A. A. A. A. A. A. A.
您是否考虑过最近的地铁对公寓价格的影响? A.
A. A.您公寓周围的几所幼儿园怎么样? 您准备好进入地理空间数据世界了吗?
A. 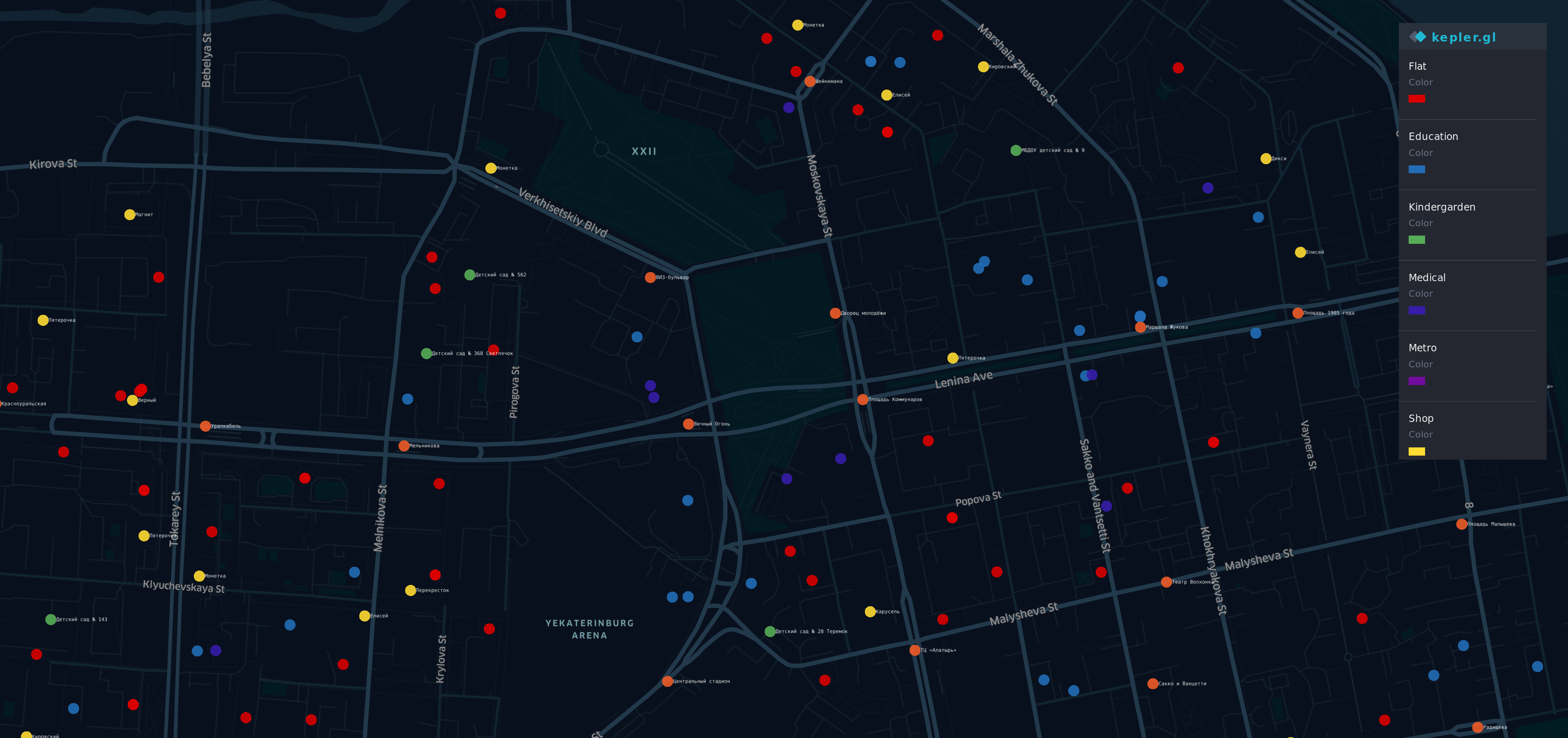 A.
A.
A. A.
A.
到底是什么?
A.
在上一部分中 ,我们有一些数据,并试图在叶卡捷琳堡的房地产市场上找到足够好的报价。
当交叉验证的准确性接近73%时,我们已经到达了一个点。 但是,每个硬币都有2个面。 而73%的准确度则是错误的27%。 我们怎么能减少它呢? 下一步是什么?
A.
空间数据将为您提供帮助
如何从环境中获取更多数据呢? 我们可以使用地理环境和一些空间数据。
A.
很少有人在家里度过一生。 A.有时他们去商店,带孩子去日托。 他们的孩子长大后上学,上大学等。 A.
还是...有时他们需要医疗帮助,他们正在寻找医院。 一个非常重要的事情是公共交通,至少是地铁。 A.换句话说,附近有很多东西会影响价格。
让我给你看一个清单:
- 公共交通站
- 商铺
- 幼稚园
- 医院/医疗机构A. A. A. A. A. A. A. A. A.
- 教育机构A. A. A. A. A. A. A. A. A.
- 地铁
可视化新数据
从获取信息后A.不同来源A. A. ,我进行了可视化。
A.
A.  A. A. A. A.
A. A. A. A.
在地图上,Yek aterinburg是最负盛名的(也是最昂贵的)地区。 A. A. A. A. A.
A. A.
- A. A. A. A. Red点-单位
- 奥兰格-车站
- Y ellow-商店
- 格林-幼儿园
- 蓝-教育
- Indigo-医疗
- 紫罗兰色-地铁
是的,彩虹在这里。
总览
现在我们有了一个以地理数据为边界的数据集,并且有了一些新信息
df.head(10)

df.describe()

一个好的旧模型
与以前一样尝试
y = df.cost X = df.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
然后,我们再次训练我们的模型,不由自主地尝试再次预测公寓的价格。
from sklearn.linear_model import LinearRegression regressor = LinearRegression() model = regressor.fit(X_train, y_train) do_cross_validation(X_test, y_test, model)

嗯...看起来比以前的结果好73%的准确性。
尝试解释怎么办? 我们以前的模型具有足够的能力来解释固定价格。
estimate_model(regressor)

糟糕...我们的新模型可以很好地与旧功能配合使用,但是新功能的行为似乎很奇怪。
例如,大量的教育或医疗机构导致公寓价格下降。 因此,在公寓附近停靠的数量是相同的情况,它应该对公寓价格产生额外的贡献。
新模型更准确,但与现实生活不符。
东西坏了
让我们考虑发生了什么。
首先-我想提醒您,线性回归的主要特征是... erm ...线性。 是的,上尉船长在这里。
如果您的数据与“更大的/租赁的是X,更大的/租赁的是Y”的思想兼容,则线性回归将是一个很好的工具。 但是地理数据比我们预期的要复杂。
例如:
- 如果在您的公寓附近是巴士站,那是个不错的选择,但是如果公寓的数量大约为5,则会导致喧闹的街道,人们希望避免在附近购买公寓。
- 如果有一所大学,它应该对价格产生良好的影响,
同时,如果您不是一个善于交际的人,那么您家附近的一群学生并不那么高兴。 - 您家附近的地铁很好,但是如果您步行一小时即可到达
从最近的地铁站出发-毫无意义。
如您所见-它取决于许多因素和观点。 而且我们的地理数据的性质不是线性的,我们无法推断它们的影响。
同时,为什么具有奇异系数的模型比以前的模型效果更好?
plot.figure(figsize=(10,10)) corr = df.corr()*100.0 sns.heatmap(corr[['cost']], cmap= sns.diverging_palette(220, 10), center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")

看起来很有趣。 我们已经在上一部分中看到了类似的图片。
到最近的地铁的距离与价格之间存在负相关。 而且这个因素对准确性的影响要比一些较旧的影响更大。
同时 ,我们的模型工作混乱,看不到聚合数据和目标变量之间的依赖关系。 线性回归的简单性有其自身的局限性。 A.
国王死了,国王万岁!
如果线性回归不适合我们的情况,还有什么更好的选择? 如果仅我们的模型可以“更智能” ...
幸运的是,我们有一种方法应该更好,因为它更灵活...并且具有内置的机制“如果这样做,则执行此操作,否则执行此操作”。
决策树出现在场景中。
from sklearn.tree import DecisionTreeRegressor A decision tree can have a different depth, usually, it works well when depth is 3 and bigger. And the parameter of max depth has the biggest influence on the result. Let's do some code for checking depth from 3 to 32 data = [] for x in range(3,32): regressor = DecisionTreeRegressor(max_depth=x,random_state=42) model = regressor.fit(X_train, y_train) accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) ax = sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

好吧...对于当A.一棵树的ax_depth等于8,精度在77以上。
如果我们不考虑这种方法的局限性,那将是一个很好的成就。 让我们看看它如何与A. A. M ax_depht = 2 A. A. A.
from IPython.core.display import Image, SVG from sklearn.tree import export_graphviz from graphviz import Source 2_level_regressor = DecisionTreeRegressor(max_depth=2, random_state=42) model = 2_level_regressor.fit(X_train, y_train) graph = Source(export_graphviz(model, out_file=None , feature_names=X.columns , filled = True)) SVG(graph.pipe(format='svg'))

在这张图片上,我们可以看到只有4种预测变体。 使用DecisionTreeRegressor时 ,其工作原理与线性回归不同。 只是有所不同。 它不使用因素(系数)的贡献,而是DecisionTreeRegressor使用“可能性”。 一个单位的价格将与预期中最相似的单位相同。
我们可以通过预测那棵树的价格来显示它。
y = two_level_regressor.predict(X_test) errors = pd.DataFrame(data=y,columns=['errors']) f, ax = plot.subplots(figsize=(12, 12)) sns.countplot(x="errors", data=errors)

并且您的每个预测都将与这些值之一匹配。 当我们使用max_depth = 8时,对于超过2000个单位,我们可以期望不超过256个不同的选项。 也许对分类的问题是有好处的,但对于我们的案例来说它不够灵活。
人群的智慧
如果您试图预测世界杯决赛的比分-很有可能您会误会。 同时,如果您要征求锦标赛所有评委的意见-您将有更好的猜测机会。 如果您问独立专家,培训师,法官,然后用答案做些魔术-您的机会将大大增加。 看起来像是总统选举。
几棵“原始”树的集合可以提供比它们更多的树。 和兰多mForestRegressor是我们将使用的工具
首先,让我们考虑基本参数- 模型中的max_depth , max_features和许多树 。
A.
树数
按照“随机森林中有多少棵树?” 最好的选择是128棵树 。 树木数量的进一步增加不会导致准确性的显着提高,但是会增加训练时间。
最大功能数
现在,我们的模型具有12个功能。 其中一半是旧的,与平面特征有关,其他与地理环境有关。 所以我决定给他们每个人一个机会。 使其成为树的6个要素。
一棵树的最大深度
对于该参数,我们可以分析学习曲线。
from sklearn.ensemble import RandomForestRegressor data = [] for x in range(1,32): regressor = RandomForestRegressor(random_state=42, max_depth=x, n_estimators=128,max_features=6)model = regressor.fit(X_train, y_train)accuracy = do_cross_validation(X, y, model) data.append({'max_depth':x,'accuracy':accuracy}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="accuracy", data=data) max_result = data.loc[data['accuracy'].idxmax()] ax.set_title(f'Max accuracy-{max_result.accuracy}\nDepth {max_result.max_depth} ')

哇... max_depth的准确度超过86% = 16,而一棵设计树的准确度为77%。 看起来很棒,不是吗?
结论
好吧...现在我们的预测结果比以前的要好,有86%接近终点。 检查的最后一步-让我们看一下功能的重要性。 地理数据对我们的模型有没有好处?
feat_importances = model.feature_importances_ feat_importances = pd.Series(feat_importances, index=X.columns) feat_importances.nlargest(5).plot(kind='barh')

某些旧功能仍然会影响结果。 同时到最近的地铁站和幼儿园的距离也受到影响。 听起来合乎逻辑。
毫无疑问,地理数据帮助我们改进了模型。
感谢您的阅读!
聚苯乙烯
我们的旅程尚未结束。 86%的准确性对于真实数据而言是巨大的结果。 同时,这是我们期望的平均误差的14%到10%之间的微小差距。 在我们故事的下一章中,我们将尝试克服这一障碍,或者至少减少这种错误。 A. A. A. A. A. A. A. A.
有 IPython笔记本