
同事们好! 如何在30秒内突出显示20,000个新闻中的主要主题? 我们在TASS中使用配合和代码进行主题建模的概述。
首先,此注释中提供的信息是ITAR-TASS数字实验室正在开发的原型的一部分,以支持业务的“数字化”。 解决方案正在不断改进,我将在当前部分进行描述,显然,它不是创造的皇冠,而是对进一步发展的支持。
好主意
除了新闻议程(TASS编辑部每天都在处理新闻议程)之外,您还可以了解哪些主题最能构成俄罗斯在线媒体的新闻背景。 为此,我们每隔24/7分钟从300个最受欢迎的网站收集最新消息; 然后最有趣的是-建模方法和实验的选择。
当魔术会议结束时,我的同事,编辑和经理将开始使用带有新闻主题的报告。 我相信对于软件开发和数据科学领域以外的人们来说,文本数据的自动处理,分析和可视化看起来有些神奇。 由于人们将高科技与他人疏远,因此他们工作中的各种缺陷会导致对内在事物的缺乏了解和失望。 为了最大程度地减少不良反应,我尝试使产品更简单,更可靠。 并且,对主题建模本质的理解可以简化为以下事实:与一个主题相关的新闻与与任何其他主题不同的新闻都属于一个主题。
我已经尝试了大约一年的主题建模。 不幸的是,我尝试过的大多数方法都给我填充新闻话题的质量带来了可疑。 同时,我根据从流行的聚类库中选择方法的参数的逻辑执行操作。 但是我没有标签数据集。 因此,每次我查看属于特定主题的一系列文本时。 这个案子很沉闷,也不感恩。
此任务的一个特殊缺点是,几位专家在查看所选主题中包含的新闻后,会在某种程度上发现他们不合适。 例如,有关埃尔多安关于叙利亚行动开始的声明的新闻和有关叙利亚行动开始后的第一份报道的新闻可以理解为一个或多个主题。 因此,媒体将引用TASS或其他新闻社的内容,撰写有关此内容的一系列文字。 而且我算法的结果将趋向于根据词频向量之间的夹角余弦,接受的先验数或在寻找最邻近词的方法中的半径来组合或分离它们。
总的来说,这个伟大的想法既脆弱又美丽。
为什么要进行因素分析?
仔细研究群集文本的方法,可以发现它们中的每一种都是基于多种假设的。 如果这些假设与所研究的问题不符,那么结果可能会很明显。 在我和许多其他研究人员看来,因子分析的假设接近于建模主题的任务。
这种方法创建于20世纪初,其思想是,除了表征样本观测值的变量之外,还有一些隐性因素与一些可观察到的变量相关联,这些隐性因素是非正式的。 例如,对“你相信上帝”和“你去教堂”这个问题的答案将是一致的,而不是不同的。 可以假设存在“宗教因素”,这在一系列相互关联的变量中表现出来。 同时,也有机会衡量变量与其隐藏因素之间的关联程度。
对于文本,问题的陈述如下。 在描述相同主题的新闻中,将出现相同的单词。 例如,在有关土耳其在叙利亚部署军事干预的新闻以及美国对此事的相应反应中,“叙利亚”,“埃尔多安”,“行动”,“美国”,“谴责”等字词会更经常出现。作为同一地区的地缘政治参与者)。
在一段时间内仍需探寻新闻议程的所有重要因素。 这些将成为新闻话题。 但这还不是全部...
一点数学
对于具有主题建模技术经验的人,我可以发表这样的声明。 我尝试过的因子分析版本是
ARTM方法的高度简化版本。
但是我决定尝试使用自由度较小的方法,以便更好地了解内部发生的事情。
(大)ARTM源自概率隐性语义分析pLSA,而后者是基于奇异矩阵分解SVD的LSA的替代方法。
智能因子分析比SVD更进一步,因为它提供了变量和因子之间关系的“简单结构”,这对于SVD而言可能不是一件简单的事情,但局限性在于它无法准确地计算因子值(分数),因此有一些因子值的向量可以替换2个或更多可观察的变量。
正式地,智力因素分析的任务如下:
观察到的变量在哪里
与隐藏因素线性相关
需要寻找
仅此而已! 这些β系数在因子分析领域被称为负荷。 稍后再考虑它们的重要性。
为了得出分析结果,可以采用多种方式进行移动。 我使用的其中之一是找到经典意义上的主要组件,然后旋转以突出显示“简单结构”。 主要成分只是从矩阵的奇异分解开始,或者从变分-协方差矩阵分解为特征向量和特征值。 该问题也通过使似然函数最大化来解决。 通常,因子分析是一种大型的“方法”,至少有10种方法得出不同的结果,建议选择最适合任务的方法。
负载矩阵的旋转也可以以不同的方式完成,我尝试了varimax-正交旋转。
为什么一切都这么复杂?事实是,在统计学家和申请人之间,讨论不会停止关于主要成分,因子分析及其组合的方法的异同。 即使从发现之日起经过100多年,该方法仍然充满了新知识。 一位受人尊敬的统计学家为我带来了以下图片,以帮助他们理解:“就是这样,整理出来。”
 来源
来源 。
全部解决!
开玩笑)。 为了理解下一步,在隔离主要成分之后,我们将它们旋转,从解释变量内的方差到解释变量和因素的协方差就足够了。
此外,我使用原子函数来完成所有这些操作,而不仅仅是按下一个“红色大按钮”。 这种方法使我们能够理解中间阶段数据的转换。
LDA去了哪里?
更新资料我决定对潜在的狄利克雷安排发表自己的看法。 我尝试了这种流行的方法,但在短时间内无法获得干净的结果。 关于如何使用它的简单示例以及“让我们将新闻划分为政治,经济和文化”确实有效,但是...就我而言,我必须将政治划分为50个白天主题,俄罗斯,普京和伊朗将是以及诸如“解放科科林和马马耶夫”之类的狭narrow话题。 实际上,所有这一切,有1-2家新闻社的新闻在媒体中被引用了数十次。
此外,在我的工作中,关于数据性质的假设,每个文本都是按主题分布的概率的假设的特征,在我看来似乎有些人为。 没有编辑同意“撤销对戈卢诺夫案”的新闻是一个混合主题。 对我们来说,这是1个主题。 也许,选择超参数有可能实现LDA的这种碎片化,我将把这个问题留给未来。
代号
我再次涉猎R语言,因此这个小实验将是Aryan。
我们使用3对相关的随机值。 这组包含3个隐藏因素-只是为了清楚起见。
set.seed(1) x1 = rnorm(1000) x2 = x1 + rnorm(1000, 0, 0.2) x3 = rnorm(1000) x4 = x3 + rnorm(1000, 0, 0.2) x5 = rnorm(1000) x6 = x5 + rnorm(1000, 0, 0.2) dt <- data.frame(cbind(x1,x2,x3,x4,x5,x6)) M <- as.matrix(dt) sing <- svd(M, nv = 3) loadings <- sing$v rot <- varimax(loadings, normalize = TRUE, eps = 1e-5) r <- rot$loadings loading_1 <- r[,1] loading_2 <- r[,2] loading_3 <- r[,3] plot(loading_1, type = 'l', ylim = c(-1,1), ylab = 'loadings', xlab = 'variables'); lines(loading_2, col = 'red'); lines(loading_3, col = 'blue'); axis(1, at = 1:6, labels = rep('', 6)); axis(1, at = 1:6, labels = paste0('x', 1:6))
我们得到以下负载矩阵:
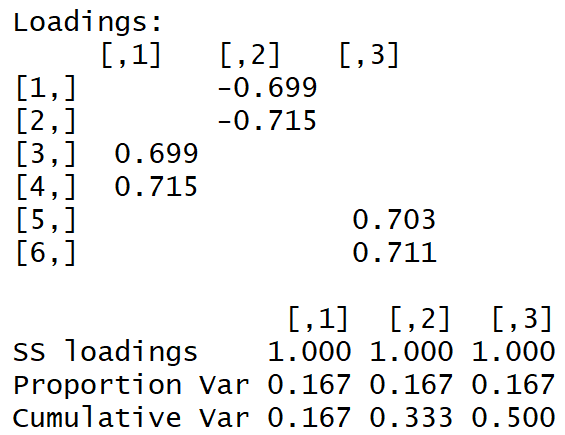
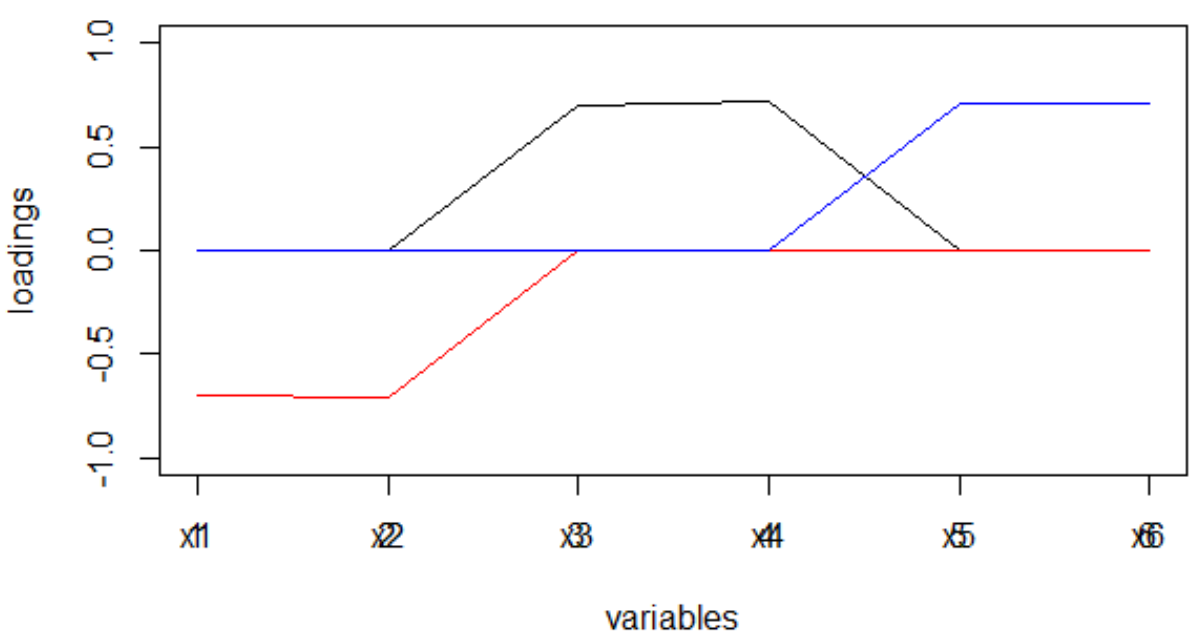
肉眼可见“简单结构”。
这是完成MGK后负载的外观:
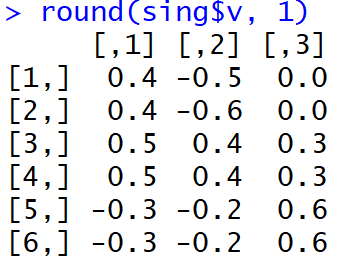
人们很难理解哪些因素与哪些变量相关联。 而且,这种权重以模为单位,并且在机器的解释中将导致主题上单词的非常奇怪的分布。
但是,在前三个主要成分中(旋转之前)所解释的色散份额达到了99%。

那新闻呢?
对于新闻,我们的变量x1,x2 ... xm成为文本中令牌出现的频率(或tf-idf)。 有很多话! 例如,每周50,000个唯一单词是正常的。 可以理解,二元语法将更大。 奇异分解的复杂度是平均值:
也就是说,它是巨大的。 在一个流中分解20,000 * 50,000值的矩阵需要几个小时...
为了能够实时阅读主题并在仪表板上显示“ Shiny”,我遇到了以下痛苦的切入点:
- 最常见字词的前10%
- 根据自我实现公式随机选择文本:
其中n是所有文本。
结果,我在30秒内处理每周数据,而在5秒内一天。 还不错! 但是,您必须了解,新闻趋势只能由最有钱的人掌握。
接收到负载(我注意到这是对观察到的变量与因子的协方差的估计)后,我将它们从符号中释放出来(通过模块,而不是通过度数),该符号会根据所使用的旋转方法而发生变化。
回想一下在进行MHC之后以及在使用varimax旋转之后,负载矩阵有何不同。 负载的稀疏性以及它们在每个因子中的分散最大化的事实:有很大的和非常小的,将导致以下事实:单词将非常整洁地分布在因子中,进而导致进一步的分散新闻文本上的因素分布将出现明显的峰值。
找到(随机选择)的各种主题中负载最重的单词的示例: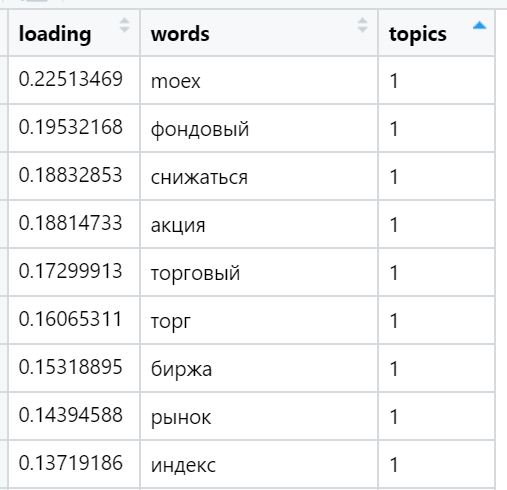
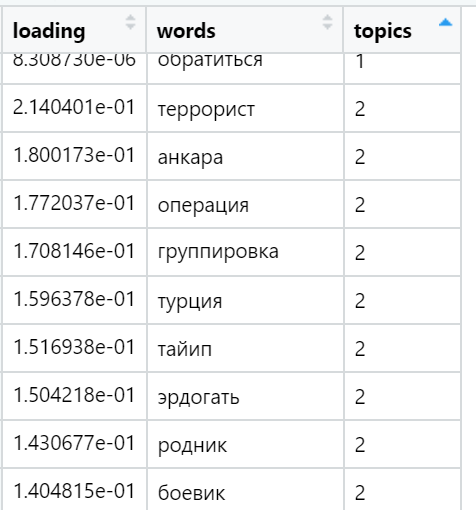

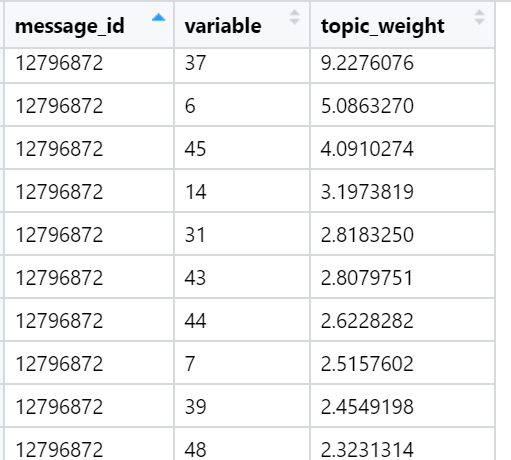
最后,我考虑了文本中与每个因素有关的总和。 最强的优势:考虑到文档中包含的单词数,为每个文本选择一个最大负荷总和的因子,正如我们在旋转过程中所提供的那样,负荷因子之间的分布非常不均匀。 在此迭代中,所有文本(n)都已包含在内,即完整的示例。
就特定新闻文本(随机选择)中的总负荷而言,排名最高的主题示例: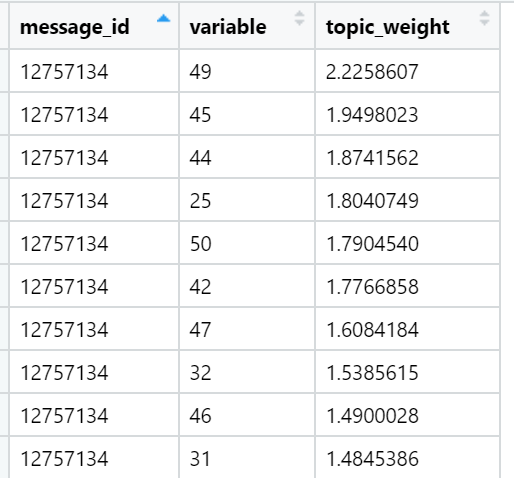
 今天的结果。
今天的结果。 附加信息。
附加信息。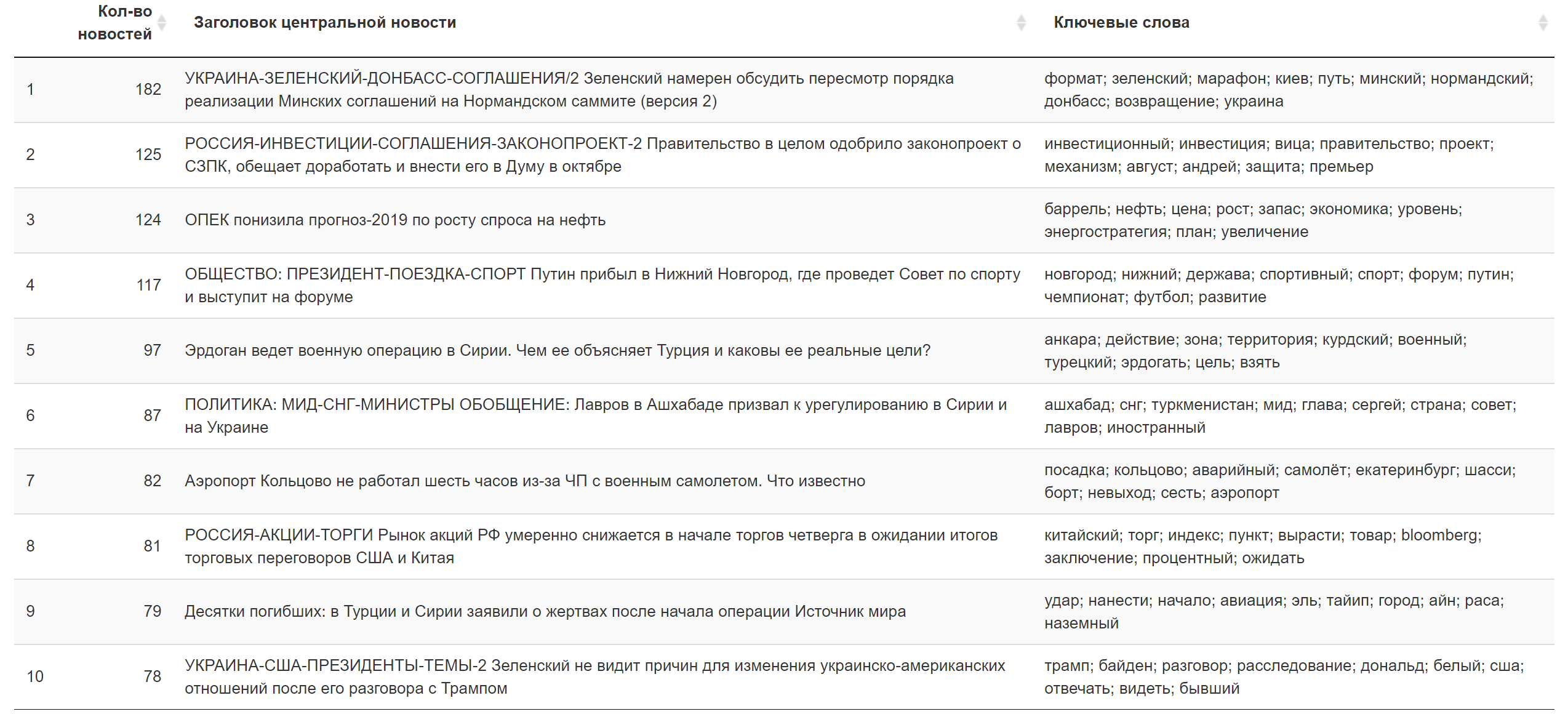
怎么办
在这里,我要做的第一件事是...通常,当灵感到来时,我将尝试配置该工作以每小时对脖子狭窄的神经网络进行训练,这将为我提供非线性的因素近似值-变形的主要成分-以隐藏层神经元的形式。 从理论上讲,可以使用提高的学习速度快速完成学习。 之后,隐藏层的权重(以某种方式标准化)将扮演令牌负载的角色。 它们已经可以以可接受的速度快速加载到最终处理环境中。 也许这个技巧可能导致一个事实,即一周内所有文本都将在10秒内处理完:这是在这种情况下的正常时间。
总之,这就是我要介绍的全部。 我希望这次对主题建模方法的简短介绍可以使您更好地了解“大红色按钮”下的操作,减少与技术的疏远并带来满足感。 如果您已经知道这一点,我将很高兴听到有关技术或产品方面的意见。 我们的实验一直在发展和变化中!