至少自1990年代初以来,自动搜索图像中文本的问题就已经存在很长时间了。 ABBYY FineReader的广泛发行可以使老人们记住它们,后者可以将文档扫描转换为可编辑的版本。
连接到个人计算机的扫描仪在公司中运作良好,但进展并非一帆风顺,移动设备已席卷全球。 处理文本的任务范围也已更改。 现在,您需要查找的文本不是在完全笔直的A4纸上带有白色背景上的黑色文本,而是在各种名片,色彩丰富的菜单,商店标牌上以及在一个人可以在现代城市的丛林中遇见的东西上寻找。
 我们神经网络工作的一个真实例子。 图片是可单击的。
我们神经网络工作的一个真实例子。 图片是可单击的。基本要求和局限性
在呈现文本的条件如此多样的情况下,手写算法已无法应对。 在这里,具有泛化能力的神经网络得以拯救。 在本文中,我们将讨论创建神经网络体系结构的方法,该体系结构可以以高质量和高速度检测复杂图像中的文本。
移动设备对方法的选择施加了其他限制:
- 由于昂贵的漫游流量或隐私问题,用户并非总是有机会使用移动网络与服务器进行通信。 因此,像Google Lens这样的解决方案在这里无济于事。
- 由于我们专注于本地数据处理,因此对于我们的解决方案将非常有用:
- 它占用很少的内存;
- 使用智能手机的技术功能,它可以快速运行。
- 文本可以旋转并位于随机背景上。
- 单词可能很长。 在卷积神经网络中,卷积内核的范围通常不覆盖整个扩展词,因此需要一些技巧来解决此限制。

- 一张照片上的文字大小可能有所不同:

解决方案
想到的最简单的文本搜索解决方案是从专门从事这项任务和业务的
ICDAR (国际文档分析和识别会议)竞赛中获得最佳网络! 不幸的是,此类网络由于其庞大性和计算复杂性而无法实现质量,并且仅适合作为不符合我们要求的第1和第2款的云解决方案。 但是,如果我们采用一个大型网络,该网络在需要覆盖并尝试减少它的情况下工作良好,那该怎么办? 这种方法已经更加有趣了。
Shibaoguang Shi等人在他们的神经网络
SegLink [1]中提出了以下内容:
- 一次查找不完整的单词(图像a中的绿色区域),而是查找其部分(称为分段),并预测其旋转,倾斜和移位。 让我们借用这个想法。
- 您需要一次搜索多个级别的单词段,以满足要求5。这些段在图像b中用绿色矩形显示。
- 为了使人们免于发明如何组合这些片段,我们仅使神经网络预测与同一个单词相关的片段之间的连接(链接)
一个 在相同比例内(图像c中的红线)
b。 在刻度之间(图d中的红线),解决了要求第4条的问题。
下图中的蓝色方块显示了不同比例的神经网络输出层像素的可见性区域,这些区域“看到”了单词的至少一部分。
 段和链接示例
段和链接示例SegLink使用著名的VGG-16架构作为基础。 段和链接的预测是在6个等级上进行的。 作为第一个实验,我们从原始体系结构的实现开始。 事实证明,该网络包含2300万个参数(权重),这些参数需要存储在88兆字节的文件中。 如果您基于VGG创建应用程序,那么如果没有足够的空间,它将是最先删除的应用程序之一,并且文本搜索本身将非常缓慢地工作,因此网络需要紧急减轻重量。
 SegLink网络架构
SegLink网络架构我们饮食的秘密
您可以通过更改网络中的层和通道数或更改卷积本身及其之间的连接来减小网络的大小。 马克·桑德勒(Mark Sandler)及其同事及时采用了他们的
MobileNetV2网络[2]的体系结构,以便它可以在移动设备上快速运行,占用很少的空间,并且在同一个VGG的工作质量上仍然不落后。 加快速度并减少内存消耗的秘诀在于三个主要步骤:
- 在没有激活功能的情况下,通过点卷积减少到整个深度(所谓的瓶颈),可以减少在块入口处具有特征图的通道的数量。
- 经典卷积被每通道可分离卷积代替。 这种卷积需要较少的权重和较少的计算。
- 瓶颈后的字符卡将转发到下一个块的输入以求和,而无需进行其他卷积。
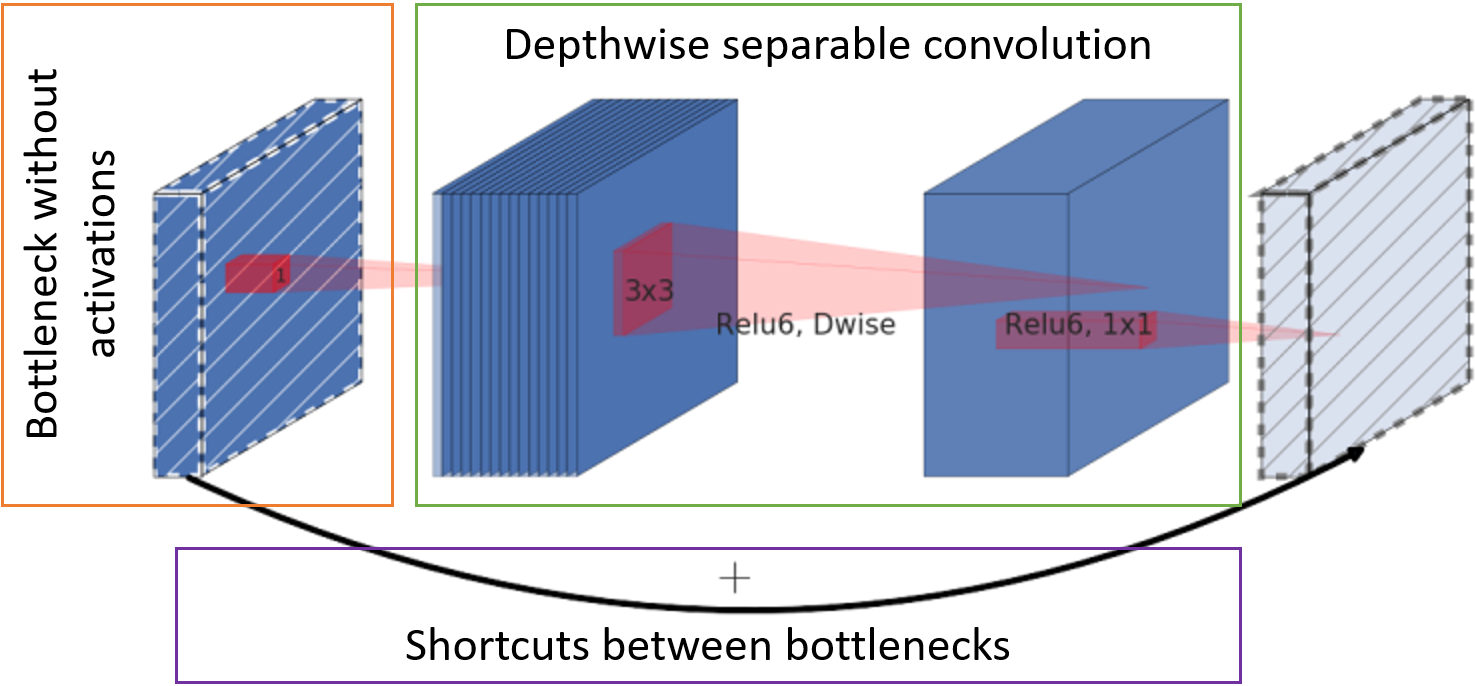 MobileNetV2基本单元
MobileNetV2基本单元
结果神经网络
使用以上方法,我们得出以下网络结构:
- 我们使用来自SegLink的细分和链接
- 用不太贪吃的MobileNetV2代替VGG
- 将文本搜索比例的数量从6减少到5以提高速度
 文字搜索摘要网络
文字搜索摘要网络
网络体系结构块中的值解密
通道的步幅步长和通道的基数分别表示为s <stride> c <channels>。 例如,s2c32表示32个通道,其偏移量为2。卷积层中的实际通道数是通过将其基数乘以缩放因子α获得的,从而可以快速模拟网络的不同“厚度”。 下表是网络中参数数量取决于α的表。

块类型:
- Conv2D-全面的卷积运算;
- D方向转换-每通道可分离卷积;
- 块-一组MobileNetV2块;
- 输出-卷积以获取输出层。 NxN类型的数值表示像素的接收场的大小。
作为激活功能,这些块使用ReLU6。

输出层有31个通道:
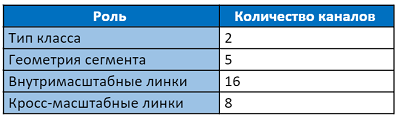
输出层的前两个通道投票使像素属于文本而不是文本。 以下五个通道包含用于准确重建片段几何形状的信息:相对于像素位置的垂直和水平偏移,宽度和高度的因数(因为片段通常不是正方形)以及旋转角度。 通道内链接的16个值指示在相同比例的八个相邻像素之间是否存在连接。 最后的8个频道向我们介绍了到前一个比例尺的四个像素的链接的存在(前一个比例尺始终大2倍)。 段的每2个值,尺度内和尺度间链接都通过softmax函数进行归一化。 进入第一尺度时没有跨尺度链接。
单词汇编
网络会预测特定的片段及其邻居是否属于文本。 仍然需要将它们收集成文字。
首先,组合通过链接链接的所有段。 为此,我们组成了一个图形,其中顶点是所有比例尺上的所有线段,而边是链接。 然后我们找到图的连接组件。 对于每个组件,现在可以如下计算单词的封闭矩形:
- 我们计算单词θ的旋转角度
- 或作为分段的旋转角度预测的平均值(如果有很多)
- 或者,如果线段很少,则作为在线段中心点上通过回归获得的直线的旋转角度。
- 选择单词的中心作为段的中心点的质心。
- 将所有线段扩展-θ以水平排列它们。 找到单词的边界。
- 单词的左边界和右边界分别被选择为最左段和最右段的边界。
- 为了获得单词的上界,将按照上边缘的高度对片段进行排序,将最高片段的20%切除,然后选择列表中过滤后剩余的第一个片段的值。
- 与最高边界类似,从最低边界获得最低边界的下边界,其截止值为最低边界的20%。
- 将生成的矩形返回到θ。
最终的解决方案称为
FaSTExt :快速小文本提取器 [3]
实验时间!
训练细节
选择网络本身及其参数是为了在一个较大的内部样本上进行良好的工作,这反映了在电话上使用该应用程序的主要场景-他将相机对准带有文本的对象并拍摄了照片。 事实证明,具有α= 1的大型网络在质量上会绕过α= 0.5的版本仅2%。 该样本不在公共领域,因此,为清楚起见,我不得不在
ICDAR2013的公共样本上训练网络,该环境的拍摄条件与我们的相似。 该样本非常小,因此该网络之前曾接受过来自
Wild Dataset中SynthText的大量合成数据训练。 对于GTX 1080 Ti,每个实验的预训练过程大约需要20天的计算时间,因此,仅针对选项α= 0.75、1和2来检查公共数据的网络操作。
作为优化程序,使用了Adam的
AMSGrad版本。
错误功能:
- 交叉熵用于细分和链接的分类;
- 段几何的Huber损失函数。
结果
就目标方案中的网络性能质量而言,我们可以说它在质量方面并没有落后于竞争对手,甚至超过了竞争对手。 MS是一个庞大的多规模竞争者网络。
 *在关于EAST的文章中,我们所需的样品没有任何结果,因此我们自己进行了实验。
*在关于EAST的文章中,我们所需的样品没有任何结果,因此我们自己进行了实验。下图显示了FaSTExt如何处理ICDAR2013图像的示例。 第一行显示ESPMOTO单词的发光字母未标记,但网络能够找到它们。 容量较小的版本(α= 0.75)处理较小的文本比较“粗”的版本差。 底线再次显示了样本中的标记缺陷,反射中丢失了文本。 FaSTExt同时看到这样的文本。

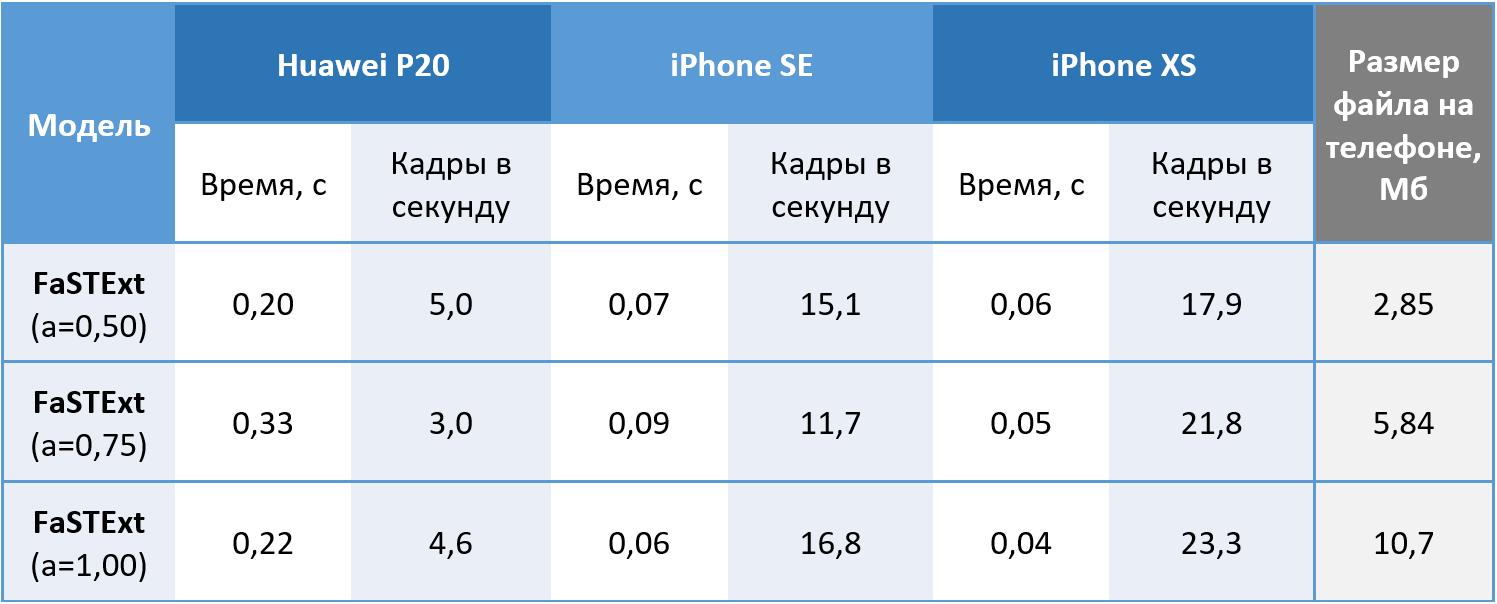
因此,网络执行其任务。 还有待检查它是否可以在手机上实际使用吗? 由于我们的机器学习系统仍仅允许在iOS上使用GPU,因此在使用CPU的Huawei P20以及在使用GPU的iPhone SE和iPhone XS上以512x512彩色图像启动模型。 通过平均100个起始点获得的值。 在Android上,我们设法实现了可接受的每秒5帧的速度。 iPhone XS表现出有趣的效果,减少了计算所需的平均时间,同时使网络复杂化。 现代iPhone可以以最小的延迟检测文本,这可以称为胜利。
参考文献
[1] B. Shi,X。Bai和S. Belongie,“通过链接段检测自然图像中的定向文本”,夏威夷,2017年。
链接[2] M. Sandler,A。Howard,M。Zhu,A。Zhmoginov和L.-C。 Chen,“ MobileNetV2:残差和线性瓶颈”,盐湖城,2018年。
链接[3] A. Filonenko,K。Gudkov,A。Lebedev,N。Orlov和I. Zagaynov,“ FaSTExt:快速和小文本提取器”,在第八届基于照相机的文档分析与识别国际研讨会上,悉尼,2019年
连结[4] Z. Zhang,C。Zhang,W。Shen,C。Yao,W。Liu和X. Bai,“具有完全卷积网络的多方向文本检测”,拉斯维加斯,2016年。
链接[5] X. Zhou,C。Yao,H。Wen,Y。Wang,S。Zhou,W。He和J. Liang,“ EAST:一种高效,准确的场景文本检测器”,在2017年IEEE计算机会议上愿景与模式,火奴鲁鲁,2017年。
链接[6]廖敏,朱中,石乙,G.-s。 Xia和X. Bai,“面向场景文本检测的旋转敏感回归”,在2018 IEEE / CVF计算机视觉和模式会议上,盐湖城,2018年。link
[7] X. Liu,D。Liang,S。Yan,D。Chen,Yiao Qiao和J. Yan,“ Fots:使用统一网络的快速定位文本点”,在2018 IEEE / CVF计算机视觉会议上模式,盐湖城,2018年。
链接计算机视觉小组