现代机器学习使您可以做不可思议的事情。 神经网络为社会造福:他们找到罪犯,识别威胁,帮助诊断疾病并做出艰难的决定。 算法可以超越一个人的创造力:他们可以绘画图片,写歌并用普通图片制作杰作。 那些开发这些算法的人通常是漫画讽刺的科学家。
并非一切都如此可怕! 任何对编程有些熟悉的人都可以从基本模型构建神经网络。 甚至没有必要学习Python,一切都可以用本机JavaScript完成。 FrontendConf的
Aleksey Okhrimenko (
obenjiro )说,这很容易上手,为什么前端
供应商需要机器学习,我们将其转移到文本中,以便手握架构名称和有用的链接。
剧透 提醒!
这个故事:
- 不适合那些已经使用机器学习的人。 会有一些有趣的事情,但是在削减的情况下,您不太可能在等待开幕。
- 与转移学习无关。 我们不会讨论如何用Python编写神经网络,然后再通过JavaScript使用它。 没有作弊-我们将专门在JS上编写深度神经网络。
- 并非所有细节。 通常,所有概念都不会写在一篇文章中,但是我们当然会分析必要的内容。
关于演讲者:阿列克谢·奥赫里缅科(Alexei Okhrimenko)在Frontito建筑部门的Avito工作,并在业余时间主持莫斯科角会,并发布了《五分钟角》。 在漫长的职业生涯中,他开发了设计模式MALEVICH,即PEG语法解析器SimplePEG。 Alexey CSSComb的维护者会定期在会议上和他的JS机器学习
电报频道中分享有关新技术的知识。
机器学习非常流行。
语音助手,Siri,Google助手,爱丽丝很受欢迎,并且经常在我们的生活中发现。 许多产品已从传统的算法数据处理转向机器学习。 一个明显的例子是Google Translate。
智能手机中的所有创新和最酷的芯片都是基于机器学习的。

例如,Google NightSight使用机器学习。 我们看到的很酷的照片不是通过镜头,传感器或稳定器获得的,而是借助机器学习获得的。 机器最终在DOTA2中击败了人们,这意味着我们几乎没有击败人工智能的机会。 因此,我们必须尽快掌握机器学习。
让我们从一个简单的开始
我们的日常编程例程是什么,通常如何编写函数?

我们采用我们自己发明或从流行的现成数据中获得的数据和算法,进行组合,做些魔术,并获得在给定情况下能够为我们提供正确答案的功能。
我们已经习惯了这种顺序,但是会有这样的机会,而无需了解算法,而只是拥有数据和答案,就可以从中获得算法。

您可以说:“我是程序员,我总是可以编写算法。”
好的,但是例如,这里需要什么算法?

假设猫的耳朵锋利,而狗的耳朵又钝又小,像哈巴狗。

让我们试着通过耳朵来了解谁是谁。 但是在某些时候,我们发现狗的耳朵可以尖锐。

我们的假设不好,我们需要其他特征。 随着时间的流逝,我们将了解越来越多的细节,从而越来越多地激励自己,并且在某个时候,我们将希望完全退出该业务。
我想象这样一个理想的图片:事先有一个答案(我们知道它是什么样的图片),有数据(我们知道是一只猫画了),我们想要一种可以提供数据并在输出中得到答案的算法。
有一个解决方案-这是机器学习,即它的一部分-深度神经网络。
深度神经网络
机器学习是一个巨大的领域。 它提供了大量的方法,每种方法都有其自己的优点。
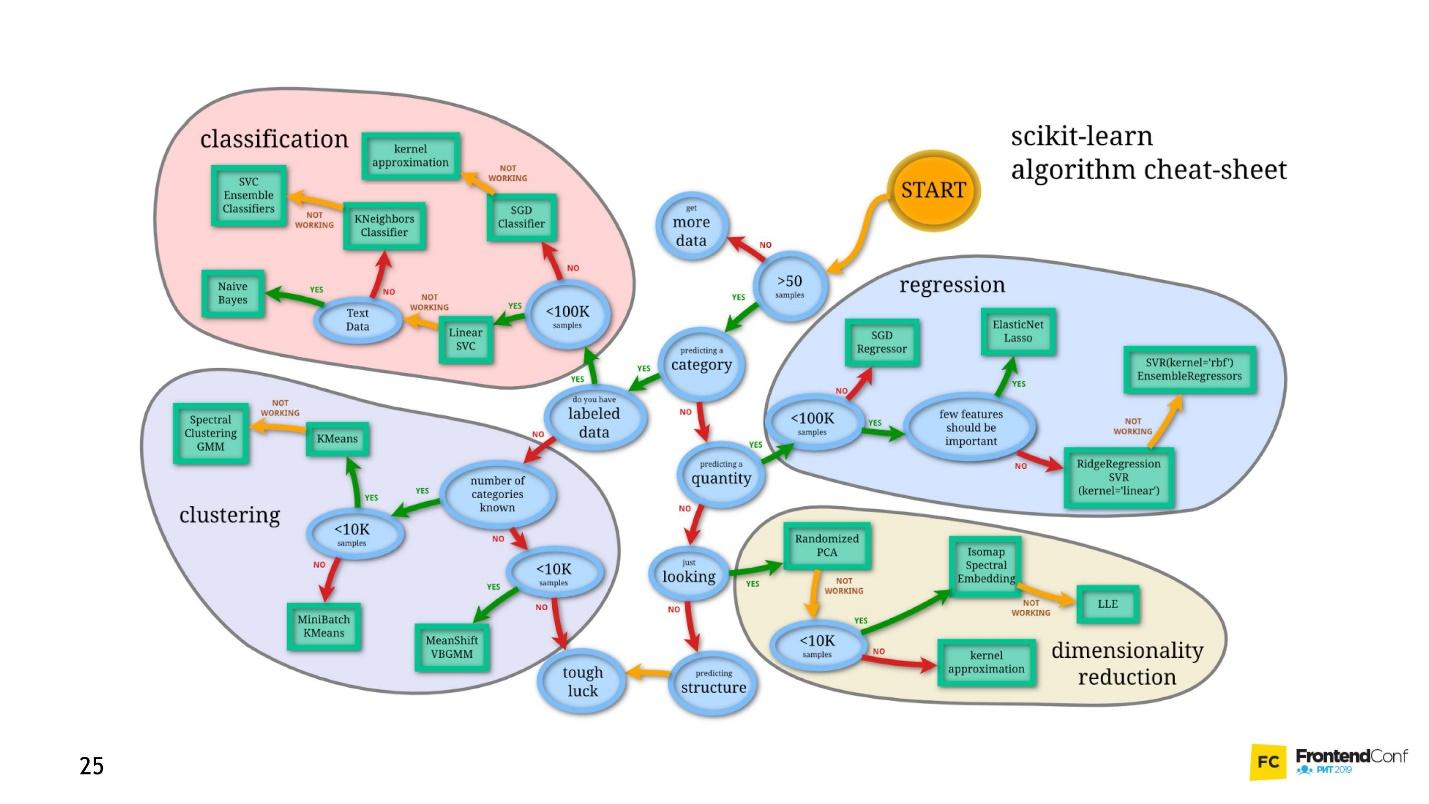
其中之一是深度神经网络。 深度学习具有不可否认的优势,正因如此,它已广受欢迎。
为了了解此优点,让我们以猫和狗为例,看看经典分类问题。
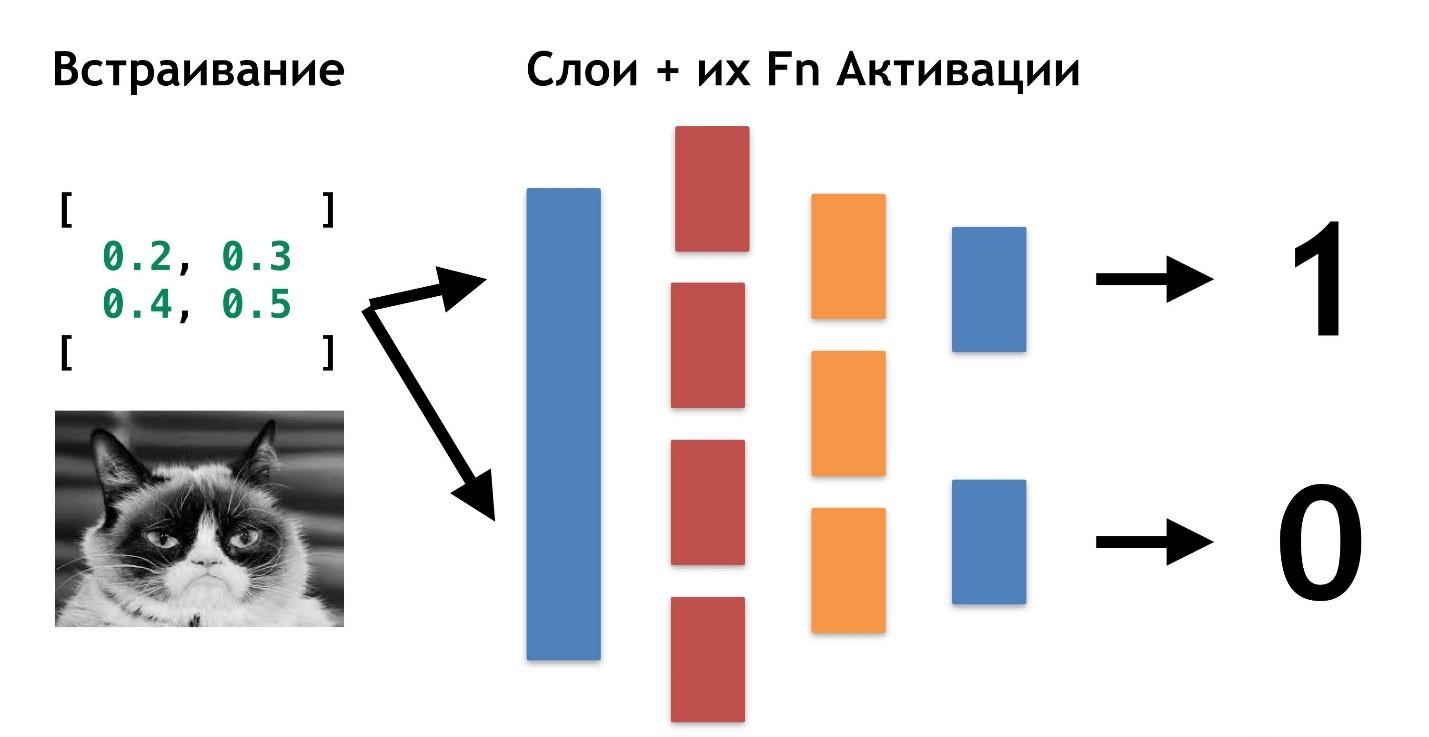
有数据:图片或照片。 首先要做的是嵌入(嵌入),即转换数据,以便机器舒适地使用它们。 图片处理不方便,汽车需要更简单的东西。
首先,对齐图片并去除颜色。 无论狗或猫是什么颜色,确定动物的类型都很重要。 然后,将图片转换为数组,例如0表示暗,1表示亮。

通过这种数据表示,神经网络已经可以工作。
让我们再创建两个数组,并将它们合并到某个“层”中。 接下来,我们将使用简单的矩阵乘法将图层的每个元素与数据数组彼此相乘,并将结果定向到两个激活函数中(稍后我们将分析这些函数是什么)。 如果激活函数接收到足够数量的值,则将其“激活”并产生结果:
- 如果是猫,第一个函数将返回1;如果不是猫,则第一个函数将返回0。
- 第二个函数如果是狗则返回1,如果不是狗则返回0。
这种对响应进行编码的方法称为“
一键编码” 。

深度神经网络的一些功能已经很明显了:
- 要使用神经网络,需要在输入处编码数据并在输出处解码。
- 编码使我们可以从数据中抽象出来。
- 通过更改输入数据,我们可以生成用于不同域域的神经网络。 即使我们不是专家。
不必知道猫是什么,狗是什么。 选择附加层的必要编号就足够了。
到目前为止,唯一不清楚的是为什么这些网络被称为“深度”。
一切都非常简单:我们可以创建另一个层(数组及其激活函数)。 并将结果转移到另一层。
这些层及其激活功能可以彼此叠加。 结合分层架构,我们得到了一个深层的神经网络。 它的深度是许多层。 并统称为
“典范” 。
现在让我们看看如何为所有这些层选择值。 有一个很酷的
可视化工具 ,可让您了解学习过程的过程。
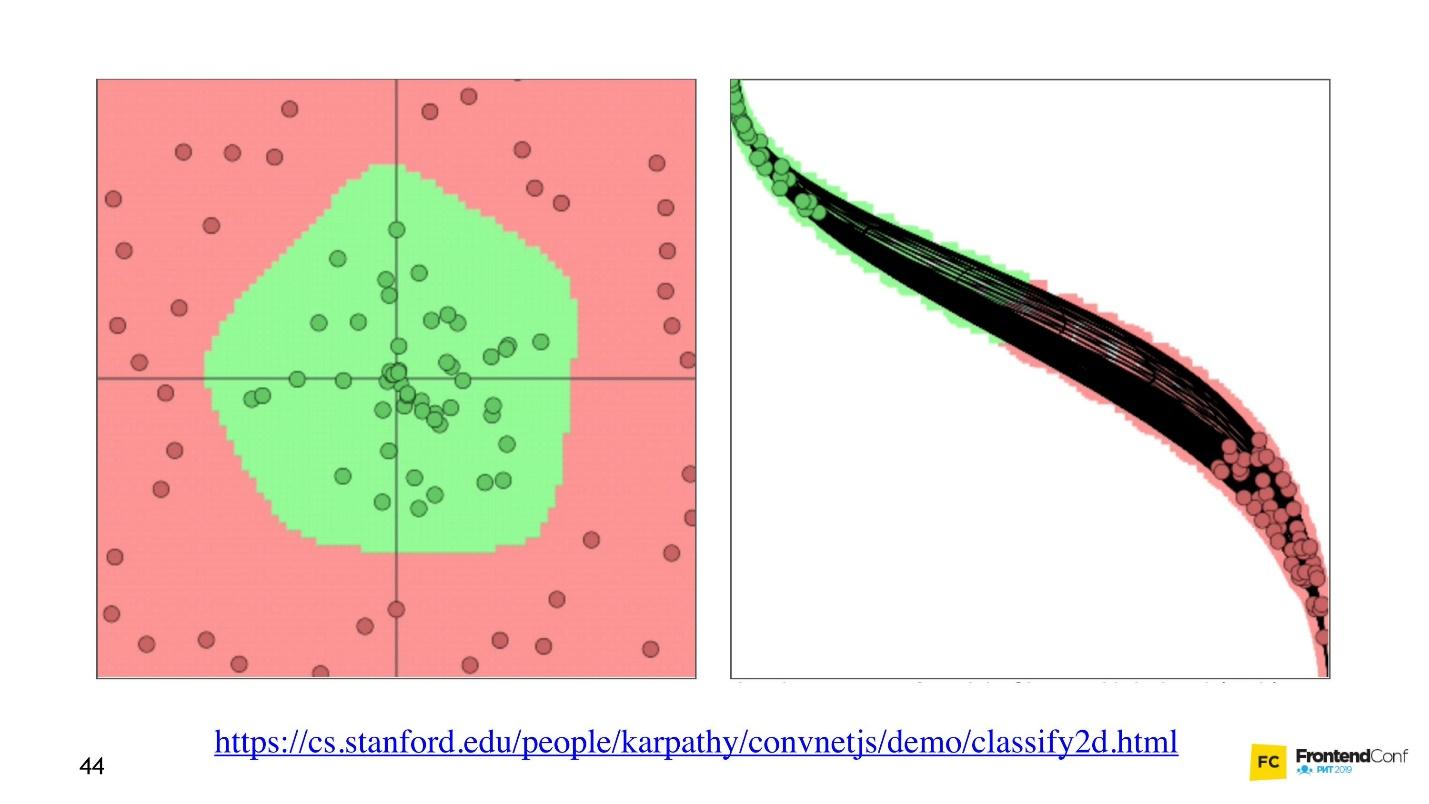
左边是数据,右边是其中一层。 可以看出,更改图层数组中的值,我们似乎更改了坐标系。 从而适应数据和学习。 因此,学习是为图层阵列选择正确值的过程。 这些值称为权重或权重。
机器学习很难
我想让你不高兴,机器学习很难。 以上所有都是一个很大的简化。 将来,您会发现大量的线性代数,而且相当复杂。 las,这是无法逃脱的。
当然有课程,但是即使最快的培训也要持续数月,而且也不便宜。 另外,您仍然必须自己弄清楚。 机器学习领域已经发展得如此之快,以至于几乎不可能跟踪所有事情。 例如,以下是仅解决一个任务(对象检测)的一组模型:

就个人而言,我很沮丧。 我无法接近神经网络并开始使用它们。 但我找到了一种方法,并希望与您分享。 它不是革命性的,里面没有类似的东西,您已经很熟悉了。
黑盒-一种简单的方法
为了学习如何将神经网络应用于您的业务任务,没有必要绝对地理解机器学习的所有方面。 我将展示一些示例,希望对您有所启发。
对于许多人来说,汽车也是黑匣子。 但是,即使您不知道它如何工作,也需要学习规则。 因此,在机器学习中,您仍然需要了解一些规则:
- 了解TensorFlow JS(用于神经网络的库)。
- 学习选择模型。
我们专注于这些任务,并从代码开始。
通过创建代码学习
TensorFlow库是为多种语言编写的:Python,C / C ++,JavaScript,Go,Java,Swift,C#,Haskell,Julia,R,Scala,Rust,OCaml,Crystal。 但是我们一定会选择最好的-JavaScript。
通过将脚本与CDN连接可以将TensorFlow连接到我们的页面:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
或使用npm:
npm install @tensorflow/tfjs-node用于节点进程(网站);npm install @tensorflow/tfjs-node-gpu (Linux CUDA)-适用于GPU,但npm install @tensorflow/tfjs-node-gpu是Linux机器和视频卡支持CUDA技术。 请确保CUDA计算能力与您的库相匹配,以免导致昂贵的硬件不适合您。npm install @tensorflow/tfjs (最慢/浏览器)-用于不使用Node.js的浏览器。
要使用TensorFlow JS,只需导入上述模块之一即可。 您将看到许多导入所有内容的代码示例。 无需执行此操作,只需选择并导入一个。
张量
准备好初始数据后,首先要做的就是
导入TensorFlow 。 由于显卡的强大功能,我们将使用tensorflow / tfjs-node-gpu获得加速。
有一个二维数据数组-我们将使用它。
接下来要做的重要事情是
创建张量 。 在这种情况下,将创建一个等级为2的张量,实际上是一个二维数组。 我们传输数据并获得2x2张量。
请注意,调用了
print方法,而不是
console.log ,因为
b (我们创建的张量)不是普通对象,即张量。 他有自己的方法和特性。
可以说,您还可以从平面阵列创建张量并牢记其形状。 也就是说,声明一个表单-一个二维数组-仅发送一个平面数组并直接指示该表单。 结果将是相同的。
由于数据和表格可以分别存储,因此可以更改张量的形状。 我们可以调用
reshape方法并将形状从2x2更改为4x1。
接下来的重要步骤是
输出数据 ,然后将其返回到现实世界。
这三个步骤的代码 。data方法返回promise。 解析后,我们获得原始值的立即值,但异步获取它。 如果需要,我们可以同步获取它,但是请记住,这里会损失性能,因此请尽可能使用异步方法。
dataSync方法始终以平面数组格式返回数据。 而且,如果我们想以张量中存储的格式返回数据,则需要调用
arraySync 。
经营者
TensorFlow中的所有运算符
默认情况下都是
不可变的 ,也就是说,在每个运算中始终会返回一个新的张量。 在上方,只需采用我们的数组并将其所有元素平方。
为什么对简单的数学运算有如此困难? 我们需要的所有运算符-总和,中位数等-都在这里。 这是必要的,因为实际上,张量和此方法使您可以创建计算图并立即执行计算,而无需在WebGL(在浏览器中)或CUDA(在计算机上的Node.js)上执行。 也就是说,实际上对我们来说,使用硬件加速是不可见的,并且在必要时对CPU进行回退。 很棒的事情是我们不需要考虑任何事情。 我们只需要学习tfjs API。
现在最重要的是模型。
型号
创建模型的最简单方法是顺序模型,即顺序模型,将一层的数据传输到下一层,再从另一层传输到下一层。 使用这里使用的最简单的层。
该层本身只是张量和运算符的抽象。 粗略地讲,这些是辅助函数,对您隐藏了大量数学。
让我们尝试了解如何使用模型,而无需深入研究实现细节。
首先,我们指出属于神经网络的数据形式
inputShape是必需的参数。 我们表示
units -多维数组的数量和激活函数。
relu函数
relu卓越之处在于它是偶然发现的-尝试过,效果更好,很长一段时间后,他们一直在寻找数学解释为什么会这样。
对于最后一层,当我们创建类别时,经常使用softmax函数-非常适合以“一键编码”格式显示答案。 创建模型后,请调用
model.summary()以确保以正确的方式组装模型。 在特别困难的情况下,可以使用函数式编程来创建模型。
如果需要创建特别复杂的模型,则可以使用功能方法:每次每个层都是一个新变量。 例如,我们手动采用下一层并对其应用上一层,因此我们可以构建更复杂的体系结构。 待会儿我会告诉你的。
下一个非常重要的细节是,我们将输入和输出层传递到模型中,即进入神经网络的层和作为答案的层。
此后,重要的一步是
编译模型 。 让我们尝试了解什么是tfjs编译。
记住,我们试图在神经网络中找到正确的值。 没必要接他们。 正如优化程序功能所说,它们是以某种方式选择的。
描述顺序层和编译的代码。我将说明什么是优化器,什么是损失函数。
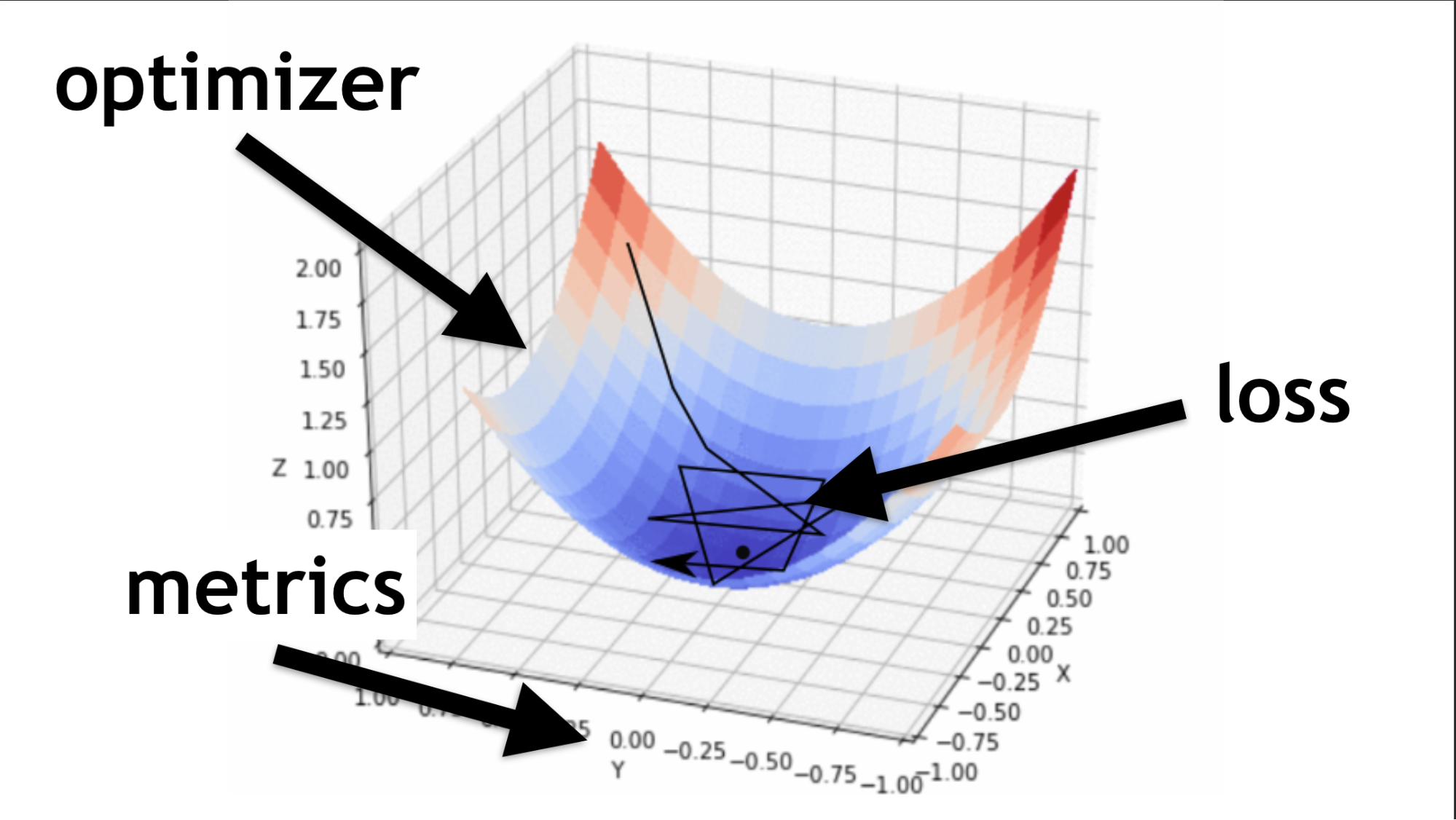
优化器是整个地图。 它使您不仅可以随机地寻找价值,而且可以根据某种算法明智地实现价值。
损失函数是我们寻找最佳值的方式(黑色小箭头)。 它有助于了解使用哪些梯度值来训练我们的神经网络。
将来,当您掌握神经网络时,您将自己编写损失函数。 神经网络的成功很大程度上取决于此函数的编写程度。 但这是另一个故事。 让我们开始简单。
网络学习实例
我们将生成随机数据和随机答案(标签)。 我们调用
fit模块,传递数据,答案和几个重要参数:
epochs -进行5次,即大约5次,我们将进行全面的培训;batchSize ,它一次可以更改多少个权重-一次要处理多少个元素。 视频卡越好,内存越多,可以设置的batchSize越多。
最后所有步骤的代码 。Model.fit异步方法,返回promise。 但是您可以使用异步/等待并以这种方式等待执行。
接下来是
使用 。 我们训练了模型,然后获取了要处理的数据,然后将其称为“
predict方法”,我们说:“预测实际存在的是什么?”,并因此得到了结果。
标准结构
每个神经网络都有三个主要文件:
- index.js-存储神经网络所有参数的文件;
- model.js-直接存储模型及其架构的文件;
- data.js-在我们的系统中收集,处理和嵌入数据的文件。
因此,我谈到了如何学习TensorFlow.js。 小型企业,
选择模型仍然
是 。
不幸的是,这并非完全正确。 实际上,每次选择模型时,都必须重复某些步骤。
- 为此准备数据,即进行嵌入,并根据体系结构进行调整。
- 配置超级设置(我稍后会告诉您这是什么意思)。
- 训练/训练每个神经网络(每个模型可能都有自己的细微差别)。
- 应用神经模型,同样,您可以以不同的方式应用。
选择型号
让我们从您经常遇到的基本选项开始。
深度感
这是深度神经网络的流行示例。 一切都非常简单:有一个公开可用的数据集-MNIST数据集。
这些被标记为带有数字的图片,在此基础上可以方便地训练神经网络。
根据“一键编码”的体系结构,我们对最后一层进行编码。 数字10-因此,最后会有10个最后一层。 我们只需将黑白图片提交到入口,所有这些都与我们一开始所谈论的非常相似。
const model = tf.sequential({ layers: [ tf.layers.dense({ inputShape: [784], units: 512, activation: 'relu' }), tf.layers.dense({ units: 256, activation: 'relu' }), tf.layers.dense({ units: 10, activation: 'softmax' }), ] });
我们将图片整理为一维数组,得到784个元素。 一层中有512个阵列。 激活功能
'relu' 。
数组的下一层稍微小一些(256),激活层也是
'relu' 。 我们减少了阵列的数量以寻找更一般的特性。 必须提示神经网络如何学习,并且必须做出更严肃的一般性决定,因为她本人不会这样做。
最后,我们制作了10个矩阵,并将softmax激活用于一键编码-这种类型的激活与这种类型的响应编码配合得很好。
深度网络可让您正确识别80-90%的图片-我想要更多。 一个人的识别质量约为96%。 神经网络可以捕捉并超越一个人吗?
CNN(卷积神经网络)
卷积网络的工作非常简单。 最后,它们具有与先前示例相同的体系结构。 但是在一开始,还有其他事情发生。 阵列不仅可以提供一些解决方案,还可以减少图像。 他们将图片的一部分缩小并缩小至一位数。 然后将它们全部收集在一起并再次减少。
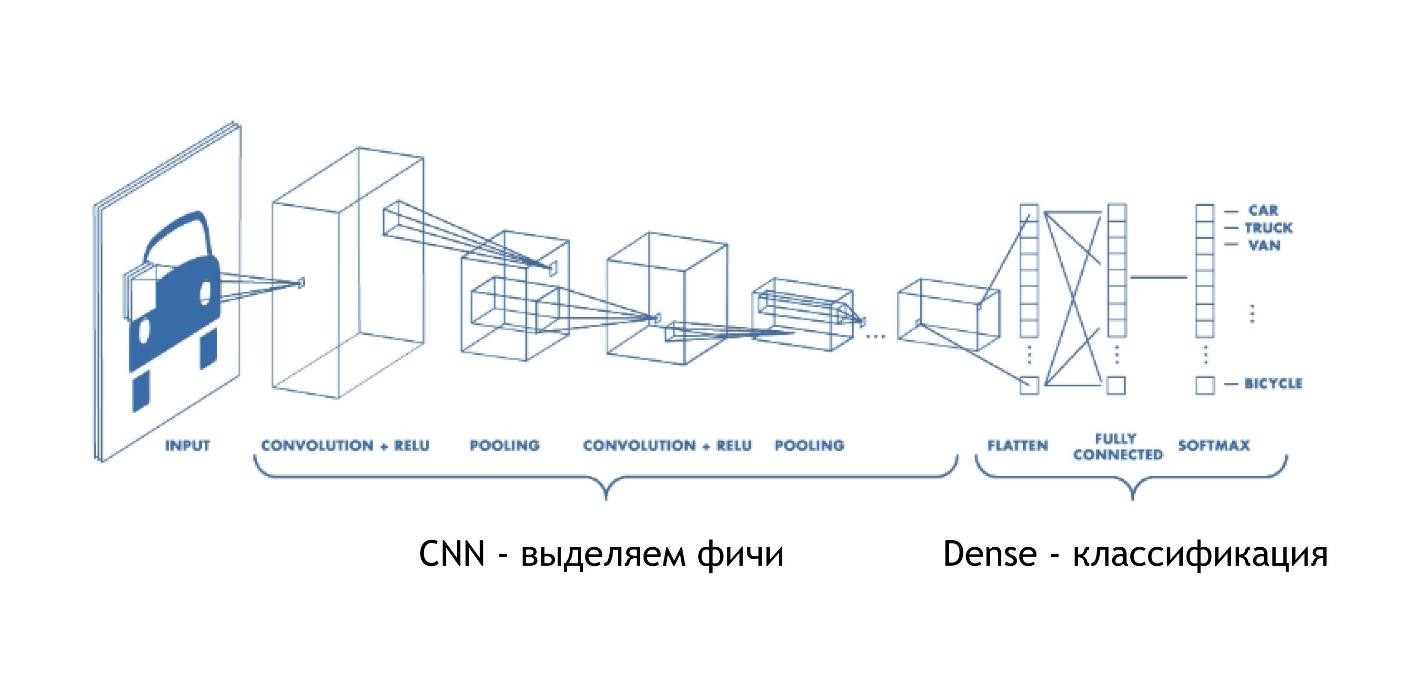
因此,减小了图像的尺寸,但是同时越来越好地识别出图像的各个部分。 卷积网络对于模式识别非常有效,甚至比人类还要好。
识别图片最好交给人而不是人。 进行了一项特殊研究,不幸的是,这个人迷路了。
CNN的工作非常简单:
const model = tf.sequential({ layers: [ tf.layers.conv2d({ inputShape: [28, 28, 1], filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.conv2d({ filters: 32, kernelSize: 3, activation: 'relu', }), tf.layers.maxPooling2d({poolSize: [2, 2]}), tf.layers.conv2d({ filters: 64, kernelSize: 3, activation: 'relu', }) tf.layers.flatten(tf.layers.maxPooling2d({ poolSize: [2, 2] })), tf.layers.dense({units: 512, activation: 'relu'}), tf.layers.dense({units: 10, activation: 'softmax'}) ] });
我们输入一个特定的多维数组:一个28x28像素的图像,再加上一个维亮度,在这种情况下,图像是黑白的,因此第三个维是1。
接下来,我们设置
filters和
kernelSize的数量-缩小多少像素。 激活功能随处可见。
还有另一层
maxPooling2d ,它需要更有效地减小大小。 卷积网络会逐渐缩小规模,通常不需要建立非常深的卷积网络。
我将解释为什么稍后再做非常深的卷积网络是不可能的,但是现在要记住:有时它们需要更快地卷起。 为此有一个单独的maxPooling层。
在最末端有相同的致密层。 也就是说,使用卷积神经网络,我们从数据中提取了各种符号,然后使用标准方法并对结果进行分类,从而可以识别图片。
网
该体系结构模型与卷积网络相关联。 有了它的帮助,在癌症控制领域,例如在识别癌细胞和青光眼方面已经取得了许多发现。 此外,该模型可以发现恶性细胞不比该领域的教授差。
一个简单的例子:在嘈杂的数据中,您需要找到癌细胞(圆圈)。

U-Net非常好,几乎可以找到它们。 架构非常简单:
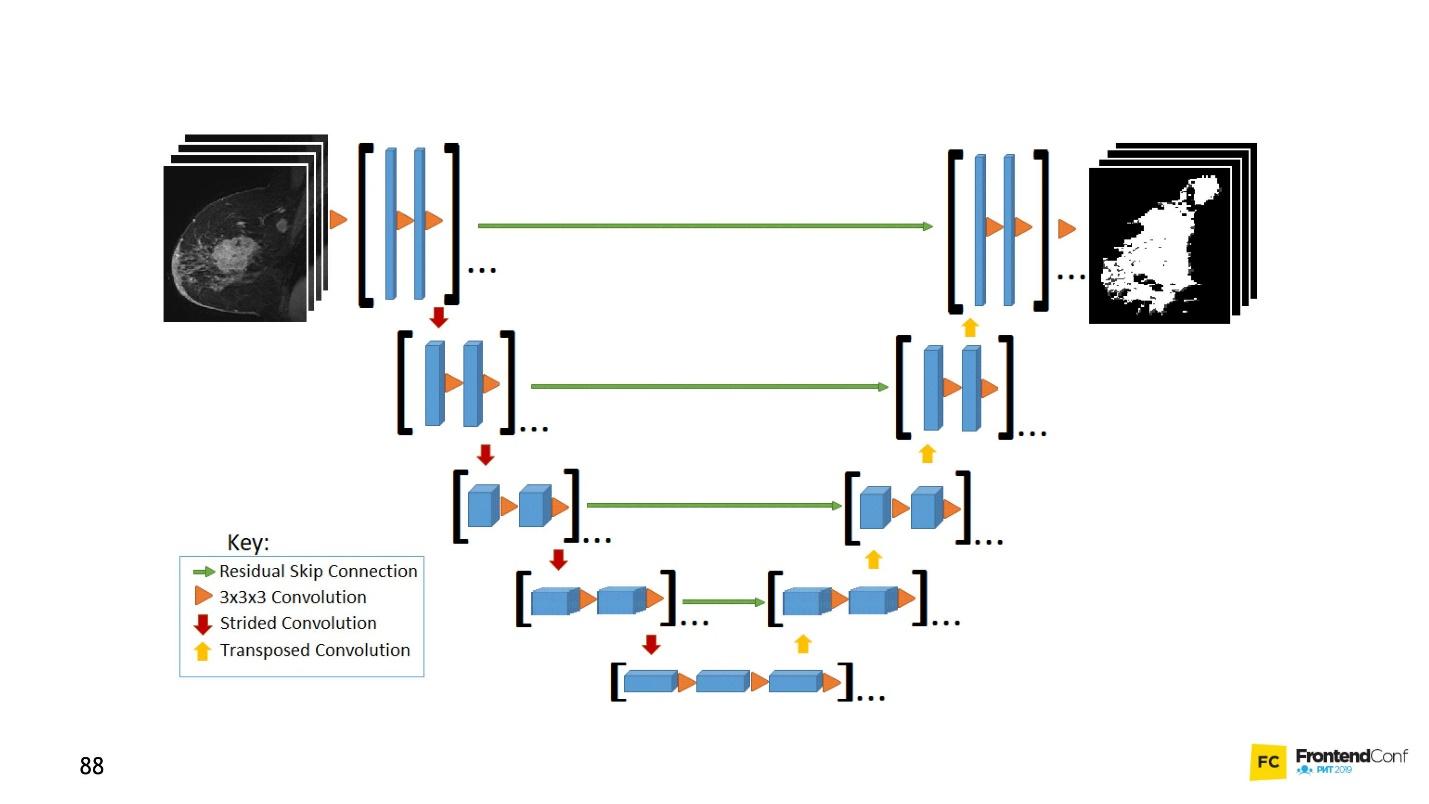
与MaxPooling一样,它们具有相同的卷积网络,从而减小了大小。 唯一的区别是:该模型还使用
扫描网络-
反卷积网络 。
除了卷积扫描,每个高层都相互组合(开始和退出),因此会出现大量关系。 这样的U-Net即使在少量数据上也能很好地工作。
此代码在编辑器中更容易学习。 通常,这里会创建大量的卷积网络,然后将它们重新部署,我们将其
concatenate并合并几层。 这只是图片的可视化,仅采用代码形式。 一切都非常简单-复制和复制这种模型很容易。
LSTM(长期短期记忆)
请注意,所有考虑的示例都具有一个功能-输入数据格式是固定的。 输入网络时,数据大小必须相同且彼此匹配。 LSTM模型专注于如何处理这一问题。
例如,有一个Yandex.Referats服务,它生成摘要。
他给出了完整的abracadabra,但与此同时,它与真相十分相似:
主题为“牛顿二项式作为公理”的数学摘要
根据前述,表面积分产生曲线积分。 仍然需要凸出底部的功能。
由此自然得出结论,仍然需要表面法线。 根据前面的内容,泊松积分本质上指定了三角泊松积分。
该服务基于Seq-to-Seq神经网络。 他们的架构更加复杂。

层以相当复杂的系统排列。 但不要惊慌-您不必亲自操作所有这些箭头。 如果需要,可以但不是必需的。 有一个帮手将为您完成此任务。
要了解的主要是,这些部分中的每一个都与上一个结合在一起。 它不仅从初始数据中获取数据,还从先前的神经层中获取数据。 粗略地说,可以建立某种类型的存储器-记忆数据序列,对其进行再现,并且由于这项工作“序列化”。 此外,序列在输入和输出处可以具有不同的大小。
代码中的一切看起来都很漂亮:
tf.sequential({ layers: [ tf.layers.lstm({ units: 512, returnSequences: true, inputShape: [10000, 64] }), tf.layers.lstm({ units: 512, returnSequences: false }), tf.layers.dense({ units: 64, activation: 'softmax' }) ] }) ;
有一个特殊的帮助器,说我们有512个对象(数组)。 接下来,返回序列和输入形式(
inputShape: [10000, 64] )。 接下来,我们介绍另一层,但是我们不返回序列(
returnSequences: false ),因为最后我们说现在我们需要对64个不同的字符(小写和大写字母)使用激活功能。 使用一键编码激活64个选项。
最有趣
现在,您可能想知道:“当然,这就是全部,但是我为什么需要它? “抗击癌症是件好事,但是为什么我需要在一线治疗?”
然后用铃鼓跳舞:例如弄清楚如何将神经网络应用于布局。
借助神经网络,可以解决以前无法解决的问题。 您甚至无法想到的一些。 这完全取决于您,您的想象力和一点练习。
现在,我将展示有关我们使用的模型的使用的有趣示例。
CNN 音频团队
使用卷积网络,您不仅可以识别图片,还可以识别音频命令,并且具有97%的识别质量,即在Google Assistant和Yandex-Alice级别。
当然,仅在网络上就不可能识别出完整的语音,句子,但是您可以创建一个简单的语音助手。
您可以在Nikita Dubko的
报告中找到有关Alice的更多信息,以及有关Google助手,如何在其中使用声音以及浏览器标准的
信息 。
事实是,任何单词,任何命令都可以变成频谱图。
您可以将任何音频信息转换成这样的声谱图。 然后,您可以对图片中的音频进行编码,然后将CNN应用于图片并识别简单的语音命令。
U网。 屏幕截图测试
U-Net不仅可用于成功诊断癌症,而且还可用于例如测试屏幕截图。 有关详细信息,请参见Lyudmila Mzhachikh的
报告 ,我将告诉基地本身。
要使用屏幕截图进行测试,需要两个屏幕截图:
- 我们正在与之比较的基本(参考);
- 屏幕截图进行测试。

不幸的是,在屏幕截图测试中,通常会有很多跌落为负(误报)的情况。 但这可以通过在前端应用先进的癌症控制技术来避免。
请记住,我们在没有癌症的区域标记了图像。 同样可以在这里完成。
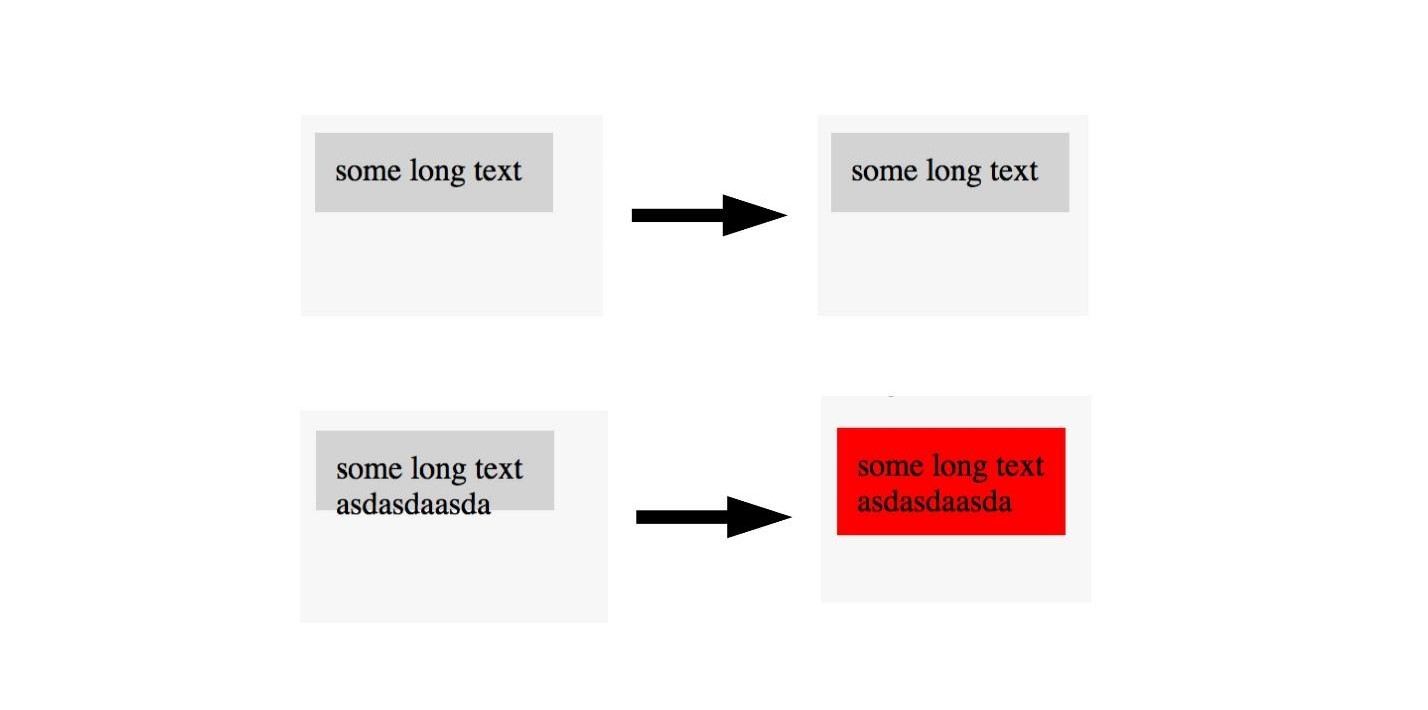
如果我们看到图片的布局很好,那么我们就不会对其进行标记,而会将图片标记为布局不好。 因此,您可以使用一张图片来测试布局。 , , , . U-Net .
, , . , U-Net, . , .
LSTM. Twitter — 2000
, , , .
, LSTM . 40 - , :
« — » .
, :

- , ?
— . - :


, «» , , (, ).
:
« » « » .
— .
« ».
:

EPOCS 250
, .
- , , , . , Overfitting — .
, — . , , . , , , .
, , .
, .

, , , . ( , ), . .
— . .
overfitting. , helper-: Dropout; BatchNormalization.
LSTM. Prettier
, — Prettier . , .
const a = 1 . :
[]c co on ns st , , :
[][] []c co on ns st , .
, , .
, , . , , 0 — , - , - . .
, . .
而不是结论
, , . . , , Deep Neural Network.
. , . . . .
JS, , . , . , JavaScript, . TensorFlow.js.
, . telegram- JS.FrontendConf , 13 . 32 .
, , . Saint AppsConf, . , , , .