
哈Ha! 我们将继续从#article_essense频道发布来自开放数据科学社区成员的科学文章的评论。 如果您想在其他所有人之前得到他们-加入社区 !
今天的文章:
- 神经常微分方程(多伦多大学,2018)
- 具有深度生成模型的半无监督学习:使用超稀疏标签进行聚类和分类(牛津大学,艾伦·图灵研究所,伦敦,2019年)
- 通过学习的潜在结构发现和缓解算法偏差(哈佛大学马萨诸塞理工学院,2019年)
- 从人类偏好中进行深度强化学习(OpenAI,DeepMind,2017)
- 探索随机有线神经网络进行图像识别(Facebook AI Research,2019)
- Photofeeler-D3:具有选民模型的神经网络,用于约会照片评级(Photofeeler Inc.,2019)
- MixMatch:半监督学习的整体方法(Google Reasearch,2019)
- 划分和征服度量学习的嵌入空间(海德堡大学,2019年)
1.神经常微分方程
作者:Ricky TQ Chen,Yulia Rubanova,Jesse Bettencourt,David Duvenaud(多伦多大学,2018年)
→原创文章
该评论的作者:乔治·伊格纳托夫(在懈怠中a2dy2n7okhtp)
NIPS最佳论文奖

本文的作者指出,类似于ResNet的网络与求解微分方程的Euler方法非常相似。 如果是这样,那么为什么不立即将这一思想发挥到最大呢?想象一下一个微分方程形式的神经网络,得到
- 具有任意数量层的网络,可以在训练和推理期间随时更改。 更多的图层->更精确,更平滑的转换(反之亦然)。
- 因此,参数数量少得多,从而降低了存储成本。
通过类比得出NODE:
- hn=fn(hn−1,W)+hn−1 -这是类似Resnet的网络中第n层的输出定义的样子-W-参数。
- hn=f(hn−1,t=n,W)+hn−1 -如果n是一个离散量,这看起来像一个类似于NODE的网络。
- hn simaf(tn)+hn−1 , f(t)=dh(t)/dt -欧拉法。
- dh(t)/dt=f(h(t),t,W) -大-! ODE支持的神经网络。
我们用任何黑盒ODEsolver求解它,使用伴随灵敏度方法(Pontryagin等,1962)抛出梯度。 由于其完全可区分性,NODE可以与常规神经网络结合使用。 作者将代码发布在pytorch上。
本文讨论了3个应用程序:
- 与类似ResNet的体系结构(在MNIST上)进行比较。 NODE的工作几乎没有差,但使用的参数却少了3倍。
- 通过NODE覆盖标准化流-连续标准化流(合成数据集)。 新模型将计算成本从O(n_hidden_units ^ 3)降低到线性。
- 使用不规则的观察(合成数据集)对临时事件进行建模。 生成了螺旋轨迹的数据集,从中随机采样了一些点,这些点上撒有:盐:高斯噪声,以求合理。 它测试了常规的RNN和NODE,第二次再次证明更好。
小字体:
- 小批量训练会导致某种计算开销,但是作者认为在实践中这几乎是看不见的。
- 出现两个新的超参数:网络深度和求解ODE时的容错能力。
- 为了使ODE解决方案保持唯一性,网络必须具有有限的权重并使用Lipshitz非线性,例如tanh或relu。
链接到有关habr的更详细的概述。
2.深度生成模型的半无监督学习:使用超稀疏标签进行聚类和分类
文章作者:Matthew Willetts,Stephen Roberts和Christopher Holmes
(牛津大学,艾伦·图灵学院,伦敦,2019)
→原创文章
评论作者:Alex Chiron(在sliron shiron8bit中)
作者考虑了分类问题的半无监督情况,当时由于选择偏见而存在于标记中的部分类别根本没有被标记,并且根据已知数据类别没有太多标记。 由于大多数模型通常都在半监督/监督模式(分类)或非监督模式(聚类)下工作,因此这会带来其他问题,在这种情况下,我们需要考虑这两种选择。 此外,使用半监督算法可能导致以下事实:未分配的数据将根据与错误类的接近程度进行分配。 此类数据的假设示例是一组肿瘤扫描。 我们收集了部分数据并标记了该部分上存在的所有类型的肿瘤,但事实证明,其余数据中还存在其他类型的肿瘤,并且标记中已知物种的变异性并未得到充分体现。
作者受到深层生成模型的启发(这种模型的单层隐藏变量深度最简单的示例是变分自动编码器,又名VAE):在以前的工作中,此类模型成功地解决了半监督案例(M2,ADGM)和聚类( VaDE,GM-VAE)。
为什么不同时解决两个问题(在很少标记的类上进行半监督学习,而在未放置的类上进行半监督学习),将学习到的潜在变量的空间保持在共同的位置,并结合上述模型的思想? 正是这种想法奠定了本文中提出的GM-DGM / AGM-DGM模型的基础。
在半监督情况下考虑M2模型。 之所以这样称呼是因为,在M1下,创建者暗示对VAE和一些分类器(svm)进行顺序训练,以得到z的潜在表示形式,但是M2已经通过从隐含变量层中添加变量y而从VAE获得,该变量y负责有时观察到的类。
p theta(x,y,z)=p theta(x|y,z)p(y)p(z) , q pi(z,y|x)=q pi(z|y,x)q pi(y|x)
在哪里 q phi(y|x)=猫( pi phi(x)) , q phi(z|x,y)=N(z| mu phi(x,y), Sigma phi(x,y))
其中q是编码器,p是解码器,一部分 q phi(y|x) -直接训练的分类器。
对于无监督/半无监督的情况,M2不起作用-发生后塌陷,分类部分q_phi(y | x)塌陷为先验分布p(y)。 GM-VAE的作者在他的文章中还展示了M2在实践中的不可操作性,并指出通常在实现M2时,h1解码器的第一层与高斯混合非常相似。
基于此观察,GM-VAE使用显式的隐藏变量层对高斯混合物进行聚类以进行聚类,本文的作者也对此进行了重复,因此,GM-DGM模型允许半无监督模式下的成功运行。 VAE在隐层中使用高斯混合函数,这取决于y类变量,具有上述两项功能,用于计算和最大化ELBO。
这篇文章的作者在一个半无监督的Fashion-MNIST版本上进行了一个实验:他们删除了前5个类别的标签,其余5个类别保留了5%的标签,而他们获得的总准确率分别为77.2%和M2的53%。 还显示了使用模型进行聚类的可能性(这并不奇怪,因为它几乎是GM-VAE)。
3.通过学习的潜在结构发现和缓解算法偏差
作者:亚历山大·阿米尼(Alexander Amini),阿娃·索莱曼尼(Ava Soleimany),威尔科·施瓦丁(Wilko Schwarting),桑吉塔·N·巴蒂亚(Sangeeta N.Bhatia),丹妮拉·罗斯(Daniela Rus)(哈佛大学马萨诸塞理工学院,2019年)
→原创文章
评论作者:Alex Chiron(在sliron shiron8bit中)
最近,越来越多的媒体在新闻中发现与数据偏见有关的新闻,尤其是与个人相关的算法-随着其适用性的增长,对那些不足(或过多)的人群和类别产生强烈负面影响的风险在数据集中显示。 最新的例子之一是一项研究,该发现显示出肤色较深的行人检测准确性较低(在标准BDD100K和MSCOCO数据集的对象检测范围内, 链接 )。
- 使用重采样进行类平衡(需要对隐藏的数据结构有先验的了解)。
- 生成无偏数据(例如,使用GAN 生成具有多种肤色的个人 )。
- 聚类和后续重采样。
- 您仍然可以等待,直到将IBM Diversity in Faces数据集带入学术界。
考虑到潜在变量z的分布,本文的作者对VAE和采样进行了修改,这可以减少训练阶段数据中偏差的影响。
因此,DB-VAE的主要思想是:
- 考虑一个分类问题,其中我们有一个训练数据集{(x,y)},x是m维特征,y是d维标签,我们的任务是近似映射X->Y。
- 以VAE为例,但是除了维度为2k的隐藏变量z的向量z之外,我们还将强制编码器(在这里我记为2,因为我们正在处理平均值和方差)也要学习维度d的向量,该向量负责上述标签。 在这种情况下,解码器仅接受向量z作为输入。 因此,我们得到了半监督学习的相似之处,其中学习了模型的一部分以重建输入,而另一部分则是解决特定问题(分类)。
- 由于合并损失,我们控制模型的训练,将VAE损失(重建+ KL散度)标准与辅助任务的损失(例如,二元分类问题的交叉熵)结合起来。
- 特别需要注意的是,您需要控制对不希望造成偏差的数据的训练(即,不要从解码器反向传播数据)。
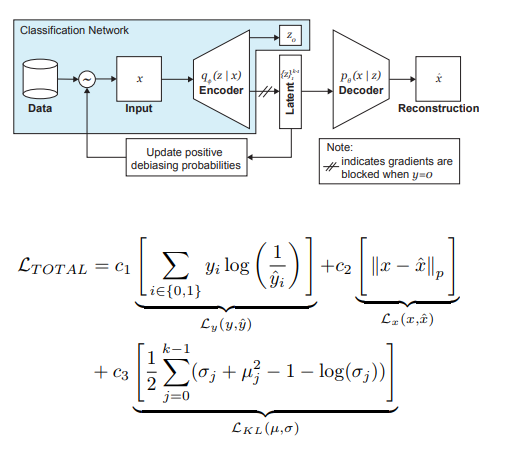
在训练阶段,自适应采样扮演着消除黑人痛苦的最重要角色。 我们想选择稀有样本(从一些隐藏的,未明确识别的因素的角度来看)样本,因此我们转向隐藏变量z空间每个维度的直方图,其积可以近似于整个空间Z上数据的分布Q(z | X)。形成新批次时,我们将考虑Q(z | X)分布W(z(x)| X)的“反”分布,它决定了在批次中选择示例的可能性(alpha是确定去偏程度的超参数),从而更新Q(z | x)。 X)在每个时代。 如您所见,去偏不是预先选择的,而是基于学习到的潜在变量。
作为实验,作者解决了二进制分类的问题(在照片中找到人脸)。 为了进行培训,我们收集了一个数据集,该数据集由CelebA的20万人和Imagenet的20万人组成,将图像调整为64x64。 如前所述,在训练期间,解码器对没有脸部照片的反向传播被阻止(y = 0)。 经过培训后,他们在飞行员议会基准(PPB)上得到了验证(来自南非,卢旺达,塞内加尔,瑞典,芬兰,冰岛的议会议员的1270张照片):对于所有alpha> 0,与相比,暗色男性,暗色女性,亮色女性类别的检测准确性有所提高选项无偏见。
4.根据人的喜好进行深度强化学习
作者:Paul Christiano,Jan Leike,Tom B.Brown,Miljan Martic,Shane Legg,Dario Amodei(OpenAI,DeepMind,2017)
→原创文章
评论作者:Dmitry Nikulin(处于dniku松弛状态)
本文是关于如何在深度强化学习(RL)的背景下实施旧思想的。 想法:让我们让一个人评估代理的行为,然后我们将基于此学习奖励功能。 问题在于,深层RL非常贪婪,而人的时间却很昂贵。 本文提供了一系列技巧,使您可以将工时减少到合理的水平。
奖励功能是一对功能(观察,动作)。 它是通过对一组神经网络的预测平均值进行设置的。 所使用的RL算法(在Atari的A2C和Mujoco的TRPO中)认为该平均值是真正的回报,并对其进行了训练。 因此,本文重点讨论训练此合奏的问题。
该合唱团接受了人类评估方面的培训。 每个等级的结构如下。 会向一个人显示两个1-2秒长的特工视频。 他可以通过4种方式评价这样的一对:左比较好/右比较好/太相似/无与伦比。 如果一个人说“无与伦比”,那么这样的评估就会被丢弃。 否则,将记住三元组(σ¹,σ²,μ),其中σⁱ是相应视频中代理的轨迹(即,对(obs,act)对的列表),μ是对(1、0),(0、1 )或(½,½)。 此外,可以相信,对轨迹的奖励的预测等于每对预测的总和(obs,act)。 最后,我们仅优化softmax_cross_entropy_with_logits。
可以相信,概率为10%的人会选择一个随机答案,在构建训练样本时要考虑到这一点。 本文的2.2.3节提供了更多技巧,并写出了所有公式。
选择要演示给人的剪辑对如下:对大量剪辑进行采样,在它们上考虑集合的离散度,并向人们显示具有高离散度的随机剪辑对。 作者说,我想根据信息的价值进行选择,但这是未来的工作。
作者在Atari和Mujoco上进行了测试,并使用了真实的人类评分(雇用的承包商)和综合评分(根据真实的奖励函数生成评分),同时将它们与常规RL进行了比较。 在近似相等数量的评级下,综合测试和真实测试的工作原理相似。 此外,令人惊讶的是,常规RL(具有真正的奖励功能)并不一定会更好。
最后,除了尝试训练代理人以通常的意义上获得很多奖励外,本文还提供了其他两个示例:Mujoco中的Hopper进行后空翻,Atari Enduro中的机器不会超越其他汽车,而是与它们平行行驶。 原来解决了这两个问题。
结论:该示例描述了重现本文的尝试。 尝试是成功的,但是在空闲时间花了8个月的时间,在纯时间上花费了220个小时,其中一半用于调试最简单的版本。
5.探索随机有线神经网络进行图像识别
作者:谢赛宁,亚历山大·基里洛夫,罗斯·吉尔希克,何凯明(Facebook AI Research,2019)
→原创文章
评论作者:Egor Panfilov(处于松弛状态的tutk1ja)
简介:
这项工作提出了生成神经网络体系结构的问题。 当前,已知许多体系结构技巧(LSTM,Inception,ResNet,DenseNet)可以提高许多任务的质量,但它们也将一定的强大体系结构引入模型中。 谷歌正在推动其神经体系结构搜索(NAS),而不是上述解决方案,在该体系结构中,通过RL-NASNet,AmoebaNet从预定义的模块中执行特定任务的体系结构搜索。
作者认为,由人和NAS决定设计的两种方法在架构之前都引入了过于严格的要求。 为了减少它,他们尝试使用神经网络的参数生成方法,其中元素的布线(连接)是随机进行的。 事实证明,自1940年代以来,诸如A. Turing,M。Minsky,F。Rosenblatt等科学家一直在探索随机布线方法。 还有一个论点,作者回忆说,在神经科学研究中,发现一种物种的有机体中神经元连接的结构是不同的(当然,达到一定的详细程度)。 总的来说,蠕虫和人类婴儿都是这样,程序神经网络的生成听起来很有趣并且很有前途,这就是研究的目的。
方法:
让我们尝试通过图方法将神经网络体系结构的过程生成过程模块化。 初始步骤如下:
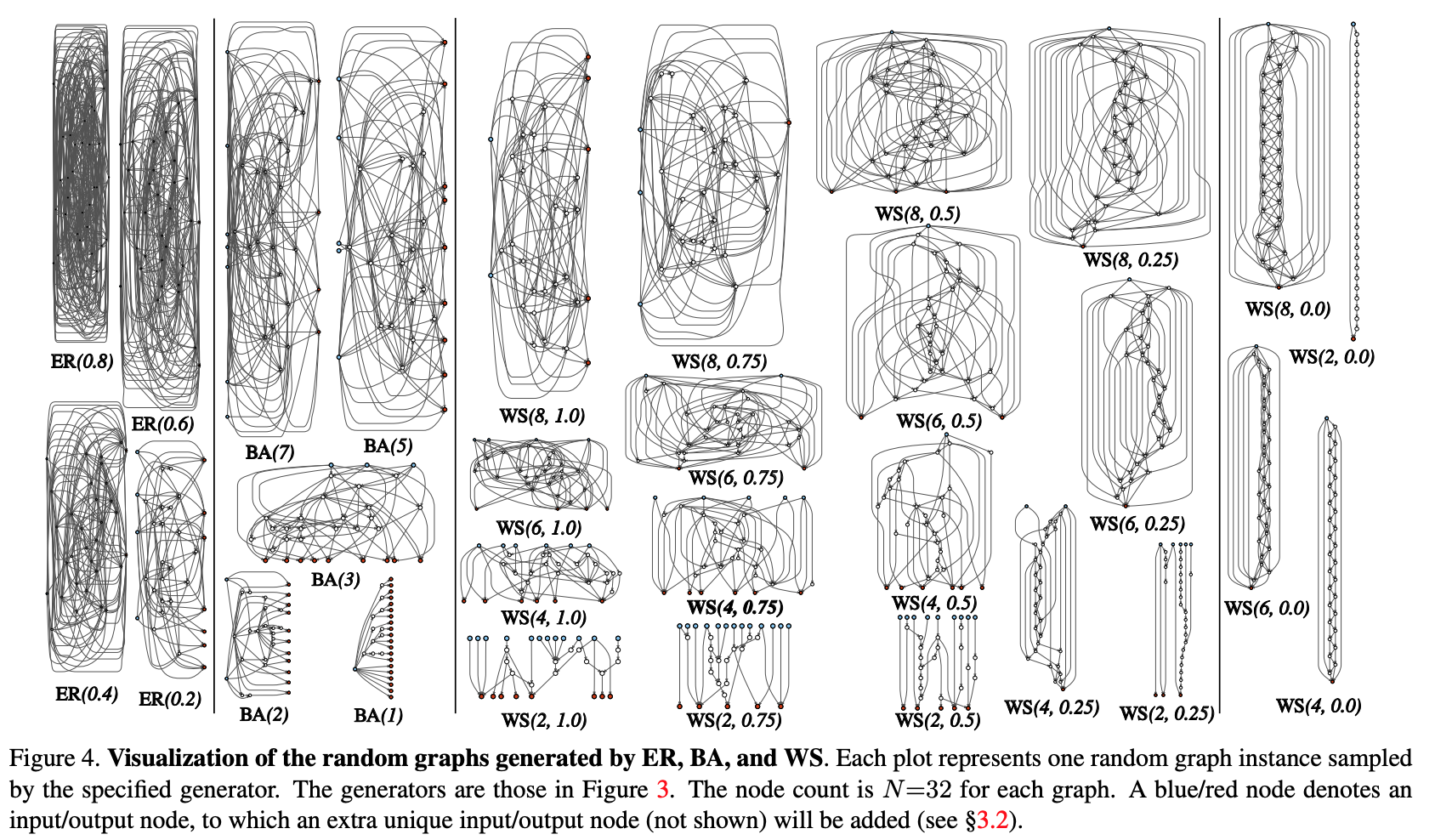
- 从参数化族生成随机图。 使用经典方法:Erdos-Renyi(ER),Barabasi-Albert(BA)和Watts-Strogatz(WS)。
- 该图将转换为神经网络:
- 假设图的所有边缘都是数据张量的有向载体;
- 对于图的每个顶点,确定其执行的操作类型:(I)通过与训练后的权重求和来进行聚合,(II)变换-ReLU +卷积+ BN,(III)分布-张量沿着每个输出边的传递;
- 根据上一个子节的结果,可以有多个输入和输出顶点,但是我想在图中有1个入口点和1个输出点。 此类节点是单独创建的。 输入一个简单地将张量的副本散布到图的所有输入顶点,输出则考虑所有输出顶点的未加权平均值。实际上,作为步骤1和步骤2的结果,并没有创建一个完整的网络,而仅创建了一个模块(例如conv_1,...)卷积编码器)。 为了完全获得神经网络:
- 创建并串联了几个模块。 为了减少网络参数的数量,请以2x2的步幅在模块的所有输入顶点进行转换。 转换到下一个模块的通道数增加了2倍。要针对特定任务进行实验:
- 在网络的输出处,添加了一个头进行分类。
结果:
该方法的测试是在ImageNet上对分类问题进行的。 生成的神经网络的质量实际上与SotA架构相当,但与最近的Google的DeepBrain AmoebaNet(具有相当数量的参数)相比有所损失。
我们检查了如果从结果图中删除随机顶点/边会发生什么情况。 公制-质量降低分别取决于相邻的输出边/输入顶点数。 通常,质量在下降,但不是很严格。
作者还检查了迁移学习是否适用于这种架构。 在COCO检测任务中,带有FPN的骨干Faster R-CNN被替换为生成的且经过预训练的网络。 结果表明,该模型的质量并不比ResNeXt-50 / -101差。 但是,即使是转学开始的事实也很有趣。
6. Photofeeler-D3:具有选民照片评级模型的神经网络
文章作者:Agastya Kalra和Ben Peterson(Photofeeler Inc.,2019)
→原创文章
评论作者:Alex Chiron(在sliron shiron8bit中)
作者建议使用Photofeeler-D3:一种用于评估约会网站在3个方向/特征上的照片的网络体系结构-一个人看起来有多聪明,可信赖且有吸引力(忽略光环效应!)。 这项任务是根据《卫报》进行的一项调查得出的,根据该调查,90%的人仅在评估潜在卫星的照片的基础上决定未来的日期
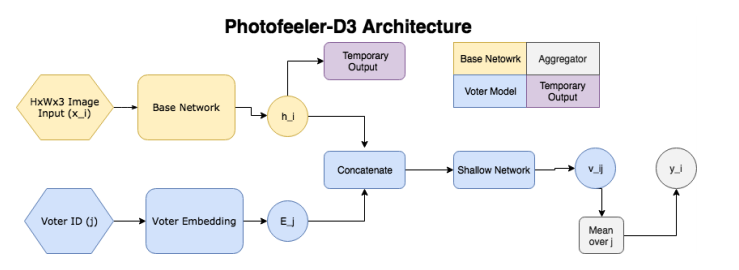
因此,网络由以下块组成:
- ( ) — (GAP ), 10 ( ) — temporary output.
- ( , voter model) - (voter), , temporary output , , 10 v_ij (( 10 [0;1]). v_ij [0.05, 0.15, 0.25...0.95].
- , 200 , .
, , , , . Facial Beauty Prediction (FBP) SCUT-FBP Hot-Or-Not, , Photofeeler, . : +100k , 1.2 , (200 ) 200 (50 ). , 600px. 10000 8000 . , 0 3, [0,1] ( , ).
:
- (backbone , , etc) (20000 train, 3000 val, 2311 test), xception 600x600.
- , (temporary output) KL- ( , , 10 [0,1]).
- voter model one-hot .
- voter' , 2 .
- trait' 2 , .:
- ~80% , London Faces , prettyscale.com hotness.ai (81 53 52).
- FBP (SCUT-FBP Hot-Or-Not) , SOTA.
- , , 10
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
: D. Berthelot, N. Carlini, IJ Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→
: ( JanRocketMan)
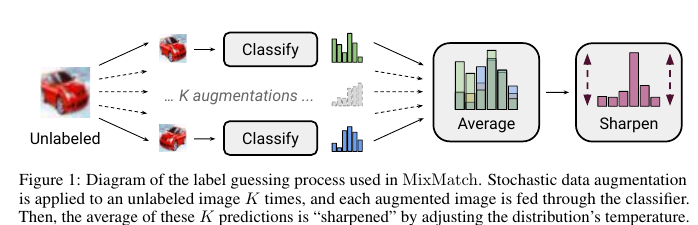
MeanTeacher Mixup- SOT- Semi-Supervised Learning (SSL) . , SSL consistency regularization. , ( ) "" , . Mean Teacher ( — c EMA ), — Mixup ( ). , . :
- unsupervised , .
"" p. - "" , one-hot. : pnew=p1/T/sum(p1/T,dim=1) 。 T , , , ( ), .
- , . , SVHN, STL CIFAR10.
CIFAR10 90% accuracy 250 . — VAT, 60%. SVHN - 96% 250- , VAT Mean Teacher 90.
STL10 90% 1 , - CCGAN, 80. , :
- , ( );
- GridSearch- ;
c. SSL SVHN .
8. Divide and Conquer the Embedding Space for Metric Learning
: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→
: ( Alexander Denisenko)
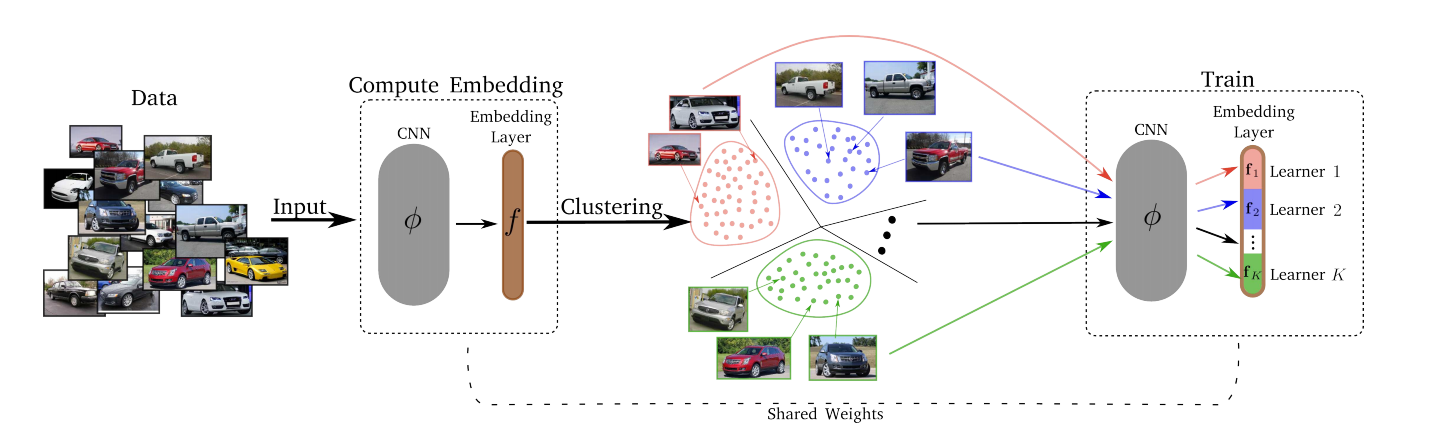
— , . , , – , , , ..
, :
- Divide.
- k-means. . . Embedding layer K . – . d/K (d – ). - Conquer.
Divide K K . , , , -, , . , T (Divide) . - Merjim-我们将所有Lerners(嵌入层的切片)连接起来。 然后,我们在整个数据集上训练嵌入层,以使Lerners成为朋友。
实验结果:每个人都赢得了几个数据集。
损失可以是任何东西-三重损失,保证金损失,代理NCA等。
最优的K Lerners数为8(整个嵌入空间的维数为128,因此每个Lerner都在16维空间中解决了他的子任务)。
T从1更改为10并没有明显影响,因此使用T = 2。