我似乎习惯于编写
功能强大的机器 ,其中许多
机器由于不正确的锁定而
处于空闲状态 。 所以...是的 再说一次。
这个故事特别令人印象深刻。 实际上,在七个命令的周期中,您多久一次将一个线程旋转7秒,并持有一个锁来停止其他63个处理器的工作? 从某种程度上讲,这真是太神奇了。
与普遍的看法相反,我实际上没有一台具有64个逻辑处理器的机器,而且我从未见过这个特殊问题。 但是我的朋友遇到了
这个书呆子 ,
这个书呆子吸引了我,他寻求帮助,我认为这个问题很有趣。 他发送了带有足够信息的
ETW跟踪 ,以便Twitter上的集体意识迅速解决了该问题。
朋友的投诉很简单:他使用
忍者收集了建物。 通常,忍者在增加负载方面做得很出色,不断地支持n + 2进程以避免停机。 但是在这里,程序集的前17秒中的CPU使用情况如下所示:

如果仔细看一下(一个玩笑),您会看到一条细线,总CPU负载在几秒钟内从100%下降到0%。 在短短的半秒内,负载从64个线程减少到两个或三个线程。 这是这些瀑布之一的放大片段-沿水平轴标记了几秒钟:
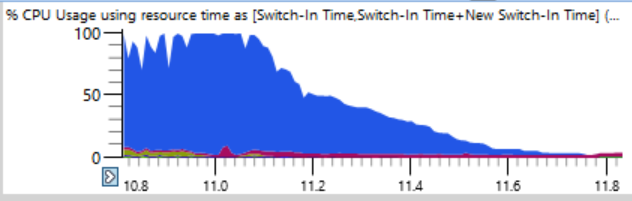
第一个想法是忍者无法快速创建流程。 我见过很多次,通常是由于防病毒软件的干预。 但是,当我按结束时间对图表进行排序时,我发现在此类崩溃期间没有完成任何流程,因此忍者不应该受到指责。
CPU使用率(精确度)表是确定停机原因的理想选择。 所有上下文切换的日志都存储在此处,包括流的每个开始的准确记录,包括位置和超时。
诀窍是停机时间没有错。 当我们确实希望线程完成工作,但实际上它是空闲的时,就会出现问题。 因此,您需要选择某些停机时间。
分析时,重要的是要了解在线程恢复操作时会发生上下文切换。 如果我们查看处理器负载开始下降的那些地方,我们将什么也找不到。 相反,请专注于系统何时再次开始工作。 跟踪阶段甚至更加引人注目。 虽然CPU负载下降需要半秒,但从一个使用的线程到满负载的反向过程仅需要12毫秒! 下图放大了很多,但从空闲到负载的过渡几乎是一条垂直线:

我放大到12毫秒,发现500个上下文切换,这里需要仔细分析。
上下文切换表有许多列,我已
在此处进行了
记录 。 当进程冻结时,为了找到原因,我按新进程,新线程,新线程堆栈等进行分组(
在此处讨论 ),但这不适用于数百个已停止的进程。 如果我研究了任何一个错误的过程,很明显它是由前一个过程准备的,而前一个过程是由前一个过程准备的,那么我将扫描一条长链以找到第一个链接(大概)具有很长一段时间的重要锁。
因此,我在程序中尝试了不同的列布局:
- 接通时间 (发生上下文切换时)
- 准备过程 (谁在等待之后释放了锁)
- 新流程 (开始工作的人)
- 自上次以来的时间 (新流程等待了多长时间)
这给出了上下文切换的时间顺序列表,并记录了谁准备了谁以及准备工作了多长时间。
事实证明,这就足够了。 如果您知道如何阅读下面的表格,这说明了一切。 最初的几个上下文切换并不重要,因为新进程的等待时间(自上次以来的时间)非常短,但是在突出显示的行(第4行)上,有趣的事情开始了:
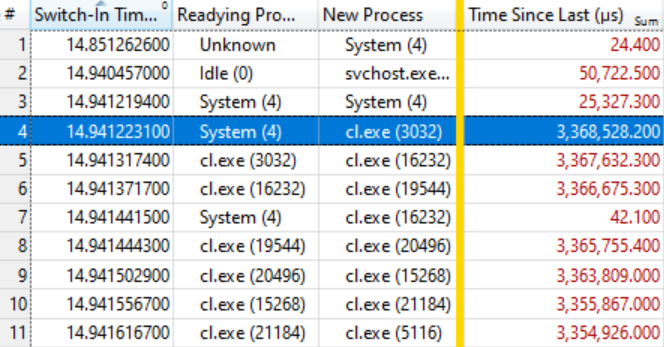
该行显示
System(4)准备了
cl。Exe(3032) ,等待了3.368秒。 下一行说,在不到0.1 ms的时间内,
cl。Exe (3032)准备了
cl.exe(16232) ,它等待了3.367秒。 依此类推。
在第7行中没有几个上下文切换,它不包含在等待链中,只是简单地反映了系统中的其他工作,但总的来说,该链被扩展到数十个元素。
这意味着所有这些进程都在等待释放相同的锁。 当
系统(4)进程释放锁定时(按住3368秒!),等待的进程依次捕获它,做些小工作并传递该锁定。 等待队列大约有一百个进程,显示单个锁的影响程度。
对
Ready Thread Stacks进行的一项小型研究表明,大多数期望来自
KernelBase.dllWriteFile 。 我要求WPA通过分组显示此函数的调用方。 在那里,您可以看到在这种导通的12毫秒中,有174个线程退出
WriteFile等待状态,平均等待了1,184秒:
 174个线程在等待WriteFile,平均等待时间1,184秒
174个线程在等待WriteFile,平均等待时间1,184秒这是一个令人惊讶的滞后,实际上甚至不是问题的整个范围,因为其他功能(例如
KernelBase.dll!GetQueuedCompletionStatus)中的许多线程都期望释放相同的锁。
系统做什么(4)
在这一点上,我知道构建进度已停止,因为所有的编译器进程和其他进程都期望使用
WriteFile ,因为
System(4)持有该锁。 另一个“
就绪线程ID”列显示线程3276在系统进程中释放了锁。
在程序集的所有“挂起”期间,线程3276被100%加载,因此很明显,它在按住锁的同时对CPU做了一些工作。 为了找出在哪里花费了CPU时间,让我们看一下线程3276的CPU使用
情况(采样)图 。CPU使用情况数据非常清楚。 几乎所有时间都使用一个函数
ntoskrnl.exe!RtlFindNextForwardRunClear (样本数量在带有数字的列中表示):
 调用堆栈会导致ntoskrnl.exe!RtlFindNextForwardRunClear
调用堆栈会导致ntoskrnl.exe!RtlFindNextForwardRunClear查看线程堆栈
Readying Thread Id确认
NtfsCheckpointVolume在3.368 s后释放了锁:
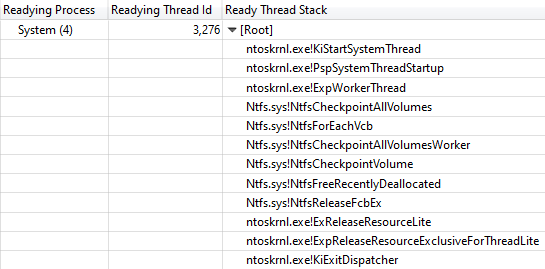 从NtfsCheckpointVolume到ExReleaseResourceLite的调用堆栈
从NtfsCheckpointVolume到ExReleaseResourceLite的调用堆栈此时,在我看来,是时候在Twitter上使用我的关注者的丰富知识了,所以我发布了
此问题并显示了完整的调用堆栈。 如果您提供足够的信息,带有此类问题的推文可能会非常有效。
在这种情况下,
凯特琳·加德 (
Caitlin Gadd)的
正确答案以及许多其他很棒的建议很快就出现了。 她关闭了系统恢复功能-突然构建速度提高了两到三倍!
但是等等,进一步更好
在整个系统中阻止执行3秒以上的时间非常令人印象深刻,但是如果将“
地址”列添加到“
CPU使用率(已采样)”表中并对其进行排序,则情况会更加令人印象深刻。 它显示了在
RtlFindNextForwardRunClear样本中确切获得的位置-其中99%落在一条指令上!

我带了
ntoskrnl.exe和
ntkrnlmp.pdb文件 (与我的朋友使用的版本相同),然后运行
dumpbin /disasm以查看汇编器中感兴趣的功能。 地址的前几位不同,因为代码在引导时移动,但是后四个十六进制值相同(在ASLR之后它们不变):
RtlFindNextForwardRunClear:
...
14006464F:4C 3B C3 cmp r8,rbx
140064652:73 0F jae 0000000140064663
140064654:41 39 28 cmp dword ptr [r8],ebp
140064657:75 0A jne 0000000140064663
140064659:49 83 C0 04添加R8.4
14006465D:41 83 C1 20添加r9d,20h
140064661:EB EC检举000000014006464F
...
我们看到关于... 4657的指令包含在七个指令的循环中,这些指令可在其他示例中找到。 此类样本的数量在右侧显示:
RtlFindNextForwardRunClear:
...
14006464F:4C 3B C3 cmp r8,rbx 4
140064652:73 0F jae 0000000140064663 41
140064654:41 39 28 cmp dword ptr [r8],ebp
140064657:75 0A jne 0000000140064663 7498
140064659:49 83 C0 04添加r8.4 2
14006465D:41 83 C1 20加r9d,20h 1
140064661:EB EC编号000000014006464F 1
...
作为读者的练习,让我们在超标量处理器上对样本数量的解释不加说明地执行,尽管可以在
本文中找到一些好主意。 在这种情况下,我们有32核AMD Ryzen Threadripper 2990WX。 显然,Micro-Up Fusion的处理器功能一次执行5条指令,实际上允许每个周期在jne上完成,因为最昂贵的指令之后的指令会陷入选择的大部分中断中。
因此,事实证明,具有64个逻辑处理器的计算机在系统进程中以七个命令的周期停止,同时持有重要的NTFS锁,该锁通过禁用系统恢复来修复。
尾田
尚不清楚为什么此代码在此特定计算机上表现不佳。 我想这与某种程度上在几乎空的2 TB磁盘上的数据分配有关。 重新启动系统恢复后,问题也再次出现,但并不是那么严重。 对于具有巨大空白空间的磁盘,也许存在某种病理?
Twitter上的另一个追随者提到Windows 7中的卷影复制错误,该错误允许
在O(n ^ 2)期间执行 。 据称此错误已在Windows 8中修复,但可能已以某种形式保留。 我的堆栈跟踪清楚地表明,
VspUpperFindNextForwardRunClearLimited (在这16兆字节的区域中查找已使用的位)调用
VspUpperFindNextForwardRunClear (在任何地方查找下一个已使用的位,但是如果它不在指定区域内则不返回)。 当然,这会引起某种似曾相识的感觉。 正如我
最近所说的 ,O(n ^ 2)是可伸缩性差的算法的弱点。 这里有两个因素同时存在:这样的代码足够快就可以投入生产,而足够慢就可以停止生产。
有报告说,
大量删除文件时也会发生类似的问题,但是我们的跟踪记录并未显示很多删除,因此,问题显然不在于此。
总之,我将从文章的开头重复整个系统的CPU负载计划,但这一次表明有问题的
System进程使用了CPU(下面的绿色)。 在这样的情况下,问题是完全显而易见的。 系统过程在技术上在最上面的图表中可见,但是按此比例,很容易错过。
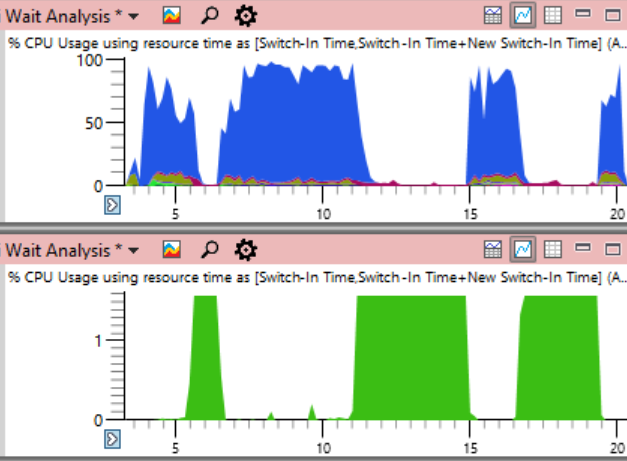
尽管该问题在图表上清晰可见,但实际上并没有证明。
正如他们所说 ,相关性不是因果关系。 只有对上下文切换事件的分析显示,正是这种流持有了关键的锁-然后您可以确保我们找到了实际的原因,而不仅仅是随机的相关性。
咨询处
像往常一样,在结束本调查时,我
呼吁更好地命名线程 。 系统进程具有数十个线程,其中许多线程具有特殊用途,并且没有一个名称。 此跟踪中最繁忙的系统线程是
MiZeroPageThread 。 我反复跳入它的堆栈,每次我回想起来都不感兴趣。 VC ++编译器也未命名其线程。 重命名流并不需要花费很多时间,这确实很有用。 只要说出名字。
很简单 。 Chromium甚至包括一个用于
在流程中列出流名称的工具。
如果Microsoft NTFS团队的某人想谈论这个话题,请告诉我,我可以将您与原始报告的作者联系起来,并提供ETW跟踪。
参考文献