
下午好,我想与大家分享我对Windows容器配置和使用AWS EKS(弹性Kubernetes服务)服务的经验,或者对于那些对Windows容器这项服务感兴趣的人,更确切地说是无法使用该服务以及AWS系统容器中的错误。在猫下。
我知道Windows容器不是一个流行的话题,很少有人使用它们,但是尽管如此,还是决定写这篇文章,因为有几篇有关kubernetes的文章和有关Habré的Windows的文章,仍然有这样的人。
开始
一切始于我们公司的服务,因此决定迁移到kubernetes,它是70%的Windows和30%的linux。 为此,AWS EKS云服务被视为可能的选项之一。 直到2019年10月8日AWS EKS Windows进入Public Preview,我才开始使用kubernetes版本,该版本在较旧的1.11版本中使用,但我还是决定对其进行检查,以查看该云服务在什么阶段正常工作,如果它确实可以正常工作,那不是一个带有删除炉膛的错误,而旧炉膛则停止通过与Windows Worker节点相同子网中的内部ip响应。
因此,决定放弃使用AWS EKS,而在同一EC2的kubernetes上使用它们自己的集群,只有我自己必须通过CloudFormation描述所有平衡和HA。
Amazon EKS Windows容器支持现已普遍可用
由马丁·比比| 上2019年10月8日我没有时间为自己的集群向CloudFormation添加模板,因为我看到了这一消息,
现已全面提供Amazon EKS Windows容器支持当然,我推迟了所有开发工作,并开始研究它们对通用航空所做的工作,以及从“公开预览”中如何改变一切。 是的,AWS研究员现已将Windows worker节点的映像更新为1.14版,并在EKS中将群集版本更新为1.14版,并支持Windows节点。 他们关闭了
github上的Public Preview项目,并说现在在这里使用官方文档:
EKS Windows支持将EKS群集集成到当前的VPC和子网中
在所有消息中,在公告上方的链接以及文档中,建议仅使用Amazon的公共子网,然后通过专有实用程序eksctl或CloudFormation + kubectl部署集群,仅使用Amazon的公共子网,并为新集群创建单独的VPC。
此选项不适用于许多情况,首先,单独的VPC是其成本+对等流量到您当前VPC的额外成本。 对于那些已经在AWS中拥有现成基础架构且具有多个AWS账户,VPC,子网,路由表,传输网关等的用户该怎么办? 当然,我不想分解或重做所有事情,我需要使用现有的VPC将新的EKS群集集成到当前的网络基础结构中,并为最大的拆分,为群集创建新的子网。
在我的情况下,选择了此路径,我使用了现有的VPC,仅为新集群添加了2个公共子网和2个私有子网,当然,所有规则均根据
创建Amazon EKS Cluster VPC的文档进行了考虑。
还有一种条件是使用EIP的公共子网中没有工作节点。eksctl与CloudFormation
我将立即预约尝试两种集群部署方法,在两种情况下图片都是相同的。
由于此处的代码较短,因此我将仅显示使用eksctl的示例。 使用eksctl群集的部署分为3个步骤:
1.创建集群本身+ Linux worker节点,稍后将在其上放置系统容器和非常糟糕的vpc-controller。
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
为了部署到现有的VPC,只需指定子网的ID,然后eksctl将确定VPC本身。
为了使工作节点仅部署到专用子网,您需要为节点组指定--node-private-networking。
2.在集群中安装vpc-controller,然后通过计算可用ip地址的数量以及实例上ENI的数量(添加和删除)来处理我们的工作节点。
eksctl utils install-vpc-controllers --name yyy --approve
3.在成功地在包括vpc-controller的linux worker节点上启动系统容器之后,仅使用Windows worker创建另一个节点组。
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
在您的节点成功挂接到集群并且一切似乎都很好之后,它处于“就绪”状态,但是没有。
vpc-controller中的错误
如果尝试在Windows Worker节点上运行Pod,则会收到错误消息:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
更深入地看,我们看到我们的AWS实例如下所示:

它应该像这样:

由此可见,vpc-controller由于某种原因未能发挥作用,因此无法向实例添加新的ip地址,以便pod可以使用它们。
我们来看看vpc-controller pod日志,这是我们看到的:
kubectl日志<vpc-controller-deployment> -n kube-system I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Google搜索没有任何结果,因为显然还没有人发现这样的错误,或者没有发布任何问题,我必须首先考虑所有选项。 首先想到的是,vpc-controller可能无法清醒ip-10-xxx.ap-xxx.compute.internal并通过它进行调试,因此错误降低了。
是的,的确,我们在VPC中使用了自定义dns服务器,而我们没有使用Amazon服务器,因此即使在该域ap-xxx.compute.internal上也没有配置转发。 我检查了此选项,它没有带来任何结果,也许测试不干净,因此,在与技术支持进行沟通时,我屈服于他们的想法。
由于没有任何想法,所有安全组都是由eksctl本身创建的,因此毫无疑问,它们在起作用,路由表也正确,nat,dns,并且还可以通过工作节点访问Internet。
同时,如果在不使用--node-private-networking的情况下将工作程序节点部署到公共子网,则该节点将立即由vpc-controller更新,并且一切工作都像时钟一样。
有两种选择:
- 锤击并等待有人描述AWS中的这个错误,他们会修复它,然后您可以安全地使用AWS EKS Windows,因为他们刚刚进入GA(撰写本文时花了8天的时间),很可能很多人会和我一样。
- 写信给AWS Support并向他们解释来自各地的整堆日志的问题实质,并向他们证明使用VPC和子网时其服务不起作用,拥有业务支持并不是徒劳的,我们必须至少使用一次:-)
与AWS工程师的交流
在门户网站上创建票证后,我错误地选择通过Web-电子邮件或支持中心答复我,尽管我的票证具有严重性-系统受损,这意味着在<12之内可以答复小时,并且由于业务支持计划提供24/7全天候支持,所以我一直希望获得最好的支持,但结果却一如既往。
我的机票从星期五到星期一降落在未分配的机票,然后我决定再次写票,然后选择“聊天回答”选项。 短暂的等待后,Harshad Madhav被任命为我,然后开始...
我们连续3个小时在线与他辩论,传输日志,将同一集群部署到AWS实验室以模拟问题,并重新创建集群,依此类推,我们唯一遇到的就是日志显示解决方案无效正如我上面写的,AWS内部域名,Harshad Madhav要求我创建转发,据说我们使用自定义dns,这可能是个问题。
转寄
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
做完了,这一天结束了,Harshad Madhav取消了对该支票的订阅,它应该可以工作,但是不,该决议没有帮助。
然后与另外2位工程师进行了交谈,其中一位刚从聊天中掉出来,显然害怕遇到麻烦的情况,第二位工程师又在整个调试周期中度过了我的一天,发送日志,在双方上创建集群,最后他说得很好,对我有用,在这里,我官方文档我会一步一步地做,您就会成功。
我礼貌地请他离开,如果您不知道在哪里寻找问题,请另外分配我的机票。
决赛
第三天,我任命了一位新工程师Arun B.,从与他进行交流的一开始,就很明显这些人不是以前的3位工程师。 他阅读了整个历史,并立即要求在github上的ps1上使用自己的脚本收集日志。 然后是创建集群,输出团队结果,收集日志的所有迭代,但是根据向我提出的问题判断,Arun B.朝着正确的方向前进。
当我们在其vpc-controller中添加-stderrthreshold = debug时,接下来会发生什么? 它当然不起作用)pod只是不以该选项开头,只有-stderrthreshold = info有效。
这是我们结束的地方,Arun B.说他将尝试重现我的步骤以得到相同的错误。 第二天,我收到了Arun B的答复。他没有放弃此案,而是接受了他们的vpc-controller的检查代码,发现在同一地方可以使用它,为什么不起作用:
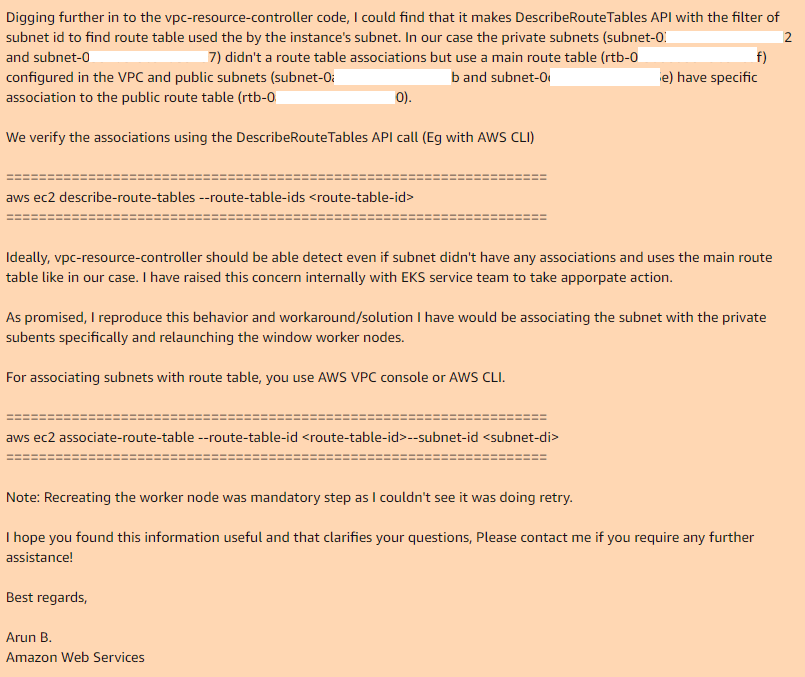
因此,如果您在VPC中使用主路由表,则默认情况下它不与必要的子网关联,因此,对于公共子网,必要的vpc-controller具有一个具有关联的自定义路由表。
通过手动添加主路由表与所需子网的关联,并重新创建节点组,一切都可以完美运行。
我希望Arun B.确实会将此错误报告给EKS开发人员,并且我们将看到vpc-controller的新版本,并且所有功能都可以立即使用。 当前最新版本:602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
有这个问题。
感谢所有读完本书的人,在实施之前测试您将在生产中使用的所有内容。
更新:新的错误#2
在找到第一个问题的解决方案之后,我们继续为我们的需求准备该服务,现在在最后阶段,我们发现了另一个与生活不兼容的错误。
问题:将应用程序部署到Kubernetes,设置部署,副本> 1,然后查看下图。 新的Pod可以正常启动并工作,而旧的Pod则失去其网络接口。 是的,是的,旧的pod完全没有网络,尽管它仍处于“运行”状态。 减少或增加副本,删除Pod,这样您就不会总是只处理最后一个进入“运行”状态的Pod,而其余的则不会。 无论如何,吊舱或不同吊舱均始于同一节点。
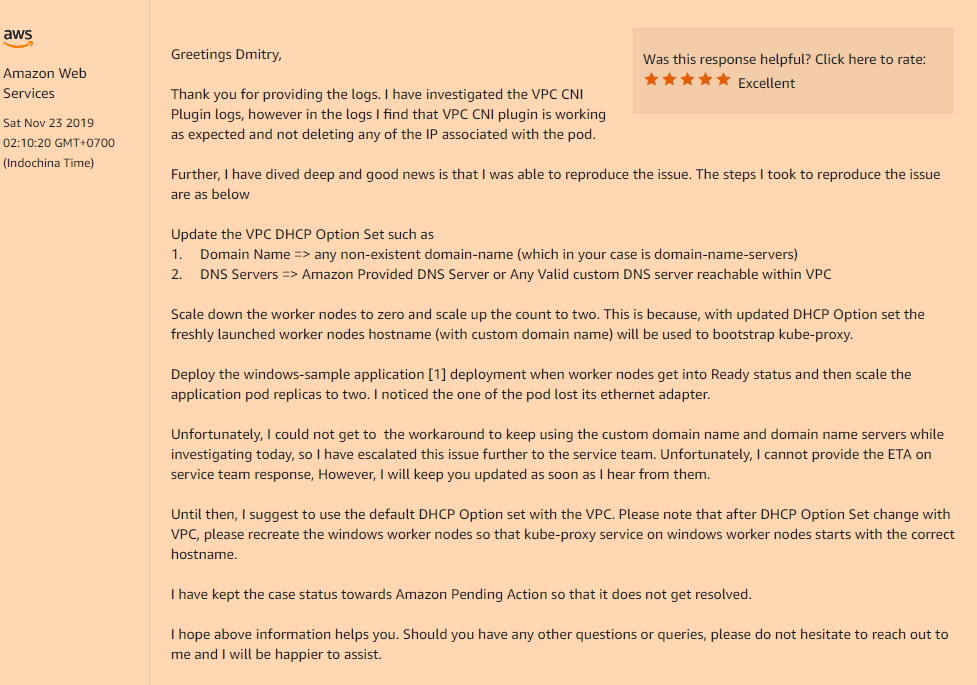
解决方案:是的,问题仍然出在我们的VPC的自定义配置中,也就是说,如果您使用的DHCP选项集指示域名字段的自定义值,或者是完全空的(例如,我只更改了域名服务器,我不需要其余的东西),启动后,您的pod内的网络接口就会消失,您将遇到一个无法理解的问题。
您需要在“ DHCP选项”集中注册它:
domain-name = <aws-region-name>.compute.internal;
然后,重新安装所有工作节点,以便在引导过程中所有组件都注册正确的设置。
以下是此域名选项如何影响您的工作节点的详细信息:
这次,我要求他们至少将文档“服务”的这些“功能”添加到适用于Windows的AWS EKS。