目的和目的
在一系列文章中,我们将讨论语音呼叫的分类器,为何需要它们,如何使它们快速发挥作用。 我将告诉您一些方法,这些方法将减少从设置任务到启动模型并获得业务成果的时间。
对于本文,您可以在链接中查看报告
Methodius如何成为Anna。 系列1
让我们开始吧!
我叫朱莉娅(Julia),我是一家大型提供商的机器学习部门的一名工程师。 每天大约有3,000个来自客户的电话到达我们的呼叫中心。 每个话务员平均每天接听100个电话。 那又怎样 看来这可以接听100个电话。 但是,有很多致电公司的主题,运营商需要了解公司的所有产品,服务和流程。 如果我们采用最典型的客户要求,则可以将它们分为40个(!)主题,并且仍然存在一些非典型的应用程序也需要进行处理。

由于主题多种多样,操作员培训花费了三个月的时间。 首先,您需要研究所有说明,然后才可以接听电话。 正在花费大量资源来创建新的合格操作员。 因此,产生了使操作员逐步适应的想法。 就是说,他只会接到他已经掌握的主题的电话,随着时间的推移,他会提高技能,学习其他主题。
好主意,为什么不做...简单的IVR? (一种预先录制的语音消息系统,该系统使用客户端通过音调拨号在电话键盘上输入的信息来路由呼叫中心内的呼叫。)
但是很少有人喜欢长时间聆听录制的声音,等待等待必须按下的数字,但最终他们仍然没有获得必要的信息。
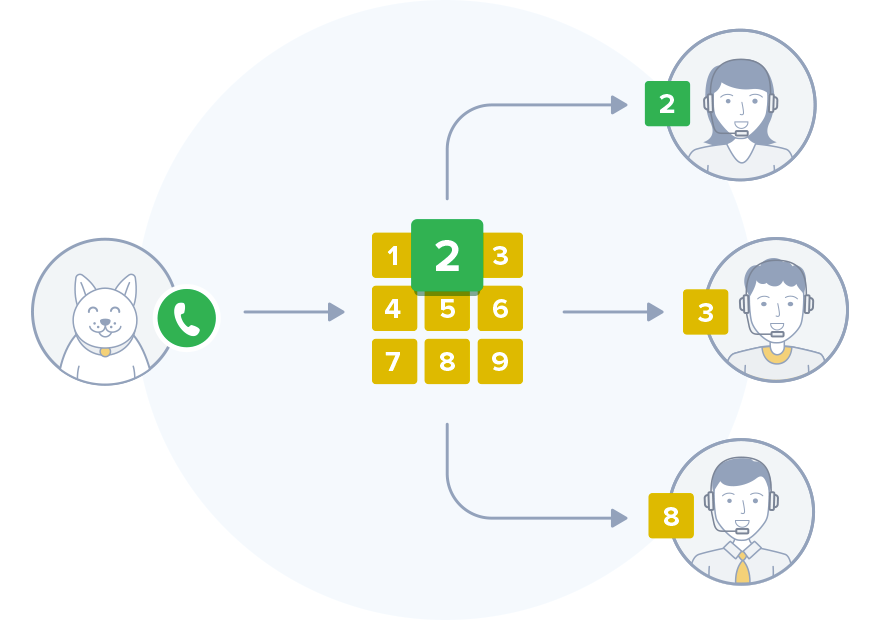
我们不想用IVR折磨我们的客户,因此我们设定了任务-根据第一句话对订户的请求进行分类。 因此,根据语音请求,将在运营商之间进行路由。
资料
关于每个呼叫结果的技术支持运营商已经公开了大约10年的呼叫主题。 我们确定了最多的16组,并且这些主题中出现了标记。 然后,我们上传了关于各种主题的12万次对话的记录,使用Yandex.SpeechKit识别了客户对话的记录,然后将它们按沉默分为短语。 因此,我们获得了带有单独短语的音频片段。
让我提醒您,我的目标是对客户的初始请求进行分类,因此从每个呼叫中仅选择第一个短语。 总计,该数据是文本格式的12万个客户短语,带有来自运营商的标记。 标准文本预处理:删除停用词,对文本进行规范化(技巧:将“ not”粒子附加到下一个单词),数据准备就绪。 在另一篇文章中,我将进一步介绍我们的预处理管道。
分类
然后,在收到处理后的文本后,我们进行了许多实验,对模型和嵌入的各种配置进行了分类。
最好的结果来自标准的TF-IDF套件和逻辑回归。 下表显示了f得分指标。 在某些实验中,除了文本外,在调用时还添加了有关客户端(上下文)的其他11个标志。 希望这会以某种方式提高质量。 上下文-这些是布尔符号,客户现在是否有负余额,维修是否已分配给该地址,以及其他当前代表客户的特征。 但是即使有背景,质量也很差,仅实现了72%。
错误分析
没有错误分析,分类的质量就无法提高。 在检查了模型错误的情况之后,我们确定了以下典型问题:
标记
由于对话可以从一个主题开始并以另一个主题结束,并且操作员设置了通话的主题,因此在对话结束时说了这样的话,因此标记通常是不正确的。 手动重新分配这种情况,问题消失了。
班级余额
有几种平衡类的方法。
更多细节- 欠采样。 从大类中随机删除示例。
- 过度采样。 随机添加次要课程中的示例。
- 综合少数族裔过采样。 随机添加最小类的示例,但略有更改。
选择哪种方法取决于任务和数据量。 作为此任务的一部分,可以通过从频率最高的类别中删除样本到样本数量的中位数来平衡数据集,但次要类别保持不变。
在阅读了最初的几个短语之后,我们注意到36%的查询包含不具信息性的文本,例如:“你好,你好”或“你好,我有问题”。 只有在操作员问:“您的问题是什么?”之后,客户才提出问题。
因此,从对话中仅提取客户的第一句话是错误的;一个人根本无法立即提出请求。 因此,对于每个第一短语,计算“信息性”。 如果模型未将请求具有较高的置信度归因于任何类别,即所有类别都收到了相等的概率值,那么该消息将无用,您需要使用第二个短语。 如果已经很有可能确定了类别,则第一个短语就足够了。
此处可能会出现正确的问题,但对产品应该怎么做,因为将存在相同的无信息查询。 我将在下一篇文章中稍后讨论。
语音识别
分析错误时,我们注意到文本识别不正确,这是由于错误定义了类。 例如,“平衡”一词有时被“香蕉”代替。 我们决定比较Yandex和Google的认可度。 Google在我们的数据上显示出了更好的优势,但并没有付出太多,价格几乎是后者的两倍。
错误分析摘要
经过分析和纠正错误后,我们能够将质量提高到84%的平均f评分;最佳质量仍然是逻辑回归的结果。
结论
总结发展的第一阶段,我们可以得出以下结论。
首先,您需要处理数据和标记。 您不应该立即训练神经网络,因为使用不正确的数据不会因此受益匪浅。 为了避免浪费时间和精力,分析“简单”模型上的错误就足够了。
在第二系列中见 ,我们将讨论如何高效地运行经过训练的模型。 我们将听取有关机器人Methodius如何接听电话的示例,并且我们将了解他为何成为Anna。