神经网络这个话题不是在第一年就激发开发人员,科学家和营销人员的心,而在最初的十年甚至没有。 但是我们都知道,在基于神经元的项目中,通常会出现一个简单的大日期和营销公告,并在点击诱饵标题的背景下夸大其词。 我们试图避免这样的故事,并基于对成分的分子相容性的研究,对30万种食谱的分析和纯粹的创造力的研究,开发了一个神经比萨项目。 在剪切下,您可以找到详细信息并在GitHub上找到开源链接。

汽车可以提出新的东西吗?还是受其所知限制? 到目前为止,还没有人知道这个问题的答案。 但是现在,人工智能完美地解决了分析大型非标准数据的问题。
到了Dodo Pizza之后,他们决定进行一项实验:系统化并在结构上描述在世界范围内被认为是混乱且主观的东西-味道。 人工智能帮助找到了最疯狂的成分组合,尽管它们具有非同寻常的性质,但对大多数人来说却很美味。
我和我的同事在这个不寻常的项目中担任MIPT和Skoltech的神经网络专家。 我们已经开发并训练了一种神经网络,可以解决生成厨房食谱的问题。 在工作过程中,分析了超过300,000种配方以及有关成分的分子相容性的科学研究结果。 在此基础上,人工智能学会了寻找成分之间的非显而易见的联系,并了解它们如何相互结合以及每种成分的存在如何影响所有其他成分的兼容性。
我们如何进入Dodo AI-pizza项目
通常发生的所有事情都是突然发生的。 在暑期练习之前,有一个短暂的超时时间,我们刚刚完成了深度学习课程,为项目辩护,并尝试适应更轻松的学习/生活节奏。 但是他们做不到:在BBDO的一个个人请求中偶然发现了一些帖子,这些帖子就是寻找可以编写神经网络来生成新食谱的人。 更具体地说:渡渡鸟的新比萨食谱。 我们毫不犹豫地决定要尝试。
当该项目刚刚开始时,我们还不完全了解它是否会进一步发展,是否会实际实施,我们只是对该任务感兴趣。 大量的redbowl和快速的互联网帮助并推动了我们前进。 回顾过去,我们知道有些事情可以做的不同,但这是正常的。
无论如何,几周后神经网络的工作模型准备就绪,就开始了其投入生产的阶段。 我们很幸运,从严格意义上来说,该项目不能称为工业或技术项目。 实验的状态更适合他。
使用我们的模型,生成了披萨食谱的各种变体,我们将其传递给非常酷的渡渡鸟厨师进行产品测试。 在认识到我们所做工作的价值方面,渡渡鸟研发实验室的披萨品尝时刻是一个分水岭。 看到产品售出非常令人兴奋。 确实,通常所有的开发和解决方案都是一时的,无形的事情,在这里不仅可以触摸到结果,而且可以品尝到结果。
数据集和辣椒的主要集合
任何模型都需要数据才能工作。 因此,为了训练我们的AI,我们从所有可用来源中收集了300,000份食谱。 对于我们来说,重要的是不仅要收集比萨饼食谱,而且还要尽可能使选择多样化,同时尽量不要超出合理范围(例如,忽略鸡尾酒食谱,意识到其语义不会对比萨饼食谱的语义产生很大影响)。
收集数据后,我们获得了100,000多种独特成分。 最大的问题是将它们合并为一种形式。 但是,这么多物品来自哪里呢? 一切都很简单,例如,食谱中的辣椒就是这样表示的:辣椒,辣椒,辣椒,辣椒。 对您来说,这很明显是相同的辣椒,但是神经网络将不同的拼写视为单独的实体。 我们解决了。 清理数据并将其显示为一个视图后,我们只剩下1,000个位置。
世界口味分析
收到准备就绪的数据集后,我们进行了初步分析。 首先,我们查看了世界上哪些美食在我们的数据集中以定量比例表示。
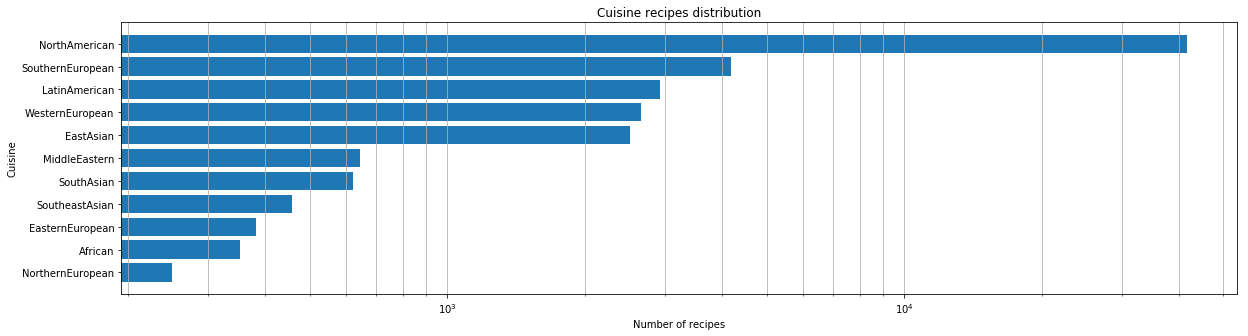
对于每种美食,我们都确定了最受欢迎的食材。
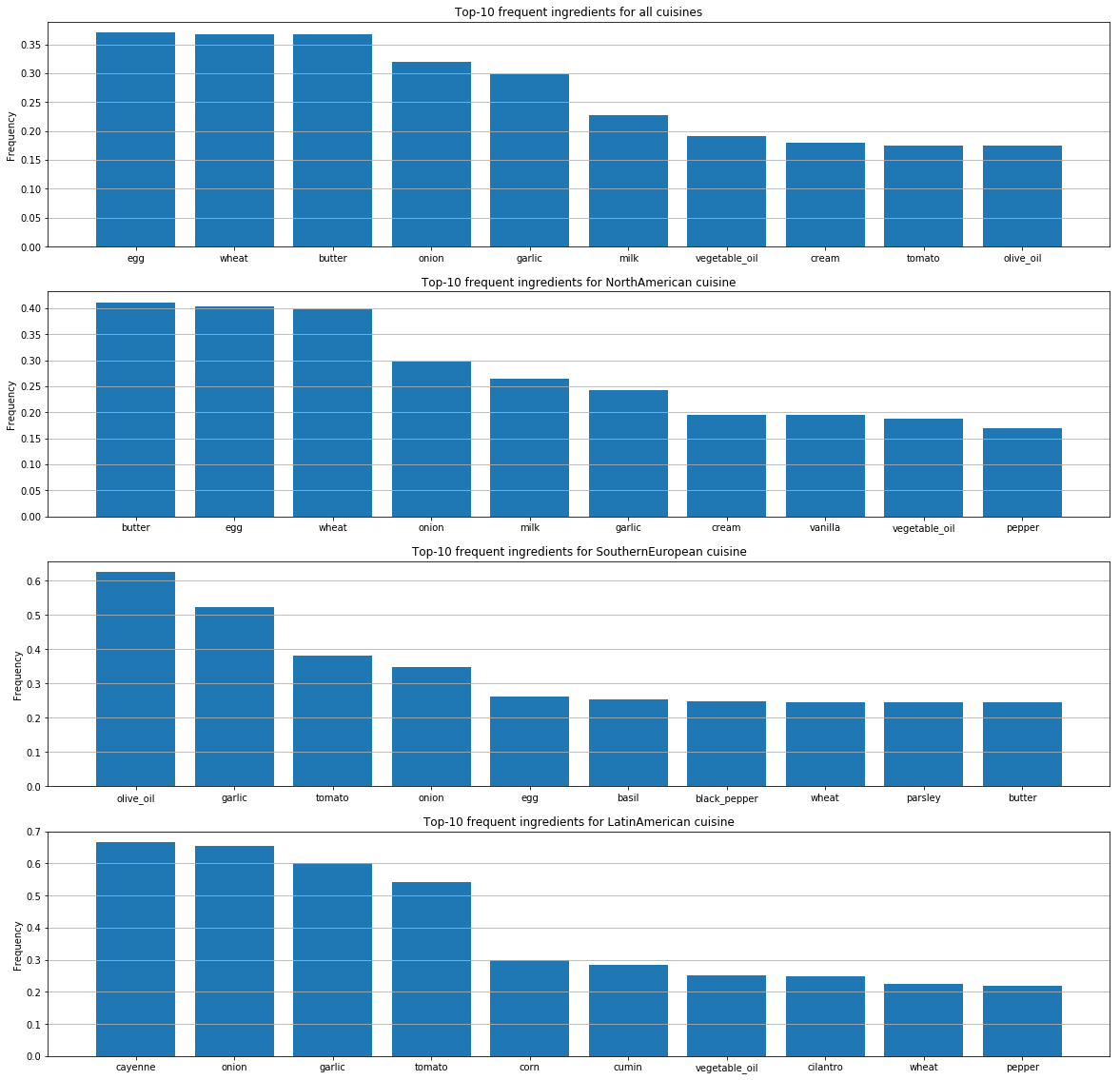
在这些图表上,每个国家/地区的人们的口味偏好差异明显。 从这些偏好也可以清楚地看出,来自不同国家的人们是如何将成分相互结合的。
两个披萨发现
经过这项全球分析之后,我们决定更详细地研究世界各地的比萨食谱,以找到其组成方式。 这是我们得出的结论:
- 披萨食谱比肉/鸡肉食谱和甜点小一个数量级。
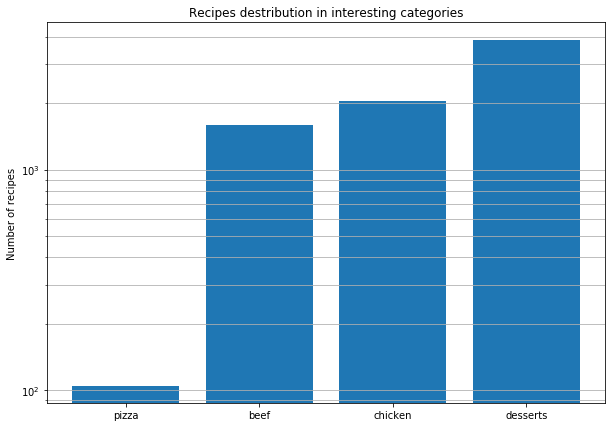
- 披萨食谱中发现的许多成分都很有限。 产品的可变性远低于其他菜肴。

我们如何测试模型
找到真正的风味组合与揭示分子的相容性不同。 所有奶酪的分子组成都相似,但这并不意味着成功的组合仅在于最接近的成分。
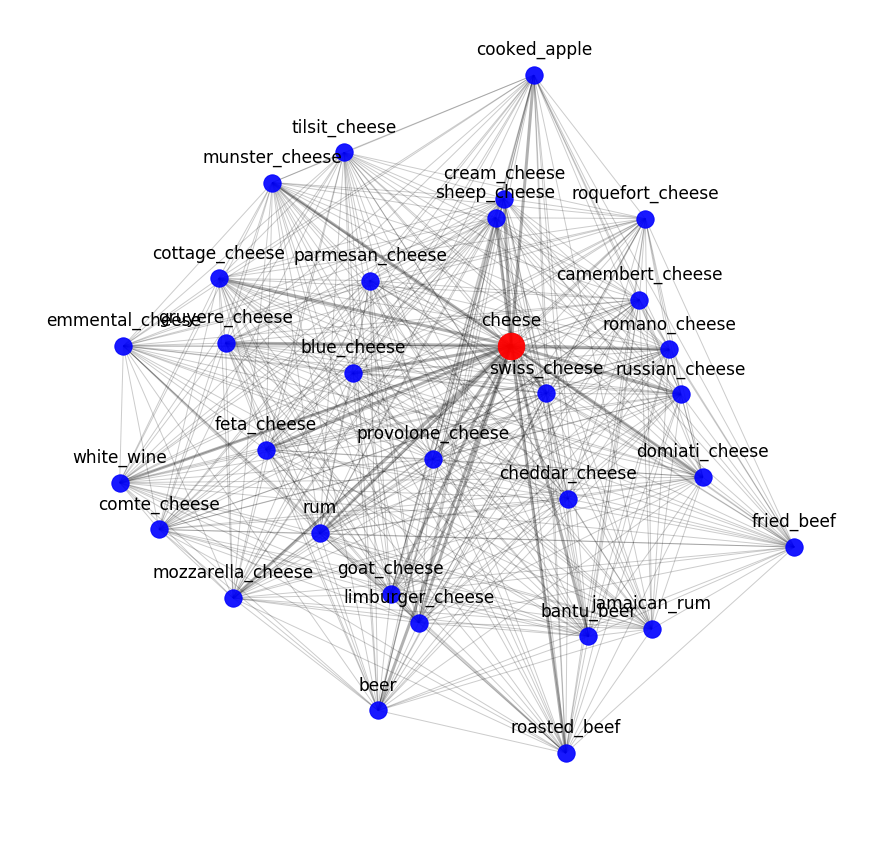
但是,当我们将所有内容转换为数学时,我们应该确切地看到类似于分子水平的成分的相容性。 因为相似的对象(相同的奶酪)应该保持相似,所以无论我们如何描述它们。 因此,我们可以确定正确地描述了这些对象。
将配方转换为数学
为了以可理解的形式展示神经网络的配方,我们使用了Skip-Gram负采样(SGNS)-word2vec算法,该算法基于上下文中单词的出现。 我们决定不使用预训练的word2vec模型,因为我们的食谱的语义结构明显不同于简单文本。 使用此类模型,我们可能会丢失重要信息。
您可以通过查看最接近的语义邻居来评估word2vec的结果。 例如,以下是我们的模型对奶酪的了解:
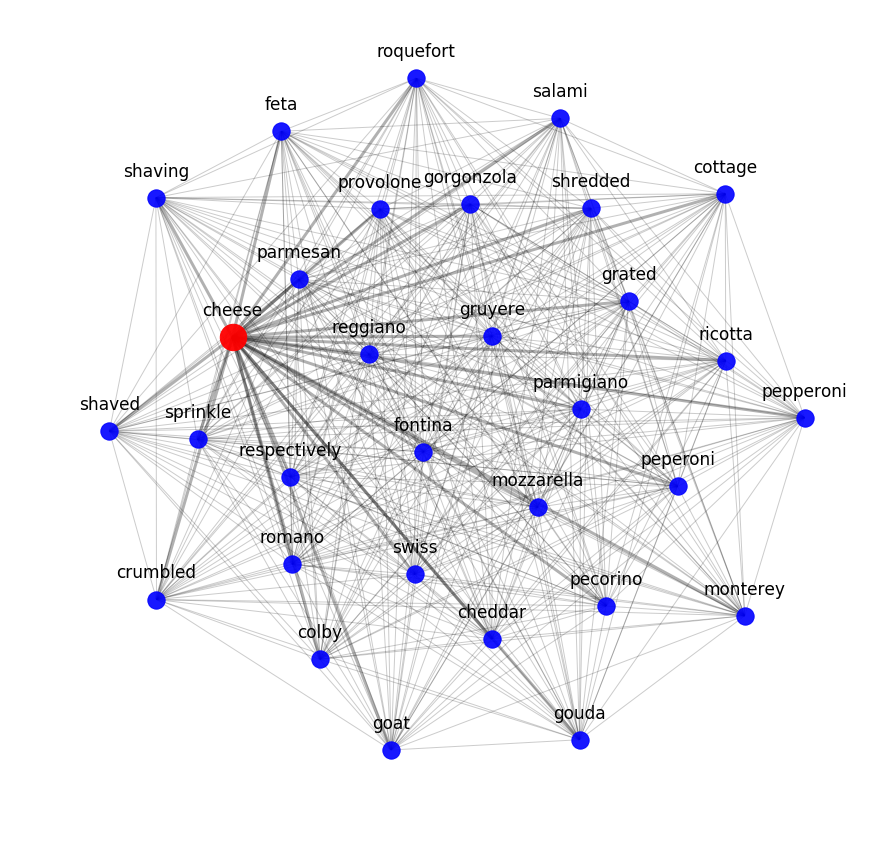
为了测试语义模型如何捕获配料的配方交互作用,我们对样本中的所有配方应用了主题建模模型。 也就是说,他们试图根据数学上确定的模式将配方数据集分为几类。

预先知道某个食谱样本属于从数据中获得的各种真实类别,我们构造了每个真实类别对所标识的生成类别的归属分布。

最明显的是甜点类,它形成了由主题模型生成的主题0和1。 除了甜点以外,这些学科几乎没有其他类别,这表明甜点很容易与其他类别的菜肴分开。 同样,在每个主题中都有一个最能描述它的课程。 这意味着我们的模型很好地满足了“口味”这一非显而易见含义的数学描述。
配方生成
为了创建新配方,我们使用了两个循环神经网络。 为此,我们建议在食谱的公共空间中有一个负责比萨饼食谱的子空间。 为了使神经网络学会提出新的披萨食谱,我们必须找到这个子空间。
当我们将图像表示为小尺寸的矢量时,此任务的含义类似于自动编码图像。 在这种情况下,向量可能包含有关图像的大量特定信息。
例如,对于照片中的人脸识别,此类矢量可以将有关人发颜色的信息存储在单独的单元格中。 正是由于隐藏子空间的独特属性,我们选择了这种方法。
为了识别披萨子空间,我们通过两个循环神经网络运行了配方。 第一个在入口处收到比萨饼食谱,并以隐藏矢量的形式寻找它的表示形式。 第二个从第一个神经网络接收到一个隐藏的向量,必须提供基于它的食谱。 第一个神经网络的输入和第二个神经网络的输出的配方应该重合。
因此,学会了以编码器解码格式的两个神经网络,可以正确地将配方中继到隐藏(潜在)矢量上,反之亦然。 基于此,我们能够发现一个隐藏的子空间,该子空间负责所有许多披萨食谱。
分子相容性
解决创建比萨饼食谱的问题时,我们必须在模型中添加分子相容性标准。 为此,我们使用了来自剑桥和美国几所大学
的科学家的
联合研究结果。
研究的结果发现,总分子对数量最多的成分是最佳组合。 因此,在创建配方时,神经网络会首选具有相似分子结构的成分。
结果和AI Pizza
结果,我们的神经网络学会了成功创建披萨食谱。 通过调整系数,AI可以生成经典食谱(例如玛格丽塔或意大利辣香肠)和疯狂食谱。 一个如此疯狂的食谱构成了世界上第一个分子完美的比萨饼的基础,该比萨饼具有十种成分:番茄酱,甜瓜,梨,鸡肉,樱桃番茄,金枪鱼,薄荷,西兰花,马苏里拉奶酪,格兰诺拉麦片。 限量版甚至可以在其中一个Dodo比萨店购买。 这里有一些更有趣的食谱,您可以尝试在家里做饭:
- 菠菜,奶酪,番茄,黑橄榄,橄榄,大蒜,胡椒,罗勒,柑橘,瓜,豆芽,酪乳,柠檬,鲈鱼,坚果,大头菜;
- 洋葱,番茄,橄榄,黑胡椒,面包,面团;
- 鸡肉,洋葱,黑橄榄,奶酪,酱汁,番茄,橄榄油,奶酪
- 番茄,黄油,奶油芝士,胡椒,橄榄油,奶酪,黑胡椒,芝士;
如果我们不提供最有趣的链接,那么所有这些都是垃圾: