注意事项 佩雷夫 :来自Zalando的首席工程师Henning Jacobs反复注意到Kubernetes用户在了解活动(和就绪)探针的目的及其正确应用方面存在的问题。 因此,他将自己的想法收集到了这篇宽敞的文章中,随着时间的推移,它将成为K8s文档的一部分。
健康检查(在Kubernetes中称为
活动性探针) (即从字面上讲是“生存力测试”-大约是Transl。)可能非常危险。 我建议尽可能避免使用它们:唯一的例外是在确实需要它们的情况下,并且您充分了解使用它们的细节和后果。 该出版物将重点关注活力和准备情况检查,还将说明在哪些情况下
值得和不值得使用它们。
我的同事桑多尔(Sandor)最近在Twitter上分享了他遇到的最常见错误,包括与使用就绪/活跃度探针相关的错误:
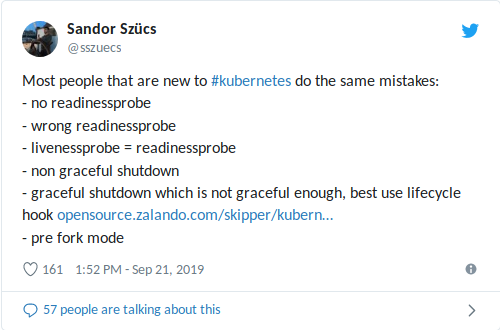
livenessProbe配置不当会加重负载(雪崩关闭+容器/应用程序可能长时间启动)的情况,并导致其他负面后果,例如依赖关系下降
(另请参阅我最近关于限制K3s + ACME捆绑包中请求数量的文章 ) 。 更糟糕的是,将活动性探针与作为外部数据库的运行状况检查结合使用时,
唯一的数据库故障将重新启动所有容器 !
在这种情况下,一般性消息
“请勿使用活动性探针”会有所帮助,因此,我们将考虑准备情况和活动性检查的用途。
注意:下面的大多数测试最初都包含在Zalando开发人员的内部文档中。准备和生活检查
Kubernetes提供了两个重要的机制,称为
活动性探针和就绪性探针 。 他们定期执行某些操作(例如,发送HTTP请求,打开TCP连接或在容器中执行命令)以确认应用程序正常运行。
Kubernetes使用
就绪性探针来了解容器何时准备接收流量。 如果已将其所有容器准备就绪,则认为吊舱已准备就绪。 该机制的一种应用是控制将哪些Pod用作Kubernetes服务(尤其是Ingress)的后端。
活动性探针可帮助Kubernetes了解何时重新启动容器。 例如,通过这种检查,您可以在应用程序“卡住”一个位置时拦截死锁。 尽管有错误,但在这种状态下重新启动容器有助于将应用程序移离地面,但也可能导致级联失败(请参阅下文)。
如果您尝试将更新部署到未通过活动性/就绪性检查的应用程序,则由于Kubernetes将等待来自所有Pod的
Ready状态,因此推出将停滞不前。
例子
这是一个准备情况探针示例,它使用默认设置(
间隔 :10秒,
超时 :1秒,
成功阈值 :1,
故障阈值 :3)通过HTTP检查
/health路径:
# deployment'/ podTemplate: spec: containers: - name: my-container # ... readinessProbe: httpGet: path: /health port: 8080
推荐建议
- 对于具有HTTP端点(REST等)的微服务,请始终定义一个就绪探针 ,以检查应用程序(pod)是否准备好接收流量。
- 确保准备就绪探针涵盖了实际Web服务器端口的可用性 :
- 使用用于管理需求的端口“ readnessProbe”(称为“ admin”或“ management”(例如9090)),确保仅当主HTTP端口(如8080)已准备好接受流量时,端点才返回OK。
*我知道Zalando中至少有一种情况没有发生,即, readinessProbe检查了“ management”端口,但是由于加载缓存的问题,服务器本身没有启动。 - 将准备就绪探针挂在单独的端口上可能会导致以下事实:运行状况检查不会反映主端口上的拥塞(也就是说,服务器上的线程池已满,但是运行状况检查仍然表明一切正常)。
- 确保准备就绪探针启用数据库初始化/迁移 ;
- 最简单的方法是仅在初始化完成后才能访问HTTP服务器(例如,从Flyway迁移数据库等); 也就是说,仅在完成数据库迁移*之后才启动Web服务器,而不是更改运行状况检查的状态。
*您还可以从pod外部的init容器运行数据库迁移。 我仍然是独立应用程序的忠实拥护者,也就是说,在那些应用程序容器无需外部协调的情况下,他们知道如何将数据库置于所需的状态。
- 使用
httpGet进行健康检查的典型端点(例如/health )的准备情况检查。 successThreshold: 1 设置 ( interval: 10s , timeout: 1s , successThreshold: 1 , failureThreshold: 3 ):- 默认参数表示pod会在大约30秒后(3个运行状况检查失败)变为未就绪状态。
- 如果技术堆栈(例如Java / Spring)允许将健康和指标的管理与常规流量分开,请使用单独的端口进行“管理”或“管理”:
- 如有必要,可以使用就绪探针来预热/加载缓存并返回状态码503,直到“预热”容器为止:
- 我还建议您熟悉新的
startupProbe检查, 该检查出现在1.16版中 (我们在此处用俄语写过-大约是transl。) 。
警告事项
- 在进行准备/活跃度测试时, 请勿依赖外部依赖项 (例如数据存储), 否则可能导致级联失败:
- 举例来说,让我们使用一个有状态的REST服务,其中有10个Pod,取决于一个Postgres数据库:当检查取决于与数据库的有效连接时,如果网络/数据库方面存在延迟,则所有10个Pod都可能掉线-通常情况下,一切结局都比它可能的糟。
- 请注意,Spring Data默认情况下会检查与数据库的连接*;
*这是Spring Data Redis的默认行为(至少就像我上次检查时一样),从而导致“灾难性”故障:当Redis短时间内不可用时,所有pod都“掉落”。 - 从这个意义上说,“外部”也可能意味着同一应用程序的其他容器,也就是说,理想情况下,检查不应依赖于同一集群的其他容器的状态,以防止级联崩溃:
- 结果对于分布式状态应用程序可能有所不同(例如Pod中的内存中缓存)。
- 请勿对吊舱使用活动性探针 (在某些情况下,确实需要使用吊舱,并且您完全了解使用吊舱的细节和后果):
- 活动度探针可以帮助恢复“挂起”的容器,但是由于您完全控制了应用程序,因此理想情况下不应发生“挂起”进程和死锁之类的事情:最好的选择是有意删除该应用程序并将其返回给先前的稳定状态;
- 失败的活动性探针将重新启动容器,从而可能加剧加载错误的后果:重新启动容器将导致停机时间(至少在应用程序启动时间(例如,超过30秒)),导致新的错误,从而增加了负载其他容器并增加其失效的可能性等;
- 活动性检查与外部依赖项结合在一起是最糟糕的组合,这可能导致级联失败:数据库方面的轻微延迟将导致所有容器重新启动!
- 活动性和准备情况检查的参数应该不同 :
- 您可以将活动性探针与相同的运行状况检查一起使用,但是可以使用较高的阈值(
failureThreshold ),例如,在3次尝试后将状态分配为未就绪 ,并假设活动性探针在10次尝试后失败;
- 不要使用exec检查 ,因为它们与导致僵尸进程出现的已知问题相关:
总结
- 使用准备情况探针来确定Pod何时准备接收流量。
- 仅在确实需要活动探针时才使用它们。
- 错误使用准备状态/活动状态探针会导致可用性降低和级联故障。

关于该主题的其他材料
从2019-09-29更新No1
关于用于数据库迁移的初始化容器 :添加了脚注。
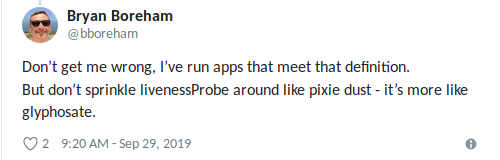
EJ让我想起了PDB:活力检查的麻烦之一是吊舱之间缺乏协调。 Kubernetes具有
Pod中断预算(PDB)来限制应用程序可能遇到的并发故障数,但是检查未考虑PDB。 理想情况下,我们可以订购K8:“如果验证失败,请重新启动一个Pod,但不要重新启动它们,以免使情况变得更糟。”
布莱恩(Bryan)完美地制定了一个规则 :“当您确定
可以做的
最好的事情是“杀死”该应用程序时 (再次,不要被带走),使用生动的声音。
从2019-09-29更新2号
关于使用前阅读文档 :我创建了一个
功能请求,以补充有关活动性探针的文档。
译者的PS
另请参阅我们的博客: