嗨,habrozhiteli! 我们最近将克里斯·伯恩哈德(Chris Bernhard)的
书《量子计算用于真实IT》移交给了我们。 在这里,他们决定分享“ Grover的算法和数据搜索”这本书的摘录
我们正在进入大数据时代。 当前,有效搜索巨大的数据集已成为许多大公司关注的焦点。 Grover的算法在理论上能够加速数据检索。
Love Grover于1996年发明了他的算法。 与Deutsch和Simon的算法一样,在查询复杂度方面,与传统算法相比,它具有更高的执行速度。 但是,如果没有Oracle提出问题,我们将无法实现当前的数据检索算法。 我们必须构造一个执行预言工作的算法。 但是在开始讨论Grover算法的实现之前,让我们先看看它的作用和作用。
格罗弗算法
假设您有四张扑克牌。 他们被颠倒了。 您知道其中之一是蠕虫的高手,您需要找到它。 在知道蠕虫的王牌位置之前,您需要翻转几张纸牌?
如果幸运的话,您会在第一次尝试时找到所需的卡片;如果不幸运的话,可以翻转三张卡片,但它们都不是蠕虫的王牌。 在最坏的情况下,交出三张卡,您肯定会知道最后一张卡是您要寻找的蠕虫的王牌。 因此,我们可以通过从一张牌翻到三张牌来找出王牌。 平均而言,您需要翻转2.25张卡片。
这是Grover算法解决的任务之一。 在开始描述算法之前,我们对问题进行重新表述。 我们有四个二进制序列:00、01、10和11。我们有一个函数f,它为其中三个序列返回0,为第四序列返回1。 我们需要找到对应于输出值1的二进制序列。例如,我们可以得到以下结果:f(00)= 0,f(01)= 0,f(10)= 1和f(11)=0。现在的问题是就是找出应该计算多少次函数才能得到结果f(10)=1。在这里,我们简单地通过用函数替换扑克牌来对问题进行重新表述,因此该问题的答案已经为人所知:与以前一样,平均而言,必须计算函数2.25倍。
与所有复杂性查询算法一样,我们构造一个oracle-封装函数的门。 图中显示了我们的示例的oracle,其中只有四个二进制序列。 9.1。
Grover算法的链如图2所示。 9.2。
该算法执行两个步骤。 首先,概率振幅的符号被翻转,与我们试图找到的位置相关。 第二个加强了这个概率幅度。 让我们看看连锁店是如何做到的。
通过Hadamard阀传输后,两个较高的量子位获得状态
较低的量子位具有状态
组合状态可以写成
量子位然后通过门F。它将第三个量子位中的0和1反转到我们要查找的位置。 对于我们的情况f(10)= 1我们得到
可以重写为
结果,我们得到了两个较高的量子位,而不是与较低的量子位相混淆,而是概率的幅度
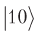
将更改符号,指示所需的位置。
如果在此步骤中测量高两个量子位,我们将得到四个位置之一,并且所有四个可能的答案都是同等可能的。 我们需要采取另一步-增加概率的幅度。 放大是通过反转数字相对于其平均值的顺序来进行的。 如果该数字高于平均值,它将翻转并变为低于平均值。 如果数字低于平均数,它将翻转并变为高于平均数。 在每种情况下,都保持远离平均值的位置。 为了说明,我们使用四个数字:1、1、1和–1。 它们的总和为2,平均值为2/4,即1/2。 然后,我们开始对序列中的数字进行排序。 第一个数字是1。它是平均值的1/2。 政变后,应比平均水平低1/2。 在这种情况下,它将变为0。数字–1比平均值低3/2。 政变后,它应该变成平均值的3/2,即变成2。
当前有两个高位qubit处于状态
相对于平均值转动幅度,我们得到

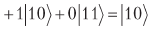
。
完成测量后,我们肯定会得到10,也就是说,相对于平均值的公转将为我们提供所需的确切信息。 我们要做的就是确保有一个门,或者说是正交的矩阵,该矩阵描述相对于平均值的旋转。 存在这样的矩阵:
由于阀对上两个量子位的作用,我们得到
在此示例中,如果只有两个量子位,则应仅使用一次oracle。 我们只问一个问题就足够了。 对于n = 2的情况,Grover算法在单个问题后给出了确切的答案,而在经典情况下,平均而言,需要提出2.25个问题。
这个想法扩展到任意数量的n个量子比特的情况。 我们首先旋转概率幅度的符号,该符号对应于所需的位置。 然后我们进行相对于平均值的革命。 然而,在这种情况下,幅度的放大不会像在两个量子位的情况下那样显着地发生。 以八个数字为例,其中七个为1,一个为-1。 他们的总和是6,平均是6/8。 翻转后,平均值1将变成1/2,而–1将变成10/4。 结果,在存在三个量子位的情况下,在幅度放大之后测量一个量子位,我们将比其他位置以更高的概率获得所需的位置。 问题是有很大的机会得到错误的答案。 我们需要更高的概率来获得正确的答案-我们需要在测量之前进一步放大幅度。 解决方案是将所有量子比特通过链传回。 我们再次翻转与所需位置相关的概率幅度的符号,并再次相对于平均值翻转。
考虑一般情况。 我们需要在m个可能的位置之一中找到某物。 要以经典方式找到它,在最坏的情况下,我们必须问m-1个问题。 问题的数量与m成正比。 Grover计算了一个公式,该公式确定需要使用多少次链才能获得正确答案的最大概率。 该公式给出的数字成比例增长
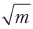
。 这是二次加速。
Grover算法应用
该算法的实现存在几个问题。 首先,相对于复杂度要求评估二次加速度。 要使用oracle,您需要创建它,并且如果您不谨慎执行此任务,则oracle执行的步骤数将超过算法节省的步骤数,结果,该算法将变得比传统算法慢而不是快。 另一个问题是,通过确定加速度,我们假设数据集是混乱的。 如果数据集具有特定的结构,则通常可以找到使用该结构的经典算法,并更快地找到解决方案。 最后一个问题与加速度有关。 二次加速度无非就是指数加速度,这是我们在其他算法中观察到的。 有可能取得更多成就吗? 让我们看看这些问题。
与oracle的实现相关的问题以及数据集中结构的存在都被证明是合理的,并且表明在大多数情况下,Grover算法在搜索数据库方面没有实际应用。 但是在某些情况下,在数据中具有结构可以创建高效执行的预言。 在这种情况下,该算法可能会超越经典算法。 已经给出了获得更大成功的可能性的答案。 证明了格罗弗算法是最优的。 没有量子算法能够解决超过二次加速的问题。 二次加速虽然不如指数般令人印象深刻,但仍提供了一些好处。 在处理大型数据集时,任何加速都是有价值的。
Grover算法很可能会找到主要应用程序,而不是如上所述的搜索方法,而是找到其主要变体。 特别地,放大幅度的想法可能派上用场。
我们只研究了几种算法,但是Shore和Grover算法被认为是最重要的。 基于这两个固有的思想,还有许多其他算法。1现在,让我们将注意力从量子算法转移到量子计算的其他应用领域。