大家好! 我的名字叫Lyudmila,我从事负载测试,我想与我们的一位客户分享我们如何在Oracle DBMS下从数据库中对系统的负载测试的回归特性进行比较分析的自动化。
本文的目的不是要发现一种用于比较数据库性能的“新”方法,而是要描述我们的经验并尝试自动比较获得的结果和获得的结果。
减少对DBA Oracle的呼叫次数。
进行任何数据库的负载测试,我们主要感兴趣:
- 安装新组件后是否发生了故障?
- 测试期间数据库的动态。
仅比较AWR报告不足以实现您的目标。
AWR转储的集中存储也是一种好习惯。 AWR转储保留所有历史视图(dba_hist)。
我们的客户已经采用了这种做法。
在下一阶段的负载测试之后,我们比较结果:
- 当前的测试转储与工业转储;
- 当前测试转储与先前的测试转储。
为什么需要这个?
目标是不同的:
- 有时,在测试环境中填充基础本身与在操作环境中进行填充是不同的,这意味着会有一些差异会干扰分析(“干扰”是回答主要问题,“有东西坏了吗?”)。 我想找出这些差异;
- 将当前测试与工业基础的工作进行比较有助于了解当前压力测试的正确性(在某些地方我们负载过多,但根本忘记了某些东西);
- 将当前测试与先前测试进行比较有助于了解当前系统行为是否正常。 与之前的测试相比,系统的行为没有任何变化。
为了实现所有这些目标,我们经常解决比较彼此之间的不同转储的问题。 应该在昨天介绍的日期通常很紧! 完全缺乏检查每个回归测试的时间。 如果您进行一天的可靠性测试,则可以花费大量时间来分析结果...
当然,在测试期间,您可以在企业管理器中在线观看所有内容(或请求gv $视图):不要吸烟,进食和睡觉。

也许您也有自己的自定义工具,是您自己制作的? 您可以分享评论。 我们将分享我们用于任务的内容。
AWR报告包含许多有用的信息:

这里有一些有用的信息,例如:查询正在执行多少,sql_id,模块和缩写文本。 尽管有文本,但是文本被截断了,可以从“ SQL文本的完整列表”段落中获取完整版本。
至于缺点:在AWR报告中,尚不清楚这些请求何时发生,在什么时候出现更多,什么时候更少...毕竟,要分析测试结果,了解发生了什么,以及大概什么时候是重要的:整体测试或峰值/电涌,如期进行。 我们在这里也只会看到有限的顶部。 通过查询历史表可以更轻松地查看它。
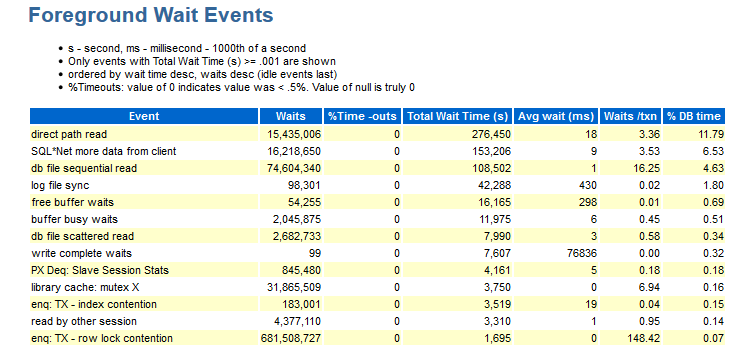
在这里,您可以查看测试期间发生了什么事件。 本节中的数据按数据库时间排序。
对我来说,此部分中缺少以下信息:
- Wait_class(是的,您会记得有此事件属于什么类型的期望)。
- 按模块的分布情况(例如,如果我看到等待enq:TX-行锁争用:需要信息,则在哪个模块下发生)。
在某些工作中,有些数字没有语义部分,也就是说,您需要将相同的模块分组并获得该分组的答案,例如:module_A_1,module_A_2,module_A_3和module_B_1,module_ B_2,module_ B_3。 也就是说,有两个语义模块,但是它们都有不同的名称。
- 我们要引用的对象(CURRENT_OBJ#-例如,如果事件enq:TX-发生索引争用,最好知道应该归咎于哪个索引)。
- Sql_id-哪个请求的文本尝试执行。
- 有关每个快照的数量分布的信息(如上所述)。
要比较两个测试,可以使用AWR报告的比较:
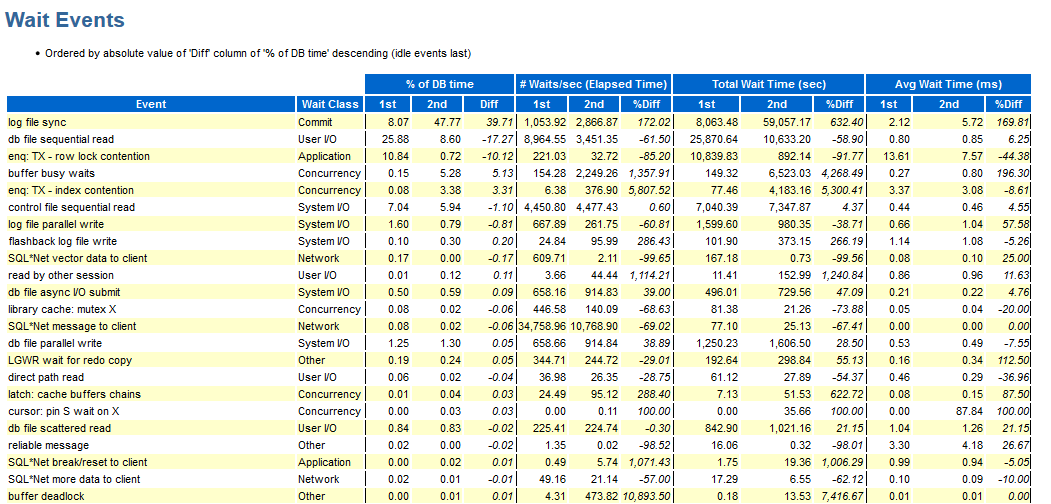
糟糕,我们在这里显示了wait_class;否则,缺点与上述相同。
有时项目上没有企业管理器,例如,您可以使用企业管理器Express或ASH Viewer。 在企业管理器中,许多人使用Top Activity来存储历史数据,但对我来说,使用查询本身可以轻松地查看很多内容。 以上所有内容应与其他测试/工作量进行比较。 我们已经在运行时方面进行了自定义比较,但是没有自定义比较,因此我们手动检查了历史数据表中的查询。
在每次回归测试之后,有必要将历史表中的结果与查询数据库进行比较,查看AWR报告,定位有问题的期望(它出现在哪个模块上,什么时候挂在哪个对象上),从而可以为正确的开发团队生成错误。
客户的数据库已达到190 TB,系统中处理了大量的请求:并行模块的数量为16237。
然后我有了一个想法,如何简化比较AWR转储的过程。 有了这个主意,我去了
弗雷德 。 我们共同创建了一个便捷的门户。
首先,我的问题陈述如下:

然后,尽管如此,我还是决定从头开始系统化对我最常用的历史表的查询... Fred开始将其固定在门户上,然后开始...
首先,我对事件的比较感兴趣,因为已经存在某种形式的查询执行速度的比较。 下一步,我需要有关每个事件的详细信息:例如,如果该事件是索引争用,那么您需要了解我们实际挂在哪个索引上。
然后,我对这些事件中最耗时的时间感兴趣,因为在实施过程中安排了许多任务(作业),因此有必要了解所有事情在什么时候破裂。
总的来说,这就是我想要得到的:
- 定量比较不同测试之间的事件(无下蹲);
- 我需要分析的所有相关信息:sql_id,查询文本,测试过程中的分发,会话引用的对象,模块;
- 方便的过滤器,让您自己查看更改了什么;
- GUI GUI,所有内容都很丰富多彩,可以立即看到(您可以从开发方筛选感兴趣的参与者)
- 模块分组:如前所述,有16237个模块,但是从执行的功能的角度来看,要少很多倍。
弗雷德和我为比较负载测试的AWR转储提供了一个方便使用的门户,我将在下面对其进行详细讨论。
关于门户
因此,将在系统中创建AWR转储,并将其倒入数据库中并在门户上进行比较。
我们使用了以下堆栈:
- Oracle DB-用于存储AWR转储
- Python 2+
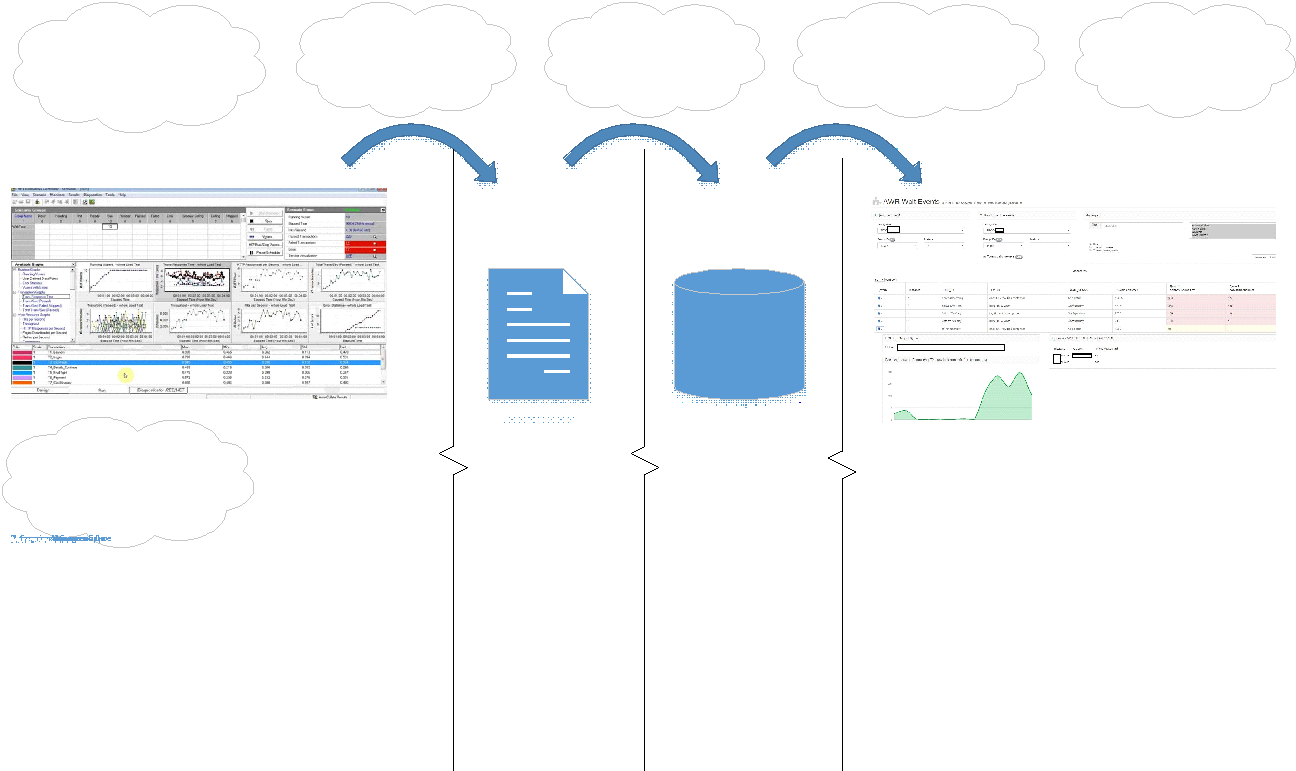
门户界面如下所示:

在门户上,您可以选择比较的转储,测试测试或测试舞会的类型。
每个转储都有自己的唯一标识符-DBID。
您还可以按以下参数进行过滤:
- 实例(实例)-我们有一个集群数据库;
- 请求(Sql_id);
- 等待类型(Wait_Class);
- 大事记
在左上方,选择转储,在右侧,可以设置必要的过滤器以立即选择所需的模块-这使您可以查明已修改/改进的功能中的问题,以便在先前版本中不会出现降级问题。
中间的表是比较转储的结果。 列标题立即显示正在输出的数据。 右两栏显示了两个转储之间的区别:
- 红色突出显示的事件比快照的比较转储相比要多。
- 黄色-新事件;
- 绿色-原始转储中已经存在的事件。
显而易见,我们的测试效果如何。 如果事件频繁发生,那么很可能是:
- 系统过载;
- 或执行后台作业的条件发生了变化,并且该事件开始变得更加频繁。 一旦以这种方式,就会在代码中发现错误:事件不断发生,而不是在所需的条件分支上发生。
如果我们有一个新事件-黄色-这表明系统发生了某种变化,我们需要分析其后果。 在这里,您可以按快照查看事件的分布,并显示有关等待的详细信息。
一旦发生一个案例:发现了一个新事件,这是非常罕见的,没有包含在最重要的事件中,但是由于这个原因,具有关键SLA的功能会变慢。 仅对AWR报告中最重要的查询进行分析无法揭示这一点。
对于每个请求,您可以获得更多详细信息:
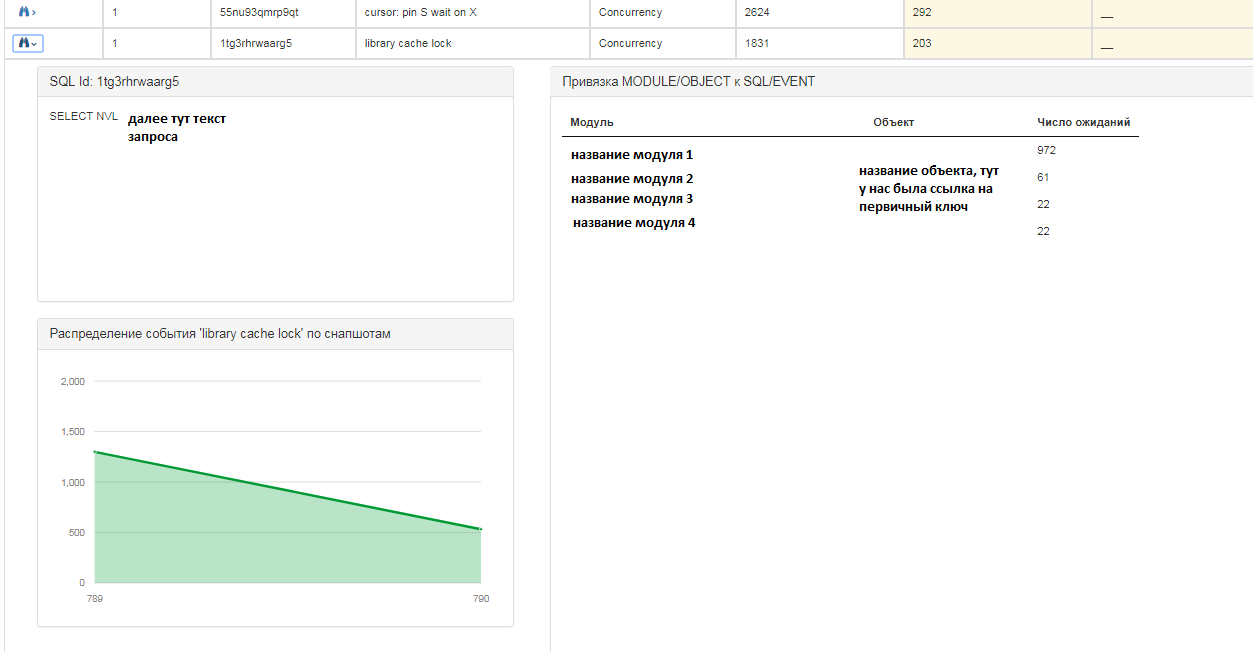
对于每个条目,您还可以看到以下信息:
- 查询sql文本;
- 快照上事件的数量以定量比例分布,即 在什么时间点发生更多/更少的事件;
- “挂”在哪些模块和对象上等待。
比较结果涉及Oracle的系统视图:
DBA_HIST_ACTIVE_SESS_HISTORY,DBA_HIST_SEG_STAT,DBA_HIST_SNAPSHOT,DBA_HIST_SQLTEXT
+
V_DUMPS_LOADED-它自己的服务表(已经由客户实现),它包含有关已加载转储的信息。
一些查询:
图片上事件的分布:
SELECT S.SNAP_ID, COUNT(*) RCOUNT FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V. WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 GROUP BY S.SNAP_ID ORDER BY S.SNAP_ID ASC
按模块分组(将单个逻辑组的模块组合到其中),对象被阻止:
SELECT MODULE, OBJECT_NAME, COUNT(*) RCOUNT (SELECT CASE (WHEN INSTR(S.MODULE, ' 1')>0 THEN ' 1' WHEN INSTR(S.MODULE, ' 2')>0 THEN ' 2' … ELSE S.MODULE END) MODULE, O.OBJECT_NAME FROM DBA_HIST_ACTIVE_SESS_HISTORY S, V_DUMPS_LOADED V, DBA_HIST_SEG_STAT O WHERE V.ID = :1 AND S.DBID = V.DBID AND S.INSTANCE_NUMBER = :2 AND S.SQL_ID = :3 AND S.EVENT_ID = :4 AND S.CURRENT_OBJ
你到底得到了什么?
该门户网站使我们节省了比较AWR转储的时间。 手动比较花了4到6个小时,现在我们花了2-3个小时。 我们总是有机会快速比较它们之间以及与工业转储之间不同测试的结果,以及设置我们现在需要的过滤器。 也就是说,我们可以方便地比较彼此之间的历史数据,而不仅仅是在线观看当前结果。
以前,每次回归之后,有必要将历史表中的结果与查询数据库进行比较,查看AWR报告,对有问题的期望进行本地化(发生在哪个模块上,发生在什么时间,它挂在哪个对象上),以便最终可能导致正确的开发团队出现缺陷。 现在,只需选择要比较的转储,设置过滤器,即可立即准备好比较结果。 您还可以向开发人员发送指向门户的链接,该链接指示测试转储的DBID,他们自己将被其模块过滤。
创建门户仅用了两周的时间,因为门户的一部分已经准备就绪:将转储加载到数据库中。 当然,任何基于Oracle的项目都不需要这种门户解决方案。 这对于将多个模块分为不同名称的产品很有用。 对于简单系统或不重视模块填写的系统,门户将是多余的。
由于门户网站分析在特定时间段内拍摄的图像,因此门户网站不能完全免除对数据库的在线监视,因为某些事件可能无法进入图像。
这是用于根据测试结果分析历史数据的便捷工具,但在创建大量图片且需要检查大量数据的其他情况下,该工具很有用。 由于过滤器和图形的结合,您可以立即看到突发事件,这些突发事件在普通AWR报告中(不要与转储混淆)将隐藏在分组信息中。 选择要比较的转储,设置过滤器就足够了,比较结果立即准备好,或者您可以向门户上的开发人员发送一个链接,指示测试转储的DBID,它们本身将被其模块过滤。
如果您决定为您的项目开发一个类似的门户,请选择最适合您的过滤器集。 如果您每次都根据不同的条件进行过滤,那么为此进行适当的过滤将更加容易。
生成的解决方案仍然可以完成,例如:
- 比较请求的持续时间;
- 比较查询计划;
- 比较具有相同计划但文本不同的请求;
- 卸载到测试报告中(作为Word / Exel文档执行)。
或者,通常,告诉门户网站连接到经过测试的数据库,以便它使用内存视图(而不仅仅是历史数据)在线构建相似的图片。 并将它们保存到您的数据库。
我们已经使用门户超过一年了。 弗雷德,非常感谢!
由Lyudmila Matskus发表,
喷气信息系统