我编写的Sloc Cloc and Code(scc)命令行
工具现已完成,并得到了很多人的支持,它计算了代码行,注释并评估了目录中文件的复杂性。 这里需要一个很好的选择。 该工具计算代码中的分支运算符。 但是什么是复杂性? 例如,如果没有上下文,语句“此文件的难度为10”不是很有用。 为了解决这个问题,我在Internet上的所有来源上运行了
scc 。 这也将使您找到我在工具本身中未考虑的一些极端情况。 强大的蛮力测试。
但是,如果我要对世界上所有来源进行测试,则将需要大量的计算资源,这也是一种有趣的体验。 因此,我决定将所有内容都写下来-并出现了这篇文章。
简而言之,我下载并处理了许多资源。
裸体人物:
- 总库9,985,051
- 9,100,083个存储库,至少包含一个文件
- 884968空存储库(无文件)
- 所有存储库中有3,500,000,000个文件
- 已处理40736530379379778字节(40 TB)
- 确定了1,086,723,618,560行
- 816,822,273,469行已识别代码
- 124382152510空白行
- 145519192581评论行
- 根据scc规则的总复杂度: 71884867919
- scc中发现2个新错误
我们只说一个细节。 如高调的标题所示,没有1000万个项目。 我错过了15,000,所以我将其四舍五入。 我为此表示歉意。
下载所有内容,通过scc并保存所有数据大约花费了五个星期。 然后,要花费49多小时来处理1 TB JSON,并获得以下结果。
另请注意,在某些计算中我可能会弄错。 如果检测到任何错误,我会立即通知您,并提供数据集。
目录
方法论
自启动
searchcode.com以来
,我已经在git,mercurial,subversion等方面积累了超过7,000,000个项目的集合。 那么为什么不处理它们呢? 使用git通常是最简单的解决方案,因此这次我忽略了Mercury和Subversion,并导出了git项目的完整列表。 事实证明,我实际上跟踪了1200万个git存储库,并且可能需要刷新主页以反映这一点。
因此,现在我有1200万个git存储库可供下载和处理。
运行scc时,可以选择JSON格式的输出并将文件保存到磁盘:
scc --format json --output myfile.json main.go 结果如下(对于单个文件):
[ { "Blank": 115, "Bytes": 0, "Code": 423, "Comment": 30, "Complexity": 40, "Count": 1, "Files": [ { "Binary": false, "Blank": 115, "Bytes": 20396, "Callback": null, "Code": 423, "Comment": 30, "Complexity": 40, "Content": null, "Extension": "go", "Filename": "main.go", "Hash": null, "Language": "Go", "Lines": 568, "Location": "main.go", "PossibleLanguages": [ "Go" ], "WeightedComplexity": 0 } ], "Lines": 568, "Name": "Go", "WeightedComplexity": 0 } ]
有关更大的示例,请参见redis项目的结果:
redis.json 。 下面的所有结果都是从这种结果中获得的,没有任何其他数据。
应该记住,scc通常根据扩展名对语言进行分类(除非扩展名是通用的,例如Verilog和Coq)。 因此,如果您保存带有Java扩展名的HTML文件,它将被视为Java文件。 通常这不是问题,因为为什么这样做? 但是,当然,在很大程度上,这个问题变得很明显。 后来,当某些文件伪装成其他扩展名时,我才发现了这一点。
前段时间,我编写了
用于生成基于scc的github标记的代码 。 由于该过程需要缓存结果,因此我对其进行了一些更改,以便在AWS S3上以JSON格式缓存它们。
借助lambda上AWS上标签的代码,我导出了一个项目列表,编写了约15行python来清除格式以匹配我的lambda,并提出了要求。 使用python多处理,我将请求并行化为32个进程,以便端点足够迅速地响应。
一切都很棒。 但是,问题在于,首先是成本问题,其次,lambda的API网关/ ALB超时了30秒,因此无法足够快地处理大型存储库。 我知道这不是最经济的解决方案,但我认为价格约为100美元,我可以忍受。 处理完一百万个存储库后,我检查了-成本约为60美元。 由于我对最终的700美元AWS账户的前景不满意,因此我决定重新考虑自己的决定。 请记住,这基本上是用于收集所有这些信息的存储和CPU。 任何数据的处理和导出都会大大提高价格。
因为我已经在AWS上,所以一种快速的解决方案是将URL作为SQS中的消息删除,并使用EC2或Fargate实例将其拉出进行处理。 然后像疯了一样缩放。 尽管有AWS的日常经验,但我始终相信
Taco Bell编程的
原理 。 此外,只有1200万个存储库,因此我决定实施一个更简单(更便宜)的解决方案。
由于澳大利亚的互联网糟糕,因此无法在本地启动计算。 但是,我的searchcode.com会谨慎使用Hetzner的专用服务器。 这些是功能强大的i7 Quad Core 32 GB RAM计算机,通常具有2 TB的存储空间(通常不使用)。 它们通常具有良好的计算能力。 例如,前端服务器大部分时间都计算零的平方根。 那么,为什么不在那里开始处理呢?
这不是真正的Taco Bell编程,因为我使用了bash和gnu工具。 我
在Go上编写了一个
简单的程序,以运行32个例程,这些例程从通道读取数据,生成git和scc子进程,然后再将输出写入S3中的JSON。 我实际上是首先用Python编写解决方案的,但是在干净的服务器上安装pip依赖项的需求似乎是一个坏主意,并且系统以我不想调试的奇怪方式崩溃。
在服务器上运行所有这些操作会在htop中产生以下指标,并且几个正在运行的git / scc进程(此屏幕快照中未显示scc)假定一切都按预期工作,这在S3中得到了证实。

展示和计算结果
我最近阅读了
这些 文章 ,所以我有一个主意,可以借用这些帖子的格式来表示信息。 但是,我还想将
jQuery DataTables添加到大型表中以对结果进行排序和搜索/过滤。 因此,在
原始文章中,您可以单击标题进行排序,并使用搜索字段进行过滤。
需要处理的数据大小提出了另一个问题。 如何处理1000万个JSON文件,它们在S3存储桶中占用的磁盘空间略大于1 TB?
首先想到的是AWS Athena。 但是由于这种数据集
每次查询的成本约为2.50
美元 ,因此我迅速开始寻找替代方案。 但是,如果将数据保存在那里并且很少处理,那么这可能是最便宜的解决方案。
我在公司聊天中发布了一个问题(为什么要单独解决问题)。
一种想法是将数据转储到大型SQL数据库中。 但是,这意味着处理数据库中的数据,然后对它执行几次查询。 另外,数据结构意味着多个表,这意味着外键和索引可提供一定程度的性能。 这似乎很浪费,因为我们可以一口气地处理从磁盘读取的数据。 我也担心创建这么大的数据库。 仅使用数据时,添加索引之前其大小将超过1 TB。
我想看到如何以简单的方式创建JSON,为什么不以相同的方式处理结果? 当然,有一个问题。 从S3中提取1 TB数据将花费很多。 如果程序崩溃,那将很烦人。 为了降低成本,我想在本地提取所有文件并将其保存以供进一步处理。 好的建议:最好不要
在一个目录中存储
许多小文件 。 这会降低运行时性能,而文件系统则不喜欢这样。
我的答案是另一个简单的
Go程序 ,该
程序可以从S3中提取文件,然后将其保存在tar文件中。 然后,我可以一次又一次地处理此文件。 该过程本身运行一个
非常难看的 Go程序来处理tar文件,因此我可以重新运行查询,而不必一次又一次从S3中提取数据。 我没有在这里使用go例程,这有两个原因。 首先,我不想尽可能多地加载服务器,因此我将自己限制在一个内核上,以使CPU能够正常工作(另一个内核通常锁定在处理器上以读取tar文件)。 其次,我想保证线程安全。
完成此操作后,需要回答一系列问题。 当我提出自己的想法时,我再次运用了集体的思想并与同事建立了联系。 这种融合思想的结果如下。
您可以找到我用来处理JSON的
所有代码 ,包括用于本地处理的代码,以及用来准备对本文有用的东西的
丑陋的Python脚本 :请不要对此发表评论,我知道代码很丑陋,它是为一次性任务编写的,因为我不太可能再看一遍。
如果要查看我编写的通用代码,请查看
scc来源 。
费用
尝试使用Lambda时,我在计算上花费了大约60美元。 我还没有看过存储S3的成本,但是根据数据的大小,它应该接近25美元。 但是,这不包括传输成本,我也没有看过。 请注意,我在用完水桶后便将其清洗干净,因此这不是固定费用。
但是一段时间后,我仍然放弃了AWS。 那么,如果我想再做一次,实际费用是多少?
我们拥有的所有软件都是免费的和免费的。 因此,无需担心。
就我而言,成本是零,因为我使用了searchcode.com留下的“免费”计算能力。 但是,并非每个人都有这样的免费资源。 因此,我们假设其他人想要重复此操作,并且必须举起服务器。
使用
Hetzner最便宜的新型
专用服务器 (包括安装新服务器的成本),即可以73欧元的价格完成此任务。 如果您等待并深入研究
拍卖部分 ,则可以找到便宜得多的服务器,而无需支付安装费用。 在撰写本文时,我发现了一款非常适合该项目的汽车,每月25.21欧元,无安装费。
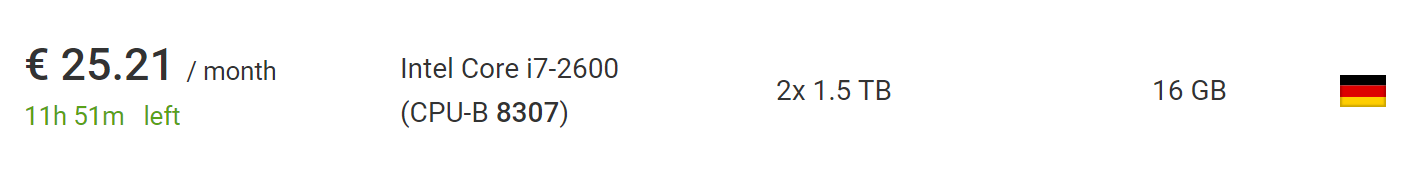
更好的是,在欧盟以外,增值税将从此价格中扣除,因此您可以再收取10%的税。
因此,如果您在我的软件上从头开始提供此类服务,则如果您有一点耐心或成功的话,它将最终花费高达100美元,而不是多达50美元。 假设您使用服务器的时间少于两个月,足以进行下载和处理。 还有足够的时间来获取1000万个存储库的列表。
如果使用压缩的tar(实际上并不那么困难),则我可以在同一台计算机上处理10倍以上的存储库,并且生成的文件仍将保持足够小以适合同一HDD。 尽管此过程可能需要几个月,但因为下载会花费更长的时间。
但是,要远远超过1亿个存储库,就需要某种分片。 不过,可以肯定地说,您将在相同的设备上以我的规模或更大的规模重复此过程,而无需花费太多精力或更改代码。
资料来源
以下是来自以下三个来源的每个项目的数量:github,bitbucket和gitlab。 请注意,这是在排除空存储库之前,因此,该数量超出了下表中实际处理并考虑的存储库数量。
如果您阅读这篇文章,我向GitHub / Bitbucket / GitLab员工道歉。 如果我的剧本引起了任何问题(尽管我对此表示怀疑),那么在遇见我时,我可以选择喝一杯。
存储库中有多少个文件?
让我们继续讨论实际问题。 让我们从一个简单的开始。 平均存储库中有多少个文件? 大多数项目只有几个文件或更多文件? 遍历存储库后,我们得到以下时间表:

在此,x轴显示具有文件数量的存储桶,y轴显示具有许多文件的项目数量。 将水平轴限制为一千个文件,因为图形太靠近轴了。
似乎大多数存储库的文件少于200个。
但是,可视化到第95个百分位会显示真实图片呢? 事实证明,在绝大多数(95%)项目中-少于1000个文件。 90%的项目文件少于300个,而85%的文件少于200个。

如果您想自己构建一个图表并且比我做得更好,这是
指向JSON中原始数据的
链接 。
语言分类是什么?
例如,如果标识了Java文件,则我们将项目中的Java数量增加一个,而对第二个文件则不执行任何操作。 这样可以快速了解最常用的语言。 毫不奇怪,最常见的语言包括markdown,.gitignore和纯文本。
Markdown是最常用的语言;在超过600万个项目中都可以看到,大约占总数的2⁄3。 这是有道理的,因为几乎所有项目都包含README.md,该文件以HTML格式显示在存储库页面中。
按语言在存储库中有多少个文件?
除上表外,但按存储库中每种语言的文件数平均。 也就是说,存在Java的所有项目平均存在多少个Java文件?
典型的语言文件中有几行代码?
我认为仍然有趣的是,平均来看哪些语言的文件最多?使用算术平均值会由于sqlite.c之类的项目而产生异常高的数字,该项目包含在许多存储库中,将许多文件合并为一个文件,但是没人能处理这个大文件(我希望!)因此,我计算了中位数的平均值。但是,仍然具有很高的价值的语言,例如Bosque和JavaScript。所以我想,为什么不采取骑士行动呢?在Darrell(Kablamo居民和出色的数据科学家)的建议下,我做了一个小小的更改,并更改了算术平均值,删除了5,000行以上的文件以消除异常。每种语言的平均文件复杂度?
每种语言的平均文件复杂度是多少?实际上,复杂度评估不能直接在语言之间进行比较。自述文件摘录scc:复杂度分数只是一个数字,只能在使用相同语言的文件之间进行匹配。它不应用于直接比较语言。原因是它是通过为每个文件查找分支和循环运算符来计算的。
因此,尽管这里可以在类似的语言(例如Java和C)之间进行比较,但语言在这里不能相互比较。对于使用相同语言的单个文件,这是更有价值的指标。因此,您可以回答以下问题:“我正在使用的文件比普通文件更容易或更难?”我不得不提到,我将对在scc中改进此指标的建议感到满意。对于一次提交,通常只需在languages.json文件中添加几个关键字就足够了,因此任何程序员都可以提供帮助。每种语言的文件平均注释数?
每种语言的文件中平均注释数是多少?也许这个问题可以改写:用语言写的开发人员最多的评论,暗示读者的误解。最常见的文件名是什么?
忽略扩展名和大小写,所有代码库中最常见的文件名是什么?如果您早些时候问我,我会说:自述文件,主要文件,索引,许可证。结果很好地反映了我的假设。虽然有很多有趣的事情。我不知道为什么这么多项目包含一个名为15或的文件s15。最常见的makefile令我有些惊讶,但是后来我想起它在许多新的JavaScript项目中都使用过。需要注意的另一件有趣的事情:jQuery似乎仍在继续发展,其死亡的报道被大大夸大了,他名列第四。请注意,由于内存限制,此过程的准确性有所降低。在每100个项目中,我检查了地图,并从列表中删除了少于10次的文件名。他们可以返回下一个测试,并且如果遇到10次以上,他们将继续留在名单上。如果某些通用名称在变得通用之前很少出现在第一批存储库中,则某些结果可能会出错。简而言之,这些不是绝对数字,但应该足够接近它们。我可以使用前缀树来“压缩”空间并获取绝对数字,但是我不想编写它,因此我略微滥用了地图以节省足够的内存并获取结果。但是,稍后尝试前缀树将非常有趣。有多少存储库缺少许可证?
这很有趣。多少个存储库至少具有一些显式许可证文件?请注意,此处缺少许可证文件并不表示该项目没有该文件,因为它可以存在于README文件中,也可以通过SPDX注释标记显示。这只是意味着scc它无法使用其自己的条件来找到显式许可证文件。当前,此类文件被认为是“许可证”,“许可证”,“复制”,“ copying3”,“无许可证”,“无许可证”,“许可证许可证”,“许可证许可证”或“版权”。不幸的是,绝大多数存储库没有许可证。我会说为什么任何软件都需要许可证有很多原因,但是其他人为我说了许可证。
多少个项目使用多个.gitignore文件?
有些人可能不知道这一点,但是git项目中可能有几个.gitignore文件。考虑到这一点,有多少项目使用多个.gitignore文件?同时,有几个没有一个?我在存储库中找到了一个相当有趣的项目,其中包含25794个.gitignore文件。下一个结果是2547。我不知道发生了什么。我简短地看了一眼:看起来它们好像是用来检查目录的,但是我无法确认。返回到数据,这是一个带有最多20个.gitignore文件的存储库图,它覆盖了所有项目的99%。 不出所料,大多数项目都有0或1个.gitignore文件。带有2个文件的项目数量下降了十倍,这证实了这一点,令我惊讶的是,有多少个项目具有多个.gitignore文件。在这种情况下,长尾巴特别长。我很好奇为什么有些项目有成千上万个这样的文件。主要的麻烦制造者之一是派生https://github.com/PhantomX/slackbuilds:每个分支都有大约2547个.gitignore文件。下面列出了具有一千多个.gitignore文件的其他存储库。
不出所料,大多数项目都有0或1个.gitignore文件。带有2个文件的项目数量下降了十倍,这证实了这一点,令我惊讶的是,有多少个项目具有多个.gitignore文件。在这种情况下,长尾巴特别长。我很好奇为什么有些项目有成千上万个这样的文件。主要的麻烦制造者之一是派生https://github.com/PhantomX/slackbuilds:每个分支都有大约2547个.gitignore文件。下面列出了具有一千多个.gitignore文件的其他存储库。?
本节不是一门精确的科学,而是属于自然语言处理的问题类别。在特定文件列表中搜索辱骂或辱骂术语永远不会有效。如果使用简单搜索进行搜索,则会发现许多普通文件assemble.sh,诸如此类。因此,我列出了一个curses列表,然后检查每个项目中是否有任何文件以这些值之一开头,后跟一个点。这意味着gangbang.java将考虑但assemble.sh不考虑命名的文件。但是,他将错过许多不同的选择,例如pu55syg4rgle.java其他同样粗鲁的名字。我的清单上有一些关于leetspeak的单词,例如b00bs和b1tch,以捕捉一些有趣的情况。完整清单在这里。如前所述,尽管这并不完全准确,但查看结果却非常有趣。让我们从诅咒最多的语言列表开始。可能应该将结果与每种语言的代码总数相关联。所以这是领导人。有趣!我的第一个想法是:“哦,这些顽皮的C开发人员!” 但是,尽管此类文件数量很多,但它们编写的代码太多,以致于诅咒在总金额中所占的百分比丢失了。但是,很明显,Dart开发人员的武器库中有几句话!如果您认识Dart程序员之一,则可以握手。我也想知道最常用的诅咒是什么。让我们看一个共同的肮脏的集体思想。我发现一些最好的名字是普通名字(如果您着眼睛看),但是大多数其他名字肯定会让同事感到惊讶,并在合并请求中提出了一些意见。请注意,列表中一些更令人反感的词的确具有匹配的文件名,我感到非常震惊。幸运的是,它们不是很常见,也没有包含在上面的列表中,该列表仅限于数量超过100个的文件。我希望这些文件仅用于测试允许/拒绝列表等。按每种语言的行数最多的文件
不出所料,纯文本,SQL,XML,JSON和CSV占据了头等位置:它们通常包含元数据,数据库转储等。注意事项 创建文件时,由于某些其他信息,下面的某些链接可能不起作用。大多数都可以,但是对于某些情况,您可能需要稍微修改URL。每种语言中最复杂的文件是什么?
同样,这些值不能彼此直接比较,但是很有趣的是,每种语言都认为最困难的是什么。这些文件中有些是绝对的怪物。例如,考虑一下我找到的最复杂的C ++文件:COLLADASaxFWLColladaParserAutoGen15PrivateValidation.cpp:它是28.3兆字节的编译器地狱(而且幸运的是,它似乎是自动生成的)。注意事项 创建文件时,由于某些其他信息,下面的某些链接可能不起作用。大多数都可以,但是对于某些情况,您可能需要稍微修改URL。关于行数最复杂的文件?
从理论上讲,这听起来不错,但实际上...缩小或没有换行符的内容会使结果失真,从而使它们毫无意义。因此,我不发布计算结果。不过,我创建了一个票在scc支持微小的检测是从计算结果中删除。您可能可以根据可用数据得出一些结论,但是我希望所有用户都能从此功能中受益scc。每种语言中评论最多的文件是什么?
我不知道您可以从中提取什么有价值的信息,但是很有趣。注意事项 创建文件时,由于某些其他信息,下面的某些链接可能不起作用。大多数都可以,但是对于某些情况,您可能需要稍微修改URL。多少个“清洁”项目
在“纯”项下的项目类型完全是一种语言。当然,这本身并不是很有趣,所以让我们从上下文中来看它们。事实证明,绝大多数项目的语言少于25种,大多数项目的语言少于10种。下图中的峰用四种语言表示。当然,在干净的项目中只能有一种编程语言,但是支持其他格式,例如markdown,json,yml,css,.gitignore scc。假设任何使用少于五种语言的项目都是“干净的”(对于某种程度的清洁度),这可能是合理的,并且这仅占整个数据集的一半以上。当然,您对清洁度的定义可能不同于我的定义,因此您可以专注于自己喜欢的任何数字。让我惊讶的是,围绕34-35种语言的语言出现了奇怪的增长。对于它的来源,我没有合理的解释,这可能值得单独调查。
使用TypeScript但不使用JavaScript的项目
啊,TypeScript的现代世界。但是对于TypeScript项目,有多少纯粹是这种语言?我必须承认,这个数字让我有些惊讶。尽管我知道将JavaScript与TypeScript混合使用是相当普遍的,但我认为将会有更多使用新语言的项目。但是,更新的存储库集可能会大大增加其数量。有人使用CoffeeScript和TypeScript吗?
我觉得有些TypeScript开发人员对此一无所知。如果这对他们有帮助,我可以假定这些项目大多数都是程序,例如scc带有用于测试目的的所有语言的示例。每种语言的典型路径长度是多少
鉴于您可以将所需的所有文件上传到一个目录中或创建目录系统,典型的路径长度和目录数是多少?为此,请对每个文件的路径中的斜杠数和平均值进行计数。我不知道在这里会发生什么,除了Java可能位于列表的顶部,因为通常文件路径很长。是YAML还是YML?
在Slack曾经有一次“讨论”-使用.yaml或.yml。双方都有许多人被杀。辩论可能最终(?)结束。尽管我怀疑有些人还是会死于争执。大写,小写还是混合大小写?
文件名使用什么寄存器?由于仍然存在扩展,因此我们可以预期主要是混合情况。当然,这不是很有趣,因为通常文件扩展名是小写的。如果忽略扩展名怎么办?不是我所期望的。同样,大多数情况是混合的,但我会认为底层会更受欢迎。Java工厂
同事在查看一些旧的Java代码时想到的另一个想法。我以为,为什么不对标题中出现Factory,FactoryFactory或FactoryFactoryFactory的任何Java代码添加检查。这个想法是估计这种工厂的数量。因此,只有2%以上的Java代码是工厂或工厂。幸运的是,没有找到工厂。尽管我确信至少有一个严肃的三级递归多工厂仍然可以在某种Java 5整体模型中运行,并且每天赚到的钱比我整个职业生涯中所赚的钱还多,但这个笑话也许最终会消失。 。。忽略文件
.ignore文件的概念由burntsushi和ggreer在“黑客新闻”的讨论中提出。也许这是“竞争”开放源代码工具的最佳示例之一,这些工具可以很好地结合在一起并在创纪录的时间内完成。它已成为添加工具将忽略的代码的事实上的标准。scc也符合.ignore规则,但也知道如何计算它们。让我们看看这个想法传播得如何。未来的想法
我喜欢对未来做一些分析。扫描AWS AKIA密钥之类的东西将非常好。我还想通过对每个项目的分析来扩大Bitbucket和Gitlab项目的覆盖范围,以查看是否可能存在来自不同领域的开发团队。如果我重复这个项目,我想克服以下缺点,并考虑以下想法。- 将URL正确存储在元数据中的某个位置。使用文件名存储它不是一个好主意,因为信息会丢失,并且可能很难确定文件的来源和位置。
- 不要理会S3。如果仅将其用于存储,则为流量付费几乎没有意义。从一开始就将所有内容锤打成tar文件会更好。
- , .
- -n , , , .
- scc, , . , CIDE.C C, , HTML. .
- , scc, , , . .
- 我想对scc添加一个shebang检测。
- 最好考虑一下Github上的星星数和提交数。
- 我想以某种方式添加可维护性指标计算。很高兴看到哪些项目根据其大小被认为是最可修复的。
为什么这一切呢?
好吧,我可以获取其中一些信息,并将其用于searchcode.com搜索引擎和program中scc。至少有一些有用的数据点。最初,该项目是通过多种方式构想的。另外,将您的项目与其他项目进行比较非常有用。花几天时间解决一些有趣的问题也是一种有趣的方式。并进行了良好的可靠性检查scc。另外,我目前正在开发一种工具,可以帮助领先的开发人员或管理人员分析代码,搜索特定的语言,大文件,缺陷等。...假设您需要分析多个存储库。您输入某种代码,该工具将说明它的可维护性以及维护它所需的技能。在决定是否购买某种代码库,为其提供服务或获得开发团队给出的有关您自己的产品的想法时,这很有用。从理论上讲,这应该有助于团队通过共享资源进行扩展。类似于AWS Macie,但需要代码-我正在研究类似的东西。我本人在日常工作中需要此工具,并且我怀疑其他人可能会找到这种工具的应用,至少是理论上如此。对于那些有兴趣的人来说,也许值得在这里进行某种形式的注册。未处理/已处理的文件
如果有人要进行自己的分析并进行更正,请访问以下链接到已处理文件(20 MB)。如果有人想在公共领域发布原始文件,请告诉我。这是83 GB的tar.gz,内部刚好超过1 TB。内容包含超过900万个各种大小的JSON文件。UPD
建议几个好心人放置文件,这些位置如下所示:托管该文件的tar.gz感谢CNCF服务器xet7项目Wekan。