Zabbix是一个监视系统。 与任何其他系统一样,它面临所有监视系统的三个主要问题:数据收集和处理,历史记录存储及其清理。
获取,处理和记录数据的步骤需要时间。 数量不多,但是对于大型系统,这可能会导致较大的延迟。 存储问题是数据访问问题。 它们用于报告,检查和触发器。 访问数据的延迟也会影响性能。 当数据库增长时,必须删除无关的数据。 删除是一项困难的操作,它也消耗了一些资源。

通过缓存解决了Zabbix收集和存储过程中的延迟问题:几种类型的缓存,数据库中的缓存。 为了解决第三个问题,缓存不适合,因此,Zabbix使用了TimescaleDB。
Zabbix SIA的技术支持工程师
Andrey Gushchin将对此进行讨论。 Andrey支持Zabbix已有6年以上,并且直接面对性能。
与常规PostgreSQL相比,TimescaleDB如何工作,可以提供什么样的性能? Zabbix在TimescaleDB中扮演什么角色? 如何从头开始运行以及如何与PostgreSQL一起迁移以及哪种性能更好? 关于这一切的削减。
性能挑战
每个监视系统都面临特定的性能挑战。 我将讨论其中三个:收集和处理数据,存储,清理历史记录。
快速的数据收集和处理。 一个好的监视系统应迅速接收所有数据并根据触发表达式(根据其自身的标准)对其进行处理。 处理后,系统还应快速将此数据保存到数据库中,以便以后使用。
保持故事。 一个好的监视系统应将历史记录存储在数据库中,并提供对度量的方便访问。 需要一个故事才能在报告,图表,触发器,阈值和计算出的警报数据项中使用它。
清除历史记录。 有时会有一天不需要存储指标。 为什么需要5年前(一个月或两个月)收集的数据:删除了一些节点,不再需要某些主机或指标,因为它们已经过时并停止了收集。 一个好的监视系统应该存储历史数据并不时删除它,以免数据库增长。
清除过时的数据是一个热门问题,对数据库性能有很大影响。
Zabbix缓存
在Zabbix中,使用缓存解决了第一个和第二个调用。 RAM用于数据收集和处理。 用于存储-触发器,图形和计算的数据元素中的故事。 在数据库方面,主要样本(例如图表)有一定的缓存。
Zabbix服务器本身的缓存是:
- ConfigurationCache;
- ValueCache;
- HistoryCache;
- TrendsCache。
让我们更详细地考虑它们。
配置缓存
这是主要的缓存,我们在其中存储指标,主机,数据项,触发器-预处理和收集数据所需的一切。
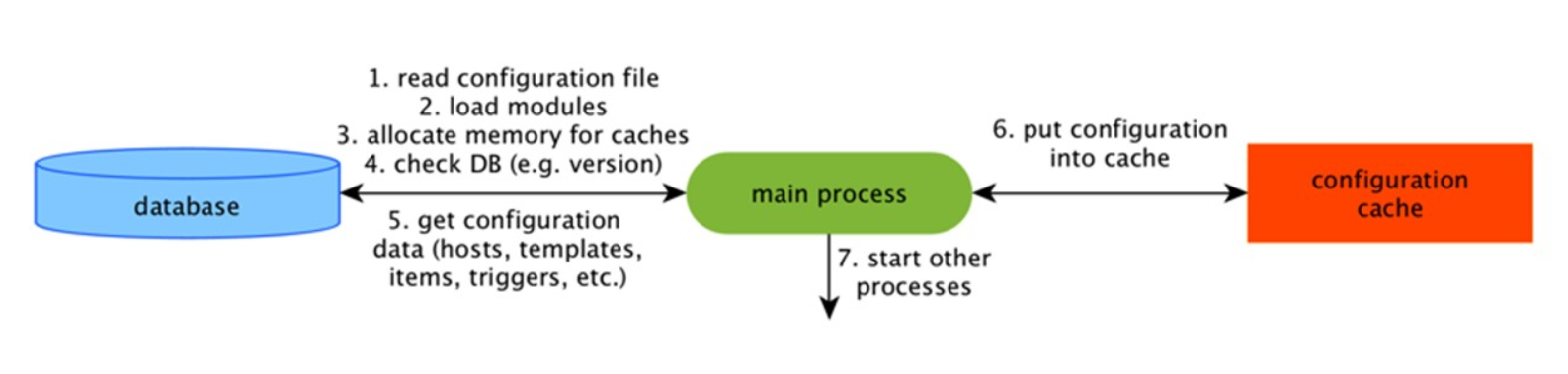
所有这些都存储在ConfigurationCache中,以免在数据库中创建不必要的查询。 服务器启动后,我们将更新此缓存,创建并定期更新配置。
资料收集
该方案相当大,但其中的主要内容是
汇编程序 。 这些是各种“轮询器”-组装过程。 他们负责不同类型的组装:他们通过SNMP,IPMI收集数据,并将其全部传输到预处理。
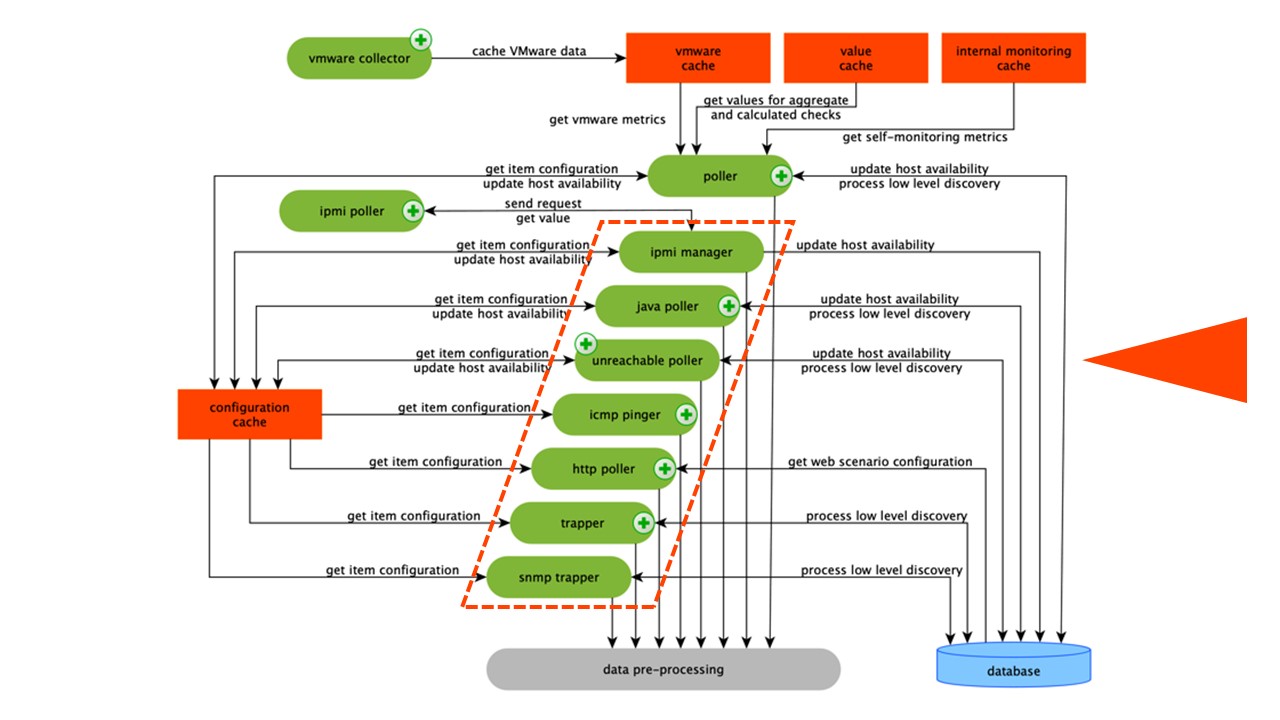 收藏家用橙色圈出。
收藏家用橙色圈出。Zabbix已计算出汇总验证所需的汇总数据元素。 如果有它们,我们将直接从ValueCache中获取它们的数据。
预处理HistoryCache
所有收集器都使用ConfigurationCache接收作业。 然后他们将它们传递给预处理。

预处理使用ConfigurationCache接收预处理步骤。 它以各种方式处理此数据。
使用预处理处理数据后,我们将其保存在HistoryCache中进行处理。 这样就结束了数据收集,我们进入Zabbix的主要过程-
历史同步器 ,因为它是一个整体架构。
注意:预处理是相当困难的操作。 从v 4.2开始,它已提交给代理。 如果您的Zabbix很大,并且具有大量数据元素,并且收集频率很高,那么这将大大简化工作。ValueCache,历史和趋势缓存
历史记录同步器是原子处理每个数据元素(即每个值)的主要过程。
历史记录同步器从HistoryCache中获取值,并在“配置”中检查计算触发器。 如果是,它将进行计算。
历史记录同步器将创建事件,并升级以创建警报(如果配置需要)和记录。 如果存在用于后续处理的触发器,则他会在ValueCache中记住该值,以免访问历史表。 因此,ValueCache充满了计算触发器和计算元素所需的数据。
历史记录同步器将所有数据写入数据库,然后将其写入磁盘。 处理过程到此结束。
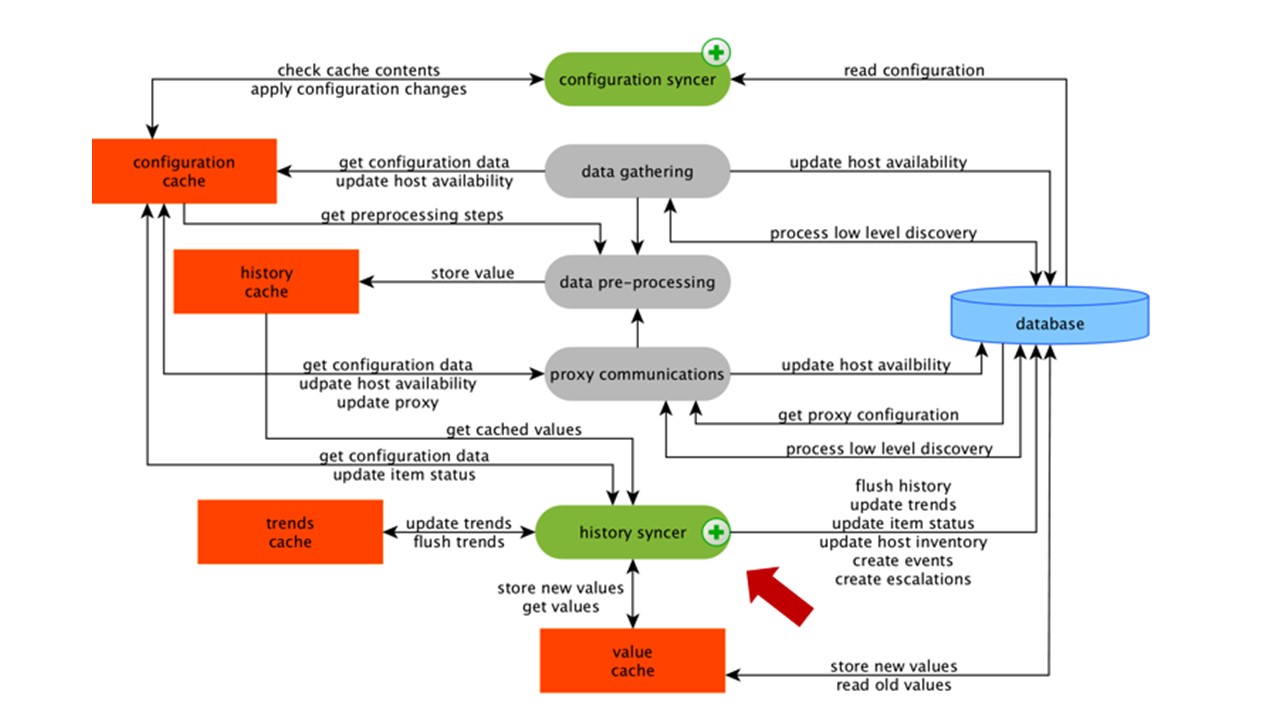
数据库缓存
在数据库方面,当您要观看图形或事件报告时,有各种缓存:
- MySQL端的
Innodb_buffer_pool ; shared_buffers上的shared_buffers ;- 在Oracle方面的
effective_cache_size ; - DB2端的
shared_pool 。
还有许多其他缓存,但是这些是所有数据库的主要缓存。 它们使您可以将查询经常需要的数据保留在内存中。 他们为此拥有自己的技术。
数据库性能至关重要
Zabbix服务器不断收集数据并将其写入。 重新启动时,它还会从历史记录中读取以填充ValueCache。 脚本和报告使用基于Web界面构建的
Zabbix API 。 Zabbix API与数据库联系,并接收图形,报告,事件列表和最新问题所需的数据。
对于可视化
-Grafana 。 在我们的用户中,这是一种流行的解决方案。 它可以直接通过Zabbix API发送请求并将其发送到数据库,并在接收数据方面具有一定的竞争力。 因此,我们需要对数据库进行更好,更好的调整,以与结果和测试的快速输出相对应。
管家
Zabbix中的第三个性能挑战是与管家一起清除历史。 它遵循所有设置-数据元素指示要保持多少天的动态变化(趋势)。
我们可以动态计算TrendsCache。 当数据到达时,我们在一小时内将其汇总,然后将其写入表格中以反映趋势变化的动态。
管家通过通常的“选择”启动并从数据库中删除信息。 这并不总是有效的,这可以从内部过程的性能图中理解。
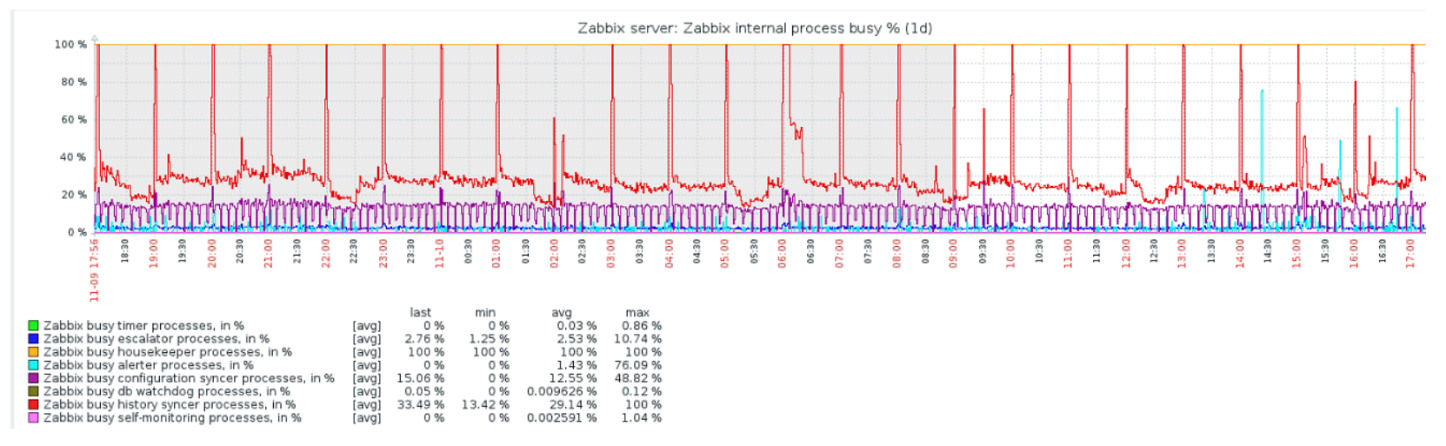
红色图形表示历史记录同步器一直很忙。 上面的橙色图表是管家,它一直在运行。 他希望数据库删除他指定的所有行。
何时关闭管家? 例如,有一个“项目ID”,您需要在特定时间内删除最后5,000行。 当然,这是通过索引发生的。 但是通常数据集非常大,数据库仍然从磁盘读取数据并将其提升到缓存中。 对于数据库而言,这始终是非常昂贵的操作,并且取决于数据库的大小,可能会导致性能问题。
管家只是一个断开。 在Web界面中,“管家”的“管理常规”中有一个设置。 对内部趋势历史记录禁用内部管理,它将不再进行管理。
管家被关闭了,图表被调平了-在这种情况下可能是什么问题,什么可以帮助解决第三项性能挑战?
分区-分区或分区
通常,在我列出的每个关系数据库上以不同的方式配置分区。 每种技术都有自己的技术,但总的来说它们是相似的。 创建新分区通常会导致某些问题。
通常根据“设置”(一天中创建的数据量)来配置分区。 通常,分区是在一天内公开的,这是最低要求。 对于新分区的趋势-为1个月。
在“设置”非常大的情况下,值可能会更改。 如果小的“设置”高达5,000 nvps(每秒的新值),则平均值为5,000至25,000,则大的“设置”高于25,000 nvps。 这些是非常大的安装,需要仔细配置数据库。
在非常大的安装中,一日运行可能不是最佳选择。 我看到每天有40 GB或更多的MySQL分区。 这是可能导致问题的大量数据,因此需要减少。
是什么赋予了分区功能?
分区表 。 通常,这些是磁盘上的单独文件。 查询计划可以更好地选择一个分区。 分区通常在一定范围内使用-对于Zabbix,这也是事实。 我们使用那里的“时间戳”-从时代开始的时间。 我们有普通数字。 您设置一天的开始和结束-这是一个分区。
快速删除 DELETE 。 选择单个文件/子表,而不选择要删除的行。
明显加快 SELECT 数据检索的速度 -使用一个或多个分区,而不是整个表。 如果您在两天前要求数据,则可以更快地从数据库中选择它们,因为您需要加载到缓存中并只发布一个文件,而不是大表。
通常,许多数据库还可以加快将
INSERT插入子表的速度。
时间刻度
对于v 4.2,我们将注意力转向了TimescaleDB。 这是具有本地接口的PostgreSQL扩展。 该扩展可有效处理时间序列数据,而不会失去关系数据库的优势。 TimescaleDB也会自动分区。
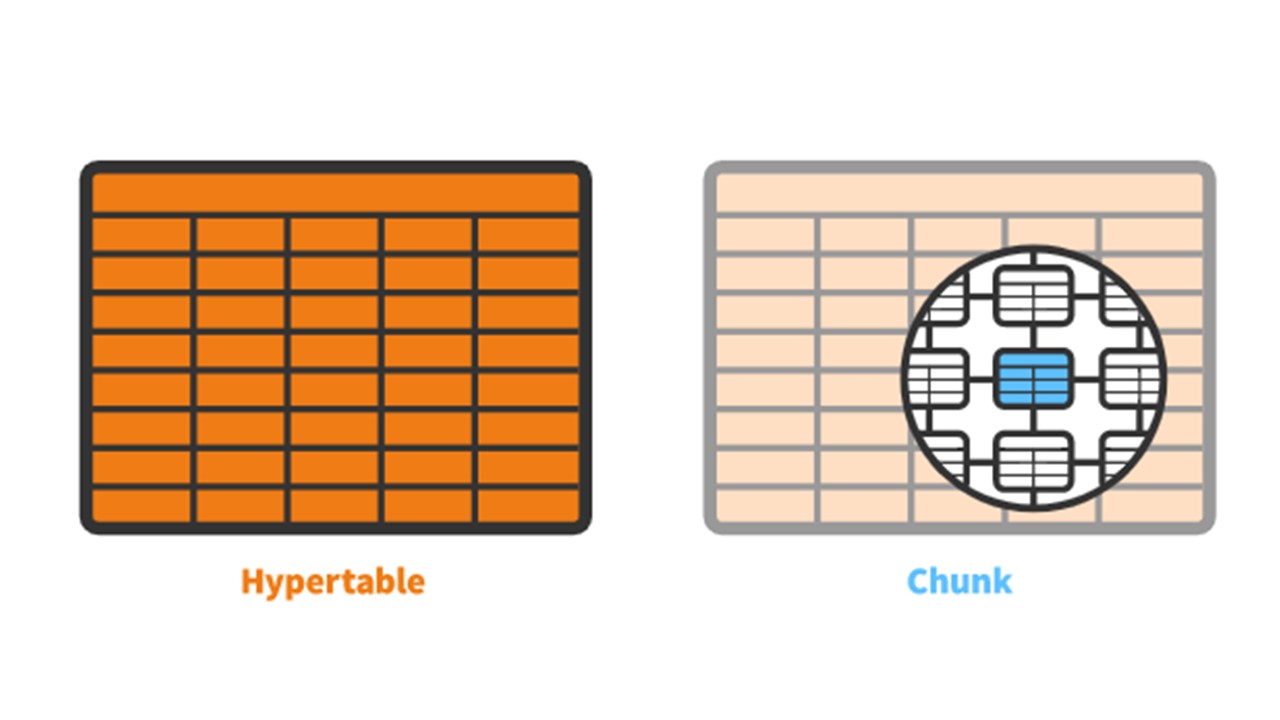
TimescaleDB具有您创建的
超表的概念。 它包含
块 -分区。 块是超表的自动控制片段,不会影响其他片段。 每个块都有自己的时间范围。
TimescaleDB与PostgreSQL
TimescaleDB的工作效率很高。 扩展制造商声称,他们使用更正确的请求处理算法,尤其是<code>插入</ code>。 当数据集插入物的尺寸增加时,该算法将保持稳定的性能。
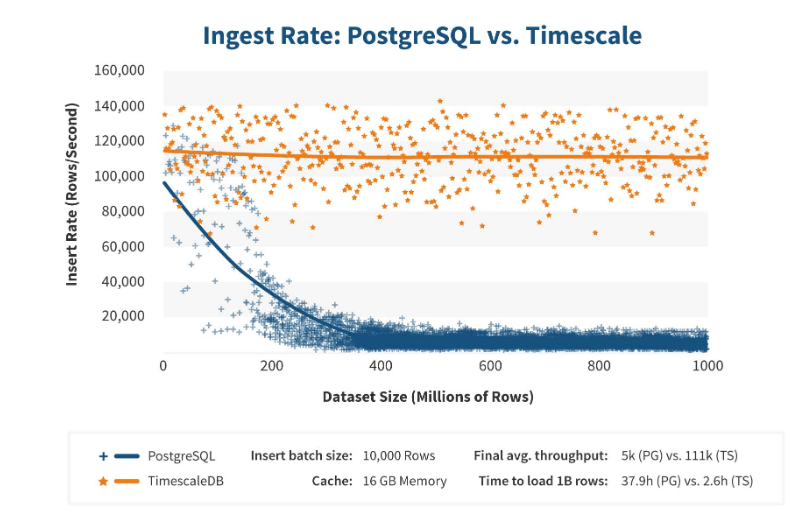
在2亿行之后,PostgreSQL通常会开始严重下垂并失去高达0的性能。TimescaleDB允许您有效地为任何数量的数据插入“插入”。
安装方式
对于任何软件包,安装TimescaleDB都非常容易。 该
文档详细描述了所有内容-取决于官方的PostgreSQL软件包。 TimescaleDB也可以手动编译。
对于Zabbix数据库,我们只需激活扩展名:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
您激活
extension并为Zabbix数据库创建它。 最后一步是创建一个超表。
将历史记录表迁移到TimescaleDB
create_hypertable有一个特殊的函数
create_hypertable :
SELECT create_hypertable('history', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_log', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_text', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('history_str', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends', 'clock', chunk_time_interval => 86400, migrate_data => true); SELECT create_hypertable('trends_unit', 'clock', chunk_time_interval => 86400, migrate_data => true); UPDATE config SET db_extension='timescaledb', hk_history_global=1, hk_trends_global=1
该函数具有三个参数。 第一个是
数据库中需要为其创建超
表的表 。 第二个是用于创建
chunk_time_interval的
字段 -您要使用的分区块的间隔。 就我而言,间隔是一天-86,400。
第三个参数是
migrate_data 。 如果设置为
true ,那么所有当前数据都将传输到先前创建的块中。 我本人使用
migrate_data 。 我大约有1 TB,这花了一个多小时。 即使在某些情况下,在测试时,我也删除了存储时可选的字符类型的历史数据,以免传输它们。
最后一步是
UPDATE :我们在
db_extension设置
timescaledb ,以便数据库了解存在此扩展名。 Zabbix会激活它并正确使用语法和已经对数据库的查询-TimescaleDB必需的那些功能。
铁配置
我使用了两台服务器。 首先是一台
VMware机器 。 它足够小:20个Intel®Xeon®处理器E5-2630 v 4 @ 2.20GHz,16 GB RAM和200 GB SSD。
我在Debian 10.8-1.pgdg90 +1和xfs文件系统上安装了PostgreSQL 10.8。 我最少配置了所有内容以使用该特定数据库,但不包括Zabbix本身将使用的内容。
Zabbix服务器,PostgreSQL和
负载代理在同一台机器上。 我有50个活跃的代理商,他们使用
LoadableModule迅速生成各种结果:数字,字符串。 我用大量数据阻塞了数据库。
最初,该配置每个主机包含
5,000个数据
项 。 几乎每个元素都包含一个触发器,因此它类似于真实安装。 在某些情况下,触发不止一个。
每个网络节点有
3,000-7,000个触发器 。
更新数据项的间隔为
4-7秒 。 我不仅使用50个代理,而且还添加了更多代理来调节负载本身。 另外,借助数据元素,我动态调整了负载并将更新间隔减少到4 s。
PostgreSQL的 35,000 nvps
我在纯PostgreSQL上首次在此硬件上运行-每秒35,000个值。 如您所见,插入数据只需要几分之一秒的时间-一切都很好且快速。 唯一可以快速填充200 GB SSD的东西。
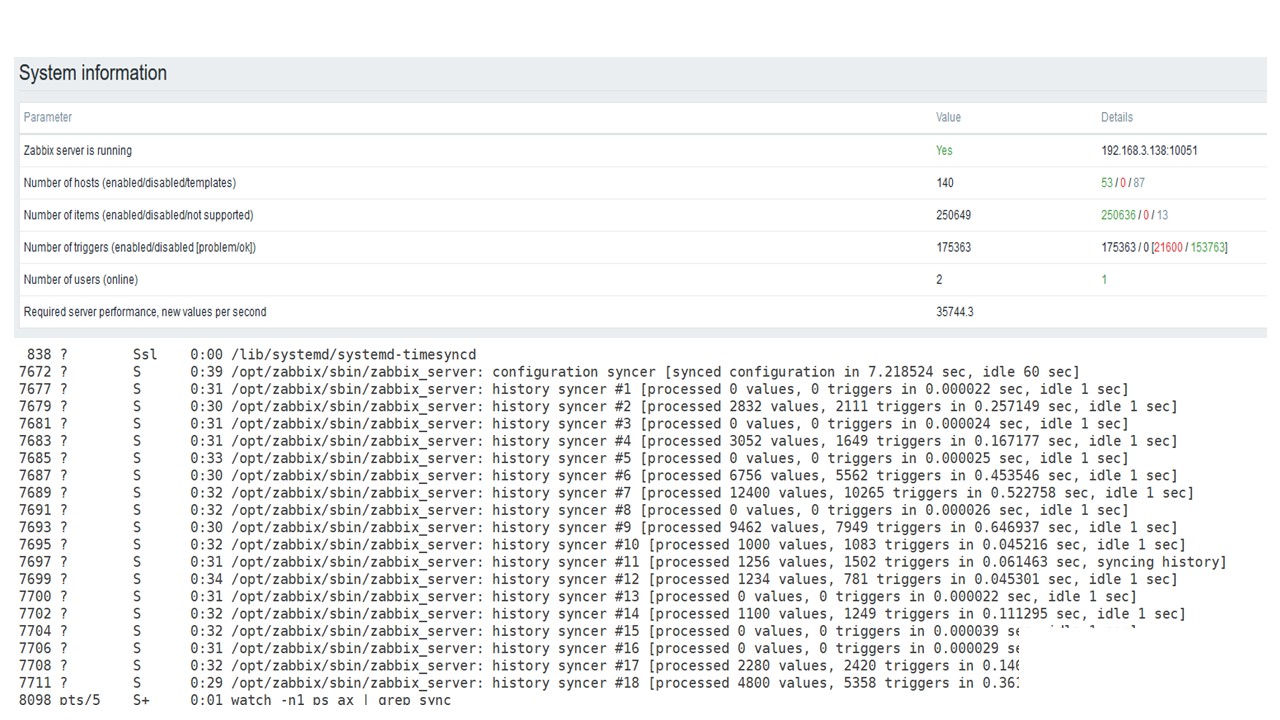
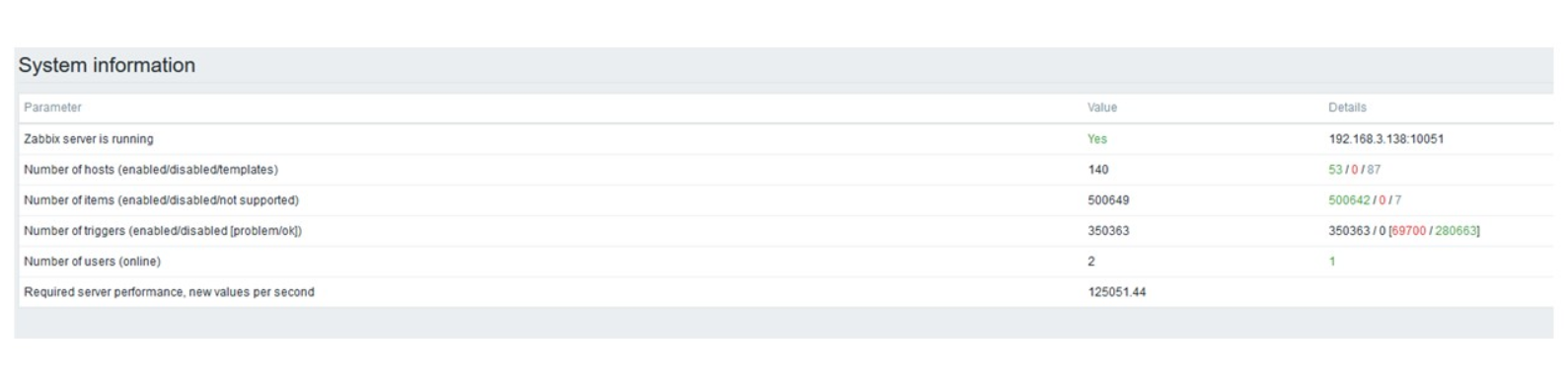
这是标准的Zabbix服务器性能仪表板。
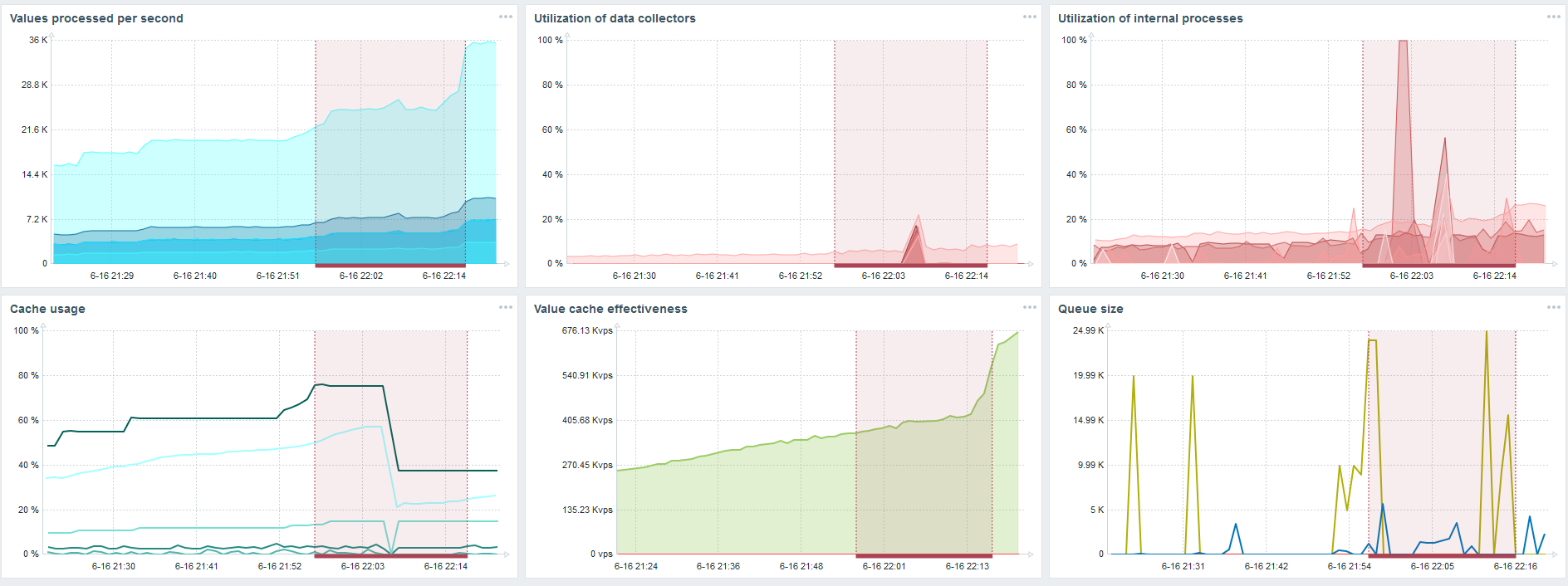
第一个蓝色图是每秒的值数。 右边的第二张图是组装过程的负载。 第三是加载内部组装过程:历史记录同步器和管家,在这里已经运行了很长时间。
第四个图显示了HistoryCache的用法。 这是插入数据库之前的缓冲区。 绿色的第五张图显示了ValueCache的使用,也就是说,每秒有几千个值对触发器的ValueCache命中。
PostgreSQL的 50,000 nvps
然后,我在同一硬件上将负载增加到每秒5万个值。
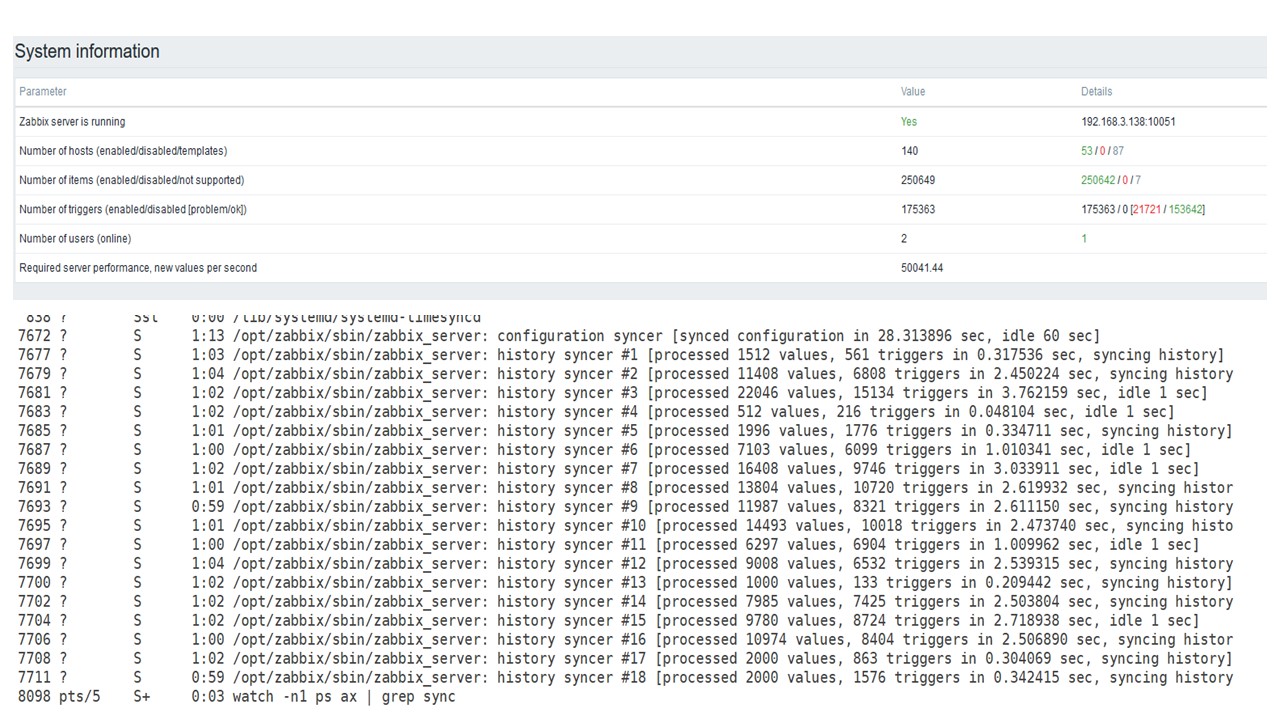
从管家加载时,记录了10,000个值的插入2-3 s。
 管家已经开始妨碍您。
管家已经开始妨碍您。第三张图显示,通常,陷阱和历史同步器的负载仍为60%。 在第四张图表中,在管家工作期间,HistoryCache已经开始非常活跃地填充。 它已满20%-约为0.5 GB。
PostgreSQL的 80,000 nvps
然后,我将负载增加到每秒8万个值。 这些大约是40万个数据元素和28万个触发器。
 加载三十个历史同步器的插入量已经很高。
加载三十个历史同步器的插入量已经很高。我还增加了各种参数:历史记录同步器,缓存。
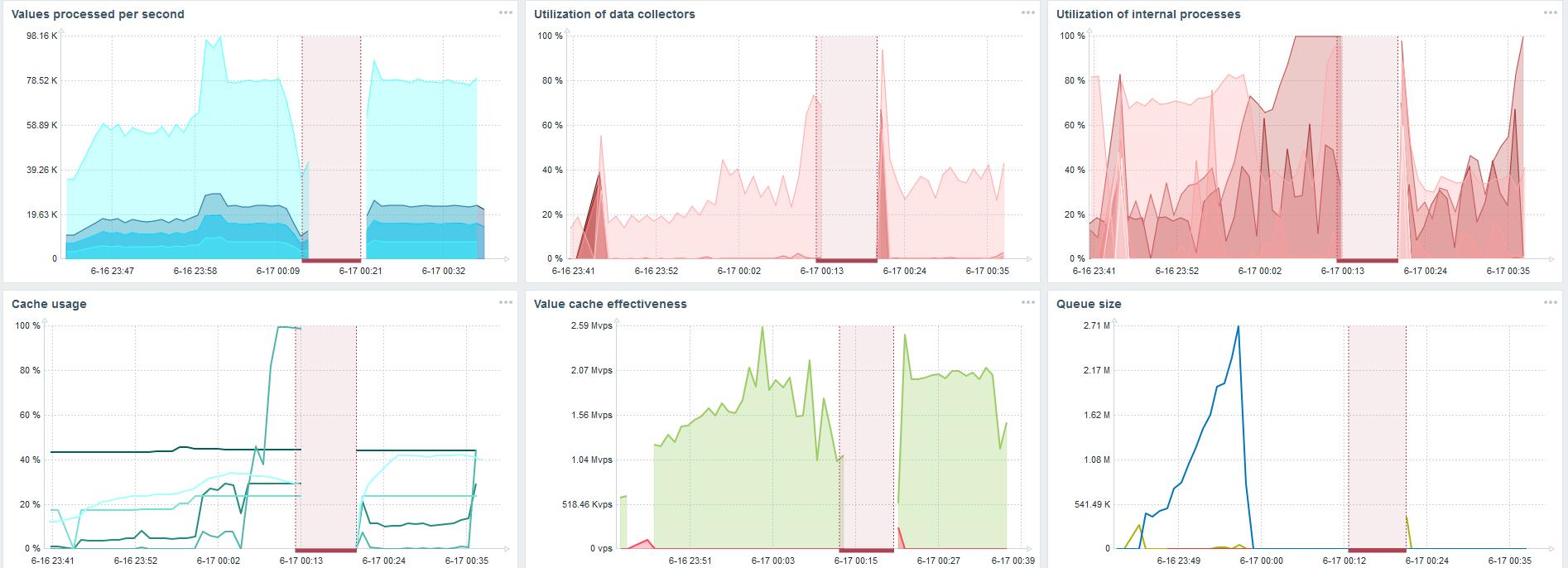
在我的硬件上,历史记录同步器的负载已增加到最大。 HistoryCache快速填充了数据-待处理的数据累积在缓冲区中。
一直以来,我一直在观察如何使用处理器,RAM和其他系统参数,并发现磁盘利用率已最大化。
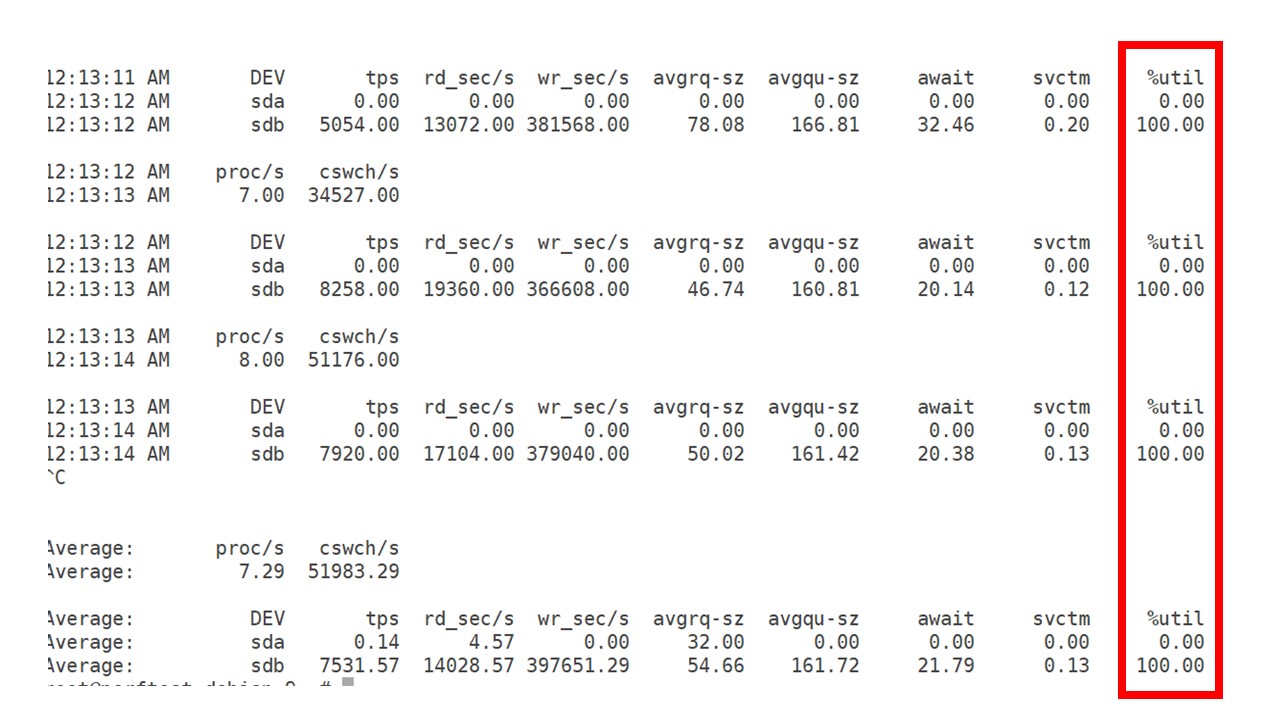
在此硬件和此虚拟机上,我
从驱动器中获得
最大收益。 在这种强度下,PostgreSQL开始非常积极地转储数据,并且磁盘不再有时间进行写入和读取。
第二台服务器
我选择了另一台已经具有48个处理器和128 GB RAM的服务器。 进行调整-设置60个历史记录同步器,并获得可接受的性能。
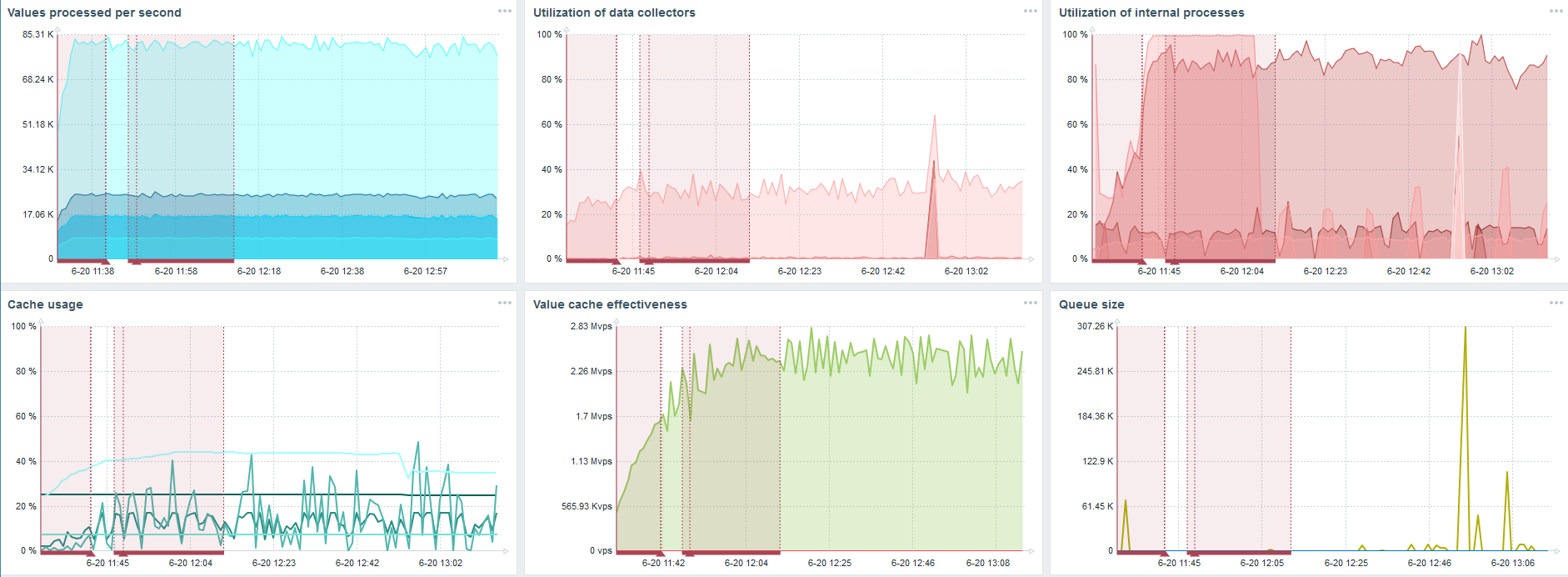
实际上,这已经是性能限制,需要执行某些操作。
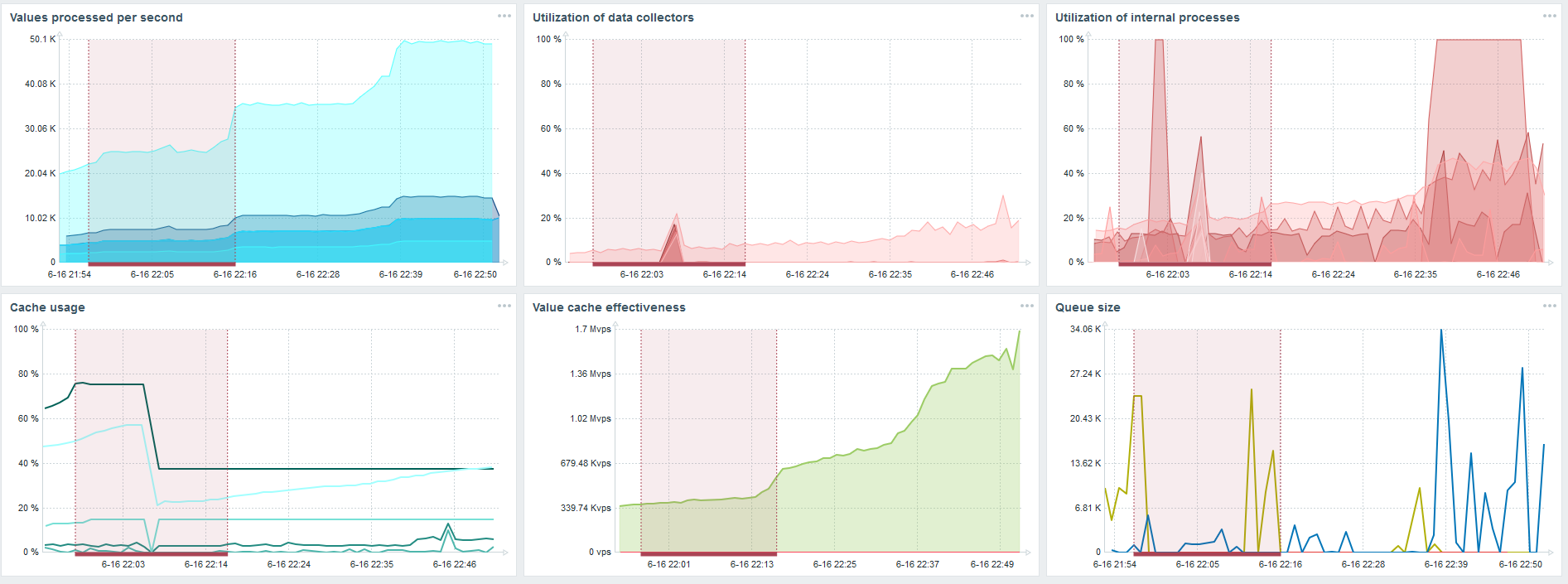
TimescaleDB。 80,000 nvps
我的主要任务是从Zabbix负载测试TimescaleDB的功能。 每秒8万个值很多,收集指标的频率(当然,不包括Yandex)和相当大的“设置”。
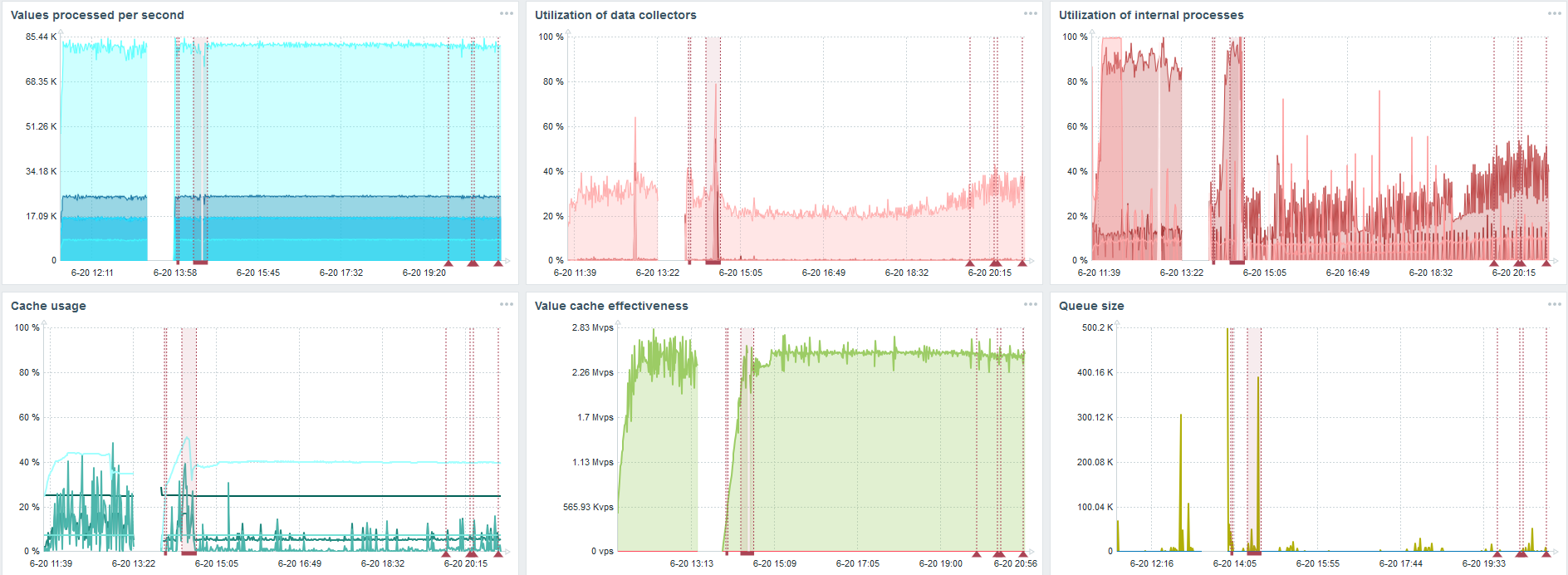
每个图表上都有一个失败-这仅仅是数据迁移。 在Zabbix服务器发生故障后,历史记录同步器启动配置文件发生了很大变化-已下降了三倍。
使用TimescaleDB,您可以将数据插入速度提高近3倍,并使用更少的HistoryCache。
因此,数据将及时交付给您。
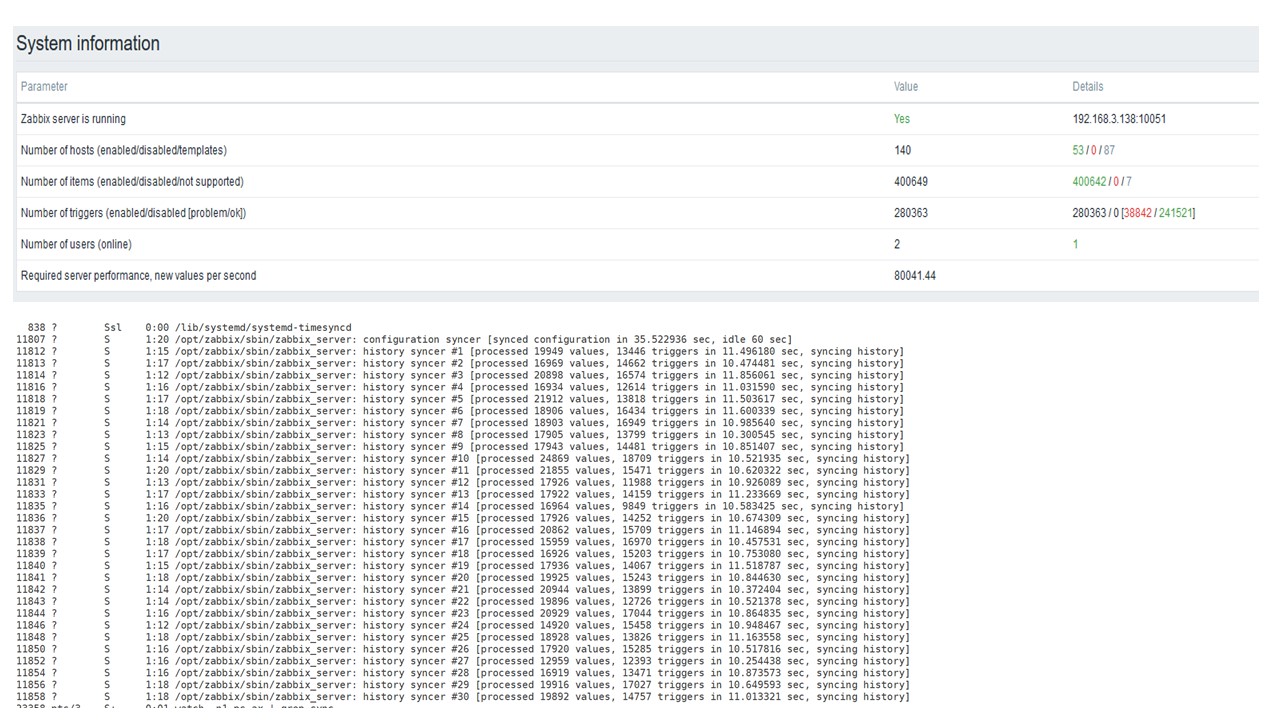
TimescaleDB。 120,000 nvps
然后,我将数据元素的数量增加到50万,主要任务是检查TimescaleDB的功能-我得到了每秒125,000个值的计算值。
这是一个可以长时间工作的“设置”。 但是由于我的磁盘只有1.5 TB,因此我在几天内就将其填满。
最重要的是,与此同时,创建了新的TimescaleDB分区。
对于性能而言,这是完全不可见的。 例如,在MySQL中创建分区时,一切都不同。 通常,这种情况发生在晚上,因为它阻止了常规插入,无法使用表,并且可能导致服务质量下降。 对于TimescaleDB,情况并非如此。
例如,我将显示社区中一组图表。 图片中包含TimescaleDB,因此,在处理器上使用io.weight的负担已减少。 内部流程要素的使用也有所减少。 这是普通煎饼磁盘上的常规虚拟机,而不是SSD。
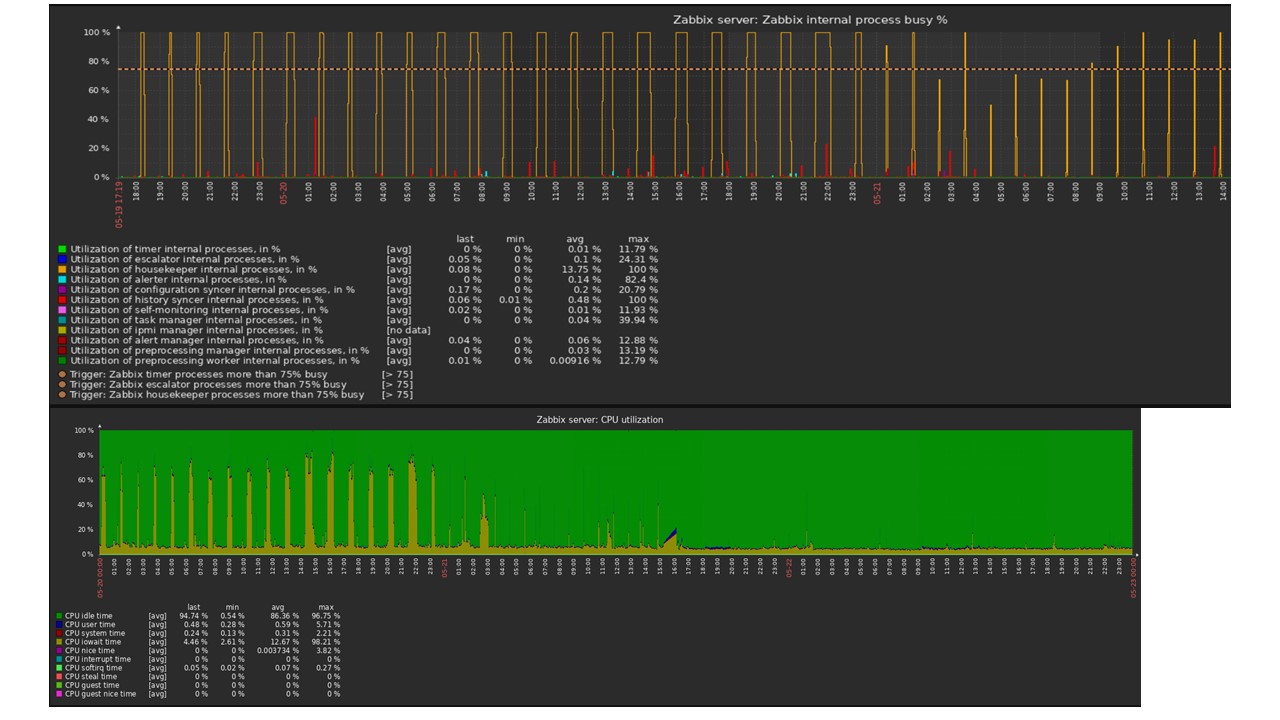
结论
对于那些依赖磁盘性能的
小型“设置” ,
TimescaleDB是一个很好的解决方案 。 它将使您继续正常工作,直到数据库迁移到铁的速度更快为止。
TimescaleDB易于配置,性能提高,与Zabbix兼容,
并且比PostgreSQL具有优势 。
如果您使用PostgreSQL并且不打算对其进行更改,那么我建议
将带有TimescaleDB扩展名的PostgreSQL与Zabbix一起使用 。 该解决方案有效地适用于中等“设置”。
我们说 “高性能”-我们的意思是HighLoad ++ 。 等待简短地了解使服务能够为数百万用户提供服务的技术和实践。 我们已经编制了11月7日和8日的报告清单,但是仍然可以提供mitaps 。
订阅我们的时事通讯和电报 ,在其中我们将展示即将举行的会议的内容,并学习如何充分利用会议的内容。