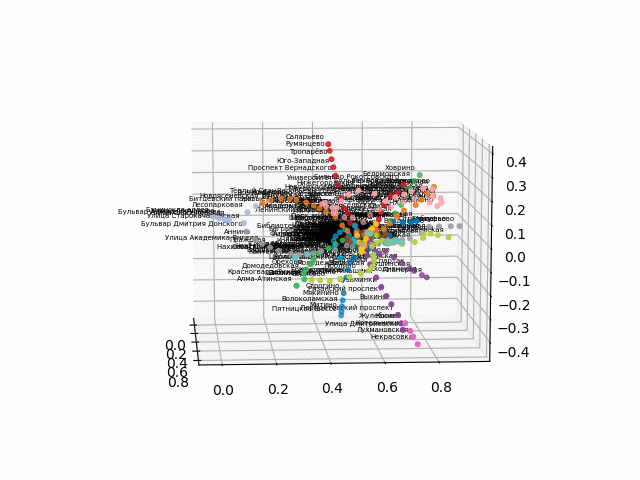
没有文本的版本看起来更漂亮,更易于识别:
xn = fincoords[0][:,0] yn = fincoords[0][:,1] zn = fincoords[0][:,2] l=[labels[idi] for idi in myIDs] colors=[ccode[lines[idi]] for idi in myIDs] xyzn = zip(xn, yn, zn) fig = plt.figure() ax = fig.gca(projection='3d') ax.scatter(xn,yn,zn, c=colors, marker='o') plt.show()
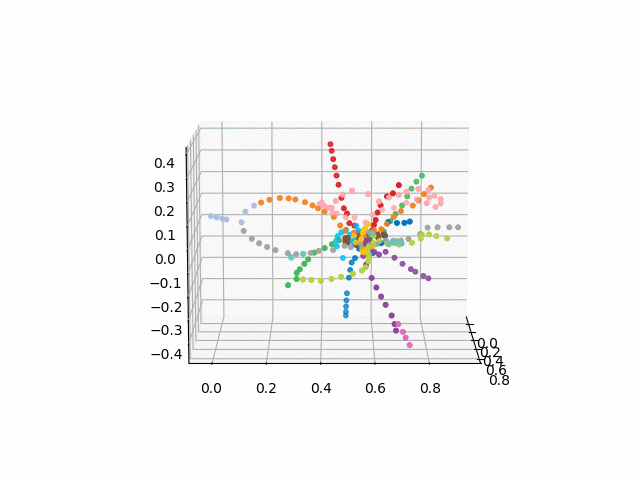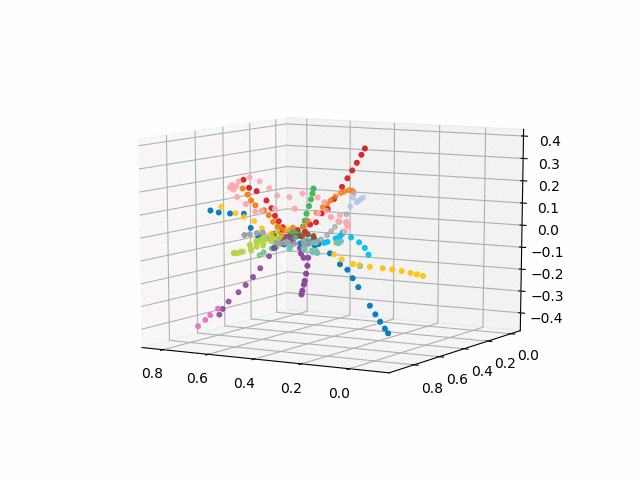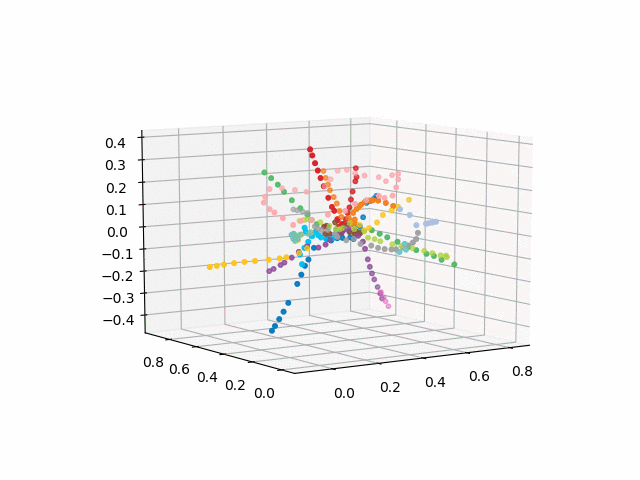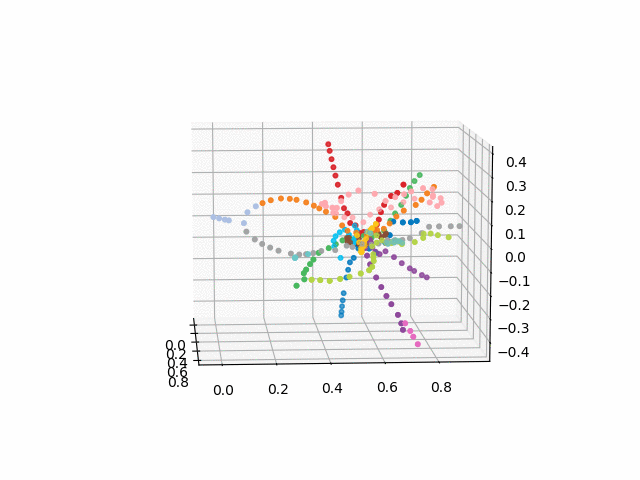
UPD:添加所需颜色的地铁线路并创建gif。 黑线-站点之间的过渡:
myedges=[(myIDs.index(edge[0]),myIDs.index(edge[1]))for edge in G.edges] xn = fincoords[0][:,0] yn = fincoords[0][:,1] zn = fincoords[0][:,2] l=[labels[idi] for idi in myIDs] c=[ccode[lines[idi]] for idi in myIDs] fig = plt.figure() ax = fig.gca(projection='3d') ax.scatter(x,y,z, c=c, marker='o',s=25) for edge in myedges: col='black' if c[edge[0]]==c[edge[1]]: col=c[edge[0]] ax.plot3D([x[edge[0]], x[edge[1]]], [y[edge[0]], y[edge[1]]], [z[edge[0]], z[edge[1]]], col) ims = [] def rotate(angle): ax.view_init(azim=angle) rot_animation = animation.FuncAnimation(fig, rotate, frames=np.arange(0, 362, 3), interval=70) rot_animation.save('rotation2.gif', dpi=80, writer=matplotlib.animation.PillowWriter(80))
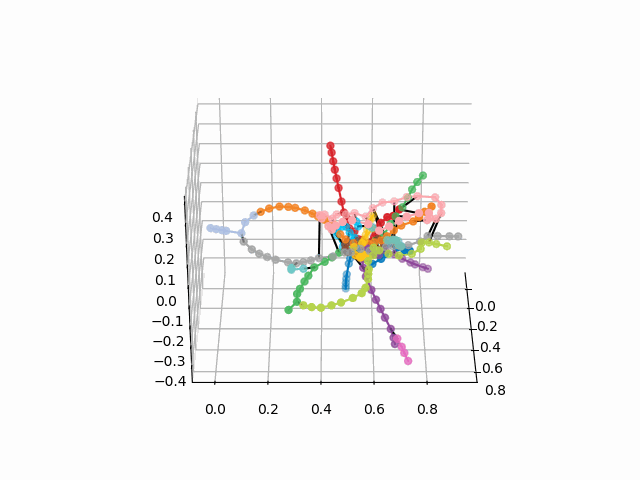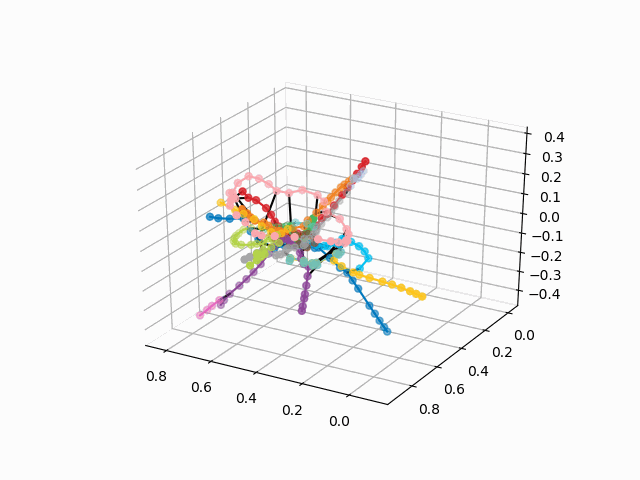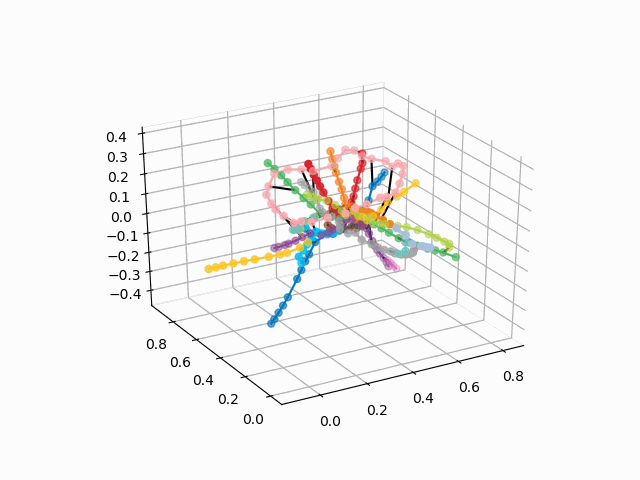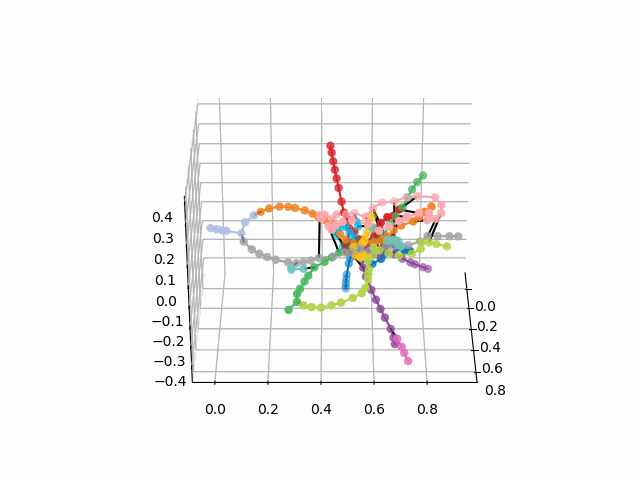
从该方案中,可以得出一些有趣的结论,这些结论在其他方案中不太明显。 对于某些分支,例如绿色,蓝色或紫色,由于不舒服的移植,MCC(粉红色的环)几乎是无用的,从环到这些分支的距离可以看出。 最长的路线-从公用公寓到快速行驶的或星期五的高速公路(红色和粉红色/蓝色的马),长途路线还包括阿拉木图讲故事和布宁·阿里·涅克拉索夫卡。 从计划来看,在莫斯科北部有部分重复的灰色和浅绿色分支-它们在图中附近。 看看新生产线(WDC,BKL)的情况以及谁会更频繁地使用它们,将是很有趣的。 无论如何,我希望这样的计划可以成为分析,启发和旅行计划的有趣工具。
不需要PS 3D,对于2D版本,只需稍微校正一下代码即可。 但是在二维方案的情况下,不可能达到这样的距离精度。