目前,Java是世界上最受欢迎的编程语言之一已经不是什么秘密了。 Java的正式发布日期是1995年5月23日。
本文致力于基础知识的基础知识:它概述了该语言的基础特性,这些语言特性对于初学者“ javists”将派上用场,而经验丰富的Java开发人员将能够刷新他们的知识。
*本文是根据IntexSoft Java开发人员Eugene Freiman的报告编写的。
本文包含外部材料的链接 。
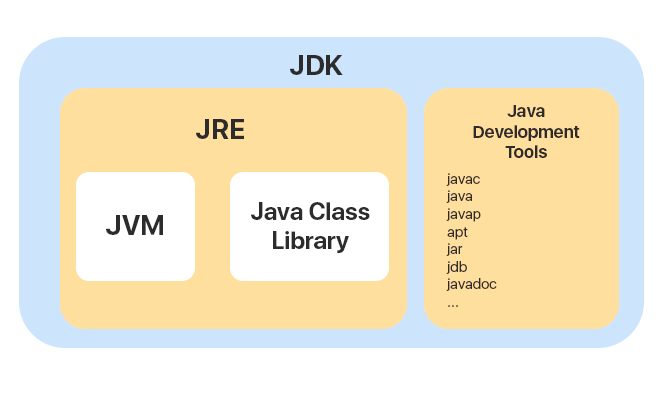
1. JDK,JRE,JVM
Java开发工具包是
Java应用程序开发工具包。 它包括
Java开发工具和Java运行时环境(
JRE )。
Java开发工具包括大约40种不同的工具:javac(编译器),java(应用程序启动器),javap(java类文件反汇编器),jdb(java调试器)等。
JRE运行时是运行已编译Java程序所需的所有程序的软件包。 包括
JVM虚拟机和
Java类库 。
JVM是旨在执行字节码的程序。 JVM的第一个优点是
“编写一次,随处运行”的原则。 这意味着用Java编写的应用程序在所有平台上都可以相同地工作。 这是JVM和Java本身的一大优势。
在Java之前,许多计算机程序是为特定的计算机系统编写的,并且优先选择手动内存管理,因为这样效率更高且可预测。 自1990年代下半年以来,在Java出现之后,自动内存管理已成为一种普遍的做法。
有许多JVM实现,包括商业和开源。 创建新JVM的目标之一是提高特定平台的性能。 每个JVM都是针对该平台分别编写的,但可以编写它,以便在特定平台上更快地工作。 最常见的JVM实现是
OpenJDK JVM热点。 也有
IBM J9 ,
Excelsior JET的实现 。
2. JVM代码执行
根据
Java SE规范 ,为了使代码在JVM中运行,您需要完成3个步骤:
- 加载字节码并实例化Class类
粗略地说,为了进入JVM,必须加载该类。 为此,有单独的加载程序类,我们稍后再返回。 - 链接或链接
加载类后,链接过程开始,在该链接过程中解析并检查字节码。 链接过程依次分为3个步骤:
-校验或字节码校验:指令的正确性,代码这一部分的堆栈溢出的可能性,变量类型的兼容性被检查; 每个班级检查一次;
-准备或准备:在此阶段,根据规范,为静态字段分配内存并进行初始化;
-分辨率或分辨率:符号链接的权限(在字节码中,打开扩展名为.class的文件时,我们看到的是数字值而不是符号链接)。 - 初始化生成的Class对象
在最后阶段,我们创建的类被初始化,并且JVM可以开始执行它。
3.类加载器及其层次结构
回到类加载器,这些是JVM一部分的特殊类。 它们将类加载到内存中,并使它们可用于执行。 加载程序适用于所有类:我们的类以及Java直接需要的类。
想象一下情况:我们编写了应用程序,除了标准类之外,还有我们的类,并且有很多类。 JVM将如何与此一起工作? Java实现了延迟的类加载,即延迟加载。 这意味着只有在应用程序中没有对类的调用之前,才可以加载类。
类加载器层次结构
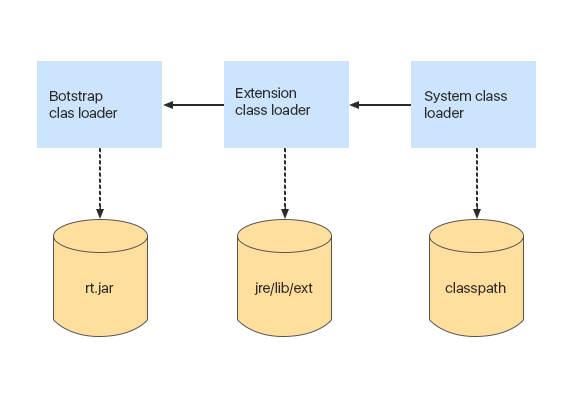
第一类加载器是
Bootstrap类加载器 。 它是用C ++编写的。 这是从
rt.jar存档中加载所有系统类的基础加载器。 同时,从
rt.jar加载类和我们的类之间存在细微差别:当JVM从
rt.jar加载类时,它不会执行加载任何其他类文件时执行的所有验证步骤,因为 JVM最初知道所有这些类均已验证。 因此,您不应在此存档中包含任何文件。
下一个引导加载程序是
Extension类加载程序。 它从
jre / lib / ext文件夹加载扩展类。 假设您希望每次Java计算机启动时都加载一个类。 为此,您可以将源类文件复制到此文件夹,它将自动加载。
另一个引导程序是
System classloader 。 它从应用程序启动时指定的类路径中加载类。
加载类的过程发生在层次结构中:
- 首先,我们请求在系统类加载器缓存中进行搜索(系统加载器缓存包含它已经加载的类);
- 如果在系统加载器的高速缓存中找不到该类,我们将查看高速缓存扩展类加载器;
- 如果在扩展加载程序缓存中找不到该类,则从Bootstrap加载程序请求该类。
如果在Bootstrap缓存中找不到该类,它将尝试加载该类。 如果Bootstrap无法加载该类,则它将类的加载委托给扩展加载器。 如果此时加载了类,则它将保留在扩展类加载器的缓存中,并且类加载完成。
4.类文件结构和启动过程
我们直接进入类文件的结构。
用Java编写的一个类被编译为扩展名为.class的单个文件。 如果我们的Java文件中有多个类,则可以将一个Java文件编译成扩展名为.class-这些类的字节码文件的多个文件。
所有数字,字符串,指向类,字段和方法的指针都存储在
常量池中 -
元空间存储区。 类描述存储在同一位置,并包含名称,修饰符,超类,超级接口,字段,方法和属性。 属性又可以包含任何其他信息。
因此,在加载类时:
- 读取类文件,即格式验证
- 在常量池(元空间)中创建类表示形式
- 加载了超类和超级接口; 如果它们没有被加载,那么类本身将不会被加载
5.在JVM上执行字节码
首先,为了执行字节码,JVM可以对其进行
解释 。 解释是一个相当缓慢的过程。 在解释过程中,解释器逐行“遍历”类文件,并将其转换为JVM可以理解的命令。
而且,JVM可以
广播它 ,即 编译为将直接在CPU上执行的机器代码。
频繁执行的命令将不会被解释,但会立即广播。
6.编译
编译器是一种程序,可以将用高级编程语言编写的程序的源部分转换为计算机“可以理解”的机器语言程序。
编译器分为:
- 没有优化
- 简单优化 (Hotspot Client):工作迅速,但生成非最佳代码
- 复杂优化 (热点服务器):在生成字节码之前执行复杂的优化转换
编译器还可以按编译时间分类:
- 动态编译器
它们与程序同时工作,这会影响性能。 这些编译器必须在经常执行的代码上运行,这一点很重要。 在程序执行期间,JVM知道最常执行哪个代码,并且为了不经常解释它,虚拟机立即将其转换为将直接在处理器上执行的命令。 - 静态编译器
编译时间更长,但会生成最佳代码以供执行。 优点:在程序执行期间它们不需要资源,每种方法都使用优化进行编译。
7. Java的内存组织
堆栈是Java中根据LIFO方案(“后进
先出 ”或“后进
先出 ”)工作的内存区域。
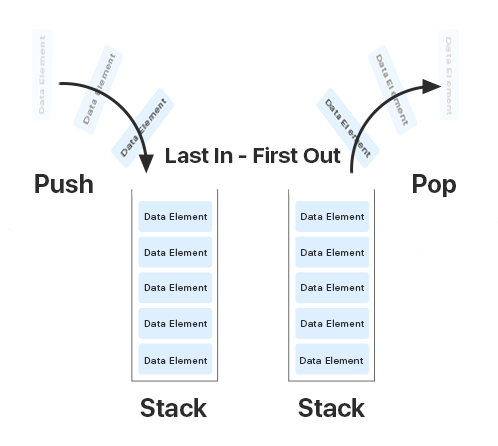
为了存储方法,它是必需的。 只要执行创建变量的方法,堆栈中的变量就存在。
在Java中调用任何方法时,都会在堆栈上创建一个框架或内存区域,并将该方法放在其顶部。 当方法完成执行时,将从内存中删除该方法,从而为以下方法释放内存。 如果堆栈内存已满,则Java将抛出
java.lang.StackOverFlowError异常。 例如,如果我们有一个将调用自身的递归函数并且堆栈上没有足够的内存,则会发生这种情况。
堆栈的主要功能:
- 随着新方法的调用和完成,将填充并释放堆栈。
- 对该内存区域的访问比堆快。
- 堆栈大小由操作系统确定。
- 它是线程安全的,因为每个堆栈都有自己的单独堆栈。
Java中的另一个内存区域是
堆或
堆 。 它用于存储对象和类。 新对象总是在堆上创建,对它们的引用存储在堆栈中。 堆上的所有对象都具有全局访问权限,也就是说,可以从应用程序中的任何位置访问它们。
堆分为几个较小的部分,称为几代:
- 年轻一代 -最近创建的对象所在的区域
- 旧的(永久的)世代 -存储“长寿命”对象的区域
- 在Java 8之前,存在另一个领域- 永久生成 -包含有关类,方法和静态变量的元信息。 Java 8出现后,决定将这些信息分别存储在堆外部,即在Meta空间中
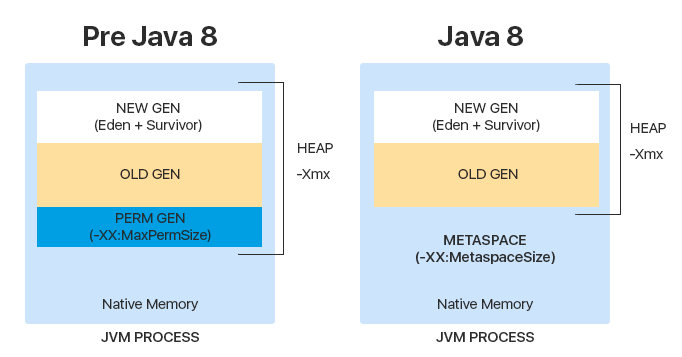
为什么抛弃永久一代? 首先,这是由于与该区域溢出相关的错误所致:由于Perm的大小恒定且无法动态扩展,因此内存迟早会耗尽,引发错误,并且应用程序崩溃。
元空间具有动态大小,并且在运行时可以扩展为JVM内存大小。
关键堆功能:
- 当此内存区域已满时,Java会引发java.lang.OutOfMemoryError
- 堆访问比栈访问慢
- 垃圾收集器收集未使用的对象
- 与堆栈不同,堆不是线程安全的,因为任何线程都可以访问它
根据上面的信息,考虑使用一个简单的示例执行内存管理的方法:
public class App { public static void main(String[] args) { int id = 23; String pName = "Jon"; Person p = null; p = new Person(id, pName); } } class Person { int pid; String name; // constructors, getters/setters }
我们有一个App类,其中唯一的
主要方法包括:
-值为
23的 int类型的原始
id变量
-具有值
Jon的 String类型的
pName引用变量
-类型
人员的参考变量
p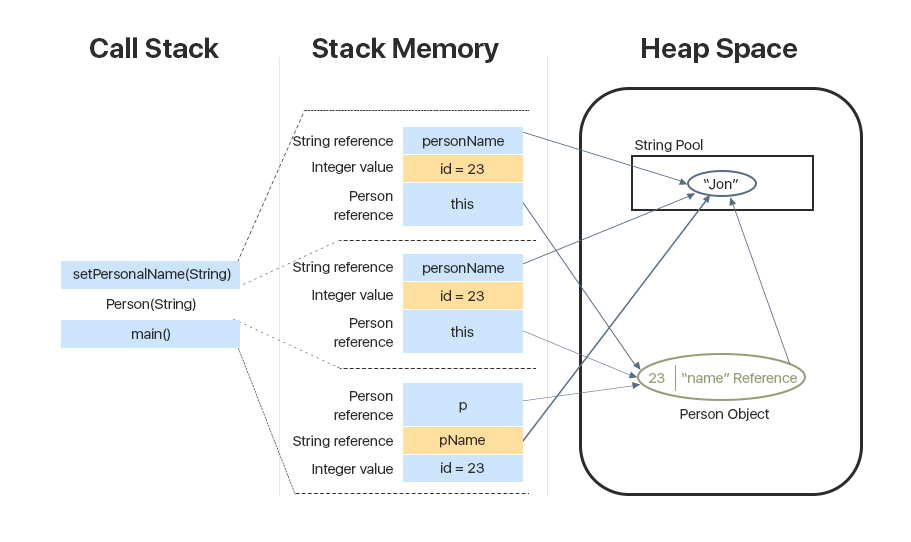
如已经提到的,当调用一个方法时,将在堆栈的顶部创建一个存储区,在其中存储要存储该方法所需的数据。
在我们的例子中,这是对
person类的引用:对象本身存储在堆中,链接存储在堆栈中。 字符串的链接也被压入堆栈,字符串本身存储在字符串池的堆中。 原语直接存储在堆栈中。
要从堆栈上的
main()方法使用
Person(String)参数调用构造函数,在上一个
main()调用的顶部,将在堆栈上创建一个单独的框架,其中存储以下内容:
-
此 -链接到当前对象
-原始
ID值
-参考变量
personName ,它指向字符串池中的字符串。
调用构造函数后,将调用
setPersonName() ,此后再次在堆栈上创建一个新框架,该框架中存储了相同的数据:对象引用,行引用,变量值。
因此,当执行
setter方法时,框架消失,堆栈被清除。 接下来,执行构造函数,清除为该构造函数创建的框架,然后
main()方法完成其工作,并将其从堆栈中删除。
如果调用其他方法,则还将在这些特定方法的上下文中为它们创建新框架。
8.垃圾收集器
垃圾收集器正在堆上工作-这是一个在Java虚拟机上运行的程序,它摆脱了无法访问的对象。
不同的JVM可能具有不同的垃圾收集算法;也有不同的垃圾收集器。
我们将讨论最简单的收集器
Serial GC 。 我们要求使用
System.gc()进行垃圾收集。
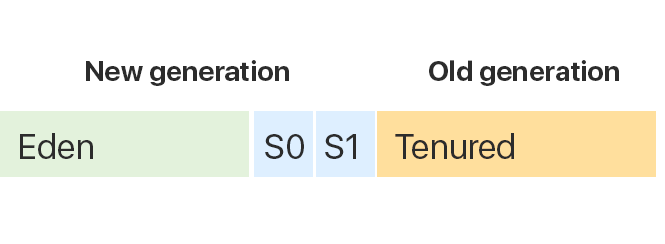
如上所述,堆分为两个区域:新一代和旧一代。
新一代(较年轻的一代)包括3个区域:
伊甸园 ,
幸存者0和
幸存者1 。
老一辈包括
终身制地区。
当我们用Java创建对象时会发生什么?
首先,物体落入
伊甸园 。 如果我们已经创建了许多对象,并且
Eden中没有更多空间,则垃圾收集器将触发并释放内存。 这就是所谓的
小型垃圾收集 -在第一遍中,它将清理
Eden区域并将“幸存”对象放入
Survivor 0区域。 因此,
伊甸园地区被完全释放。
如果碰巧再次填充了
Eden区域,则垃圾收集器将开始使用
Eden区域和
Survivor 0 (当前已被占用)工作。 清洗后,幸存的物体将掉入另一个区域-
幸存者1 ,另外两个将保持干净。 在随后的垃圾收集之后,
幸存者0将再次被选择为目标区域。 这就是为什么
幸存者区域之一始终为空很重要的原因。
JVM监视不断被复制并从一个区域移动到另一个区域的对象。 并且为了优化此机制,在一定阈值之后,垃圾收集器将此类对象移动到
Tenured地区。
当
Tenured中没有足够的空间容纳新对象时,将存在一个完整的垃圾收集
-Mark-Sweep-Compact 。

在该机制期间,确定不再使用哪些对象,清除这些对象的区域,并对使用
期限的存储
区进行碎片整理,即 依次填充必要的对象。
结论
在本文中,我们研究了Java语言的基本工具:JVM,JRE,JDK,JVM代码执行,编译,内存组织的原理和阶段,以及垃圾收集器的原理。