
这是在服务器硬件领域非常普遍的神话。 在实践中,超融合解决方案(全合时)需要很多功能。 从历史上看,第一个架构是由Amazon和Google为它们的服务开发的。 然后的想法是建立一个由相同节点组成的计算场,每个节点都有自己的驱动器。 所有这些都由一些系统形成软件(管理程序)组合在一起,并且已经划分为虚拟机。 主要任务是最小的维护一个节点的工作量和最小的扩展问题:我们刚购买了另外一千或两台相同的服务器并在附近连接。 实际上,这些是孤立的情况,我们经常谈论的是较少数量的节点和稍微不同的体系结构。
但是优点仍然是相同的-难以置信的扩展和控制。 减号-不同的任务消耗资源的方式不同,在某个地方将有许多本地磁盘,在某个地方将几乎没有RAM,依此类推,也就是说,对于不同类型的任务,资源利用率将下降。
事实证明,为便于设置,您要多付10-15%。 这引起了大标题神话。 我们寻找了将技术最佳应用的很长时间,然后找到了它。 事实是Tsiska没有自己的存储系统,但他们想要一个完整的服务器市场。 他们制作了Cisco Hyperflex,这是节点上的本地存储解决方案。
突然之间,这对于备份数据中心(灾难恢复)来说是一个非常好的解决方案。 为什么和如何-现在我要说。 我将展示集群测试。
去哪里
超融合是:
- 将磁盘转移到计算节点。
- 存储子系统与虚拟化子系统的完全集成。
- 传输/与网络子系统集成。
通过这种组合,您可以从一个控制窗口在虚拟化级别实现存储系统的许多功能。
在我们公司中,对备份数据中心的设计项目有很高的需求,通常选择超融合解决方案是因为开箱即用的复制选项堆(最多城域集群)。
对于备用数据中心,通常是城市另一端或一般其他城市中的站点上的远程设施的问题。 如果主数据中心发生部分或全部故障,它使您可以还原关键系统。 销售数据一直在此处复制,并且此复制可以在应用程序级别或块设备级别(SHD)进行。
因此,现在我将讨论系统的设备和测试,然后再讨论一些具有节省数据的实际情况。
测验
我们的副本包括四台服务器,每台服务器每960 GB具有10个SSD磁盘。 有一个专用磁盘用于缓存服务虚拟机的写操作和存储。 解决方案本身是第四个版本。 坦率地说,第一个是原始的(通过评论判断),第二个是潮湿的,第三个已经相当稳定,可以将其称为Beta测试结束后的发行版本。 在测试我没有看到的问题时,一切都像时钟一样工作。
v4的变化修复了许多错误。
最初,该平台只能与VMware ESXi虚拟机管理程序配合使用,并支持少量节点。 此外,部署过程并不一定总是成功结束,我必须重新启动一些步骤,在从旧版本进行更新时会遇到问题,GUI中的数据并非总是能正确显示(尽管我对显示性能图表仍然不满意),有时虚拟化界面存在问题。
现在,所有儿童的疮已得到修复,HyperFlex可以同时执行ESXi和Hyper-V,而且还可以:
- 创建拉伸集群。
- 在不使用Fabric Interconnect的情况下为办公室创建集群,该集群有两个到四个节点(我们仅购买服务器)。
- 能够使用外部存储。
- 支持容器和Kubernetes
- 创建可访问区域。
- 如果内置功能不合适,则与VMware SRM集成。
该架构与主要竞争对手的决定并没有太大不同;他们没有开始制造自行车。 所有这些都可以在VMware或Hyper-V虚拟化平台上运行。 托管在Cisco UCS专有服务器上的硬件。 有些人讨厌平台的初始设置的相对复杂性,有很多按钮,一个不平凡的模板和依赖项系统,但是也有一些学习Zen的人受到了这一想法的启发,不再希望与其他服务器一起工作。
我们将考虑专门针对VMware的解决方案,因为该解决方案最初是为VMware创建的,并且具有更多功能,在此过程中添加了Hyper-V,以与竞争对手保持一致并满足市场期望。
有一个群集服务器,其中装有磁盘。 有用于数据存储的磁盘(SSD或HDD-根据您的喜好和需求),有一个SSD磁盘用于缓存。 将数据写入数据存储时,数据将保存在缓存层(专用SSD磁盘和服务VM RAM)上。 并行地,数据块被发送到集群中的节点(节点数取决于集群复制因子)。 在从所有节点确认成功记录后,将记录确认发送到虚拟机监控程序,然后再发送到VM。 后台记录的数据将被重复数据删除,压缩并写入存储磁盘。 同时,大块总是按顺序写入存储磁盘,从而减少了存储磁盘上的负载。
重复数据删除和压缩始终处于启用状态,无法禁用。 数据直接从存储磁盘或RAM缓存中读取。 如果使用混合配置,则读取内容也将缓存在SSD上。
数据不绑定到虚拟机的当前位置,而是在节点之间平均分配。 这种方法允许您平均加载所有驱动器和网络接口。 明显的减号是:我们不能最小化读取延迟,因为不能保证本地数据的可用性。 但是我相信,与收到的好处相比,这是微不足道的牺牲。 此外,网络延迟已达到这样的值,以至于它们实际上不会影响总体结果。
对于磁盘子系统的所有逻辑,Cisco HyperFlex Data Platform控制器的特殊服务VM负责,该VM在每个存储节点上创建。 在我们的服务VM配置中,分配了8个vCPU和72 GB的RAM,这个数目并不小。 让我提醒您,主机本身具有28个物理核心和512 GB RAM。
通过将SAS控制器转发到虚拟机,服务虚拟机可以直接访问物理磁盘。 与虚拟机管理程序的通信通过特殊的IOVisor模块进行,该模块拦截I / O操作,并使用允许您将命令传输到虚拟机管理程序API的代理。 该代理负责处理HyperFlex快照和克隆。
在虚拟机管理程序中,磁盘资源作为NFS或SMB球挂载(取决于虚拟机管理程序的类型,请猜测是哪个)。 在后台,这是一个分布式文件系统,使您可以添加成人完整存储系统的功能:精简卷分配,压缩和重复数据删除,使用写时重定向技术的快照,同步/异步复制。
Service VM提供对HyperFlex子系统管理的WEB界面的访问。 它与vCenter集成在一起,并且大多数日常任务都可以通过它执行,但是例如,如果您已经切换到快速HTML5界面或使用具有完全集成功能的完整Flash客户端,则从单独的网络摄像头中剪切数据存储区将更加方便。 在服务网络摄像头中,您可以查看系统的性能和详细状态。
集群中还有另一种节点-计算节点。 它可以是不带内置驱动器的机架式或刀片式服务器。 在这些服务器上,您可以运行VM,其数据通过磁盘存储在服务器上。 从数据访问的角度来看,节点类型之间没有区别,因为该体系结构涉及从数据的物理位置进行抽象。 计算节点与存储节点的最大比例为2:1。
使用计算节点可以在扩展群集资源时提高灵活性:如果只需要CPU / RAM,就不必购买带有磁盘的节点。 另外,我们可以添加刀片服务器篮并节省机架服务器空间。
因此,我们拥有一个具有以下功能的超融合平台:
- 群集中最多64个节点(最多32个存储节点)。
- 群集中的最小节点数为3(对于Edge群集,为2)。
- 数据冗余机制:使用复制因子2和3进行镜像。
- 地铁集群。
- 异步VM复制到另一个HyperFlex群集。
- 将虚拟机切换到远程数据中心的流程。
- 使用写重定向技术的本机快照。
- 具有复制因子3且无重复数据删除功能的最大可用空间为1 PB。 我们不考虑复制因子2,因为这不是严重出售的选择。
另一个巨大的优点是易于管理和部署。 配置UCS服务器的所有复杂性均由思科工程师准备的专用VM处理。
测试平台配置:
- 2个Cisco UCS Fabric Interconnect 6248UP作为管理群集和网络组件(48个端口以以太网10G / FC 16G模式运行)。
- 四个Cisco UCS HXAF240 M4服务器。
服务器功能:
更多配置选项除了选定的熨斗,当前还有以下选项:
- HXAF240c M5。
- 一两个CPU,范围从Intel Silver 4110到Intel Platinum I8260Y。 第二代可用。
- 24个内存插槽,从16 GB RDIMM 2600到128 GB LRDIMM 2933的板条。
- 6到23个数据磁盘,一个高速缓存磁盘,一个系统和一个引导磁盘。
容量驱动器- HX-SD960G61X-EV 960GB 2.5英寸企业价值6G SATA SSD(1X耐久性)SAS 960 GB。
- HX-SD38T61X-EV 3.8TB 2.5英寸企业级6G SATA SSD(1X耐久性)SAS 3.8 TB。
- 缓存驱动程序
- HX-NVMEXPB-I375 375GB 2.5英寸Intel Optane驱动器,具有出色的性能和耐用性。
- HX-NVMEHW-H1600 * 1.6TB 2.5英寸Ent。 性能 NVMe SSD(3倍耐力)NVMe 1.6 TB。
- HX-SD400G12TX-EP 400GB 2.5英寸Ent。 性能 12G SAS SSD(10倍耐力)SAS 400 GB。
- HX-SD800GBENK9 ** 800GB 2.5英寸Ent。 性能 12G SAS SED SSD(10倍耐力)SAS 800 GB。
- HX-SD16T123X-EP 1.6TB 2.5英寸企业级性能12G SAS SSD(3倍耐力)。
系统/日志驱动器- HX-SD240GM1X-EV 240GB 2.5英寸企业级6G SATA SSD(需要升级)。
启动驱动- HX-M2-240GB 240GB SATA M.2固态硬盘SATA 240 GB。
通过40G,25G或10G以太网端口连接到网络。
作为FI,可以是HX-FI-6332(40G),HX-FI-6332-16UP(40G),HX-FI-6454(40G / 100G)。
自我测试
为了测试磁盘子系统,我使用了HCIBench 2.2.1。 这是一个免费的实用程序,可让您自动从多个虚拟机创建负载。 负载本身是由常规fio生成的。
我们的集群由四个节点(复制因子3)和所有闪存驱动器组成。
为了进行测试,我创建了四个数据存储和八个虚拟机。 对于写测试,假定缓存磁盘未满。
测试结果如下:
表示粗体值,之后生产率没有增加,有时甚至可见到退化。 由于我们依赖网络性能/控制器/驱动器。- 顺序读取4432 MB /秒。
- 顺序写入804 MB / s。
- 如果一个控制器发生故障(虚拟机或主机故障),则性能下降将翻倍。
- 如果存储驱动器发生故障,则压降为1/3。 固定磁盘占用每个控制器的5%的资源。
在一个很小的块中,我们遇到了控制器(虚拟机)的性能,它的CPU负载为100%,同时增加了我们遇到的端口带宽块。 10 Gbps不足以释放AllFlash系统的潜力。 不幸的是,提供的演示架的参数不允许以40 Gbps的速度检查工作。
在测试和体系结构研究的印象中,由于将数据放置在所有主机之间的算法,我们获得了可扩展的可预测性能,但是这也是读取时的局限性,因为有可能从本地磁盘中挤出更多数据,更多为了节省生产力更高的网络,例如,可以使用40 Gbps FI。
此外,一个用于缓存和重复数据删除的磁盘可能会受到限制;实际上,在这种情况下,我们可以在四个SSD磁盘上进行写入。 能够增加高速缓存的磁盘数量并看到差异将是很棒的。
实际使用
可以使用两种方法来组织备份数据中心(我们不考虑将备份放置在远程站点上):
- 主动被动 所有应用程序都托管在主数据中心中。 复制是同步或异步的。 万一主数据中心发生故障,我们需要激活备份中心。 这可以通过/脚本/编排应用程序手动完成。 在这里,我们得到与复制频率相对应的RPO,RTO取决于管理员的反应和技能以及交换计划的开发/调试质量。
- 主动主动 在这种情况下,仅存在同步复制,数据中心的可用性由严格置于第三平台上的仲裁/仲裁程序确定。 RPO = 0,并且RTO可以达到0(如果应用程序允许)或等于对虚拟化群集中的节点进行故障转移的时间。 在虚拟化级别上,将创建一个需要Active-Active存储的扩展(Metro)群集。
通常,我们会与客户一起在主数据中心中看到一种已经实现的,具有经典存储的架构,因此我们设计了另一种用于复制。 如前所述,Cisco HyperFlex提供异步复制和扩展虚拟化集群的创建。 同时,我们不需要具有两个服务器上昂贵的复制功能和Active-Active数据访问功能的专用中型或更高级别的存储系统。
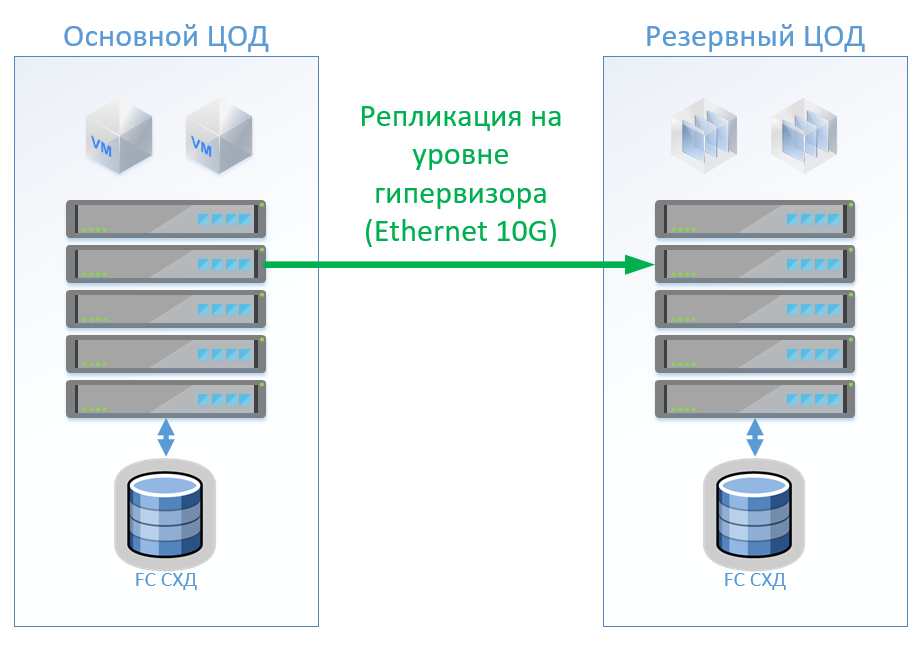
方案1:我们有主数据中心和备份数据中心,这是VMware vSphere上的虚拟化平台。 所有生产系统都主要位于数据中心,并且虚拟机复制是在虚拟机管理程序级别执行的,这将不允许在备份数据中心中保持打开虚拟机的状态。 我们使用内置工具复制数据库和特殊应用程序,并保持打开虚拟机的状态。 如果主数据中心发生故障,我们将在备用数据中心启动系统。 我们相信我们有大约100个虚拟机。 只要主数据中心处于运行状态,就可以在备用数据中心中启动测试环境和其他系统,如果切换了主数据中心,则可以禁用该环境。 我们也可能使用双向复制。 从设备的角度来看,什么都不会改变。
在经典架构的情况下,我们将在每个数据中心中放置一个混合存储系统,并通过FibreChannel进行访问,撕裂,重复数据删除和压缩(但不在线),每个站点8个服务器,2个FibreChannel交换机和10G以太网。 对于经典体系结构中的复制和交换控制,我们可以使用VMware工具(Replication + SRM)或第三方工具,它们会稍微便宜一些,有时会更方便。
该图显示了一个示意图。
如果使用Cisco HyperFlex,您将获得以下架构:
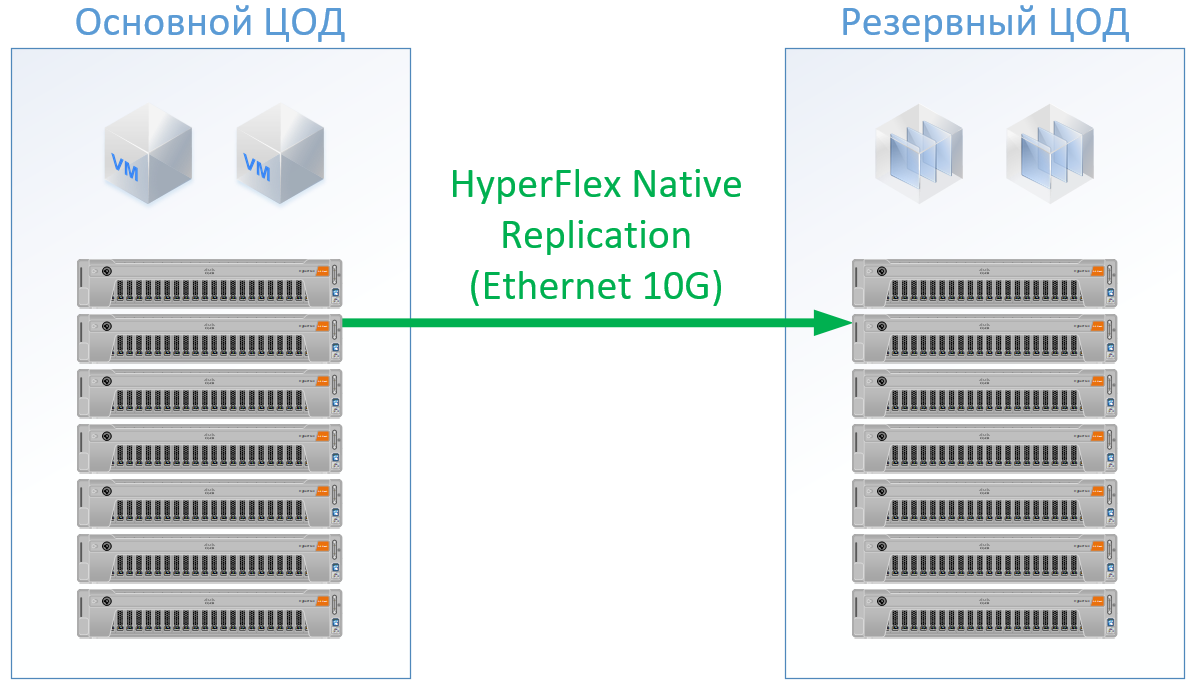
对于HyperFlex,我使用了具有大量CPU / RAM资源的服务器, 部分资源将分配给HyperFlex控制器VM,我什至在HyperFlex配置中在CPU和内存上重新加载了一点,以免与Cisco并肩作战,并保证了其余VM的资源。 但是我们可以拒绝使用FibreChannel交换机,并且我们不需要每个服务器的以太网端口,而是在FI内部交换本地流量。
结果是每个数据中心的以下配置:
对于Hyperflex,我没有承诺复制软件许可证,因为我们可以立即使用它。
对于古典建筑,我聘请了一家将自己确立为优质廉价制造商的供应商。 对于这两种选择,我都为特定的解决方案滑道使用了标准,在输出时,我得到了实际价格。
Cisco HyperFlex上的解决方案便宜13%。
方案2:创建两个活动的数据中心。 在这种情况下,我们在VMware上设计了扩展集群。
经典架构由虚拟化服务器,SAN(FC协议)和两个存储系统组成,两个存储系统可以在它们之间延伸的一个上进行读写。 在每个SHD上,我们都为锁设置了有用的容量。
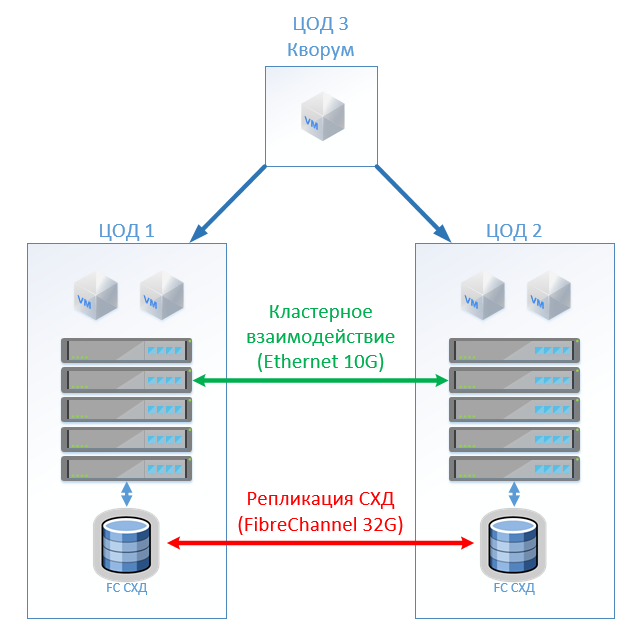
在HyperFlex,我们仅创建两个站点上具有相同数量节点的拉伸群集。 在这种情况下,将使用复制因子2 + 2。
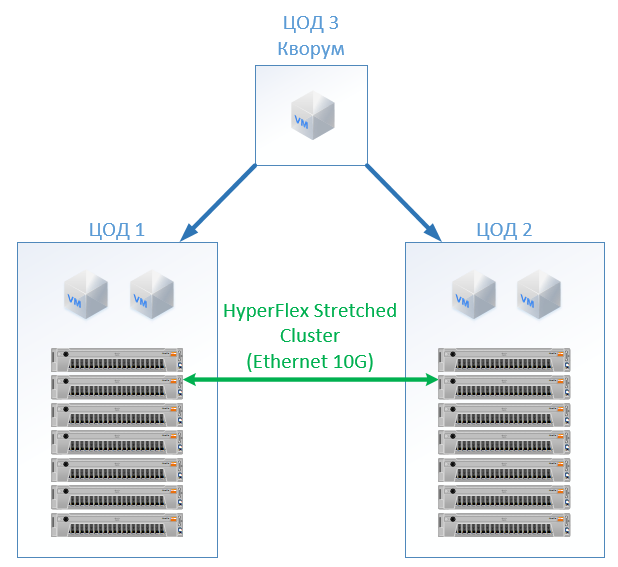
结果是以下配置:
在所有计算中,我没有考虑网络基础架构,数据中心成本等:对于传统体系结构和HyperFlex解决方案,它们将是相同的。
结果证明,HyperFlex的价格要贵5%。 在这里值得注意的是,对于CPU / RAM资源,我对Cisco抱有偏见,因为在配置中,它均匀地填充了内存控制器的通道。 , , , « », . , Cisco UCS .
SAN , - , (, , — ), ( ), .
, — Cisco. Cisco UCS, , HyperFlex , . , . : « , ?» « - , . !» — , : « » .
参考文献