
引言
您好,亲爱的哈布罗维特!
我在
Synesis工作的最后两年与创建和开发
Synet的过程紧密相关,
Synet是一个开放库,用于在CPU上运行经过预训练的卷积神经网络。 在这项工作的过程中,我不得不遇到许多有趣的问题,这些问题与神经网络中直接信号传播算法的优化有关。 在我看来,对这些观点的描述对于哈布拉哈伯的读者来说将非常有趣。 我想专门介绍我的一系列文章。 周期的持续时间将取决于您对此主题的兴趣,当然还取决于我克服懒惰的能力。 我想以
自行车框架本身的描述开始这个周期。 构成其基础的算法的问题将在后续文章中披露:
- 卷积层:矩阵乘法优化技术
- 卷积层:根据Shmuel Vinograd的方法进行快速卷积
问题答案
在开始详细描述框架之前,我将尝试立即回答读者可能会遇到的许多问题。 经验表明,最好这样做,因为许多人会立即开始写愤怒的评论,而不是读到最后。
在这种情况下通常会出现第一个问题:
现在谁在常规处理器上运行网络,何时会有图形加速器和张量(矩阵)加速器?我会回答是的-确实不建议在CPU上进行神经网络的训练,但是运行现成的神经网络是非常必要的,尤其是在网络足够小的情况下。 其原因可能有所不同,但主要有以下原因:
- CPU更常见。 并非所有机器都具有GPU,尤其是服务器。
- 在小型神经网络上,使用GPU的收益很小,有时甚至完全没有。
- 有效地利用GPU来加速神经网络通常需要复杂得多的应用程序结构。
下一个可能的问题:
当存在Tensorflow , Caffe或MXNet时,为什么要使用专门的解决方案来启动?您可以回答以下问题:
- 各种各样的框架并不总是很好-因此,如果在一个项目中有多个在不同框架中训练的模型,那么您将不得不将它们全部嵌入到现成的解决方案中,这非常不方便。
- 经典框架旨在训练GPU模型-它们肯定擅长这一点! 但是要在CPU上运行经过训练的模型,它们的功能是多余的,而且不是最佳的。
- 确认需要专用解决方案是OpenVINO的流行-OpenVINO是Intel的一种框架,具有相同的功能。
在这里,关于自行车的发明立即引起一个逻辑问题:
为什么要使用公认的世界领先者提供的完全专业的解决方案来使用您的手工艺品?我的答案是:
- 在Synet上开始工作时,OpenVINO仍处于起步阶段。 实际上,如果那时OpenVINO处于当前状态,那么我很有可能不会参与我自己的项目。
- 您可以根据需要调整自己的框架。 因此,在我的情况下,主要要求是最大的单线程性能。
- 如果您突然需要新功能,则可以尽快为其提供支持(例如,添加新层并消除性能错误)。
- 易于集成到交钥匙解决方案中。
- 库在x86 / x86_64以外的平台上的功能-例如,在ARM上。
读者可能会有其他问题或异议-但我仍然无法预测它们,因此我将在对本文的评论中回答。 同时,让我们开始对Synet进行直接描述。
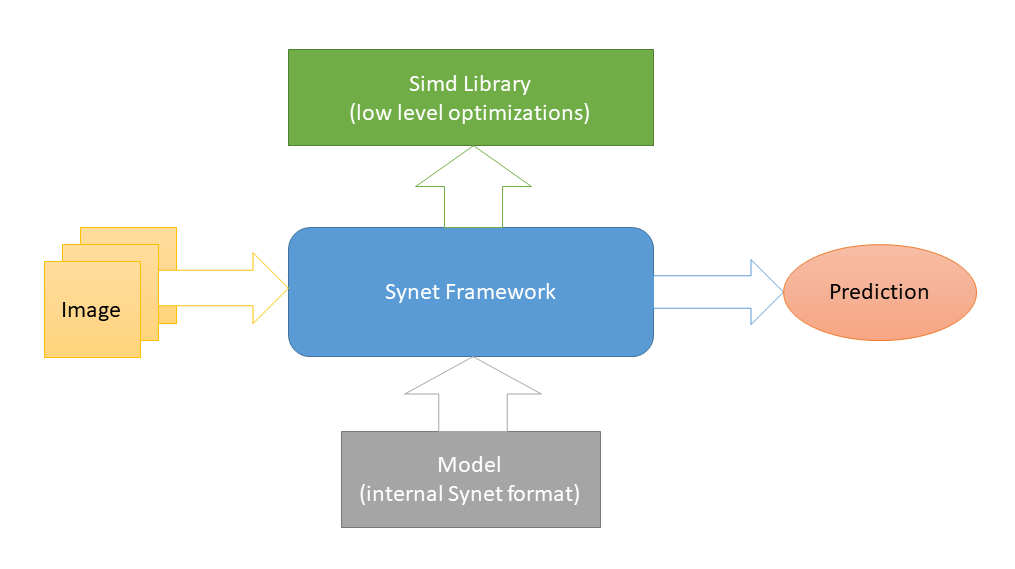
Synet简短说明
Synet用
C ++编写,仅包含
头文件 。 在
特定于底层平台的优化是在
Simd中实现的,
Simd是另一个致力于加速CPU上图像处理的开源项目。 这是Synet的唯一外部依赖项(选择这种方案是为了促进将库集成到第三方项目中)。 为了启动神经网络,使用其内部格式的模型。
将预训练模型转换为内部格式的过程分为两步:1)首先,将模型转换为推理引擎格式(好的
OpenVINO具有为此所需的所有必要
工具 )。 2)然后,从此中间表示形式直接转换为内部Synet格式。

Synet模型包含两个文件:1)* .XML-一个描述模型结构的文件。 2)* .BIN-具有经过训练的权重的文件。

同义词的例子
以下是使用Synet检测面部的示例。 原始的推理引擎模型
在这里采用 。
#define SYNET_SIMD_LIBRARY_ENABLE #include "Synet/Network.h" #include "Synet/Converters/InferenceEngine.h" #include "Simd/SimdDrawing.hpp" typedef Synet::Network<float> Net; typedef Synet::View View; typedef Synet::Shape Shape; typedef Synet::Region<float> Region; typedef std::vector<Region> Regions; int main(int argc, char* argv[]) { Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin"); Net net; net.Load("synet.xml", "synet.bin"); net.Reshape(256, 256, 1); Shape shape = net.NchwShape(); View original; original.Load("faces_0.ppm"); View resized(shape[3], shape[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea); net.SetInput(resized, 0.0f, 255.0f); net.Forward(); Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f); uint32_t white = 0xFFFFFFFF; for (size_t i = 0; i < faces.size(); ++i) { const Region & face = faces[i]; ptrdiff_t l = ptrdiff_t(face.x - face.w / 2); ptrdiff_t t = ptrdiff_t(face.y - face.h / 2); ptrdiff_t r = ptrdiff_t(face.x + face.w / 2); ptrdiff_t b = ptrdiff_t(face.y + face.h / 2); Simd::DrawRectangle(original, l, t, r, b, white); } original.Save("annotated_faces_0.ppm"); return 0; }
作为该示例的结果,应该显示带有带注释的面孔的图片:

现在让我们以步骤为例:
- 首先,将模型从推理引擎格式转换为Synet:
Synet::ConvertInferenceEngineToSynet("ie_fd.xml", "ie_fd.bin", true, "synet.xml", "synet.bin");
实际上,此步骤仅执行一次,然后已转换的模型将在各处使用。 - 下载转换后的模型:
Net net; net.Load("synet.xml", "synet.bin");
- 调整输入图像和批处理大小的可选步骤(自然,模型必须支持调整输入图像的大小):
net.Reshape(256, 256, 1);
- 加载图片并将其带入模型的输入大小:
View original; original.Load("faces_0.ppm"); View resized(net.NchwShape()[3], net.NchwShape()[2], original.format); Simd::Resize(original, resized, ::SimdResizeMethodArea);
- 将图像加载到模型中:
net.SetInput(resized, 0.0f, 255.0f);
- 开始在网络中直接传播信号:
net.Forward();
- 获取具有找到的面孔的一组区域:
Regions faces = net.GetRegions(original.width, original.height, 0.5f, 0.5f);
性能比较
将Synet与经典的机器学习框架进行比较可能并不完全正确,例如,推理引擎
在许多测试中多次绕过它们 。
因此,以下是在一
组开放模型的样本上比较推理引擎(具有类似功能的产品)和Synet的单线程性能的示例:
从表中可以看出,在支持AVX2(i7-6700)的机器上进行的这些测试中,Synet的性能通常与推理引擎的性能相对应(尽管不同型号之间的性能差异很大)。 在支持AVX-512(i9-7900X)的计算机上,Synet的性能平均比推理引擎高25%。
所有测量均由Synet中的测试应用程序执行。 因此,如果需要,读者将能够自己重现测试:
git clone -b master --recurse-submodules -v https://github.com/ermig1979/Synet.git synet cd synet ./build.sh inference_engine ./test.sh
优缺点
我将从专家开始:
- 该项目的规模很小,很容易在第三方项目中实施。
- 显示高单线程性能。
- 在移动处理器上工作(支持ARM-NEON)。
好与不好,如果没有它们:
- 不支持GPU和其他特殊的加速器。
- 多核CPU上一项任务的并行性差。
- 不支持INT8(权重量化)。
结论
Synet目前被用作
Kipod项目的一部分,该项目是基于云的视频分析平台。 也许他还有其他用户,但是不确定:)。 将来,随着项目的发展,我想在其中添加以下内容:
- 支持新的模型,层,算法。
- 支持INT8格式的整数计算(量化的权重)。
- GPU计算支持。
- 从ONNX格式转换。
该列表远非完整,我想参考社区的意见对它进行补充-因此,我在等待您的反馈! 使该工具不仅对我们公司有用,而且对广泛的用户有用。 而且,作者不会拒绝开发过程中的社区帮助。
在描述我在本文中介绍的Synet时,我故意没有深入研究其内部实现的细节-幕后有很多不错的算法,但是我想在本系列的以下文章中公开其实现的细节:
- 卷积层:矩阵乘法优化技术
- 卷积层:根据Shmuel Vinograd的方法进行快速卷积