这个简短的故事将致力于如何避免在估计即将到来的冲刺任务的过程中陷入虚构的控制陷阱。 我必须马上说,下面提供的数据仅是示意性的,为估算此处未使用斐波那契数的评论将是多余的。
我们的团队由一名分析师,测试人员,设计师和2名开发人员组成,但是为了更加清晰起见,我们只保留开发人员。
我们开始新的冲刺,并顺利进行用户故事的评估。 没什么新的。 继续...

计划已完成,结果可以在上方看到。 他们选择了3个用户故事,分别价值16、20和37个故事点。 总计-73。
此外,就像任何崇尚Scrum的乐趣的自尊开发团队一样,我们将这些评级添加到Jira。 同时,我们仅介绍每个故事的一般(或平均-甚至更差!)估计。
工作了两个星期,而不必从键盘上移开手,也不必从多年来一直深受欢迎的办公椅上站起来,所以您可以考虑新创建的功能。
但是怎么了? 冲刺结束了,我们看到前部按计划进行了所有操作,没有时间进行一次击键,而后部超出了冲刺并且完成了比计划更多的任务。
然后刚读完内容的Trenches PM的Scrum和XP出现,并说:“一切都清楚了!!! 有必要将更多的storpoints带到下一个冲刺,然后一切都会好起来,没有任何支持会再离我远去,与我一起探索范围!”
我们正在计划新的冲刺....
太好了! 多花了10个积分! 现在我们已经确定了一切!
又过了两个星期,该花点时间了。
但令所有人感到遗憾的是,冲刺的结束方式与我们希望的完全不同。
由于某种原因,后排再次拉回前方,而前排没有时间去做他们计划的事情(前排只是一个缺乏经验的六月的可能性,我们将降低后排不动的传感器,并想象整个事情只是在错误的计划中进行)。
另一个冲刺是失败的! 但是,为什么,我们花了更多的故事,并且仅仅是出于良好的目的-为服务器端提供必要的工作量?!?
这怎么可能?? 答案全与评估系统本身有关。 回到我们的冲刺。

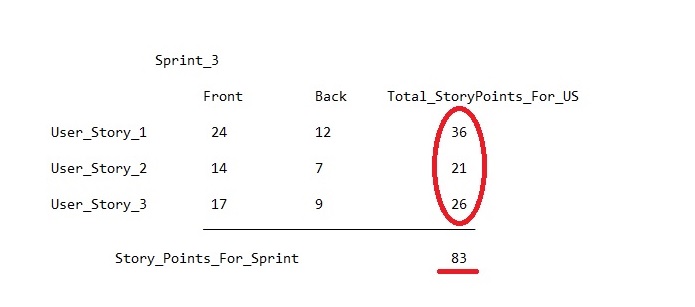
我们看到了什么? 事实证明,在新的sprint上花更多的storpoints来加载后部,我们只是加载了前部。
了解了这一点之后,PM疯狂的头脑中的第一个想法就是找出正面已经占据了多少故事点以及有多少支持。 但是根本无法查看Jira的整体等级,因为您只能找到每个故事的整体(平均或平均)等级,并且记住不再给谁评分。

然后解决方案就来了。 为了成功地调节团队的工作量,不仅需要在历史记录中保留一般记录,而且还要在前后负载情况下保留单独的记录。 这将使您找出每个区域的最佳工作量,并依靠它来填补sprint的待办事项。 到目前为止,如果没有MS Excel中的单独注释,则无法在Jira中实现此方法,但这并不意味着不应使用它。
我确信Atlassian开发人员将解决此问题,但就目前而言,不要重复我们的错误!
PS这些结论仅适用于客户端服务器应用程序的开发,在前端和后端工作之间存在明显的分离。 对于立即从两个方向评估工作的全栈开发人员团队来说,这样的问题就不会出现。