哈Ha!
作为探索C#8主题的一部分,我们建议讨论以下有关实现接口的新规则的文章。
 仔细查看C#8中的
仔细查看C#8中的接口结构,您需要考虑的是,在实现接口时,默认情况下可以打破常规。
与默认实现有关的假设可能导致代码损坏,运行时异常和性能下降。C#8接口的一种积极宣传的功能是,您可以在不破坏现有实现者的情况下将成员添加到接口。 但是,这种情况下的注意力不集中充满了大问题。 考虑其中做出错误假设的代码-这样可以更清楚地避免此类问题的重要性。
本文的所有代码都发布在GitHub: jeremybytes / interfaces-in-csharp-8中 ,特别是在DangerousAssumptions项目中 。
注意:本文讨论了目前仅在.NET Core 3.0中实现的C#8的功能。 在我使用的示例中,Visual Studio 16.3.0和.NET Core 3.0.100 。
关于实施细节的假设我阐明此问题的主要原因如下:我在Internet上找到了一篇文章,其中的作者提供的代码对实现的假设非常差(我不会指出该文章,因为我不希望作者被评论汇总;我会亲自与他联系) 。
本文讨论了默认实现的良好程度,因为即使在代码已经具有实现者之后,它也允许我们补充接口。 但是,此代码中有许多错误的假设(该代码在我的GitHub项目中的文件夹的
BadInterface中)
这是原始界面:
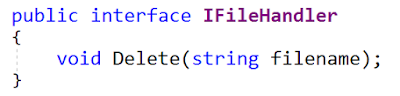
本文的其余部分演示了MyFile接口的实现(对我来说,在
MyFile.cs文件中):
然后,本文介绍了如何使用默认实现添加
Rename方法,并且不会破坏现有的
MyFile类。
这是更新的接口(来自
IFileHandler.cs文件):

MyFile仍然有效,因此一切都很好。 那呢 不完全是
错误的假设重命名方法的主要问题是与之相关的巨大假设:实现使用位于文件系统中的物理文件。
考虑一下我创建的用于RAM中文件系统的实现。 (注意:这是我的代码。它并非来自我所批评的文章。您可以在
MemoryStringFileHandler.cs文件中找到完整的实现。)

此类实现了一个正式的文件系统,该系统使用位于RAM中的词典,该词典包含文本文件。 这里没有影响物理文件系统的任何内容;通常没有对
System.IO引用。
实施者错误更新接口后,此类已损坏。
如果客户端代码调用Rename方法,它将生成运行时错误(或更糟糕的是,重命名存储在文件系统中的文件)。
即使我们的实现可以处理物理文件,它也可以访问位于云存储中的文件,并且此类文件无法通过System.IO.File访问。
当涉及单元测试时,还存在一个潜在的问题。 如果模拟或伪造的对象未更新,而测试的代码已更新,则在执行单元测试时它将尝试访问文件系统。
由于错误的假设涉及该接口,因此该接口的实现者已损坏。
不合理的恐惧?认为这种担心是没有根据的是毫无价值的。 当我谈论代码中的滥用行为时,他们回答我:“嗯,只是一个人不知道如何编程。” 我不能不同意这一点。
通常,我这样做:我等待着看如何工作。 例如,我担心“静态使用”的可能性会被滥用。 到目前为止,这还没有被说服。
必须牢记,这些想法浮出水面,因此我们有能力帮助他人走更方便的道路,跟随它不会那么痛苦。
性能问题我开始考虑,如果我们对接口实现者做出错误的假设,还会有什么其他问题等待着我们。
在前面的示例中,调用的代码位于接口本身之外(在这种情况下,位于System.IO外部)。 您可能会同意,此类行为是危险的钟声。 但是,如果我们使用接口中已经存在的东西,那么一切都应该没事吧?
并非总是如此。
作为一个明确的示例,我创建了IReader接口。
源接口及其实现这是原始的IReader接口(来自
IReader.cs文件-尽管现在该文件中已经有更新):

这是一个通用方法接口,使您可以获取只读项目的集合。
此接口的实现之一生成斐波那契数列(是的,我对生成斐波那契数列有不健康的兴趣)。 这是
FibonacciReader界面(来自
FibonacciReader.cs文件-它还在我的github上进行了更新):
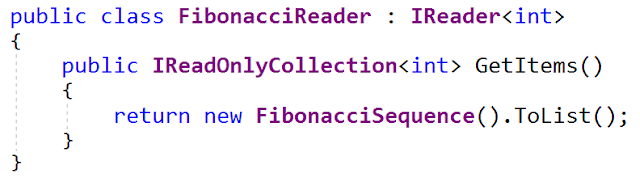
FibonacciSequence类是
IEnumerable <int> (来自FibonacciSequence.cs文件)。 它使用32位整数作为数据类型,因此溢出会很快发生。

如果您对此实现感兴趣,请查看我
在C#文章中
对斐波那契序列的TDD入门 。
DangerousAssumptions项目是一个控制台应用程序,它显示FibonacciReader的结果(来自
Program.cs文件):

这是结论:
 界面更新
界面更新现在我们有了工作代码。 但是,迟早,我们可能需要从IReader中获得一个单独的元素,而不是一次获得整个集合。 由于我们在接口上使用了通用类型,但是在对象中没有“自然ID”属性,因此我们将扩展位于特定索引处的元素。
这是我们
GetItemAt方法的接口(来自
IReader.cs文件的最终版本):

GetItemAt此处假定为默认实现。 乍一看-还不错。 它使用一个现有的接口成员(
GetItems ),因此,此处不作“外部”假设。 结果,他使用了LINQ方法。 我是LINQ的忠实拥护者,我认为这段代码是合理构建的。
性能差异由于默认实现调用
GetItems ,因此它要求在选择特定项目之前返回整个集合。
对于
FibonacciReader这意味着将生成所有值。 以更新的形式,
Program.cs文件将包含以下代码:

所以我们叫
GetItemAt 。 结论如下:

如果我们在FibonacciSequence.cs文件中放置一个检查点,我们将看到为此生成了整个序列。
启动该程序后,我们将在该控制点上两次
GetItems :首先是在调用
GetItems ,然后是在调用
GetItemAt 。
假设对绩效有害这种方法最严重的问题是它需要检索整个元素集合。 如果此
IReader要从数据库中获取它,则必须从中提取很多元素,然后仅选择其中之一。 如果在数据库中处理这样的最终选择,那就更好了。
使用我们的
FibonacciReader ,我们可以计算每个新元素。 因此,必须对整个列表进行完全计算,以得到我们所需的一个元素。 斐波那契数列计算是一种不会给处理器带来太多负担的操作,但是如果我们处理更复杂的事物,例如,我们将计算素数怎么办?
您可能会说:“好吧,我们有一个
GetItems方法,它返回所有内容。 如果工作时间太长,则可能不应该在这里。 这是一个诚实的声明。
但是,调用代码对此一无所知。 如果我调用
GetItems ,那么我知道(可能)我的信息将必须通过网络,并且此过程将是密集的日期。 如果我要一件东西,那为什么还要花这么多钱呢?
具体性能优化对于
FibonacciReader我们可以添加自己的实现以显着提高性能(在
FibonacciReader.cs文件的最终版本中):

GetItemAt方法将覆盖接口中提供的默认实现。
在这里,我使用与默认实现中相同的LINQ
ElementAt方法。 但是,我没有将此方法与GetItems返回的只读集合一起使用,而是与FibonacciSequence(即
IEnumerable 。
由于
FibonacciSequence是
IEnumerable ,因此一旦程序到达我们选择的元素,对
ElementAt的调用
ElementAt结束。 因此,我们将不会生成整个集合,而只会生成位于索引中指定位置之前的元素。
要尝试此操作,请在应用程序中保留我们上面所做的控制点,然后再次运行该应用程序。 这次,我们一次(在调用
GetItems )
GetItems遇到一个断点。 调用
GetItemAt时不会发生。
一个稍微做作的例子这个示例有些牵强,因为通常来说,您不必按索引从数据集中选择元素。 但是,您可以想象如果我们使用自然ID属性,可能会发生类似的事情。
如果按ID而不是按索引提取项目,则默认实现可能会遇到相同的性能问题。 默认实现要求返回所有元素,然后才从中选择一个。 如果允许数据库或其他“读取器”通过其ID提取特定元素,则这样的操作将更加高效。
考虑一下你的假设假设是必不可少的。 如果我们试图在代码中考虑我们库的任何可能用例,那么将永远不会完成任何任务。 但是您仍然需要仔细考虑代码中的假设。
这并不意味着
GetElementAt实现不一定很糟糕。 是的,它存在潜在的性能问题。 但是,如果数据集很小,或者计算的元素“便宜”,则默认实现可能是一个合理的折衷方案。
但是,在接口已经具有实现者之后,我不欢迎对接口进行更改。 但我知道,在某些情况下,首选替代选项。 编程是解决问题的方法,解决问题时,有必要权衡我们使用的每种工具和方法固有的利弊。
默认实现可能会损害接口实现者(以及可能调用这些实现的代码)。 因此,您需要特别注意与默认实现有关的假设。
祝您工作顺利!