南桥解决方案架构师和Slurm讲师Pavel Selivanov在2019年DevOpsConf上做了演讲。该报告是Kubernetes深度Slur Mega深度课程的一部分。
Slurm Basic: 11月18日至20日在莫斯科对Kubernetes进行了介绍 。
Slurm Mega: 11月22日至24日, 我们在Kubernetes的幕后 –莫斯科。
在线Slurm:两种Kubernetes课程始终可用。
在报告的抄本下-成绩单。
同事和同情者,下午好。 今天,我将讨论安全性。
我看到今天大厅里有许多保安人员。 如果我不按照您惯用的方式使用安全领域的条款,我会提前向您道歉。
碰巧的是,大约六个月前,我进入了一个Kubernetes公共集群。 公共-表示存在第n个名称空间,在这些名称空间中,有用户被隔离在其名称空间中。 所有这些用户都属于不同的公司。 好吧,原以为该群集应该用作CDN。 也就是说,他们给您一个集群,他们给用户在那里,您在名称空间中到达那里,部署前端。
他们试图将这种服务卖给我以前的公司。 我被要求在这个问题上打个招呼-这种解决方案是否合适。
我来到这个集群。 我被授予有限的权限,有限的名称空间。 在那里,他们知道什么是安全。 他们读到了基于Kubernetes的基于Rober的访问控制(RBAC),并且他们扭曲了它,以便我不能将Pod与部署分开运行。 我不记得我试图通过在没有部署的情况下运行来解决的任务,但我真的很想在下面运行。 我决定好运,看看我在集群中拥有什么权利,我能做什么,我不能做什么,他们搞砸了什么。 同时,我将告诉您它们在RBAC中的配置有误。
碰巧的是,两分钟后,我让他们的集群成为管理员,查看了所有相邻的命名空间,看到了已经购买了该服务并被困在那里的公司的生产前沿。 我几乎没有停下脚步,以免走到前面的人,也不要在首页上放任何淫秽的词。
我将举例说明我是如何做到的,以及如何保护自己免受此侵害。
但首先,请自我介绍。 我叫Pavel Selivanov。 我是Southbridge的建筑师。 我了解Kubernetes,DevOps和各种花哨的东西。 我和南桥工程师正在构建所有这些,我建议。
除了我们的核心业务,我们最近还启动了名为Slory的项目。 我们正在努力将与Kubernetes合作的能力带给大众,也要教其他人如何与K8合作。
我今天要谈的是什么。 该报告的主题很明显-有关Kubernetes集群的安全性。 但是我想马上说这个话题非常大-因此我想立即规定我不会肯定说的话。 我不会谈论在Internet上已经被磨碎一百倍的黑话。 任何RBAC和证书。
我将谈论我和我的同事如何对Kubernetes集群的安全感到厌倦。 我们提供Kubernetes集群的提供商以及来找我们的客户都会遇到这些问题。 甚至还有其他咨询管理公司来找我们的客户。 也就是说,悲剧的规模实际上很大。
从字面上讲三点,我今天要谈:
- 用户权限与pod权限。 用户权限和壁炉权限不是一回事。
- 集群信息收集。 我将展示从该群集中可以收集所需的所有信息,而无需在该群集中拥有特殊权限。
- 集群上的DoS攻击。 如果我们无法收集信息,则可以在任何情况下放置群集。 我将讨论对集群控件的DoS攻击。
我要提到的另一件事是我在所有地方进行了测试,可以肯定地说所有工作都可以进行。
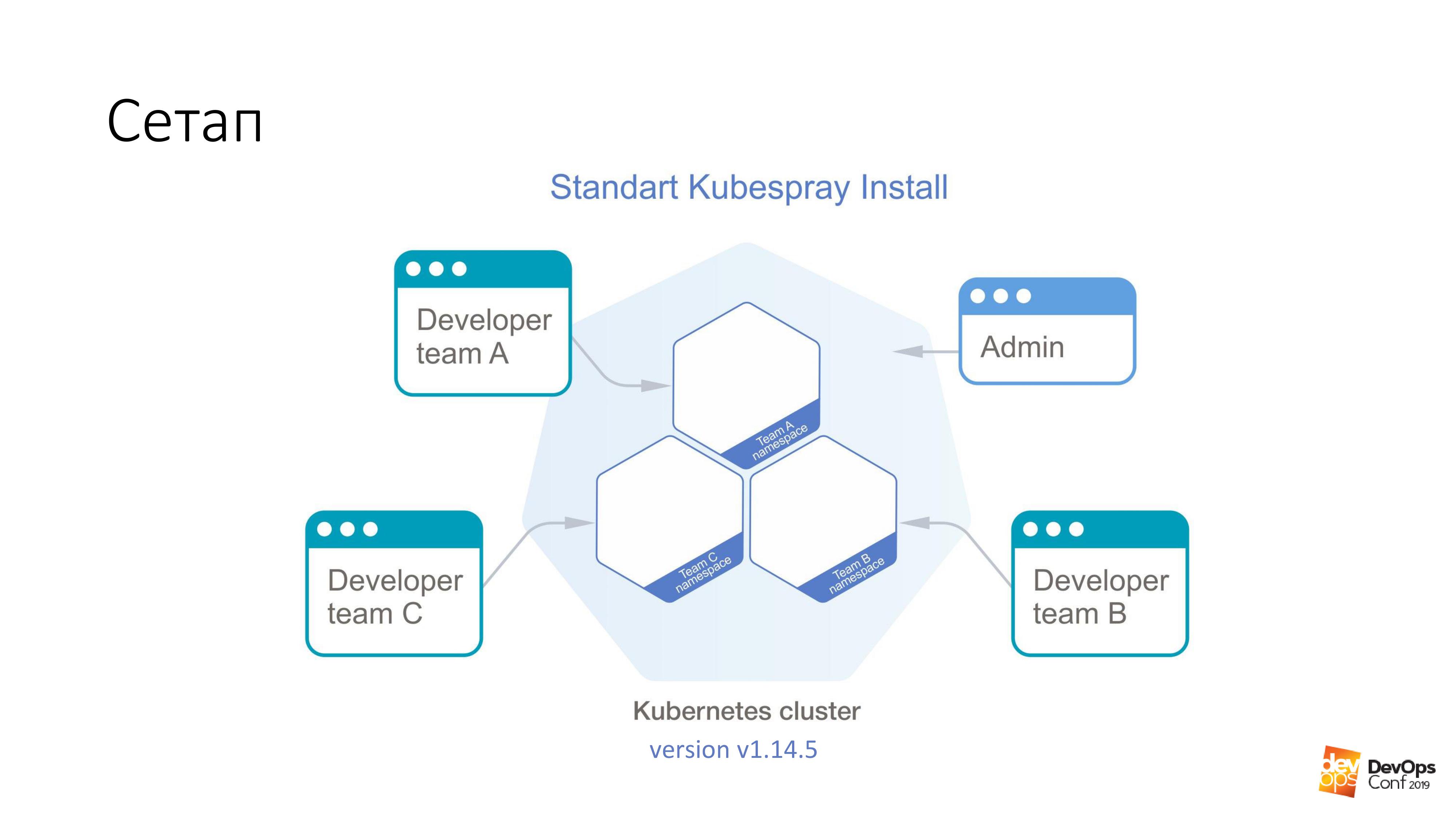
作为基础,我们将使用Kubespray安装Kubernetes集群。 如果有人不知道,这实际上是Ansible的一组角色。 我们在工作中不断使用它。 好消息是,您可以在任何地方滚动-您可以在腺体上滚动,也可以在云中的某个地方滚动。 一种安装方法原则上适用于所有情况。
在这个集群中,我将拥有Kubernetes v1.14.5。 我们将考虑将古巴的整个集群分为多个命名空间,每个命名空间都属于一个单独的团队,该团队的成员可以访问每个命名空间。 他们不能进入不同的名称空间,只能进入自己的名称空间。 但是,有些管理员帐户拥有对整个群集的权限。
我保证我们要做的第一件事就是获得群集的管理员权限。 我们需要一个专门准备的吊舱,它将打破Kubernetes集群。 我们需要做的就是将其应用于Kubernetes集群。
kubectl apply -f pod.yaml
该吊舱将到达Kubernetes集群的主人之一。 之后,集群将很高兴向我们返回一个名为admin.conf的文件。 在古巴,所有管理证书都存储在此文件中,同时配置了集群API。 我认为,这就是您可以对98%的Kubernetes群集进行管理员访问的方式。
我再说一遍,这个pod是由您集群中的一位开发人员制作的,该开发人员有权将其提案部署到一个小型命名空间中,而他全都受RBAC的束缚。 他没有权利。 但是,证书已经退回。
现在关于特别准备的壁炉。 在任何图像上运行。 例如,以debian:jessie为例。
我们有这样的事情:
tolerations: - effect: NoSchedule operator: Exists nodeSelector: node-role.kubernetes.io/master: ""
什么是宽容? Kubernetes集群中的主机通常标有一个叫做taint(英语为“ infection”)的东西。 而这种“感染”的本质是-她说豆荚不能分配给主节点。 但是没有人愿意以任何方式表明他对“感染”是宽容的。 容忍部分只是说,如果NoSchedule在某个节点上,那么我们的这种感染是可以容忍的-没问题。
此外,我们说我们的弱点不仅是宽容的,而且还想专门落在主人身上。 因为主人是我们需要的最美味的食物-所有证书。 因此,我们说nodeSelector-向导上有一个标准标签,它使我们能够从群集的所有节点中精确选择那些是向导的节点。
有了这两部分,他肯定会成为大师。 而且他将被允许住在那。
但是仅仅成为主人对我们来说还不够。 它不会给我们任何东西。 因此,我们还有以下两点:
hostNetwork: true hostPID: true
我们指示我们正在启动的底层将位于内核名称空间,网络名称空间和PID名称空间中。 在向导上启动后,它将能够看到该节点的所有实际活动接口,侦听所有流量并查看所有进程的PID。
接下来,它很小。 接受etcd并阅读您想要的内容。
最有趣的是此Kubernetes功能,该功能默认存在。
volumeMounts: - mountPath: /host name: host volumes: - hostPath: path: / type: Directory name: host
其实质是可以说,即使没有该集群的权限,我们也要在运行的pod中创建一个类型为hostPath的卷。 这意味着从我们将要启动的主机处获取路径-并将其视为卷。 然后将其命名为:host。 我们将所有这些hostPath安装在炉膛内。 在此示例中,转到/ host目录。
我再说一遍。 我们告诉Pod进入主服务器,在那里获得hostNetwork和hostPID-并将主服务器的整个根安装在此Pod中。
您知道在debian中我们运行bash,并且该bash在我们的根目录下工作。 也就是说,我们只是获得了主服务器的根,而在Kubernetes集群中没有任何权利。
然后,整个任务是进入/ host / etc / kubernetes / pki下的目录,如果我没有记错的话,请在那里找到集群的所有主证书,并因此成为集群管理员。
如果您这样看,尽管有用户权限,但这些是pod中最危险的权限:

如果我有权在某些群集名称空间下运行,则默认情况下,此子项具有这些权限。 我可以运行特权Pod,这通常是所有权利,实际上是在节点上。
我最喜欢的是Root用户。 Kubernetes具有这样的选项“以非根方式运行”。 这是一种黑客保护。 您知道什么是“摩尔达维亚病毒”吗? 如果您是黑客,并且进入我的Kubernetes集群,那么我们(拙劣的管理员)会问:“请在您的Pod中指出要以非root用户身份运行我的集群的黑客。 碰巧的是,您可以在根底下的壁炉中启动该过程,这对您来说很容易被黑客入侵。 请保护自己免受自己的伤害。”
主机路径量-我认为这是从Kubernetes集群中获得所需结果的最快方法。
但是,如何处理所有这些呢?
任何遇到Kubernetes的普通管理员都会想到的想法:“是的,我告诉你,Kubernetes不起作用。 里面有孔。 而且整个立方体都是胡扯。” 实际上,这里有文档之类的东西,如果您看那里,就会发现Pod安全策略部分。
这是一个Yaml对象-我们可以在Kubernetes集群中创建它-控制炉膛描述中的安全性方面。 也就是说,实际上,它控制了启动时在吊舱中使用各种hostNetwork,hostPID和某些类型的卷的那些权限。 使用Pod安全策略,可以描述所有这些。
Pod安全策略中最有趣的事情是,在Kubernetes集群中,并没有简单地不描述所有PSP安装程序,而是默认情况下将它们关闭。 使用准入插件启用了Pod安全策略。
好的,让我们结束一个集群Pod安全策略,假设我们在命名空间中有某种服务Pod,只有管理员可以访问。 假设在其他所有广告连播中,他们拥有有限的权利。 因为最有可能的是,开发人员不需要在您的集群中运行特权Pod。
而且我们似乎做得很好。 而且我们的Kubernetes集群无法在两分钟内被黑客入侵。
有问题。 最有可能的是,如果您有一个Kubernetes集群,则在集群中安装了监视程序。 我什至假设要预测,如果您的集群中存在监视,则称为Prometheus。
我现在要告诉您的内容对Prometheus运算符和以其纯格式交付的Prometheus均有效。 问题是,如果我不能让管理员这么快地进入集群,那就意味着我需要更多。 我可以使用您的监视进行搜索。
大概每个人都在Habré上读过相同的文章,而监视就是监视。 舵图对于每个人来说都大致相同。 我假设如果您确实安装了stable / prometheus,那么您将获得大致相同的名称。 甚至最有可能,我也不必猜测您群集中的DNS名称。 因为它是标准的。
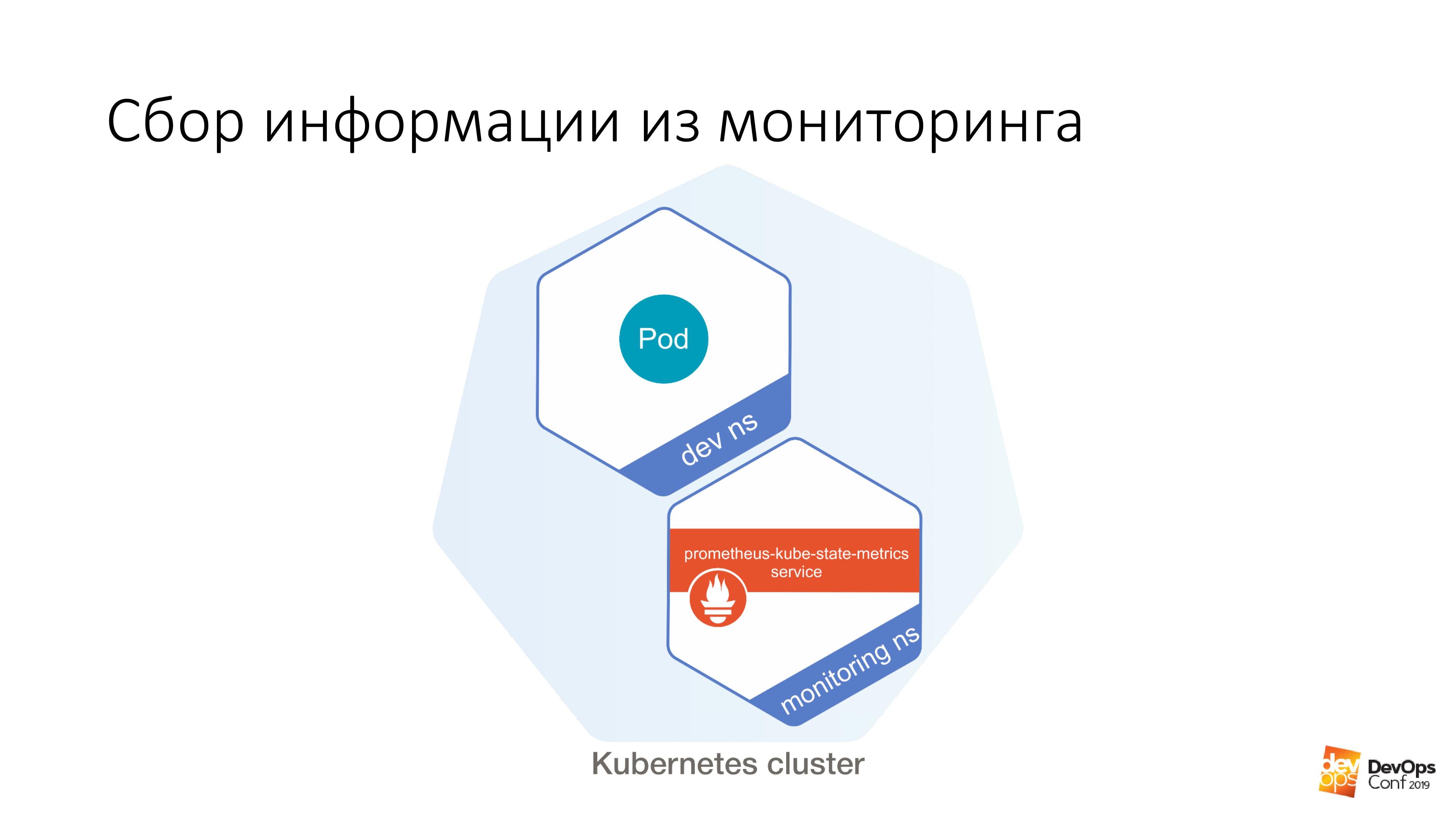
此外,我们有一个确定的设计,有可能启动某个确定的任务。 而且从这个灶台开始,这样很容易做到:
$ curl http://prometheus-kube-state-metrics.monitoring
prometheus-kube-state-metrics是从Kubernetes API收集指标的Prometheus出口商之一。 集群中正在运行大量数据,它是什么,它有什么问题。
作为一个简单的例子:
kube_pod_container_info {namespace =“ kube-system”,pod =“ kube-apiserver-k8s-1”,container =“ kube-apiserver”,图片=
“ gcr.io/google-containers/kube-apiserver:v1.14.5”
,Image_id = “搬运工-可拉://gcr.io/google-containers/kube- API服务器@ SHA256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989”,CONTAINER_ID = “搬运工:// 7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b”} 1
从无特权的文件发出简单的curl请求后,您可以获得这些信息。 如果您不知道正在运行哪个版本的Kubernetes,它将很容易告诉您。
最有趣的是,除了您转向kube-state-metrics之外,您还可以直接应用于Prometheus本身。 您可以从那里收集指标。 您甚至可以从那里建立指标。 即使从理论上讲,您也可以从Prometheus中的集群构建这样的请求,只需将其关闭即可。 并且您的监视通常在集群中停止工作。
在这里,已经出现了一个问题,即是否有任何外部监视监视您的监视。 我只是有机会在Kubernetes集群中行动,对我自己没有任何后果。 您甚至都不知道我在那儿表演,因为已经没有监控了。
就像PSP一样,问题在于所有这些新潮技术-Kubernetes,Prometheus-它们只是无效,而且充满漏洞。 不完全是
有这样的事情- 网络策略 。
如果您是普通管理员,那么很可能是关于网络策略的,您知道这是另一个Yaml,在群集中已经是dofig。 而且绝对不需要某些网络策略。 即使您阅读了什么网络策略,什么是Kubernetes yaml-firewall,它也允许您限制名称空间之间,pod之间的访问权限,然后您肯定会决定下一个抽象中的Kubernetes中的yaml型防火墙...不,不是。 绝对没有必要。
即使您的安全专家没有被告知使用Kubernetes,您也可以非常轻松,简单地构建防火墙,而且粒度非常精细。 如果他们仍然不知道并不会拉您:“恩,给,给...”无论如何,您都需要网络策略来阻止对某些服务场所的访问,而这些服务场所可以未经您的授权就从群集中提取。
如我引用的示例中所示,您可以从Kubernetes集群中的任何名称空间提取kube状态指标,而无需对其拥有任何权限。 网络策略关闭了从所有其他命名空间到命名空间监视的访问权限,以及一切:没有访问权限,没有问题。 在现有的所有图表中,无论是标准协议还是运营商协议中的协议,都只是在掌舵值中提供了一个选项,可以简单地为其启用网络策略。 您只需要打开它,它们就会起作用。
这里确实有一个问题。 作为一名普通的有胡子的管理员,您很可能决定不需要网络策略。 在阅读了有关Habr等资源的各种文章之后,您决定最好选择法兰绒,尤其是采用主机网关模式的法兰绒。
怎么办
您可以尝试重新部署Kubernetes群集中的网络解决方案,并尝试用功能更强大的替代它。 例如,在同一个印花布上。 但是,我想立即说一下,在Kubernetes工作集群中更改网络解决方案的任务相当艰巨。 我解决了两次(理论上两次),但是我们甚至在Slurms上展示了如何做到这一点。 对于我们的学生,我们展示了如何在Kubernetes集群中更改网络解决方案。 原则上,您可以尝试确保生产群集上没有停机时间。 但是您可能不会成功。
这个问题实际上很简单地解决了。 群集中有证书,并且您知道证书将在一年后失效。 好吧,通常是在群集中使用证书的普通解决方案-我们为什么要蒸蒸日上,我们将在它旁边提出一个新群集,让它在旧的群集中腐烂,然后我们将重做所有操作。 的确,当情况恶化时,一切都会落到我们这一天,然后是一个新集群。
当您要提出一个新的群集时,同时插入Calico而不是法兰绒。
如果您拥有颁发一百年的证书并且不打算重新群集集群该怎么办? 有这样的东西Kube-RBAC-Proxy。 这是一个非常酷的开发,它允许您将自己作为Sidecar容器嵌入Kubernetes集群中的任何壁炉。 实际上,她通过Kubernetes RBAC向此吊舱添加了授权。
有一个问题。 以前,Kube-RBAC-Proxy内置于操作员的Prometheus中。 但是后来他走了。 现在,现代版本依赖于您拥有网络策略并关闭使用它们这一事实。 因此,您必须稍微重写一下图表。 实际上,如果您转至该存储库 ,则有一些示例说明如何将其用作辅助工具,并且您将不得不最少地重写图表。
还有另一个小问题。 不仅Prometheus还将其指标提供给任何获得它的人。 我们也拥有Kubernetes集群的所有组件,它们可以提供其指标。
但是正如我所说,如果您无法访问群集并收集信息,那么至少可以造成危害。
因此,我将向您快速介绍两种破坏Kubernetes集群的方法。
当我告诉您时,您会笑,这是现实生活中的两种情况。
第一种方式。 资源不足。
我们推出了另一个特别的产品。 他将有这样一个部分。
resources: requests: cpu: 4 memory: 4Gi
如您所知,请求是主机上为带有请求的特定Pod保留的CPU和内存量。 如果我们在Kubernetes集群中有一个四核主机,并且有四个CPU来处理请求,那么这意味着不再有向该主机发出请求的Pod。
如果我在下面运行此命令,则将执行命令:
$ kubectl scale special-pod --replicas=...
这样,其他任何人都将无法部署到Kubernetes集群。 因为在所有节点中请求都将结束。 因此,我停止了您的Kubernetes集群。 如果我在晚上这样做,那么我可以停止部署一段时间。
如果我们再次查看Kubernetes文档,我们将看到称为极限范围的东西。 它为群集对象设置资源。 您可以使用yaml编写一个Limit Range对象,将其应用于某些名称空间-在该名称空间中,您还可以说您拥有默认,最大和最小Pod的资源。
借助这样的东西,我们可以将用户限制在团队的特定产品命名空间中,以便在其Pod上指示任何令人讨厌的事物。 但是不幸的是,即使您告诉用户不可能通过一个以上的CPU请求来运行Pod,还是有一个非常棒的scale命令,或者可以通过仪表板进行缩放。
第二种方法来自这里。 我们启动了11 111 111 111 111炉膛。 那是110亿。 这不是因为我想出了这样一个数字,而是因为我自己看到了它。
真实的故事。 傍晚,我正要离开办公室。 我看,一群开发人员正坐在角落里,疯狂地做笔记本电脑。 我上去问这些人:“你怎么了?”
早一点,晚上九点,一个开发人员要回家了。 然后他决定:“我现在将跳过最多一个应用程序。” 我点击了一下,互联网有点沉闷。 他再次单击该单元,然后单击该单元,然后单击Enter。 竭尽所能。 然后,互联网开始活跃起来-一切都开始扩展到这个日期。
没错,这个故事并不是在Kubernetes上发生的,当时是Nomad。 最后一个事实是,在我们试图阻止Nomad顽固地坚持在一起的一个小时之后,Nomad回答说他不会停止粘合并且不会做任何其他事情。 “我累了,我要走了。” curl缩起来。
我自然尝试在Kubernetes上做同样的事情。 他说,对110亿个Kubernetes吊舱不满意,他说:“我不能。 超过内部护齿器。” 但是1,000,000,000炉膛可以。
为了响应十亿,多维数据集没有进入内部。 他真的开始扩大规模。 过程越深入,他创建新壁炉所需的时间就越多。 但是过程仍在继续。 唯一的问题是,如果我可以在命名空间中无限期地运行Pod,那么即使没有请求和限制,我也可以通过执行某些任务来启动如此多的Pod,以至于这些任务,节点将开始从内存,CPU中累加。 当我运行这么多炉膛时,来自它们的信息应该转到存储库中,即etcd。 当有太多信息到达那里时,仓库开始放出的速度太慢-在Kubernetes上,沉闷的事情开始了。
还有一个问题……如您所知,Kubernetes的控制元素不仅是一件重要的事情,而且是几个组件。 特别是那里有一个控制器管理器,调度程序等。 所有这些家伙将同时开始进行不必要的愚蠢工作,随着时间的流逝,这将花费越来越多的时间。 控制器管理员将创建新的吊舱。 调度程序将尝试为他们找到一个新节点。 群集中的新节点很可能很快会结束。 Kubernetes集群将开始越来越缓慢地工作。
但是我决定走的更远。 如您所知,在Kubernetes中有一种称为服务的东西。 好吧,默认情况下,在您的群集中,该服务很可能使用IP表工作。
例如,如果您运行十亿个壁炉,然后使用脚本强制Kubernetis创建新服务:
for i in {1..1111111}; do kubectl expose deployment test --port 80 \ --overrides="{\"apiVersion\": \"v1\", \"metadata\": {\"name\": \"nginx$i\"}}"; done
在群集的所有节点上,大约同时会生成大约新的iptables规则。 而且,对于每个服务,将生成十亿个iptables规则。
我检查了整件事,几千到十二个。 问题是,已经在节点上达到此阈值ssh时就存在很大问题。 因为经过这么多链条的数据包开始感觉不太好。
所有这些还可以借助Kubernetes解决。 有这样的资源配额对象。 设置集群中名称空间的可用资源和对象的数量。 我们可以在Kubernetes集群的每个命名空间中创建一个yaml对象。 使用这个对象,我们可以说已经为该名称空间分配了一定数量的请求和限制,然后我们可以说在该名称空间中可以创建10个服务和10个pod。 一个开发人员至少可以在晚上挤。 Kubernetes将对他说:“您不能将Pod设置得如此之高,因为它超出了资源配额。” 一切,问题都解决了。 文档在这里 。
与此相关的一个问题点出现了。 您会感到在Kubernetes中创建名称空间变得多么困难。 要创建它,我们需要考虑很多事情。
资源配额+限制范围+ RBAC
•创建名称空间
•创建内部极限范围
•创建内部资源配额
•为CI创建服务帐户
•为CI和用户创建角色绑定
•(可选)运行必要的服务舱
因此,我想借此机会分享我的发展。 有这样的事情,称为SDK运算符。 这是Kubernetes集群中为其编写运算符的一种方式。 您可以使用Ansible编写语句。
首先,它是用Ansible编写的,然后我发现有一个SDK运算符,并重写了该运算符中的Ansible角色。 该运算符使您可以在Kubernetes集群中创建一个称为团队的对象。 yaml . , - .
.
. ?
. Pod Security Policy — . , , - .
Network Policy — - . , .
LimitRange/ResourceQuota — . , , . , .
, , , . .
. , warlocks , .
, , . , ResourceQuota, Pod Security Policy . .
.