
哈Ha! 我们将继续从#article_essense频道发布来自开放数据科学社区成员的科学文章的评论。 如果您想在其他所有人之前得到他们-请加入社区 !
今天的文章:
- 层旋转:深度网络中泛化的出奇的强大指标吗? (比利时卢旺德天主教大学,2018年)
- 适用于NLP的参数有效转移学习(Google研究,Jagiellonian University,2019)
- RoBERTa:鲁棒优化的BERT预训练方法(华盛顿大学,Facebook AI,2019)
- EfficientNet:对卷积神经网络的模型缩放的重新思考(Google Research,2019)
- 大脑如何从意识转变为潜意识(美国,阿根廷,西班牙,2019年)
- 具有产品密钥的大内存层(Facebook AI Research,2019)
- 我们真的取得了很大进步吗? 对最近的神经推荐方法的担忧分析(米兰理工大学,克拉根福大学,2019年)
- 用于人员重新识别的全方位特征学习(萨里大学,玛丽皇后大学,三星AI),2019年
- 神经重新参数化可改善结构优化(Google Research,2019)
1.层轮换:深度网络中泛化的令人惊讶的强大指标吗?
作者:西蒙·卡伯内尔(Simon Carbonnelle),克里斯托弗·德·弗里舒沃(Christophe De Vleeschouwer)(比利时卢旺德天主教大学,2018年)
→原创文章
评论作者:Svyatoslav Skoblov(松弛error_derivative)

在本文中,作者提请注意一个相当简单的观察结果:初始化期间和训练后各层权重之间的余弦距离(训练期间增加距离的过程称为“层旋转”)。 先生们,在大多数实验中,在所有层中达到1距离的网络在精度上始终优于其他配置。 本文还提出了Layca算法(权重旋转的层级控制量),该算法允许使用此分层学习速率来控制同一层旋转。 实际上,它与通常的SGD算法不同之处在于存在正交投影和归一化。 可以在本文中找到该算法的详细列表以及训练方案。
作者得出的主要思想是: 图层旋转越大,泛化性能越好 。 本文的大部分内容是记录各种实验场景的实验记录:MNIST,CIFAR-10 / CIFAR-100,使用了从单层网络到ResNet系列的具有不同体系结构的小型ImageNet。
一系列实验分为几个阶段:
- Vanilla SGD事实证明,总的来说,刻度的行为与假设一致(距离的较大变化对应于最佳度量值),但是,也注意到了一些问题:层旋转早于所需值就停止了; 还注意到距离变化的不稳定性。
- SGD +重量衰减减少重量范数极大地改善了训练效果:大多数图层达到最大距离,并且测试性能与拟议的Layca相似。 作者方法的优点无疑是缺少附加的超参数。
- LR预热事实证明,预热可以帮助SGD克服不稳定的图层旋转问题,但是对Layca没有影响。
- 自适应梯度方法除了众所周知的事实(使用这些方法很难达到SGD +权重衰减所能提供的一般化水平)之外,还发现层旋转的效果非常不同:第一个层在最后一层增加旋转,而SGD在初始层增加。 作者暗示这可能是自适应方法的意思。 他们建议与Layca一起使用(提高自适应方法中的归纳能力并加速SGD中的学习)。
本文最后试图解释这种现象。 为此,作者在MNIST的精简版上训练了一个具有1个隐藏层的网络,之后他们可视化了随机神经元,得出了一个非常合乎逻辑的结论:层旋转度越大,初始化效果越好,对特征的研究越好,这有助于改善泛化能力。
上载已实现算法的代码(tf / keras)和用于再现实验的代码。
2. NLP的参数有效传递学习
文章作者:尼尔·霍尔斯比(Neil Houlsby),安德烈·朱古(Andrei Giurgiu),斯坦尼斯瓦夫·贾斯特热斯基(Stanislaw Jastrzebski),布鲁娜·莫罗内(Bruna Morrone),昆汀·德·拉卢西尔(Quentin de Laroussilhe),安德里亚·格斯蒙多(Andrea Gesmundo),蒙娜·阿塔里扬(Mona Attariyan),席尔文·盖利(Sylvain Gelly)(谷歌研究,雅盖隆大学,2019年)
→原创文章
评论作者:阿列克谢·卡纳切夫(Alexey Karnachev)
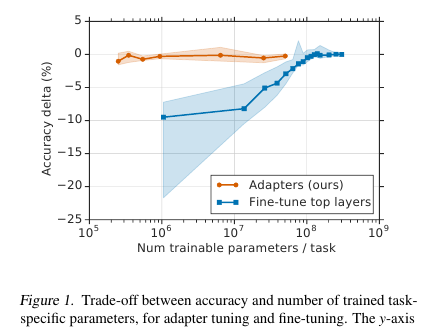
在此,先生们为NLP模型(在本例中为BERT)提供了一种简单但有效的微调技术。 这个想法是将学习层(适配器)直接嵌入到网络中。 每个这样的层都是一个具有瓶颈的网络,该网络使原始模型的潜在状态适应特定的下游任务。 反过来,原始模型的权重保持冻结。
动机
在流训练(或近在线训练)的条件下,有很多下游任务,我真的不想归档整个模型。 首先,很长一段时间,其次,这很困难,其次,即使很紧,也需要以某种方式存储模型:转储或保留在内存中。 而且,我们将无法为以下任务重用此模型:每次我们必须以新方式进行调整时。 结果,我们可以尝试使隐藏的网络状态适应当前的问题。 此外,原始模型保持不变,并且适配器本身比主模型大得多(约占参数总数的4%)
实作
这个问题的解决方法非常简单:我们在模型的每一层都添加了2个适配器。 在基于变压器的模型中进行层归一化之前,会发生跳过连接:将转换后的输入(当前隐藏状态)添加到原始输入中。
每个变压器层中有2个这样的部分,一个在多头注意之后,第二个在前馈之后。 因此,这些部分的隐藏状态还会通过适配器传递:具有1瓶颈隐藏层并且输出与输入尺寸相同的浅层网络。 将非线性应用于瓶颈状态,并将输入(跳过连接)添加至输出。 事实证明,训练后的参数总数为:2md + m + d,其中d是原始模型的隐藏状态的维,m是瓶颈适配器层的大小。 事实证明,对于基于BERT的模型(12层,110M参数)和适配器bottlneck'a 128的大小,我们获得了参数总数的4.3%
结果
通过完整模型调整进行了比较。 对于所有任务,此方法显示出度量指标的轻微损失(平均不到1分),训练后的权重数量占总数的3%。 我不会列出任务本身,其中有很多,本文中有一个平板电脑。
微调
在此模型中,仅调整适配器部分(+输出分类器本身)。 对于适配器规模,他们建议进行近身份初始化。 因此,未经训练的模型将不会以任何方式更改隐藏的网络状态,这将使得在训练模型的过程中可以决定哪些状态适合任务,哪些保持不变。
建议学习率比标准BERT微调更多。 就我个人而言,在1e-04 lr上运行良好。 另外,(在我个人的观察中)在调整过程中,模型几乎总是爆炸梯度,因此您需要记住进行剪裁。 优化器-Adam预热10%
代号
随附文章中的代码。 Tensorflow的实现 。
对于Torch,该评论的作者分叉了pytorch-transformers,并添加了一个Adapter层 (在README.md文件的开头有一个小的启动手册)
3. RoBERTa:经过严格优化的BERT预训练方法
文章作者:刘因韩,迈尔·奥特,纳曼·戈亚尔,杜静飞,曼达·乔希,陈丹琪,奥默·利维,迈克·刘易斯,卢克·泽特尔默耶,维斯林·斯托亚诺夫(华盛顿大学,Facebook AI,2019)
→原创文章
评论作者:Artem Rodichev(在闲逛的fuckai中)
极大地提高了BERT模型的质量,在许多NLP任务上均居GLUE排行榜和SOTA榜首。 他们提出了许多方法来尽可能地训练BERT模型,而无需对模型体系结构本身进行任何更改。
与原始BERT的主要区别:
- 火车建设时间增加了10倍,从原始文本16 GB增加到160 GB
- 对每个样本进行动态遮罩
- 删除了使用下一句预测损失
- 微型批次的大小从256个样本增加到8k
- 通过将数据库从Unicode转换为字节,改进了BPE编码。
最佳最终模型在1024个Nvidia V100卡(128个DGX-1服务器)上进行了5天的培训。
该方法的本质:
资料。 除了用于教授原始BERT的Wiki shell和BookCorpus(总共16GB)之外,他们还添加了3个更大的shell,全部使用英语:
- 2.5年来,SS-News在76GB容量上有6300万条新闻
- OpenWebText是向其教授GPT2模型的OpenAI框架。 这些是经过爬网的文章,在reddit上的帖子中提供了指向链接的链接,并至少进行了三个更新。 38GB数据
- 故事-31GB CommonCrawl故事案例
动态遮罩。 在原始BERT中,每个样本中有15%的令牌被屏蔽,并且使用序列的未屏蔽部分预测这些令牌。 在预处理期间会为每个样本生成一次模板,并且不会更改。 同时,火车中的同一样本可能会发生几次,具体取决于体内的时代数。 动态屏蔽的想法是每次为序列创建一个新的屏蔽,而不是在预处理中使用固定的屏蔽。
下一个句子预测目标。 让我们削减这个目标,看看它是否变得更糟? 在SQuAD,MNLI,SST和RACE任务上,它变得更好还是仍然存在。
增加小批量的大小。 在许多地方,特别是在机器翻译中,结果表明,迷你批量越大,火车的最终效果就越好。 他们表明,如果像原始BERT中那样,将最小批次从256个样本增加到2k,然后又增加到8k,则验证的复杂性下降,MNLI和SST-2的度量标准也会增加。
BPE 原始BERT实现中的BPE使用Unicode字符作为子单词单元的基础。 这导致了这样一个事实,在各种情况下,字典的很大一部分将被单个Unicode字符占用。 GPT2中的OpenAI建议不要使用Unicode字符,而应使用字节作为子词的基础。 如果我们使用50k BPE词典,那么我们将不会有未知的令牌。 与原始BERT相比,基本模型的模型大小增加了1500万,对于大型模型,模型增加了20M,即增加了5-10%。
结果:
BERT-large和XLNet-large用作比较模型。 RoBERTa本身的参数与BERT-large相同,因此,它们在GLUE基准测试中获得了第一名。 我们使用单任务文件调整,这与GLUE基准测试中的许多其他方法进行多任务文件调整不同。 在GLUE中的女孩上,比较了单个模型的结果,他们在所有9个任务上都获得了SOTA。 在测试集上,比较了模型的集合,9个任务中的4个的SOTA和最终胶合速度。 在SOTA开发人员网络上的两个SQuAD版本上,在XLNet级别的测试集上。 此外,与XLNet不同,在解决SQuAD之前,他们不会被其他质量检查包所吸引。

SOTA on RACE任务,其中给出了一段文本,一个关于该文本的问题以及4个答案选项,您需要在其中选择正确的答案。 为了解决此任务,他们将文本,问题和答案连接起来,通过BERT运行,从CLF令牌中获取表示形式,应用于一个完全连接的层并预测答案是否正确。 对于每个答案选项,此操作完成4次。
我们在fairseq萝卜中发布了RoBERTa模型的代码和预训练 。 您可以使用它,一切看起来都很简洁。
4. EfficientNet:卷积神经网络的模型缩放比例的重新思考
作者:Tan Mingxing,Quoc V.Le(Google Research,2019)
→原创文章
评论作者:Alexander Denisenko(处于闲置状态的Alexander Denisenko)

他们研究了模型的缩放(缩放),以及它们在网络的深度和宽度(通道数)之间的平衡,以及网格中图像的分辨率。 他们提供了一种新的缩放方法,可以统一缩放深度/宽度/分辨率。 在MobileNet和ResNet上显示其有效性。
他们还使用神经体系结构搜索来创建新的网格并对其进行缩放,从而获得一类新模型-EfficientNets。 它们比以前的网格更好,更经济。 在ImageNet上,EfficientNet-B7达到了最先进的84.4%top-1和97.1%top-5精度,与目前同类最佳的ConvNet相比,推理效率低8.4倍,快6.1倍。 它可以很好地转移到其他数据集-他们在8个最受欢迎的数据集中的5个中获得了SOTA。
复合模型缩放
缩放是指在网格内部执行的操作固定且仅更改深度(相同模块的重复次数)d,宽度(卷积通道数)w和分辨率r时。 在寻呼机中,缩放被公式化为一个优化问题-尽管我们不从内存和FLOPS中爬出来,但我们仍希望获得最大的准确度(Net(d,w,r))。
我们进行了实验,并确保在宽度缩放时也确实有助于深度缩放和分辨率。 使用相同的FLOPS,我们在ImageNet上获得了明显更好的结果(请参见上图)。 通常,这是合理的,因为似乎随着网络图像分辨率的提高,深度上需要更多的层来增加接收场和更多的通道,以便以更高的分辨率捕获图像中的所有模式。
复合缩放的本质:我们采用复合系数phi,该系数用该系数均匀缩放d,w和r: 在哪里 -从源网格的小网格视图获得的常数。 -表征可用计算资源量的系数。
高效网
为了创建网格,我们使用了多目标神经体系结构搜索,优化的Accuracy和FLOPS,并在参数之间做出了权衡。 这样的搜索得到了EfficientNet-B0。 简而言之-Conv,紧随其后的是几个MBConv,位于Conv1x1,Pool,FC的末尾。
然后分两步进行缩放:
- 首先,我们修复 ,做网格搜索进行搜索 。
- 使用d,w和r的公式缩放网格。 获得了EffiientNet-B1。 同样,增加 ,获取EfficientNet-B2,... B7。
针对不同的ResNet和MobileNet进行缩放,到处都对ImageNet进行了重大改进,与仅在一个维度上进行缩放相比,复合缩放带来了显着增长。 我们还在EfficientNet上对另外八个流行的数据集进行了实验,无论我们到哪里获得SOTA或参数数量少得多的接近它的结果。
代号
5.大脑如何从意识转变为潜意识
文章作者:弗朗西斯卡·阿里斯·卢西尼(Francesca Arese Lucini),吉诺·德尔·费拉罗(Gino Del Ferraro),马里亚诺·西格姆(Mariano Sigman),埃尔南·马克斯(Hernan A.Makse)(美国,阿根廷,西班牙,2019年)
→原创文章
评论作者:Svyatoslav Skoblov(松弛error_derivative)
本文是Dehaene,S,Naccache,L,Cohen,L,Le Bihan,D,Mangin,JF,Poline,JB和Rivie`re D的工作的延续和反思。单词掩盖和无意识重复启动的脑机制作者试图考虑有意识和无意识大脑功能的模式。
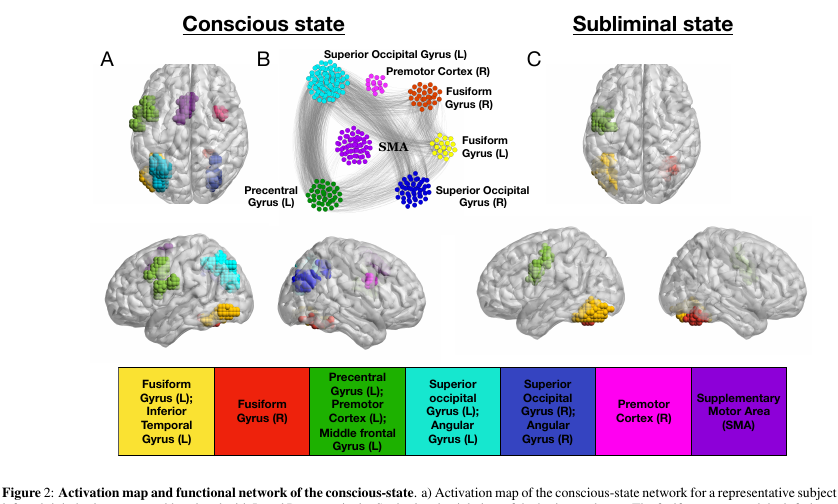
实验:
志愿者会看到图片(4个字母的单词,或空白屏幕或涂鸦)。 它们每个显示30毫秒,通常整个动作持续5分钟。
- 在实验的“有意识”模式下,空白屏幕与单词交替显示,使人们可以有意识地感知文本。
- 在“无意识”模式下,单词与涂鸦交替出现,这在有意识的水平上非常有效地干扰了文本的感知。
资料:
在此演示中,使用fMRI扫描了灵长类动物的大脑。 研究人员总共有15名志愿者,每人重复了5次实验,总共有75条fMRI流。 值得注意的是,体素扫描结果非常大(非常简化:体素是一个包含大量单元的3D立方体)-4x4x4mm。
魔术:
让我们从流中将节点称为活动体素。 由于大脑是一块模块化的毛巾,因此我们在其中引入了两种类型的连接:外部连接和内部连接(对应于节点的空间排列)。 连接以一种有趣的方式进行组装:我们在节点之间建立互相关矩阵,如果相关性大于某个自适应参数lambda,则将节点与连接相连接。 此参数影响网络的放电。
使用“过滤”过程进行参数调整。 如果我们稍微摇摆一下λ,则网络的最终尺寸之间的急剧过渡会变得很明显(即,参数更改足够小就意味着大小的增大)。
因此:内部连接由lambda-1值激活,该值对应于急剧过渡之前的lambda值。 外部-急剧过渡后立即与lambda值相对应的lambda-2值。
魔法2:
k核过滤。 k核心概念描述了网络连通性,并用非常简单的方式表述:最大子网,所有子网的所有节点都至少有k个邻居。 可以通过迭代删除少于k个邻居的节点来获得这样的子网。 由于其余节点将失去邻居,因此该过程将继续进行,直到没有要删除的内容为止。 剩下的就是k-core网络。
结果:
将这种火炮应用于我们的大脑,您会看到许多非常有趣的功能。
- k小/非常大的k核中的节点数非常大。 但是,相反,对于中等k,这是不够的。 在图片中,它看起来像一个U形,也就是说,这样的网络配置提供了系统的最大稳定性(抵抗局部和全局错误)。
- 几乎可以在网络的任何状态下看到属于k核且k较小的最重要节点。 但是,只有在无意识状态梭状回和左中前回活跃的大脑部分才具有k大的k核。 皮质的相同部分最活跃,处于意识状态。
为了检查结果,作者在真实节点的基础上创建了一百万个随机网络,进行随机重新布线,同时保持节点的原始度(与图中顶点的度相同)。 实际网络与随机网络的区别在于最大值k更大。 同时,在随机网络中,簇中节点数量的U形仍然很明显,这促使作者想到了节点的程度是造成这种现象的原因。
结论:
, , , . , , , - ( , , , ).
, , , , , , , - . , , qualia.
6. Large Memory Layers with Product Keys
: Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou (Facebook AI Research, 2019)
→
: ( belerafon)

, key-value , .
- attention. q, k v. q, k, , value . , . , . , , . - q (, -10). . .
— q k . , "Product Keys". , q , . -10 , , O(N) "" , (sqrt(N)).
key-value . , ( , ). , BERT 28 . , , . : 12- 2 , 24- , perplexity .
( self-attention). , - . , multy-head attention. 即 query , value, . -.
, , , , BERT . .
7. Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
: Maurizio Ferrari Dacrema, Paolo Cremonesi, Dietmar Jannach (Politecnico di Milano, University of Klagenfurt, 2019)
→
: ( netcitizen)

DL , , .
DL top-n. DL KDD, SIGIR, TheWebConf (WWW) RecSys :
- -
- 7/18 (39%)
- “” train/test, ., , , .
- (Variational Autoencoders for Collaborative Filtering (Mult-VAE) ± ) KNN, SVD, PR.
DL, CV, NLP , .
8. Omni-Scale Feature Learning for Person Re-Identification
: Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang (University of Surrey, Queen Mary University, Samsung AI, 2019)
→
: ( graviton)
Person Re-Identification, Face Recognition, , . (Kaiyang Zhou) deep-person-reid , (OSNet), Person Re-Identification. .
Person Re-Identification:

:
- conv1x1 deepwise conv3x3 conv3x3 (figure 3).
- , . ResNeXt , Inception (figure 4).
- “aggregation gate” . , Inception .

OSNet , .. , : ( , ) .
ReID OSNet ( 2 ) (Market: R1 93.6%, mAP 81.0% OSNet R1 87.0%, mAP 69.5% MobileNetV2) ResNet DenseNet (Market: R1 94.8%, mAP 84.9% OSNet R1 94.8%, mAP 86.0% ResNet).
另一个挑战是领域适应 :在一个数据集上训练的模型在另一个数据集上的质量较差。 在不使用“无监督域自适应”(使用未分配形式的测试数据来使数据分布均匀)的情况下,OSNet在此细分市场中也显示出良好的结果。
该体系结构还已经在ImageNet上进行了测试,该体系结构使用MobileNetV2达到了类似的精度,参数更少,但操作更多。
9.神经参数调整可改善结构优化
作者:Stephan Hoyer,Jascha Sohl-Dickstein,Sam Greydanus(Google研究,2019年)
→原创文章
评论作者: Alexey (在Arech站着)
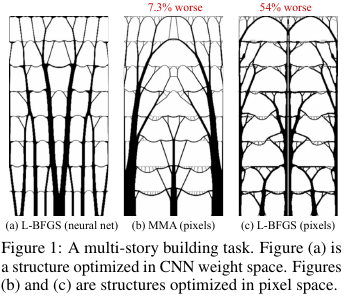
在建筑和其他技术中,存在优化某些解决方案的结构/拓扑的任务。 粗略地说,这是计算机对问题的答案,例如,如何设计飞机的桥梁/建筑物/机翼/涡轮叶片/ blablabla,以便满足某些限制并且结构足够坚固。 有一套“标准”的解决方法-可以工作,但那里的一切并不总是那么顺利。
这些来自Google的家伙想出了什么? 他们说:让我们先通过神经网络(UNet的上采样部分)生成一个解决方案,然后使用可微分的物理模型,该模型将计算在所有力和重力的影响下解决方案的行为,计算目标函数-强度(更确切地说,是其逆函数-依从性) )设计。 然后,由于一切都是自动可微的,我们得到了目标函数的梯度,该梯度通过整个结构推回到权重和神经网络的输入中。 我们改变权重和输入,并继续循环直到收敛到一个稳定的解决方案。
结果证明是在较小的问题上(就可能解决方案的空间而言),可以与传统的拓扑优化方法相提并论;对于较大的问题,它们明显优于传统方法(在99个问题中超重,而在116个问题中有66个问题)。 而且,所得到的解决方案通常比基线的决策具有更高的技术和最优性。
即 实际上,他们将NS用作参数化结构物理模型的棘手方法,这隐含地(由于NS的体系结构)能够对参数值施加一些有用的限制(通过从方法中删除NS并直接优化像素值来控制)。
源代码。
有关habr的本文的更详细概述。