
在分配排序中,将元素分配并重新分配到类中,直到对数组进行排序为止。
在最一般的情况下,这几乎以相同的方式发生。 元素根据某种标准按类别分散。 如果这不导致数组排序,则对类的属性进行精炼,然后将元素再次分散到精炼的类。 直到阵列变得有序为止。
在按分布排序时,几乎总是没有元素之间及其交换之间的比较。 最主要的是,该元素是否属于某个类,与其他元素的比较很少起作用。
通常,这些排序具有线性时间复杂度(而不是对数,如有效的交换,合并,选择或插入排序)。 同样,此类的算法几乎总是需要大量额外的内存,因为按类分组的元素必须存储在某个位置。
分布排序非常适合对整数和字符串进行排序。 用它们对实数进行排序通常很不方便。 而且,分布对由重复数字组成的数组进行了完美排序-重复次数越多,所需的类越少。

本文是在EDISON的支持下编写的。
客户意见: EDISON的10多位程序员
这很有趣,并且很有用: 早餐程序员
考虑一种最能凸现上述特性的算法。
斗类::斗类
其他名称是篮子分类,块分类,口袋分类。
我们将数字分散在篮子中,然后在每个篮子中分散在较小的篮子中,依此类推,直到篮子中的某个位置只有相同的元素。 然后,可以从最低级别的存储篮中轻松恢复阵列的有序状态。
让我们用一个具体的例子来解释。 假设我们有一个无序数组。 已知此数组包含从1到8的数字。
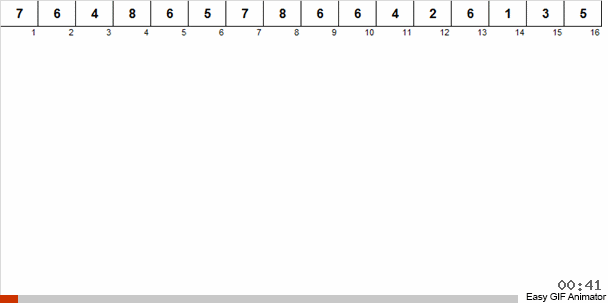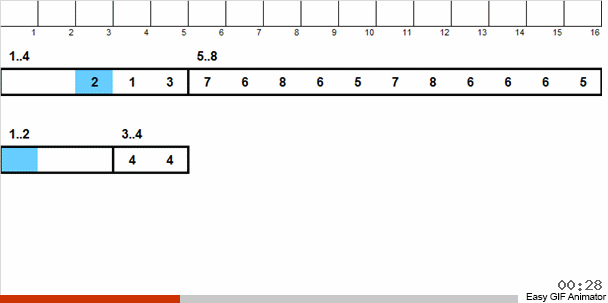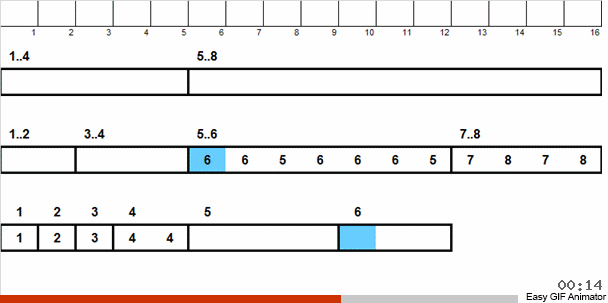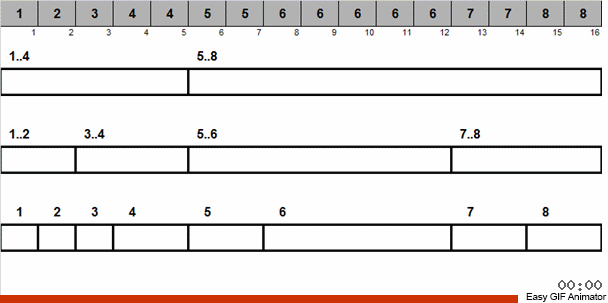
我们将这些数字分为2组:从1到4的数字分成一组,从5到8的数字分成第二组,然后将第一个篮子中的数字分配到两个篮子中:一个数字1和2,另一个3和4。我们还将这些篮子分发到已经包含相同大小数字的韧皮篮子中。 对于包含5到8的数字的大篮子,我们应用类似的递归。
然后,从每个都包含相同数字的小篮子中,按照优先顺序将元素返回到主数组。
这种形式的核分类在实践中并不是特别适用,但是它可以从标准上演示按分布进行的所有分类通常是如何工作的。
塔诺斯排序::塔诺斯排序
有时,作者分类会发送给我,这就是这种情况。 作者安德烈·达尼林(Andrei Danilin)称其为“俄罗斯的一半分类”,但是我将其称为Thanos分类。 或者,如果我们从使用的方法正式开始,我们可以称其为算术均值排序。
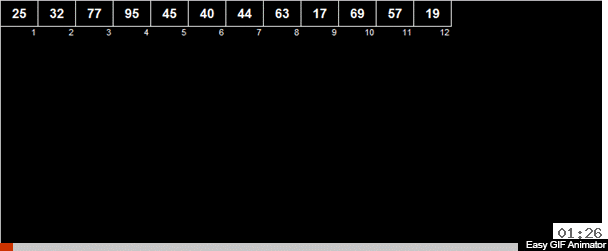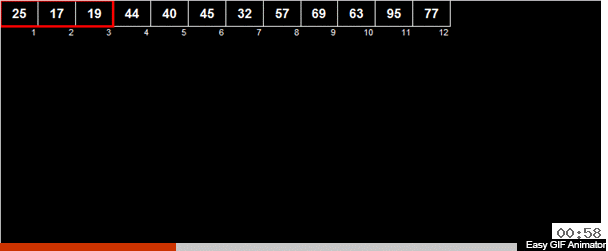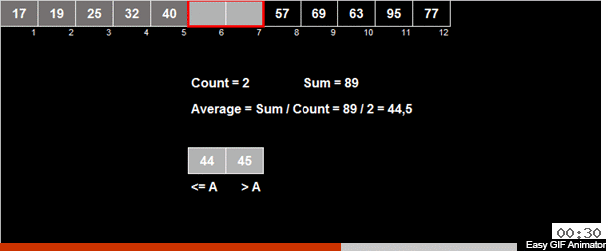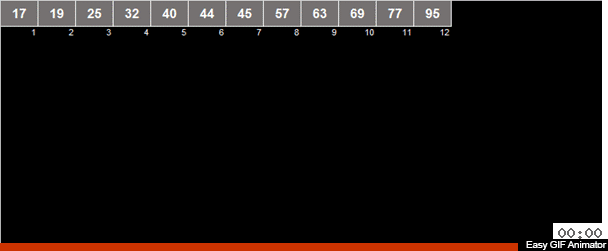
在数组中计算元素的算术平均值,然后将所有元素分为2组。 小于(或等于)算术平均值的元素进入一组,比第二组的算术平均值大。 然后,将相同的动作递归应用于两个组,以此类推。
那疯狂的钛呢? 如果这是一个随机数组,则与算术平均值相比,该元素大体上有50/50的机会会进入两组之一。
顺便说一句,在互联网上,我遇到了另一个同名的漫画算法。 如果未对数组进行排序,则单击“无限手套”,然后将随机选择的一半数组元素发送到不存在。 如果幸存者组成一个有序的队伍,那么就可以认为他们的伟大使命已经实现。 如果尚未点击,则可以再点击几下。

但是回到我们的分布排序。 它们全部可以分为两组-
计数排序和
按位排序 。 好吧,如果您愿意的话,您也可以突出显示
计数位排序 ,即 那些可以归因于两者。
还有混合算法(这些算法使用不同类的方法,例如,Tim的排序是合并排序和插入排序的混合,自省排序是进入一堆排序的快速排序等),包括分布排序但是,混合动力是一个单独的部分。 稍后关于他们。
千排序和算术平均值排序与计数排序有关。
计数排序
基本思想是我们计算每个班级有多少个数字。
计数排序::计数排序
我们计算一个或另一个数字在数组中出现的次数。 知道了这些数量后,我们迅速形成一个已经排序的数组。
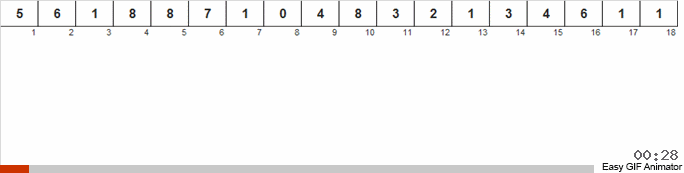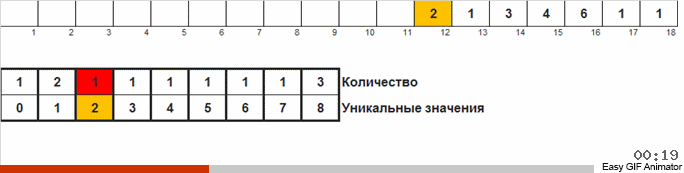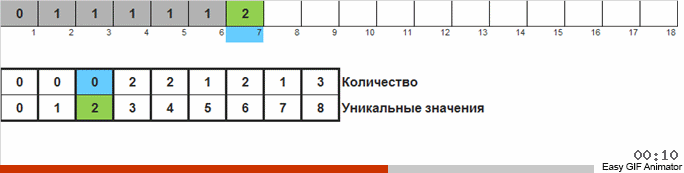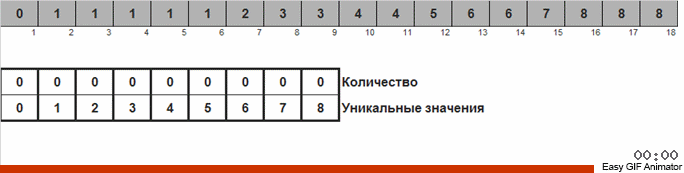
对于这种排序,您需要知道数组中的最小值和最大值。 然后为辅助阵列生成密钥,在该密钥中我们确定其满足的条件和次数。
Python代码:
def CountingSort(array, mn, mx): count = defaultdict(int) for i in array: count[i] += 1 result = [] for j in range(mn,mx+1): result += [j]* count[j] return result
鸽子排序::鸽子洞排序
我们遍历数组,如果找到一个新数字,那么我们将启动该数字的计数器(作为辅助列表的键)。 如果不是第一次遇到该数字,则仅触发该计数器的增量。
与以前的方法的不同之处在于,在通过计数进行排序时,我们会立即启动数组中可能出现的所有可能数字的计数器(如果知道数组中的最大值和最小值,我们可以负担得起)。 一些数字永远不会出现,并且其计数器显示为零。 在鸽子分类中,我们仅针对数组中实际出现的数字启动计数器。 数组用于对计数器进行计数排序,而双链列表用于鸽子排序,这使您可以在旅途中添加新的计数器。
这种方法有时也称为
Dirichlet排序 ,因为该算法本身是Dirichlet原理的各种结果的说明。
如果将N个对象分布在M个容器中,并且N> M,则至少一个容器包含一个以上的元素。
Python代码:
def PigeOnHoleSort(a): mi = min(a) size = max(a) - mi + 1 holes = [0] * size for x in a: holes[x - mi] += 1 i = 0 for count in range(size): while holes[count] > 0: holes[count] -= 1 a[i] = count + mi i += 1
位排序
我们根据数字的特定类别中的哪个数字来分配数字。 如果我们多次对不同的数字执行此操作,那么我们突然会得到一个排序数组。
低阶按位排序:: LSD基数排序

我们从较低的数字移到较大的数字,并且在每次迭代时,根据数字中的数字来分配数组的元素。
在下一次分发之后,我们按照元素在下一次重新分发期间落入类的顺序将元素返回到主数组。
对于按位排序,将元素视为具有相同位数的数字很重要。 如果实际数字位数不同,则可以通过将其他零添加为更高的数字来解决该问题。
高阶按位排序:: MSD基数排序

首先,我们在高级职级之间进行分配,然后从这些职级转移到年轻级。
由于向低位数字的转换是在类内部而不是在数组的所有元素之间递归执行的,因此此选项更难以实现。
但是,由于MSD比LSD更快,这一事实使这种复杂性得到了回报。 从较低的数字传递到较大的数字时,必须处理所有数字的所有数字才能正确排序。 如果您从高年级转到低年级,那么实际上您不必处理所有数字的所有数字,通常,排序状态会更早。
大多数按位排序是更有效的MSD的变体。 这对排序字符串特别有用;为此,通常使用后缀树。 我们将在以下文章之一中进行分析。
计数按位排序
有时,分布排序是同时可计数的和按位的。
珠子分类::珠子分类

该算法的其他名称:算盘排序,重力排序。
我已经写过几次有关这种排序的文章(
1,2 ),所以我会简短地介绍一下,只涉及本质。
假设数组中的每个数字都是一组球,那么球的数量就是一个数字的值。 如果我们将这些数字作为这些球的水平行彼此排列,然后将其垂直推入,则得到一个有序数组。
这里的技巧是在一元数系统中,我们用球表示每个数字。 实际上,我们只计算所有数字每个数字有多少次。
Python中的BeadSort一行:
稍后,我们将分析更复杂的按位排序,其中
美国国旗排序占据着突出的位置。
参考文献
 桶
桶 ,
计数 /
鸽孔 /
Dirichlet ,
基数 /
排放 ,
珠系列文章:
AlgoLab Excel应用程序已得到重大更新。 今天这篇文章中的一些算法是第一次出现在这里。 更新正在使用的人。