哈Ha 在本文中,我们将处理不可压缩流体的Navier-Stokes方程,对其进行数值求解,并通过在CUDA上进行并行计算进行漂亮的模拟。 主要目的是说明解决液体和气体建模问题时,如何在实践中应用方程式基础的数学。

警告本文包含许多数学知识,因此对问题的技术方面有兴趣的人员可以直接转到算法的实现部分。 但是,我仍然建议您阅读整篇文章,并尝试了解解决方案的原理。 如果您在阅读结束时有任何问题,我将很乐意在帖子评论中回答。
注意:如果您正在通过移动设备阅读Habr,但没有看到公式,请使用网站的完整版本不可压缩流体的Navier-Stokes方程
\部分b ˚F v Ê Ç ù ö v é ř \部分吨 = - (b ˚F v Ê Ç ù Ç d ö 吨Ñ 一个b 升一)b ˚F v ë Ç ù - 1 ö v Ë - [R [R ħ o n a b l a b f p + n u n abla2 bf vecu+ bf vecF
我认为至少每个人都听说过这个方程式,有些甚至可能是解析地解决了它的特殊情况,但总的来说,这个问题至今仍未解决。 当然,在本文中我们没有设定解决千年问题的目标,但是我们仍然可以对其应用迭代方法。 但是对于初学者来说,让我们看一下此公式中的表示法。
按照惯例,Navier-Stokes方程可分为五个部分:
- \部分 bf vecu over\部分t -表示某一点的流体速度变化率(我们将在模拟中为每个粒子考虑该速度)。
- −( bf vecu cdot nabla) bf vecu -流体在太空中的运动。
- −1 over rho nabla bfp 施加在粒子上的压力是 rho -流体密度系数)。
- nu nabla2 bf vecu -介质的粘度(越大,液体抵抗施加到其部分的力越强), nu -粘度系数)。
- bf vecF -我们对流体施加的外力(在我们的情况下,该力将起非常具体的作用-它将反映用户执行的操作。
另外,由于我们将考虑不可压缩且均质的流体,因此我们有另一个方程:
{{{{\\ nabla \ cdot \ bf \ vec {u}} = 0} 。 环境中的能量是恒定的,不会流到任何地方,也不会来自任何地方。
剥夺所有对
向量分析不熟悉的读者的想法是错误的,因此同时简短地浏览方程式中存在的所有运算符(但是,我强烈建议您回顾微分,微分和向量的含义,因为它们是所有这些的基础。什么将在下面讨论)。
我们从nabla运算符开始,该运算符就是这样的一个向量(在我们的例子中,它将是两部分的,因为我们将在二维空间中对流体进行建模):
nabla=\开始pmatrix\部分 over\部分x,\部分 over\部分y\结束pmatrix
nabla运算符是矢量微分运算符,可以同时应用于标量函数和矢量一。 在标量的情况下,我们获得函数的梯度(其偏导数的向量),在矢量的情况下,获得沿轴的偏导数之和。 此运算符的主要功能是通过它可以表达矢量分析的主要操作-
梯度 (
梯度 ),
div (
散度 ),
rot (
转子 )和
nabla2 (
Laplace运算符 )。 值得注意的是
( bf vecu cdot nabla) bf vecu 不等于 ( nabla cdot bf vecu) bf vecu -nabla运算符不具有可交换性。
正如我们将在后面看到的那样,当移动到一个离散空间来执行所有计算时,这些表达式将显着简化,因此,如果您现在不太清楚如何处理所有这些,请不要惊慌。 将任务划分为几个部分,我们将依次解决每个部分,并以将多个功能顺序应用到我们的环境中的形式呈现所有这些内容。
Navier-Stokes方程的数值解
为了在程序中表示流体,我们需要在任意时间点获得每个流体粒子状态的数学表示。 最方便的方法是创建一个粒子矢量场,以坐标平面的形式存储其状态:

在二维数组的每个像元中,我们将一次存储粒子速度
t: bf vecu=u( bf vecx,t), bf vecx=\开始pmatrixx,y endpmatrix ,粒子之间的距离用
\增量x 和
\增量 相应地。 在代码中,对于我们来说,每次迭代更改速度值就足以解决一组几个方程式。
现在我们考虑到我们的坐标网格来表示梯度,散度和拉普拉斯算子(
我,j -数组中的索引,
\ bf \ vec {u} _ {(x)},\ vec {u} _ {{y)} -从向量中获取相应的分量):
如果我们假设向量运算符的离散公式可以进一步简化
deltax= deltay=1 。 该假设不会极大地影响算法的准确性,但是,它减少了每次迭代的操作次数,并且通常使表达式更令人愉悦。
粒子运动
仅当我们可以找到相对于当前正在考虑的粒子最近的粒子时,这些语句才起作用。 为了使与找到它们相关的所有可能成本无效,我们将不跟踪它们的运动,而是通过在时间上向后投影运动轨迹来跟踪粒子在迭代开始时的位置(换句话说,减去速度矢量乘以时间变化)当前位置)。 对数组的每个元素使用此技术,我们将确保任何粒子都将具有“邻居”:
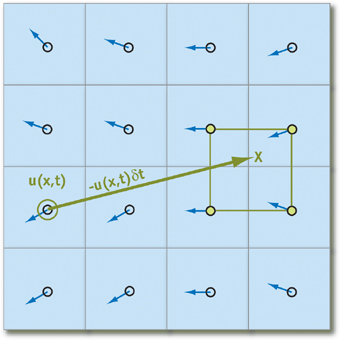
把那个
q -存储粒子状态的数组元素,我们获得以下公式来计算粒子随时间的状态
\增量t (我们认为,已经计算出了所有必需的参数,如加速度和压力):
q( vec bfx,t+ deltat)=q( bf vecx− bf vecu deltat,t)
我们立即注意到,对于足够小的
\增量t 而且我们永远都不会超出细胞的限制,因此选择用户赋予颗粒合适的动量非常重要。
为了避免在投影碰到单元格边界或非整数坐标的情况下准确性下降,我们将对四个最近粒子的状态进行双线性插值,并将其作为该点的真实值。 原则上,这种方法实际上不会降低仿真的准确性,同时实现起来也很简单,因此我们将使用它。
黏度
每种液体都有一定的粘度,可以防止外力对其零件产生影响(蜂蜜和水将是一个很好的例子,在某些情况下,它们的粘度系数相差一个数量级)。 粘度直接影响液体获得的加速度,可以用下面的公式表示,如果为了简短起见,我们暂时省略了其他术语:
\部分 vec bfu over\部分t= nu nabla2 bf vecu
。 在这种情况下,速度的迭代方程采用以下形式:
u( bf vecx,t+ deltat)=u( bf vecx,t)+ nu deltat nabla2 bf vecu
我们将稍微改变这种平等,将其转化为形式
bfA vecx= vecb (线性方程组的标准形式):
( bfI− nu deltat nabla2)u( bf vecx,t+ deltat)=u( bf vecx,t)
在哪里
bfI 是单位矩阵。 我们需要进行这样的转换,以便随后应用
Jacobi方法来求解几个相似的方程组。 我们稍后还将讨论。
外力
该算法最简单的步骤是对介质施加外力。 对于用户而言,这将以鼠标或其移动在屏幕上的单击形式反映出来。 外力可以通过以下公式描述,我们将其应用于矩阵的每个元素(
vec bfG -动量矢量
xp,yp -鼠标位置
x,y -当前单元格的坐标,
-作用半径,缩放参数):
\ vec {\ bf F} = \ vec {\ bf G} \ delta t {\ bf exp} \左(-{{{(x-x_p)^ 2 +(y-y_p)^ 2} \ over r} \正确)
可以将冲动矢量轻松地计算为鼠标的上一个位置与当前位置(如果有)之间的差,在这里您仍然可以发挥创造力。 正是在算法的这一部分中,我们可以将颜色添加到液体,其照明等中。 外力还可以包括重力和温度,尽管实现这些参数并不困难,但在本文中我们将不考虑它们。
压力值
Navier-Stokes方程中的压力是一种力,该力可防止在对粒子施加任何外力之后将粒子填满所有可用空间。 立刻,它的计算非常困难,但是通过应用
亥姆霍兹分解定理可以大大简化我们的问题。
致电
bf vecW 计算位移,外力和粘度后获得的矢量场。 它将具有非零散度,这与液体不可压缩的条件相矛盾(
nabla cdot bf vecu=0 ),并且要解决此问题,必须计算压力。 根据亥姆霍兹分解定理,
bf vecW 可以表示为两个字段的总和:
bf vecW= vecu+ nablap
在哪里
bfu -这是我们正在寻找零散度的向量场。 本文不会提供这种相等性的证明,但是最后您可以找到带有详细说明的链接。 我们可以将nabla运算符应用于表达式的两侧,以获得以下公式来计算标量压力场:
nabla cdot bf vecW= nabla cdot( vecu+ nablap)= nabla cdot vecu+ nabla2p= nabla2p
上面写的表达式是压力
的泊松方程 。 我们还可以通过前述的Jacobi方法求解它,从而在Navier-Stokes方程中找到最后一个未知变量。 原则上,线性方程组可以用各种不同的复杂方法求解,但是我们将继续讨论它们中最简单的一个,以免给本文增加负担。
边界条件和初始条件
在有限域上建模的任何微分方程都需要正确指定初始或边界条件,否则我们很可能会得到物理上不正确的结果。 建立边界条件以控制坐标网格边缘附近的流体行为,并且初始条件指定程序启动时粒子具有的参数。
初始条件将非常简单-最初流体是静止的(粒子速度为零),压力也为零。 边界条件将通过给定公式设置速度和压力:
bf vecu0,j+ bf vecu1,j over2 deltay=0, bf vecui,0+ bf vecui,1\超过2 deltax=0
bfp0,j− bfp1,j over deltax=0, bfpi,0− bfpi,1 over deltay=0
因此,边缘处的粒子速度将与边缘处的速度相反(因此它们将从边缘排斥),并且压力等于紧邻边界的值。 这些操作应应用于数组的所有边界元素(例如,存在网格大小
N\乘以M ,然后将算法应用于图中蓝色标记的单元):

染剂
利用我们现在拥有的,您已经可以想出很多有趣的东西。 例如,实现染料在液体中的扩散。 为此,我们只需要维护另一个标量字段,该字段将负责模拟每个点上的绘制量。 更新染料的公式与速度非常相似,表示为:
\部分d over\部分t=−( vec bfu cdot nabla)d+ gamma nabla2d+S
在公式中
S 负责为该区域补充染料(可能取决于用户单击的位置),
d 直接是该点的染料量,并且
\伽玛 -扩散系数。 解决这个问题并不困难,因为有关公式推导的所有基本工作已经完成,并且足以进行一些替换。 绘画可以在代码中以RGB格式的颜色实现,在这种情况下,任务可以简化为具有多个实际值的操作。
涡度
涡度方程不是Navier-Stokes方程的直接部分,但是对于合理地模拟染料在液体中的运动,它是一个重要的参数。 由于我们正在离散的字段上生成算法,并且由于浮点值精度的损失,因此这种效果消失了,因此我们需要通过对空间中的每个点施加额外的力来恢复它。 此力的向量指定为
bf vecT 并由以下公式确定:
bf omega= nabla times vecu
vec eta= nabla| omega|
bf vec psi= vec eta over| vec eta|
bf vecT= epsilon( vec psi times omega) deltax
omega 将
转子应用于速度矢量的结果(在本文开头给出了其定义),
vec eta -绝对值的标量场的梯度
omega 。
vec psi 代表归一化向量
vec eta 和
epsilon 是一个常数,用于控制流体中的涡旋大小。
求解线性方程组的Jacobi方法
在分析Navier-Stokes方程时,我们提出了两个方程组-一个用于粘度,另一个用于压力。 它们可以通过迭代算法解决,该算法可以通过以下迭代公式来描述:
x ^ {(k + 1)} _ {i,j} = {{x ^ {{k)} _ {i-1,j} + x ^ {{k)} _ {i + 1,j} + x ^ {{(k)} _ {i,j-1} + x ^ {{k)} _ {i,j + 1} + \ alpha b_ {i,j}} \ over \ beta}
对于我们
x -表示标量或矢量字段的数组元素。
k -迭代次数,我们可以对其进行调整,以提高计算的准确性,反之亦然,以减少迭代次数并提高生产率。
为了计算粘度,我们用以下公式代替:
x=b= bf vecu ,
alpha=1 over nu deltt ,
beta=4+ alpha ,这是参数
beta -权重之和。 因此,我们需要存储至少两个矢量速度场,以便独立读取一个场的值并将其写入另一场。 平均而言,为了通过Jacobi方法计算速度场,必须执行20至50次迭代,如果我们在CPU上进行计算,这将是很多工作。
对于压力方程,我们进行以下替换:
x=p ,
b= nabla bf cdot vecW ,
alpha=−1 ,
beta=4 。 结果,我们获得了价值
pi,j deltat 在这一点上。 但是,由于它仅用于计算从速度场减去的梯度,因此可以省略其他变换。 对于压力场,最好执行40-80次迭代,因为数字越小,差异就越明显。
算法实现
我们将使用C ++实现该算法,还需要
Cuda Toolkit (您可以在Nvidia网站上阅读如何安装它)以及
SFML 。 我们需要CUDA来使算法并行化,并且SFML仅用于创建窗口并在屏幕上显示图片(原则上,这可以用OpenGL编写,但是性能上的差别并不明显,但是代码会再增加200行)。
Cuda工具包
首先,我们将讨论如何使用Cuda Toolkit并行化任务。 Nvidia本身提供了
更详细的指南 ,因此在这里我们只限于最必要的内容。 还假定您能够安装编译器,并且能够构建测试项目而没有错误。
要创建在GPU上运行的功能,您首先需要声明我们要使用多少个内核,以及要分配多少个内核块。 为此,Cuda Toolkit为我们提供了一种特殊的结构
-dim3 ,默认情况下将其所有x,y,z值都设置为1。通过在调用函数时将其指定为参数,我们可以控制分配的内核数。 由于我们使用的是二维数组,因此我们只需要在构造函数中设置两个字段:
x和
y :
dim3 threadsPerBlock(x_threads, y_threads); dim3 numBlocks(size_x / x_threads, y_size / y_threads);
其中
size_x和
size_y是要处理的数组的大小。 签名和函数调用如下(三尖括号由Cuda编译器处理):
void __global__ deviceFunction();
在函数本身中,可以使用以下公式通过该块中的块号和内核号来恢复二维数组的索引:
int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y;
应当注意,在视频卡上执行的功能必须用
__global__标记标记,并且必须返回
void ,因此大多数情况下,计算结果将作为参数传递到数组中,并预先分配在视频卡的内存中。
功能
CudaMalloc和
CudaFree负责释放和分配视频卡上的内存。 我们可以对指向它们返回的存储区的指针进行操作,但是我们无法从主代码访问数据。 返回计算结果的最简单方法是使用
cudaMemcpy ,类似于标准
memcpy ,但是能够将数据从视频卡复制到主内存,反之亦然。
SFML和窗口渲染
有了所有这些知识,我们终于可以继续直接编写代码。 首先,让我们创建
main.cpp文件,并在其中放置窗口渲染的所有辅助代码:
main.cpp #include <SFML/Graphics.hpp> #include <chrono> #include <cstdlib> #include <cmath> //SFML REQUIRED TO LAUNCH THIS CODE #define SCALE 2 #define WINDOW_WIDTH 1280 #define WINDOW_HEIGHT 720 #define FIELD_WIDTH WINDOW_WIDTH / SCALE #define FIELD_HEIGHT WINDOW_HEIGHT / SCALE static struct Config { float velocityDiffusion; float pressure; float vorticity; float colorDiffusion; float densityDiffusion; float forceScale; float bloomIntense; int radius; bool bloomEnabled; } config; void setConfig(float vDiffusion = 0.8f, float pressure = 1.5f, float vorticity = 50.0f, float cDiffuion = 0.8f, float dDiffuion = 1.2f, float force = 1000.0f, float bloomIntense = 25000.0f, int radius = 100, bool bloom = true); void computeField(uint8_t* result, float dt, int x1pos = -1, int y1pos = -1, int x2pos = -1, int y2pos = -1, bool isPressed = false); void cudaInit(size_t xSize, size_t ySize); void cudaExit(); int main() { cudaInit(FIELD_WIDTH, FIELD_HEIGHT); srand(time(NULL)); sf::RenderWindow window(sf::VideoMode(WINDOW_WIDTH, WINDOW_HEIGHT), ""); auto start = std::chrono::system_clock::now(); auto end = std::chrono::system_clock::now(); sf::Texture texture; sf::Sprite sprite; std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4); texture.create(FIELD_WIDTH, FIELD_HEIGHT); sf::Vector2i mpos1 = { -1, -1 }, mpos2 = { -1, -1 }; bool isPressed = false; bool isPaused = false; while (window.isOpen()) { end = std::chrono::system_clock::now(); std::chrono::duration<float> diff = end - start; window.setTitle("Fluid simulator " + std::to_string(int(1.0f / diff.count())) + " fps"); start = end; window.clear(sf::Color::White); sf::Event event; while (window.pollEvent(event)) { if (event.type == sf::Event::Closed) window.close(); if (event.type == sf::Event::MouseButtonPressed) { if (event.mouseButton.button == sf::Mouse::Button::Left) { mpos1 = { event.mouseButton.x, event.mouseButton.y }; mpos1 /= SCALE; isPressed = true; } else { isPaused = !isPaused; } } if (event.type == sf::Event::MouseButtonReleased) { isPressed = false; } if (event.type == sf::Event::MouseMoved) { std::swap(mpos1, mpos2); mpos2 = { event.mouseMove.x, event.mouseMove.y }; mpos2 /= SCALE; } } float dt = 0.02f; if (!isPaused) computeField(pixelBuffer.data(), dt, mpos1.x, mpos1.y, mpos2.x, mpos2.y, isPressed); texture.update(pixelBuffer.data()); sprite.setTexture(texture); sprite.setScale({ SCALE, SCALE }); window.draw(sprite); window.display(); } cudaExit(); return 0; }
主功能开头的行
std::vector<sf::Uint8> pixelBuffer(FIELD_WIDTH * FIELD_HEIGHT * 4);
创建具有恒定长度的一维数组形式的RGBA图像。 我们将其与其他参数(鼠标位置,帧之间的差异)一起传递给
computeField函数。 后者以及其他几个函数在
kernel.cu中声明,并调用在GPU上执行的代码。 您可以在SFML网站上找到有关任何功能的文档,文件代码中没有任何有趣的事情,因此我们不会在此停留太久了。
GPU计算
要开始在gpu下编写代码,请首先创建一个kernel.cu文件并在其中定义几个辅助类:
Color3f,Vec2,Config,SystemConfig :
kernel.cu(数据结构) struct Vec2 { float x = 0.0, y = 0.0; __device__ Vec2 operator-(Vec2 other) { Vec2 res; res.x = this->x - other.x; res.y = this->y - other.y; return res; } __device__ Vec2 operator+(Vec2 other) { Vec2 res; res.x = this->x + other.x; res.y = this->y + other.y; return res; } __device__ Vec2 operator*(float d) { Vec2 res; res.x = this->x * d; res.y = this->y * d; return res; } }; struct Color3f { float R = 0.0f; float G = 0.0f; float B = 0.0f; __host__ __device__ Color3f operator+ (Color3f other) { Color3f res; res.R = this->R + other.R; res.G = this->G + other.G; res.B = this->B + other.B; return res; } __host__ __device__ Color3f operator* (float d) { Color3f res; res.R = this->R * d; res.G = this->G * d; res.B = this->B * d; return res; } }; struct Particle { Vec2 u;
方法名称前面的
__host__属性意味着可以在CPU
__device__上执行代码,相反,这迫使编译器必须在GPU下收集代码。 该代码声明了用于与两个分量的矢量,颜色,具有可在运行时更改的参数的配置一起使用的原语,以及几个指向数组的静态指针,我们将它们用作计算的缓冲区。
cudaInit和
cudaExit的定义也很简单:
kernel.cu(init) void cudaInit(size_t x, size_t y) { setConfig(); colorArray[0] = { 1.0f, 0.0f, 0.0f }; colorArray[1] = { 0.0f, 1.0f, 0.0f }; colorArray[2] = { 1.0f, 0.0f, 1.0f }; colorArray[3] = { 1.0f, 1.0f, 0.0f }; colorArray[4] = { 0.0f, 1.0f, 1.0f }; colorArray[5] = { 1.0f, 0.0f, 1.0f }; colorArray[6] = { 1.0f, 0.5f, 0.3f }; int idx = rand() % colorArraySize; currentColor = colorArray[idx]; xSize = x, ySize = y; cudaSetDevice(0); cudaMalloc(&colorField, xSize * ySize * 4 * sizeof(uint8_t)); cudaMalloc(&oldField, xSize * ySize * sizeof(Particle)); cudaMalloc(&newField, xSize * ySize * sizeof(Particle)); cudaMalloc(&pressureOld, xSize * ySize * sizeof(float)); cudaMalloc(&pressureNew, xSize * ySize * sizeof(float)); cudaMalloc(&vorticityField, xSize * ySize * sizeof(float)); } void cudaExit() { cudaFree(colorField); cudaFree(oldField); cudaFree(newField); cudaFree(pressureOld); cudaFree(pressureNew); cudaFree(vorticityField); }
在初始化函数中,我们为二维数组分配内存,指定将用于绘制液体的颜色数组,并在配置中设置默认值。 在
cudaExit中,我们只是释放所有缓冲区。 听起来很矛盾,对于存储二维数组,使用一维数组是最有利的,将使用以下表达式进行访问:
array[y * size_x + x];
我们开始使用粒子运动函数来实现直接算法。 字段
oldField和
newField (数据
来自的字段以及将数据写入的字段),数组的大小以及时间增量和密度系数(用于加速染料在液体中的溶解并使介质对
平移不太敏感
)被转移到
平移中用户操作)。
双线性插值函数
是通过计算中间值以经典方式实现的:
决定将粘度扩散函数分为几部分:从主代码调用
computeDiffusion ,该函数将
diffuse和
computeColor调用预定的次数,然后从获取数据的位置交换数组并从写入数据的位置交换数组。 这是实现并行数据处理的最简单方法,但是我们要花两倍的内存。
这两个函数都会导致Jacobi方法的变化。
jacobiColor和
jacobiVelocity的主体
会立即检查当前元素是否不在边界上-在这种情况下,我们必须根据“
边界和初始条件”部分所述的公式进行设置。
外力的使用是通过单个函数
applyForce实现的 ,该函数将鼠标的位置,染料的颜色以及作用半径作为参数。 有了它的帮助,我们可以提高粒子的速度,并对它们进行绘制。 兄弟指数使您可以使区域不太尖锐,同时在指定半径内也非常清晰。
涡度的计算已经是一个更加复杂的过程,因此我们在
computeVorticity和
applyVorticity中实现它,我们还注意到,对于它们,有必要定义两个这样的矢量运算符,例如
curl (转子)和
absGradient (绝对场值的梯度)。 为了指定其他涡旋效应,我们乘以
y 上的梯度向量的分量
−1 ,然后通过除以长度对其进行归一化(不要忘记检查向量是否为非零):
该算法的下一步将是计算标量压力场及其在速度场上的投影。 为此,我们需要实现4个功能:
divergence (将考虑速度差异),
jacobiPressure (实现用于压力的Jacobi方法)以及带有
computePressureImpl的computePressure (执行迭代字段计算):
投影适合两个小功能-
投影和
需要压力的
渐变 。 这可以说是我们仿真算法的最后阶段:
投影之后,我们可以安全地将图像渲染到缓冲区和各种后效果。
绘制功能将颜色从粒子场复制到RGBA阵列。 此外,还实现了
applyBloom函数,当将光标
置于其上并按下鼠标按钮时,该函数会突出显示液体。 从经验来看,这种技术使图片对于用户的眼睛来说更加愉悦和有趣,但是根本没有必要。
在后期处理中,您还可以突出显示流体速度最快的位置,根据运动矢量更改颜色,添加各种效果等,但是在我们的情况下,我们将自身限制在最低限度,因为即使这样,图像也非常迷人(尤其是动态变化) :
最后,我们还有一个主要函数,可以从
main.cpp -
computeField调用。 它将算法的所有部分链接在一起,调用视频卡上的代码,还将数据从gpu复制到cpu。 它还包含动量矢量的计算和染料颜色的选择,我们将其传递给
applyForce :
结论
在本文中,我们分析了用于求解Navier-Stokes方程的数值算法,并为不可压缩的流体编写了一个小型仿真程序。 也许我们并不了解所有的复杂性,但我希望该材料对您来说有趣而有用,至少可以作为流体建模领域的一个很好的介绍。
作为本文的作者,我将衷心感谢您的任何评论和补充,并将尝试回答您在本文下的所有问题。
附加材料
您可以在我的
Github存储库中找到本文中的所有源代码。 欢迎提出任何改进建议。
您可以在Nvidia的官方网站上阅读用作本文基础的原始材料。 它还提供了用着色器语言实现算法各部分的示例:
developer.download.nvidia.com/books/HTML/gpugems/gpugems_ch38.html本书中可以找到亥姆霍兹分解定理的证明以及有关流体力学的大量其他材料(英语,请参见第1.2节):
Chorin,AJ和JE Marsden。 1993年。《流体力学数学导论》。 第三版。 施普林格一个讲英语的YouTube的频道,制作与数学相关的高质量内容,尤其是求解微分方程(英语)。以帮助十分生动的视频,你明白很多事情在数学和物理学的本质:3Blue1Brown - YouTube的微分方程(3Blue1Brown)也感谢WhiteBlackGoose在准备材料本文援助。
最后,还有一点好处-在程序中拍摄了一些漂亮的屏幕截图: 直接流(默认设置)
直接流(默认设置) 漩涡(applyForce中的大半径)
漩涡(applyForce中的大半径) 波浪(高涡度+扩散)此外,根据受欢迎的需求,我添加了带有模拟的视频:
波浪(高涡度+扩散)此外,根据受欢迎的需求,我添加了带有模拟的视频: