哈伯峰会-故事尚未登场。 我们曾经举办300-400人的大型活动Toaster,但现在我们决定召开小型主题会议,您也可以确定其发展方向-例如,在评论中。 这种格式的第一次会议于7月举行,致力于后端开发。 与会者聆听了有关从后端到ML过渡的功能以及State Services门户上的Quadrupel服务设备的报告,还参加了专门讨论Serverless的圆桌会议。 对于那些无法亲自参加活动的人,在这篇文章中我们讲最有趣的。

从后端开发到机器学习
ML数据工程师做什么? 后端开发人员和ML工程师的任务之间有什么异同? 您需要采取什么途径将第一专业转换为第二专业? 这是由亚历山大·帕里诺夫(Alexander Parinov)讲述的,他在后端工作了10年后进入了机器学习。
 亚历山大·帕里诺夫(Alexander Parinov)
亚历山大·帕里诺夫(Alexander Parinov)如今,Alexander在X5 Retail Group担任计算机视觉系统的架构师,并致力于与计算机视觉和深度学习相关的开源项目(github.com/creafz)。 他参加了世界排名前100名的Kaggle Master(kaggle.com/creafz),这是举办机器学习竞赛的最受欢迎的平台,这印证了他的技能。
为什么要转向机器学习
一年半以前,谷歌深度学习人工智能研究项目Google Brain的负责人杰夫·迪恩(Jeff Dean)告诉谷歌,如何将Google Translate中的100万行代码替换为仅由500行组成的Tensor Flow神经网络。 在对网络进行培训之后,数据质量得到了提高,基础架构得到了简化。 看来这是我们的光明前景:不再需要编写代码,只需使神经元发送数据即可。 但是实际上,一切都更加复杂。
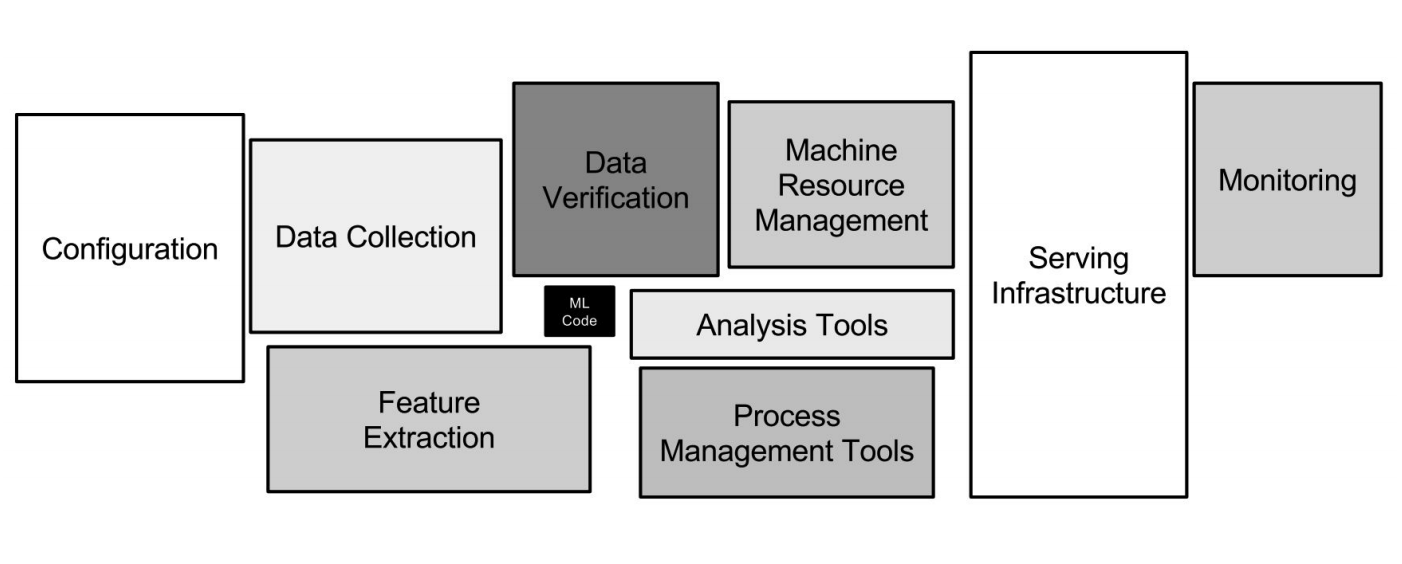 Google ML基础架构
Google ML基础架构神经网络只是基础设施的一小部分(上图中的小黑框)。 需要更多辅助系统来接收数据,对其进行处理,对其进行存储,检查质量等,我们需要用于培训,在生产中部署机器学习代码,测试该代码的基础结构。 所有这些任务就像后端开发人员所做的一样。
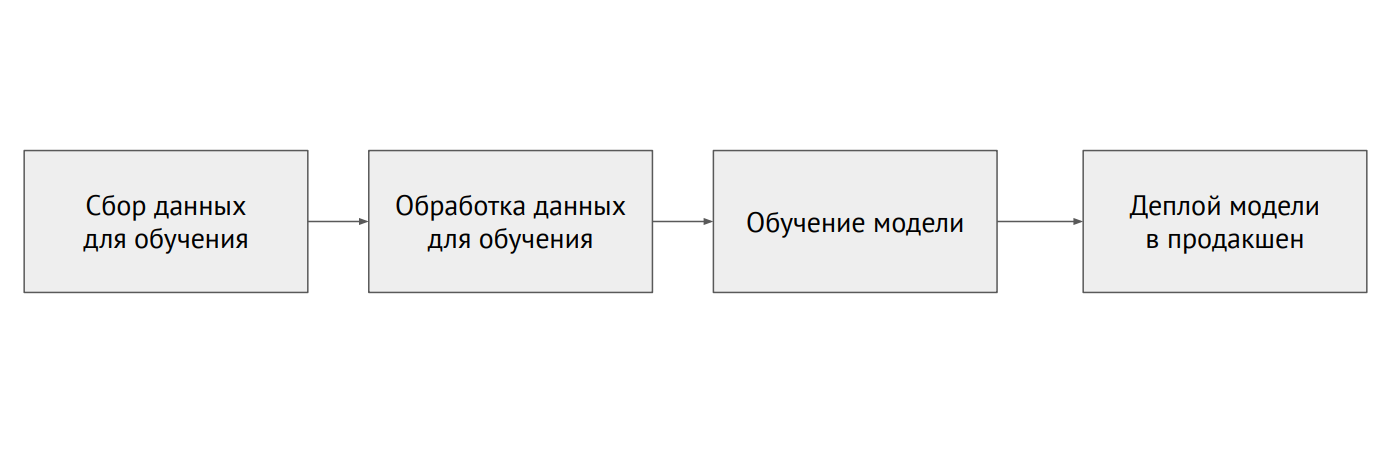 机器学习过程
机器学习过程ML和后端有什么区别
在经典编程中,我们编写代码,这决定了程序的行为。 在ML中,我们只有很小的模型代码和大量数据,因此我们可以删除模型。 机器学习中的数据非常重要:使用不同数据训练的同一模型可以显示出完全不同的结果。 问题在于,几乎所有数据都是零散的,并且位于不同的系统(关系数据库,NoSQL数据库,日志,文件)中。
 数据版本控制
数据版本控制ML不仅需要像经典开发中那样对代码进行版本控制,还需要对数据进行版本控制:有必要清楚地了解对模型进行了哪些培训。 您可以为此使用流行的Data Science版本控制库(dvc.org)。
 数据标记
数据标记下一个任务是数据标记。 例如,标记图片中的所有对象或说出它属于哪个类。 这是由Yandex.Tolki等特殊服务完成的,大大简化了API的可用性。 由于“人为因素”而引起困难:通过将同一任务委托给多个执行者,可以提高数据质量并最大程度地减少错误。
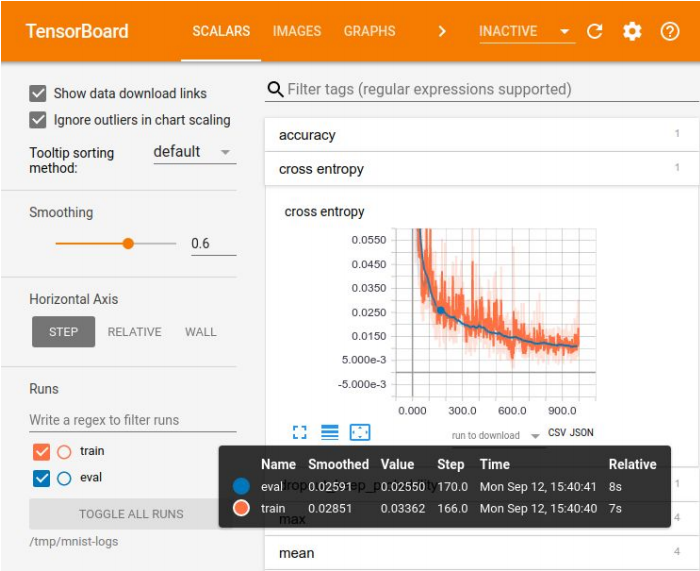 张量板中的可视化
张量板中的可视化为了比较结果,为某些指标选择最佳模型,必须记录实验。 为了可视化,有大量工具-例如Tensor Board。 但是,没有用于存储实验的理想方法。 在小型公司中,他们通常会使用excel-plate,而在大型公司中,他们会使用特殊的平台将结果存储在数据库中。
 机器学习有很多平台,但是其中没有一个平台可以满足70%的需求
机器学习有很多平台,但是其中没有一个平台可以满足70%的需求将训练有素的模型投入生产时,您必须处理的第一个问题与您喜欢的数据科学家工具-Jupyter Notebook有关。 其中没有模块性,也就是说,输出就是这样的“脚步倒塌”的代码,没有分成逻辑部分-模块。 一切混合在一起:类,函数,配置等。此代码难以版本和测试。
怎么处理呢? 您可以忍受Netflix并创建自己的平台,该平台使您可以直接在生产中运行这些笔记本电脑,将数据传输到笔记本电脑并获得结果。 您可以强迫将模型投入生产的开发人员正常地重写代码,并将其分解为模块。 但是使用这种方法,很容易犯一个错误,并且该模型将无法按预期工作。 因此,理想的选择是禁止在模型代码中使用Jupyter Notebook。 如果数据科学家当然同意这一点。
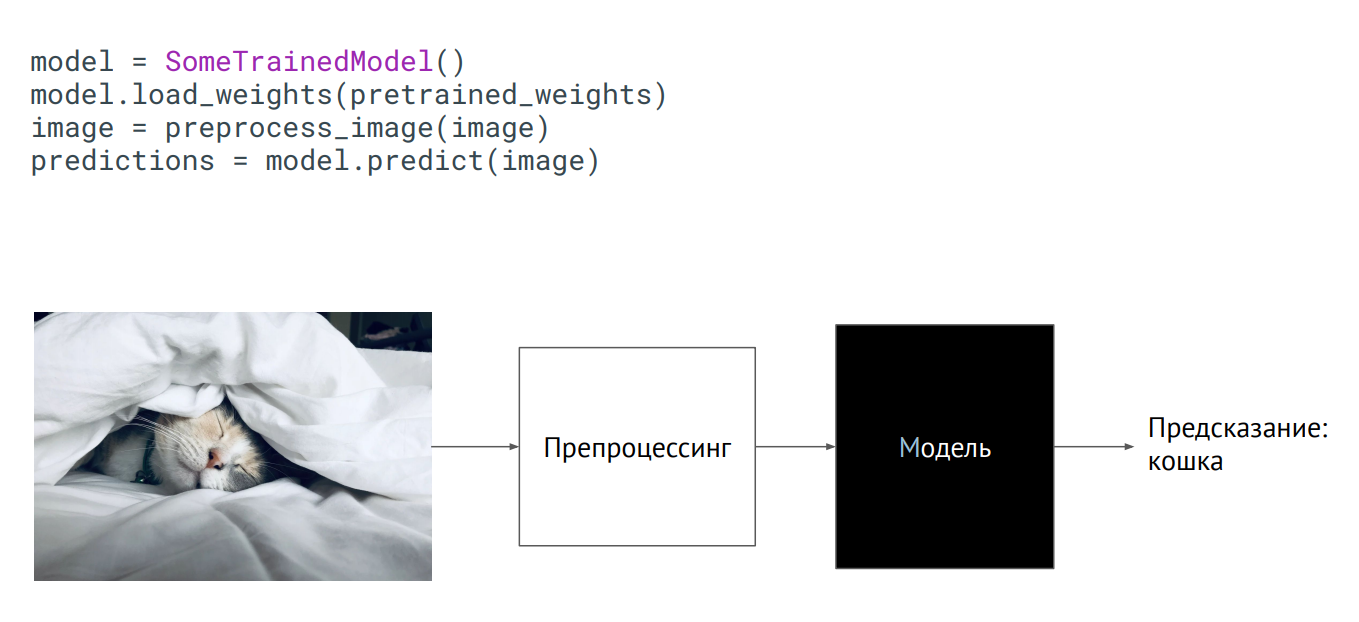 建模为黑匣子
建模为黑匣子将模型投入生产的最简单方法是将其用作黑匣子。 您具有模型的某个类别,该模型的权重(受过训练的网络的神经元参数)已传递给您,如果您初始化此类(调用预报方法,在上面放图片),则输出将获得某种预测。 内部发生什么无关紧要。
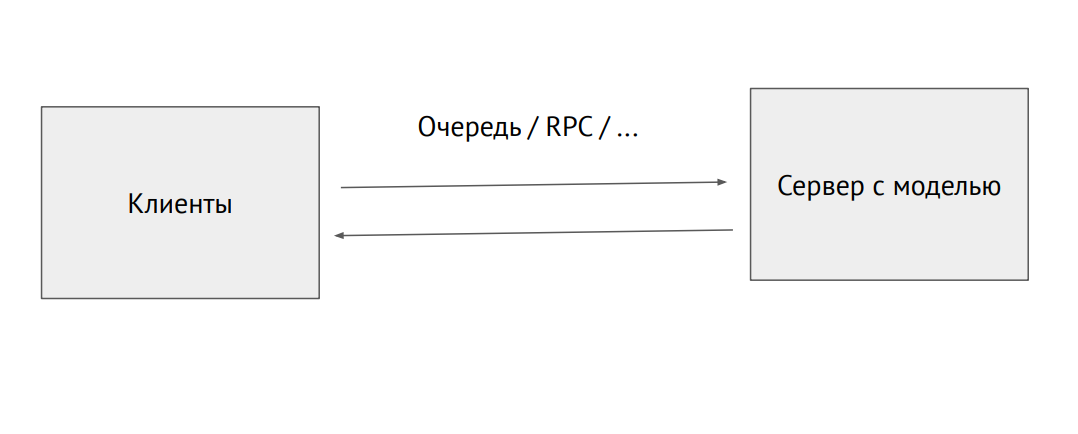 使用模型将服务器进程分开
使用模型将服务器进程分开您还可以选择一个单独的进程,并将其通过RPC队列发送(带有图片或其他源数据)。在输出中,我们将接收预测。
在Flask中使用模型的示例:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
这种方法的问题是性能限制。 假设我们有一个由数据科学家编写的Phyton代码,它会减慢速度,并且我们想压缩最大性能。 为此,您可以使用将代码转换为本机代码或将其转换为针对生产而优化的其他框架的工具。 每个框架都有这样的工具,但是没有理想的工具,您必须自己完成。
ML中的基础架构与常规后端中的基础架构相同。 有Docker和Kubernetes,仅对于Docker,您需要设置NVIDIA运行时,该运行时允许容器内的进程访问主机中的视频卡。 Kubernetes需要一个插件,以便它可以使用视频卡管理服务器。
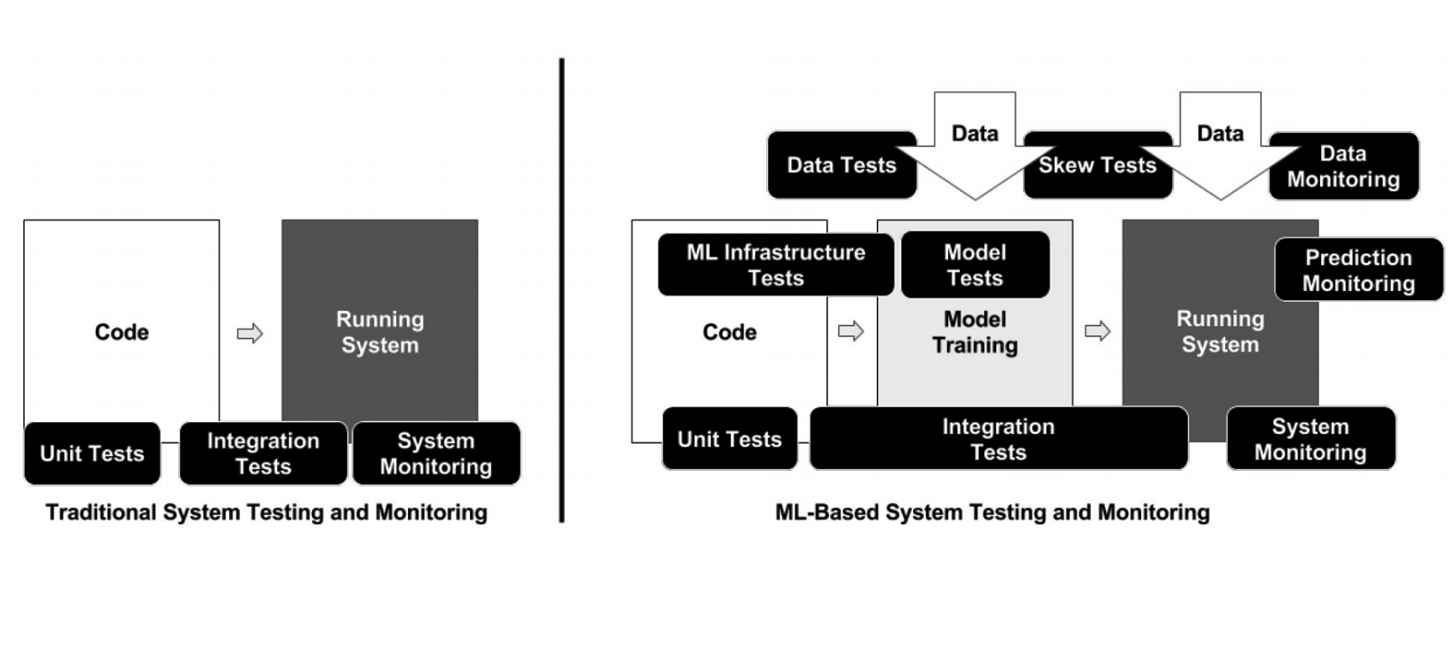
与经典编程不同,就ML而言,基础结构具有许多需要检查和测试的不同移动元素-例如,数据处理代码,模型训练管道和生产(请参见上图)。 测试连接不同部分管道的代码很重要:有很多部分,并且模块边界经常出现问题。
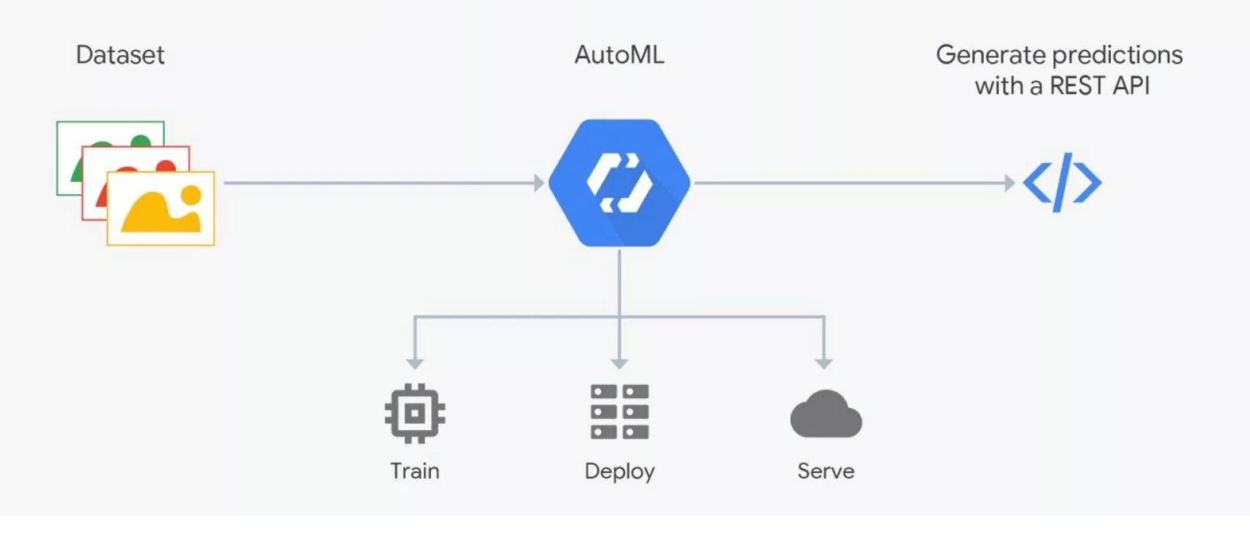 AutoML如何工作
AutoML如何工作AutoML服务承诺为您的目标选择最佳模型并进行培训。 但是您需要了解:在ML数据中非常重要,其结果取决于它们的准备。 人们正在标记,这充满了错误。 没有严格的控制,可能会产生垃圾,但是自动化仍无法解决;需要由专家进行验证-数据科学家。 这是AutoML“中断”的地方。 但是,这对于选择体系结构很有用-当您已经准备好数据并想要进行一系列实验以找到最佳模型时。
如何进入机器学习
如果您正在使用Python开发,那么进入ML最容易,这是所有深度学习框架(和常规框架)都使用的。 实际上,此语言是此活动领域所必需的。 C ++用于某些具有计算机视觉的任务,例如在无人驾驶汽车的控制系统中。 JavaScript和Shell-用于可视化以及诸如在浏览器中启动神经元之类的奇怪事情。 在使用大数据和进行机器学习时,将使用Java和Scala。 R和Julia受到统计人员的喜爱。
在Kaggle,获得实践经验是最方便的,参与该平台的一项竞赛对这一理论进行了超过一年的研究。 在此平台上,您可以采用某人的布局和注释代码,并尝试对其进行改进,针对您的目标进行优化。 Kaggle的奖励等级会影响您的薪水。
另一种选择是担任ML团队的后端开发人员。 现在有很多初创公司都参与了机器学习,在这些初创公司中,您可以通过帮助同事解决问题来获得经验。 最后,您可以加入一个数据科学家社区-Open Data Science(ods.ai)和其他社区。
演讲者在https://bit.ly/backend-to-ml上对该主题提供了更多信息。
“ Quadrupel”-门户“ State Services”的定向通知服务

叶夫根尼·斯米尔诺夫(Evgeny Smirnov)
下一位发言者是电子政府基础设施开发部门负责人Yevgeny Smirnov,他谈到了Quadrupel。 这是Gosuslugi门户(gosuslugi.ru)的有针对性的通知服务,该门户是俄罗斯Internet上访问量最大的州资源。 每天的受众为260万,总共有9000万用户在该网站上注册,其中有6000万已确认。 门户网站API的负载为3万RPS。
 Gosuslug后端中使用的技术
Gosuslug后端中使用的技术“四元组”是一种地址通知服务,通过设置特殊的信息规则,用户可以在最合适的时间获得该服务的帮助。 服务开发的主要要求是灵活的设置和足够的邮寄时间。
四重如何工作?

上图以需要替换驾驶证的情况为例,显示了“四重”规则之一。 首先,该服务搜索到期日期在一个月后到期的用户。 他们在标语上张贴了接受相应服务并发送电子邮件的要约。 对于那些已经过期的用户,横幅和电子邮件正在更改。 成功交换权利后,用户会收到其他通知-并建议更新证书中的数据。
从技术角度来看,这些是编写代码的常规脚本。 在输入处-数据,在输出处-正确/错误,匹配/不匹配。 总共有超过50条规则-从确定用户的生日(当前日期等于用户的生日)到困难的情况。 根据这些规则,每天确定大约一百万场比赛-需要通知的人。
 四重通知渠道
四重通知渠道Quadrupel的内部有一个用于存储用户数据的数据库,以及三个应用程序:
- 工作程序旨在更新数据。
- Rest API会提取横幅广告,并将其本身提供给门户网站和移动应用程序。
- 计划程序启动横幅重新计数或批量邮件。
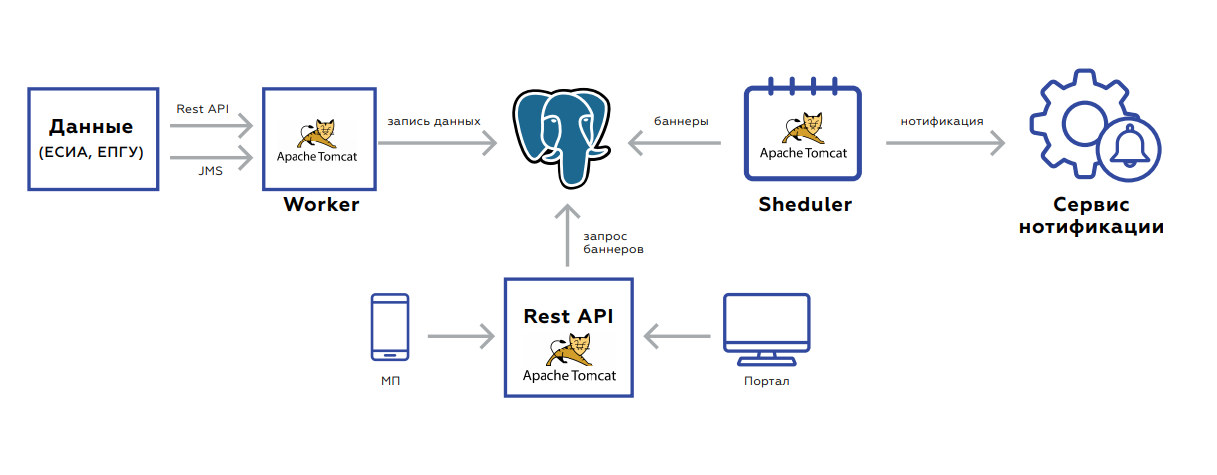
后端是面向事件的,用于更新数据。 两个接口-rest或JMS。 有很多事件,在保存和处理事件之前,先将它们聚合起来,以免发出不必要的请求。 数据库本身(存储数据的板块)看起来像键值存储-用户的键和值本身:指示存在或不存在相关文档,其有效期限,该用户对服务顺序的汇总统计信息的标志等。

保存数据后,将在JMS中设置任务,以便立即重新计算标语-必须立即将其显示在Web上。 系统从晚上开始:在JMS中,用户间隔会抛出任务,您需要根据这些间隔重新计算规则。 这由重新计票者领取。 此外,处理结果落入下一个队列,该队列要么将标语保存在数据库中,要么将任务发送给用户以通知用户。 该过程需要5到7个小时,因此您可以随时删除处理器或使用新处理器引发实例,因此可以轻松扩展。

该服务效果很好。 但是,随着用户数量的增加,数据量也在增长。 这会导致数据库负载增加-甚至考虑到Rest API正在查看副本的事实。 第二点是JMS,事实证明,由于内存消耗大,它不太适合。 由于JMS崩溃和处理停止,队列溢出的风险很高。 此后如果不清理日志就无法提高JMS。
计划使用分片解决问题,这将允许平衡基础上的负载。 还计划更改数据存储方案,并将JMS更改为Kafka-一种更具容错能力的解决方案,它将解决内存问题。
后端即服务与。 无服务器
 从左至右:亚历山大·博尔加特,安德烈·托米连科,尼古拉·马尔科夫,阿拉·以色列
从左至右:亚历山大·博尔加特,安德烈·托米连科,尼古拉·马尔科夫,阿拉·以色列后端即服务还是无服务器解决方案? 下列人员参加了圆桌会议对这一紧迫问题的讨论:
- 首席技术官兼Scorocode创始人Ara Israelyan。
- Aligned Research Group的高级数据工程师Nikolay Markov。
- RUVDS开发部主管Andrey Tomilenko。
对话由高级开发人员Alexander Borgart主持。 我们以简短的形式介绍辩论,听众参加了辩论。
-您认为无服务器是什么?
Andrei :这是一个计算模型-Lambda函数,应处理数据,以便结果仅取决于数据。 该术语来自Google或Amazon及其AWS Lambda服务。 提供者通过为此分配容量池来更容易地处理这种功能。 可以在同一服务器上独立考虑不同的用户。
Nikolay :如果很简单,我们会将IT基础架构的一部分(业务逻辑)转移到云中,以进行外包。
阿拉 :对于开发商来说-一种节省市场资源的好方法-对于营销商来说–可以赚更多的钱。
-无服务器-与微服务相同吗?
尼古拉 :不,Serverless更像是一个架构组织。 微服务是某种逻辑的原子单位。 无服务器是一种方法,而不是“单独的实体”。
回答 :无服务器功能可以打包在微服务中,但是从此它将不再是无服务器功能,不再是Lambda函数。 在无服务器中,功能仅在被请求时启动。
安德鲁 :他们的生活时间不同。 我们启动并忘记了Lambda函数。 它工作了几秒钟,下一个客户端可以在另一台物理计算机上处理其请求。
-哪个比例更好?
答案 :通过水平缩放,Lambda函数的行为与微服务完全相同。
Nikolai :您要求多少个副本-将有很多副本,无服务器扩展没有问题。 Kubernetes制作了一个副本集,“在某处”启动了20个实例,并向您返回了20个匿名链接。 来吧!
-是否可以在无服务器上编写后端?
安德鲁 :从理论上讲,但这没有意义。 Lambda函数将基于单个存储库-我们需要提供保证。 例如,如果用户进行了某笔交易,则下次他应该看到:交易已完成,资金已记入贷方。 此调用将阻止所有Lambda函数。 实际上,许多无服务器功能将变成一个服务,并且只有一个狭窄的数据库访问点。
-在什么情况下使用无服务器架构有意义?
Andrew :不需要公用存储的任务-相同的挖矿,区块链。 您需要在其中数很多的地方。 如果您具有强大的计算能力,则可以定义一个函数,例如“计算那里某物的哈希...”,但是您可以通过采用Amazon和Lambda函数及其分布式存储来解决数据存储的问题。 事实证明,您正在编写常规服务。 Lambda函数将访问存储库并向用户提供某种响应。
尼古拉(Nikolai) :在无服务器环境中运行的容器非常有限。 几乎没有什么记忆。 但是,如果您已将所有基础架构完全部署在某种类型的云(Google,Amazon)上,并且与它们有永久合同,则所有这些都需要预算,然后对于某些任务,您可以使用无服务器容器。 由于所有内容都是为在特定环境中使用而量身定制的,因此必须完全位于此基础结构内部。 也就是说,如果您准备将所有内容绑定到云基础架构,则可以进行试验。 优点是您不必管理此基础结构。
Ara :Serverless不需要您管理Kubernetes,Docker,安装Kafka等,这是自欺欺人。 亚马逊和谷歌是相同的经理,他们都这样说。 另一件事是您拥有SLA。 同样,您可以将所有内容外包,而无需自己进行编程。
Andrew :无服务器本身很便宜,但是您必须为其余的Amazon服务(例如,数据库)支付很多费用。 人们已经起诉他们,因为他们为API门付出了疯狂的金钱。
阿拉 :如果我们谈论金钱,那么您需要考虑这一点:您将必须在公司中部署整个开发方法的180度,以便将所有代码转移到Serverless。 这将花费大量时间和金钱。
-是否有付费的无服务器亚马逊和谷歌替代品?
尼古拉(Nikolay) :在Kubernetes中,您开始某种工作,它实现并消亡-从体系结构的角度来看,这是相当无服务器的。 如果您想使用队列和基础来创建一个非常有趣的业务逻辑,那么您需要多考虑一下。 这一切都无需离开Kubernetes即可解决。 我不会开始拖延其他实现。
-监视无服务器中发生的事情有多重要?
回答 :取决于系统架构和业务需求。 实际上,提供者应该提供报告,以帮助开发人员找出可能的问题。
Nikolai :在Amazon中有CloudWatch,所有日志(包括Lambda)都在其中流传输。 集成日志转发,并使用一些单独的工具进行查看,警报等。 在启动的容器中,您可以填充代理。
 -让我们总结一下。
-让我们总结一下。
安德鲁 :思考Lambda函数很有用。 如果您先创建一个服务-不是微服务,而是创建一个请求,访问数据库并发送答案的服务-Lambda函数将解决许多问题:多线程,可伸缩性等等。 如果您的逻辑是通过这种方式构建的,那么将来您将能够将这些Lambda转移到微服务或使用第三方服务(如Amazon)。 该技术是有用的,一个有趣的想法。 有多少商业理由仍然是一个悬而未决的问题。
Nikolai:Serverless最好用于操作任务,而不是计算某种业务逻辑。 我一直将此作为事件处理。 如果您在Amazon中拥有它,那么如果您在Kubernetes中-是的。 否则,您将不得不付出很多努力来提高自己的无服务器能力。 您需要观看特定的业务案例。 例如,我现在有一项任务:当文件以某种格式出现在磁盘上时,您需要将它们上传到Kafka。 我可以使用此WatchDog或Lambda。 从逻辑上讲,两者都是合适的,但是Serverless难以实现,并且我更喜欢没有Lambda的简单方法。
Ara :无服务器-一个有趣的,适用的,技术上非常漂亮的想法。 迟早,技术将达到任何功能在不到100毫秒的时间内上升的地步。 这样,原则上就不会有等待时间对于用户是否至关重要的问题。 同时,正如同事已经说过的那样,Serverless的适用性完全取决于业务任务。
感谢我们为我们提供了很多帮助的赞助商:
