-我需要多大的集群?
-好吧,这取决于...(生气的咯咯笑)
Elasticsearch是Elastic Stack的核心,在其中发生了文档的所有魔术:发行,接收,处理和存储。 性能取决于正确的节点数和解决方案的体系结构。 顺便说一句,如果您订购的是金牌或白金牌,价格也一样。
硬件的主要特征是磁盘(存储),内存(内存),处理器(计算)和网络(网络)。 这些组件中的每一个都负责Elasticsearch对文档执行的操作,这些文档分别是存储,读取,计算以及接收/传输。 让我们谈谈调整大小的一般原则,并揭示其“取决于”。 在文章的末尾是网络研讨会和相关文章的链接。 走吧
本文基于
David Moore的网络研讨会规模和容量规划 。 我们通过链接和注释对他的推理进行了补充,以使其更加清晰。 在文章的结尾,有一条额外的链接是指向Elastic材料的链接,这些链接供那些想更好地融入主题的人使用。 如果您在Elasticsearch方面拥有良好的经验,请在评论中分享如何设计集群。 我们和所有同事都很想知道您的意见。
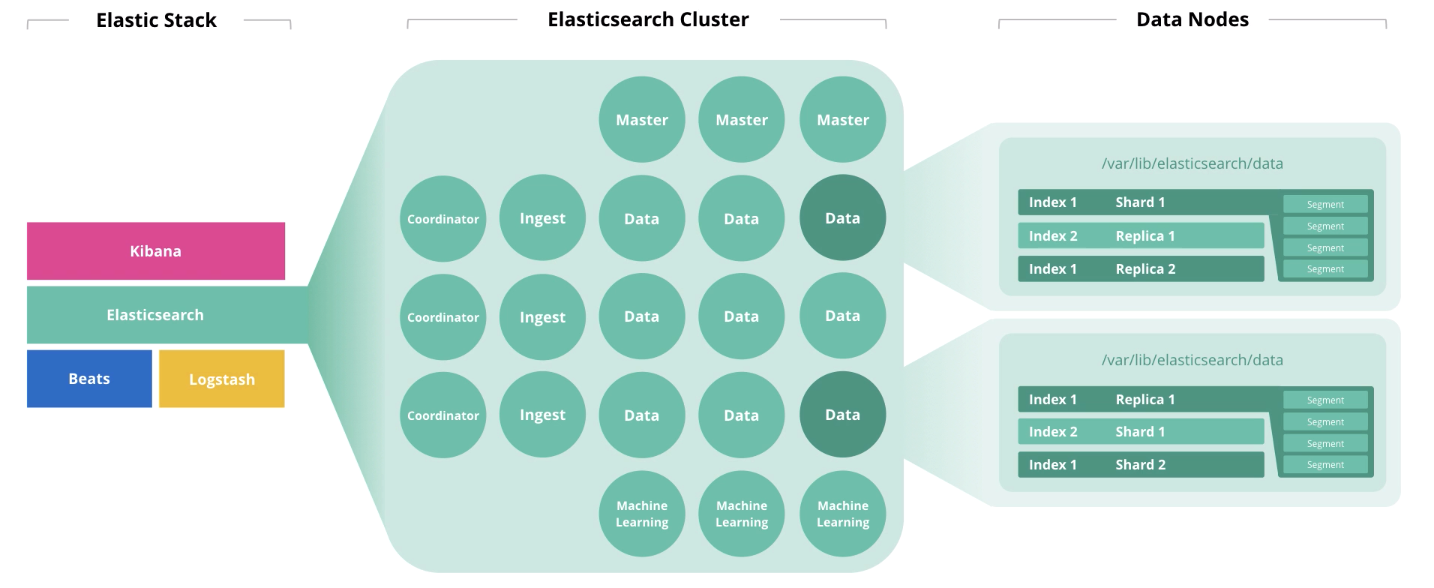
Elasticsearch架构和运营
在本文的开头,我们讨论了构成硬件的4个组件:磁盘,内存,处理器和网络。 节点的角色会影响这些组件中每个组件的处置。 一个节点可以一次执行多个角色,但是随着群集的增长,这些角色应该分布在不同的节点上。
主节点监视整个集群的运行状况。 在主节点的工作中,必须遵守法定人数,即 它们的数量应该是奇数(可能是1,但最好是3)。
数据节点执行存储功能。 为了提高群集性能,必须将节点分为
“热”,“热”和“冷”(冻结) 。 第一个用于在线访问,第二个用于存储,第三个用于存档。 因此,对于“热”,使用本地SSD驱动器是合理的,而对于“热”和“冷” HDD阵列则适合在本地或SAN中使用。
为了确定要存储的节点的存储容量,Elastic建议使用以下逻辑:“热”→1:30(每千兆字节内存30GB磁盘空间),“热”→1:100,“冷”→1:500)。 在
JVM Heap下,不超过总内存的50%,并且不超过30GB,以避免垃圾收集器突袭。 剩余的内存将用作操作系统的缓存。
诸如
线程池和线程队列之类的Elastisearch实例性能指标受处理器核心
利用率的影响更大。 第一个是根据节点执行的操作形成的:搜索,分析,编写和其他操作。 第二个是各种类型的相应请求的队列。 可用的Elasticsearch处理器数量是自动确定的,但是您可以在设置中手动指定此值(如果在同一主机上运行2个或更多Elasticsearch实例,则很有用)。 可以在设置中设置每种类型的最大线程池和线程队列数。 线程池指标是Elasticsearch的主要性能指标。
接收节点从收集器(Logstash,Beats等)获取输入,对其进行转换,然后写入目标索引。
机器学习节点旨在进行数据分析。 正如我们
在Elastic Stack中有关机器学习的
文章中所写的那样,该机制是用C ++编写的,并且在JVM之外运行,JVM本身运行Elasticsearch,因此在单独的节点上执行此类分析是合理的。
协调器节点接受搜索请求并将其路由。 此类节点的存在可加快搜索查询的处理速度。
如果我们根据基础架构容量来考虑节点上的负载,则分布将如下所示:
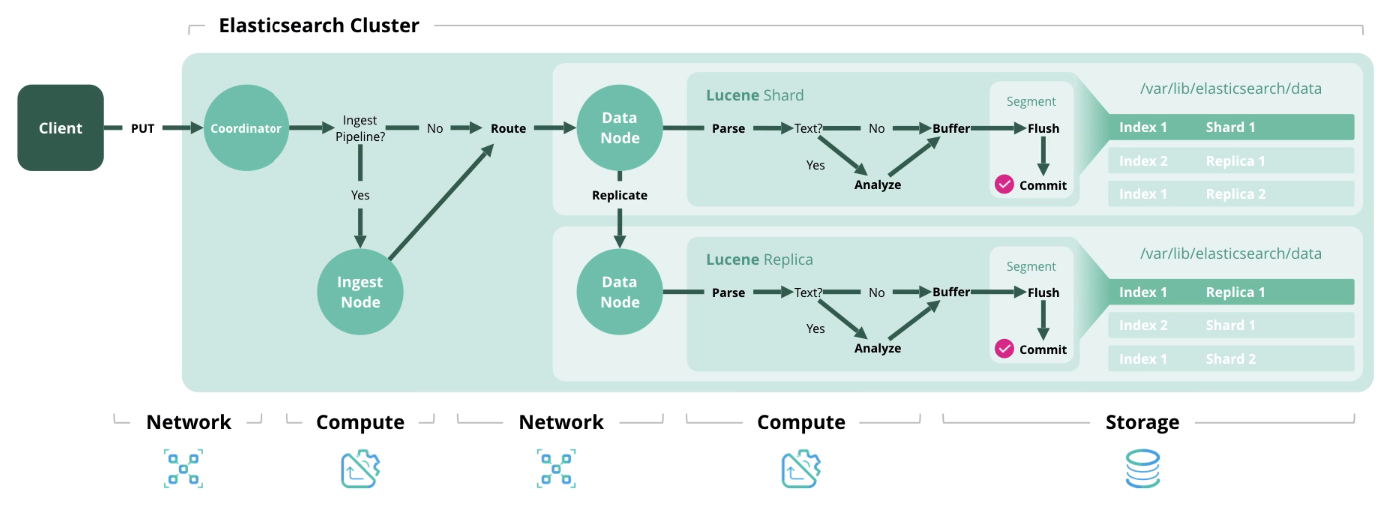
接下来,我们介绍Elasticsearch中的4种主要操作类型,每种操作都需要某种类型的资源。
索引 -处理并将文档保存在索引中。 下图显示了每个阶段使用的资源。
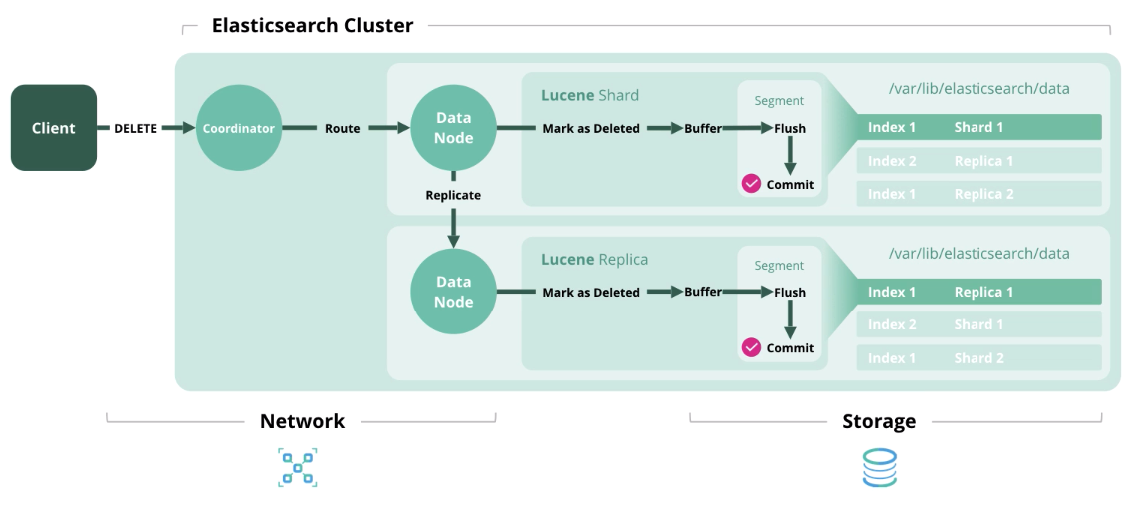
 删除
删除 -从索引中删除文档。
 更新
更新 -像索引和删除一样工作,因为Elasticsearch中的文档是不可变的。
搜索 -从一个或多个索引中获取一个或多个文档或其集合。
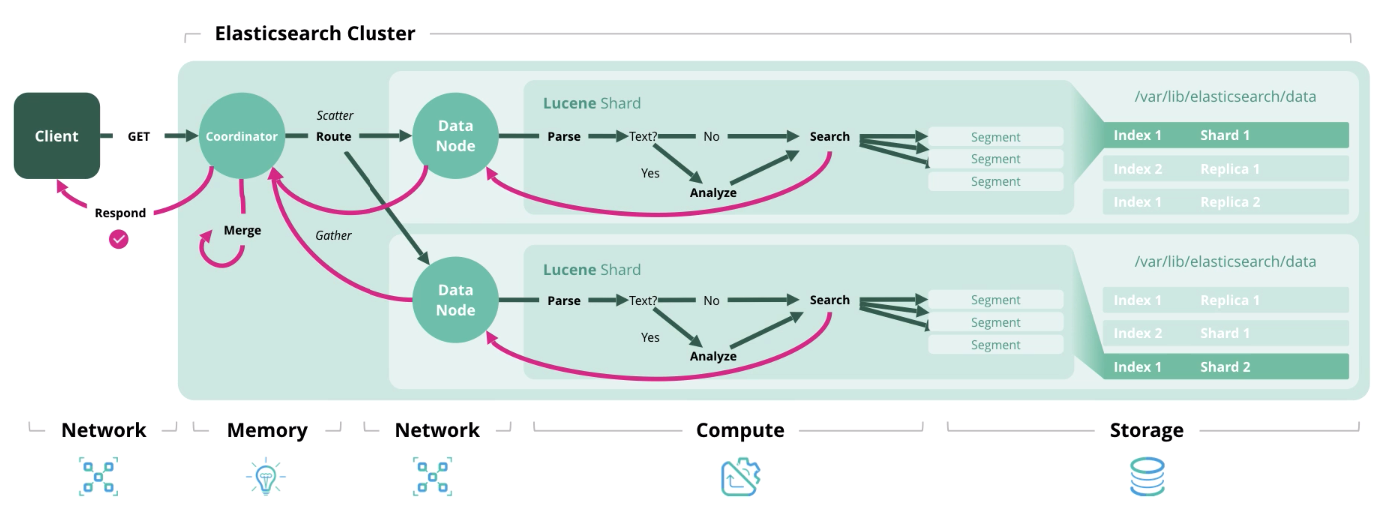
我们确定了负载的体系结构和类型,现在让我们继续进行规模模型的形成。
确定Elasticsearch的大小并在其形成之前提出问题
Elastic建议使用两种大小调整策略:面向存储和吞吐量。 在第一种情况下,磁盘资源和内存至关重要,在第二种情况下,内存,处理器能力和网络至关重要。
根据存储大小调整Elasticsearch体系结构的大小
在计算之前,我们获得了初始数据。 需要:
- 每天的原始数据量;
- 数据存储期限(天);
- 数据转换因子(json因子+索引因子+压缩因子);
- 分片复制数;
- 内存数据节点数量;
- 内存与数据的比率(1:30、1:100等)。
不幸的是,数据转换因子只是凭经验计算的,并且取决于各种因素:原始数据的格式,文档中的字段数等。 为了找出答案,您需要将一部分测试数据加载到索引中。 关于此类测试的主题,
会议上有一段
有趣的视频,并
在Elastic社区中进行了
讨论 。 通常,您可以将其保留为等于1。
默认情况下,
Elasticsearch使用LZ4算法
压缩数据 ,但还有DEFLATE,其
压缩量增加 15%。 通常,可以达到20%至30%的压缩率,但这也是凭经验计算的。 当切换到DEFLATE算法时,计算能力的负担会增加。
仍然有其他建议:
- 存入15%的磁盘空间;
- 承诺5%的额外需求;
- 放置1个等效的数据节点,以确保快速迁移。
现在让我们继续进行公式。 这里没有什么复杂的,而且我们认为,检查您的集群是否符合这些建议将很有趣。
数据总量(GB) =每天原始数据*存储天数*数据转换因子*(副本数-1)
总数据存储(GB) =总数据(GB)*(1 + 0.15库存+ 0.05额外需求)
节点总数 = OK(总数据存储(GB)/每个节点的内存量/内存与数据的比率+ 1个等效数据节点)
Elasticsearch体系结构的大小确定,以取决于存储大小确定分片和数据节点的数量
在计算之前,我们获得了初始数据。 需要:
- 您将创建的索引模式的数量;
- 核心分片和副本的数量;
- 在几天之后将执行索引轮换(如果有的话);
- 存储索引的天数;
- 每个节点的内存量。
仍然有其他建议:
- 每个节点上每1 GB JVM堆不超过20个分片;
- 请勿超过40 GB的硬盘空间。
公式如下:
分片数=索引模式数*主分片数*(复制的分片数+ 1)*存储天数
数据节点数 = OK(分片数/(20 *每个节点的内存))
Elasticsearch带宽调整
需要高带宽的最常见情况是频繁出现,并且搜索查询数量很多。
计算所需的初始数据:
- 每秒最高搜寻量;
- 平均允许响应时间(以毫秒为单位);
- 数据节点上每个处理器核心的核心和线程数。
峰值线程值= OK UP(每秒搜索查询的峰值*响应搜索查询的平均时间(以毫秒为单位)/ 1000毫秒)
卷线程池= OKRUP((每个节点的物理核心数*每个核心的线程数* 3/2)+1)
数据节点数= OK(峰值线程值/线程池容量)
在设计体系结构时,也许并非所有的初始数据都在您的手中,但是在看了
网络研讨会或阅读了本文之后,就会出现一种理解,即原则上会影响硬件资源的数量。
请注意,没有必要遵循给定的体系结构(例如,创建coord coord节点和处理程序节点)。 知道存在这样的参考架构就足够了,它可以带来其他方式无法实现的性能提升。
在以下文章之一中,我们将发布确定群集大小需要回答的问题的完整列表。
要与我们联系,您可以使用Habré
上的个人消息或
网站上的反馈表 。
附加材料网络研讨会“ Elasticsearch规模和容量规划”Elasticsearch容量规划网络研讨会在ElasticON上的主题为“量化集群大小调整”的演讲关于Rally实用程序的网络研讨会,用于确定集群性能指标Elasticsearch尺寸调整文章弹性堆栈网络研讨会